Hub documentation
Using SpeechBrain at Hugging Face
Using SpeechBrain at Hugging Face
speechbrain is an open-source and all-in-one conversational toolkit for audio/speech. The goal is to create a single, flexible, and user-friendly toolkit that can be used to easily develop state-of-the-art speech technologies, including systems for speech recognition, speaker recognition, speech enhancement, speech separation, language identification, multi-microphone signal processing, and many others.
Exploring SpeechBrain in the Hub
You can find speechbrain models by filtering at the left of the models page.
All models on the Hub come up with the following features:
- An automatically generated model card with a brief description.
- Metadata tags that help for discoverability with information such as the language, license, paper, and more.
- An interactive widget you can use to play out with the model directly in the browser.
- An Inference API that allows to make inference requests.
Using existing models
speechbrain offers different interfaces to manage pretrained models for different tasks, such as EncoderClassifier, EncoderClassifier, SepformerSeperation, and SpectralMaskEnhancement. These classes have a from_hparams method you can use to load a model from the Hub
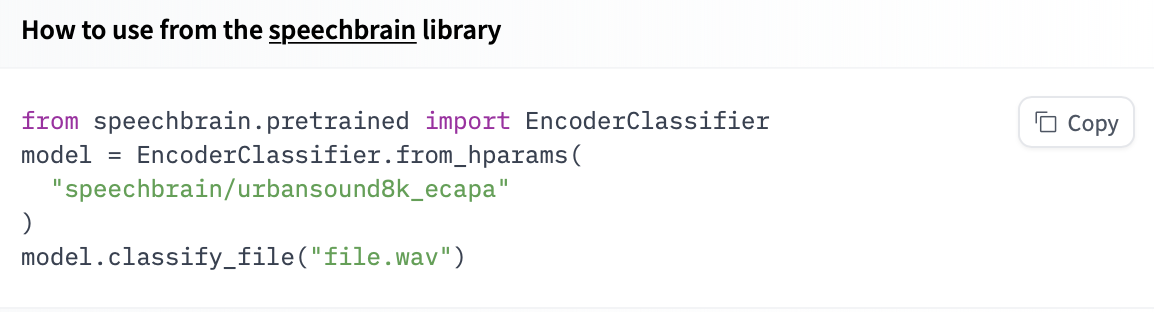
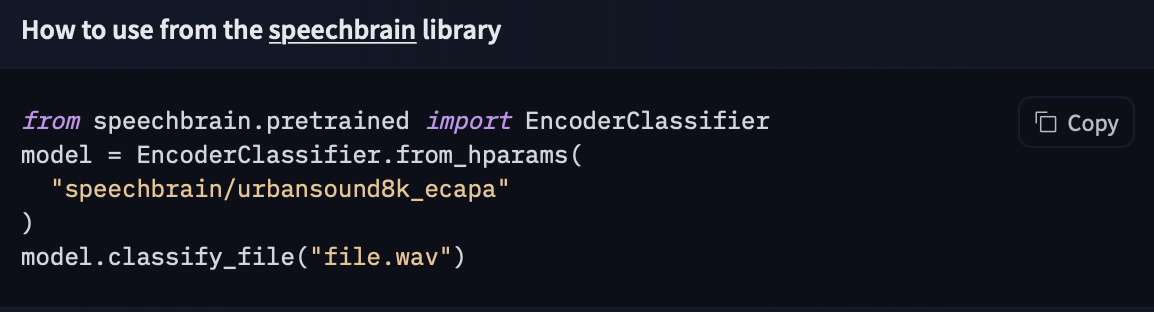
Here is an example to run inference for sound recognition in urban sounds.
import torchaudio
from speechbrain.pretrained import EncoderClassifier
classifier = EncoderClassifier.from_hparams(
source="speechbrain/urbansound8k_ecapa"
)
out_prob, score, index, text_lab = classifier.classify_file('speechbrain/urbansound8k_ecapa/dog_bark.wav')If you want to see how to load a specific model, you can click Use in speechbrain and you will be given a working snippet that you can load it!