
CogAgent
Reminder: This is the repository for CogAgent of SAT (SwissArmyTransformer) version.
Please refer to https://huggingface.co/THUDM/cogagent-chat-hf for CogAgent of Huggingface version.
Introduction
CogAgent is an open-source visual language model improved based on CogVLM. CogAgent-18B has 11 billion visual and 7 billion language parameters.
📖 Paper: https://arxiv.org/abs/2312.08914
🚀 GitHub: For more information, please refer to Our GitHub
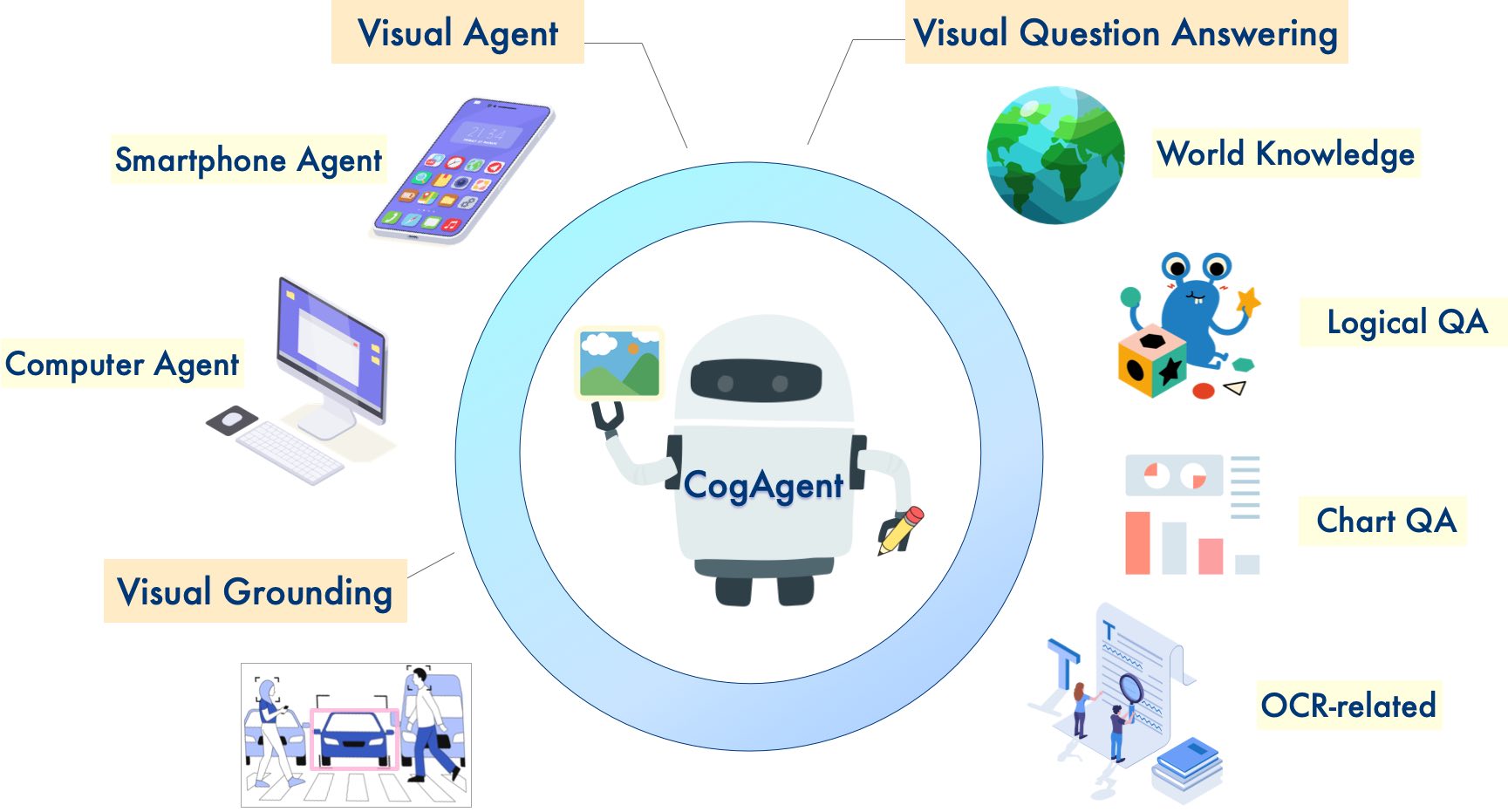
CogAgent demonstrates strong performance in image understanding and GUI agent:
CogAgent-18B achieves state-of-the-art generalist performance on 9 cross-modal benchmarks, including: VQAv2, MM-Vet, POPE, ST-VQA, OK-VQA, TextVQA, ChartQA, InfoVQA, DocVQA.
CogAgent-18B significantly surpasses existing models on GUI operation datasets, including AITW and Mind2Web.
In addition to all the features already present in CogVLM (visual multi-round dialogue, visual grounding), CogAgent:
Supports higher resolution visual input and dialogue question-answering. It supports ultra-high-resolution image inputs of 1120x1120.
Possesses the capabilities of a visual Agent, being able to return a plan, next action, and specific operations with coordinates for any given task on any GUI screenshot.
Enhanced GUI-related question-answering capabilities, allowing it to handle questions about any GUI screenshot, such as web pages, PC apps, mobile applications, etc.
Enhanced capabilities in OCR-related tasks through improved pre-training and fine-tuning.
Quick Start
Please refer to the instructions located at our GitHub - section cli-SAT for inference and fine-tuning of the SAT version of the model.
You only need to use a command for easy inference.
python cli_demo_sat.py --from_pretrained cogagent-chat --version chat --bf16 --stream_chat
License
The code in this repository is open source under the Apache-2.0 license, while the use of CogAgent and CogVLM model weights must comply with the Model License.
Citation & Acknowledgements
If you find our work helpful, please consider citing the following papers
@misc{hong2023cogagent,
title={CogAgent: A Visual Language Model for GUI Agents},
author={Wenyi Hong and Weihan Wang and Qingsong Lv and Jiazheng Xu and Wenmeng Yu and Junhui Ji and Yan Wang and Zihan Wang and Yuxiao Dong and Ming Ding and Jie Tang},
year={2023},
eprint={2312.08914},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
In the instruction fine-tuning phase of the CogVLM, there are some English image-text data from the MiniGPT-4, LLAVA, LRV-Instruction, LLaVAR and Shikra projects, as well as many classic cross-modal work datasets. We sincerely thank them for their contributions.