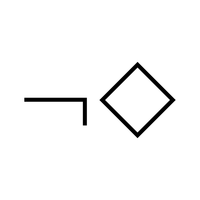
ibm-research/AttaQ
Viewer
•
Updated
•
1.4k
•
2.18k
•
15





Try HuggingChat to chat with AI
Display a leaderboard with UGI scores




































Search and save datasets generated with a LLM in real time













Analyze images to detect and label objects