Hub documentation
Widgets
Widgets
What’s a widget?
Many model repos have a widget that allows anyone to run inferences directly in the browser. These widgets are powered by Inference Providers, which provide developers streamlined, unified access to hundreds of machine learning models, backed by our serverless inference partners.
Here are some examples of current popular models:
- DeepSeek V3 - State-of-the-art open-weights conversational model
- Flux Kontext - Open-weights transformer model for image editing
- Falconsai’s NSFW Detection - Image content moderation
- ResembleAI’s Chatterbox - Production-grade open source text-to-speech model.
You can explore more models and their widgets on the models page or try them interactively in the Inference Playground.
Enabling a widget
Widgets are displayed when the model is hosted by at least one Inference Provider, ensuring optimal performance and reliability for the model’s inference. Providers autonomously chose and control what models they deploy.
The type of widget displayed (text-generation, text to image, etc) is inferred from the model’s pipeline_tag, a special tag that the Hub tries to compute automatically for all models. The only exception is for the conversational widget which is shown on models with a pipeline_tag of either text-generation or image-text-to-text, as long as they’re also tagged as conversational. We choose to expose only one widget per model for simplicity.
For some libraries, such as transformers, the model type can be inferred automatically based from configuration files (config.json). The architecture can determine the type: for example, AutoModelForTokenClassification corresponds to token-classification. If you’re interested in this, you can see pseudo-code in this gist.
For most other use cases, we use the model tags to determine the model task type. For example, if there is tag: text-classification in the model card metadata, the inferred pipeline_tag will be text-classification.
You can always manually override your pipeline type with pipeline_tag: xxx in your model card metadata. (You can also use the metadata GUI editor to do this).
How can I control my model’s widget example input?
You can specify the widget input in the model card metadata section:
widget:
- text: "This new restaurant has amazing food and great service!"
example_title: "Positive Review"
- text: "I'm really disappointed with this product. Poor quality and overpriced."
example_title: "Negative Review"
- text: "The weather is nice today."
example_title: "Neutral Statement"You can provide more than one example input. In the examples dropdown menu of the widget, they will appear as Example 1, Example 2, etc. Optionally, you can supply example_title as well.
widget:
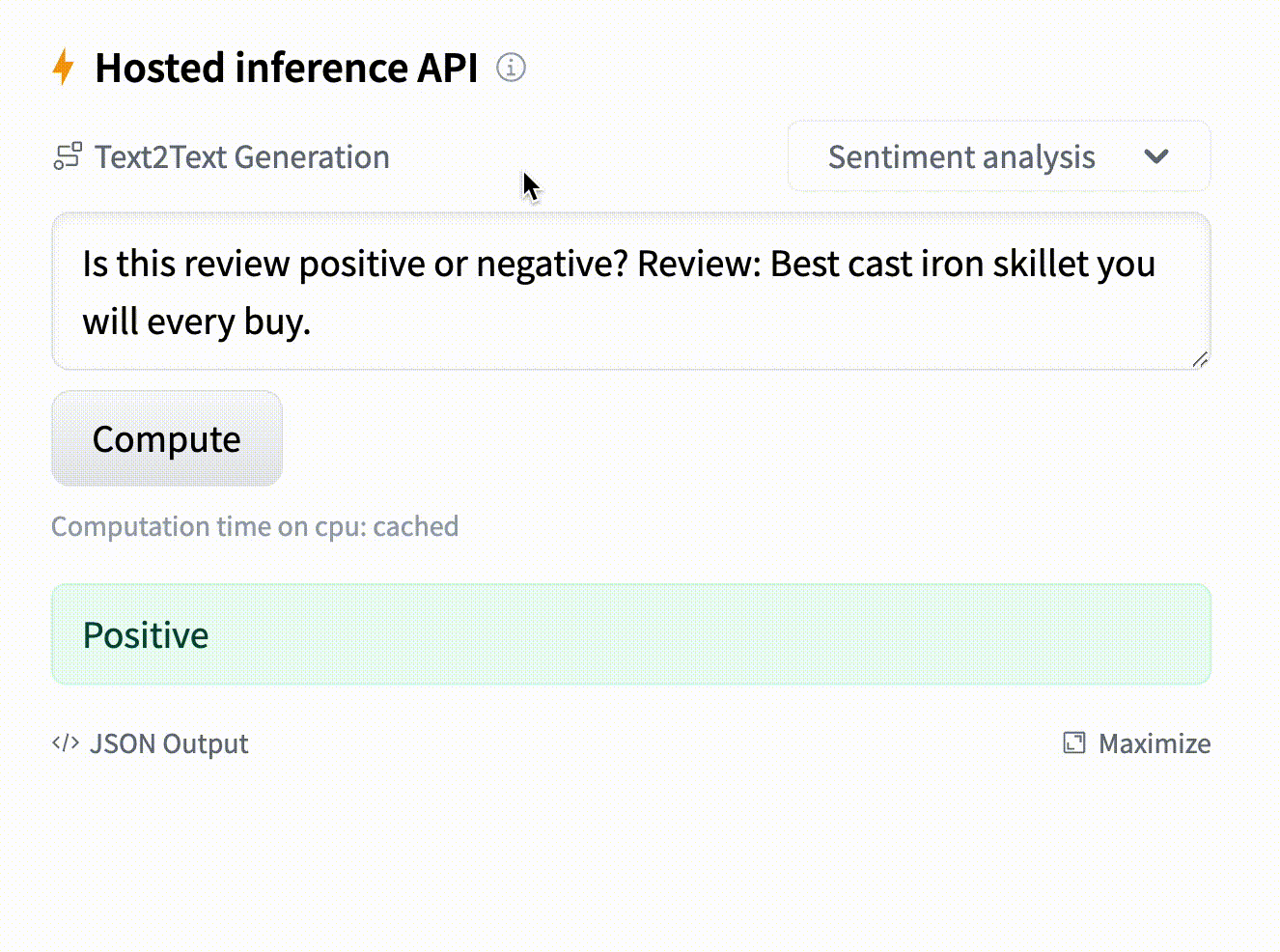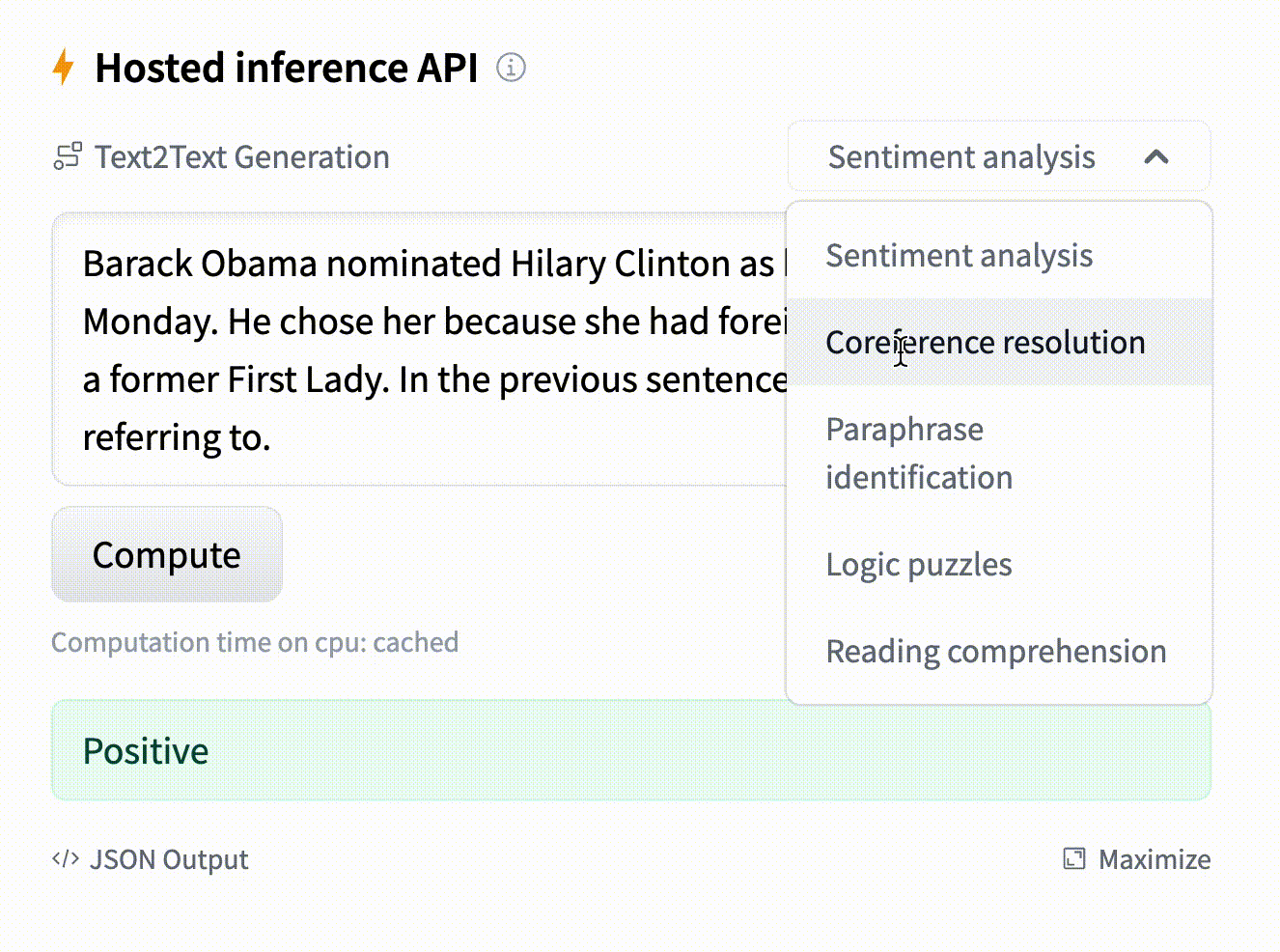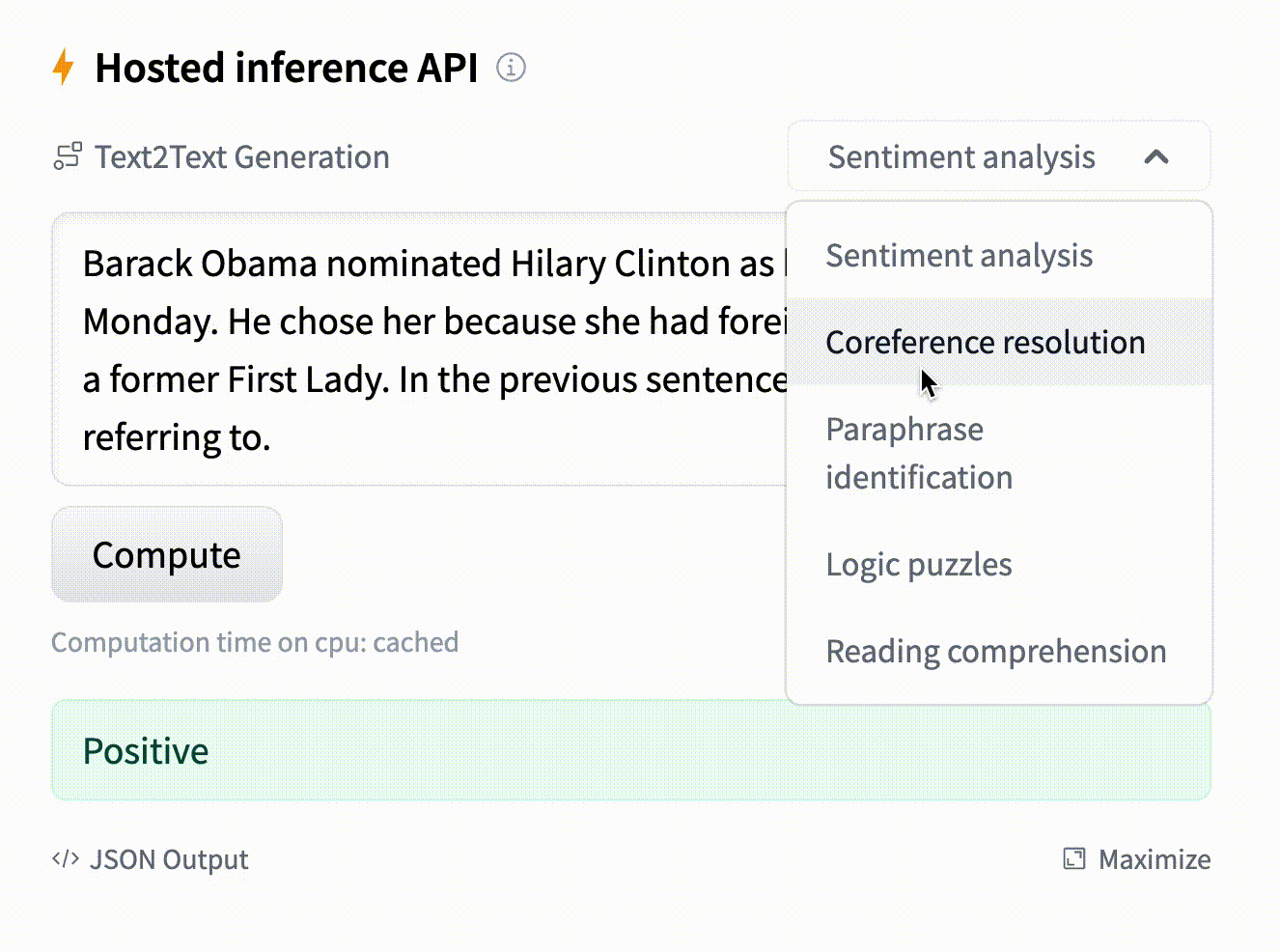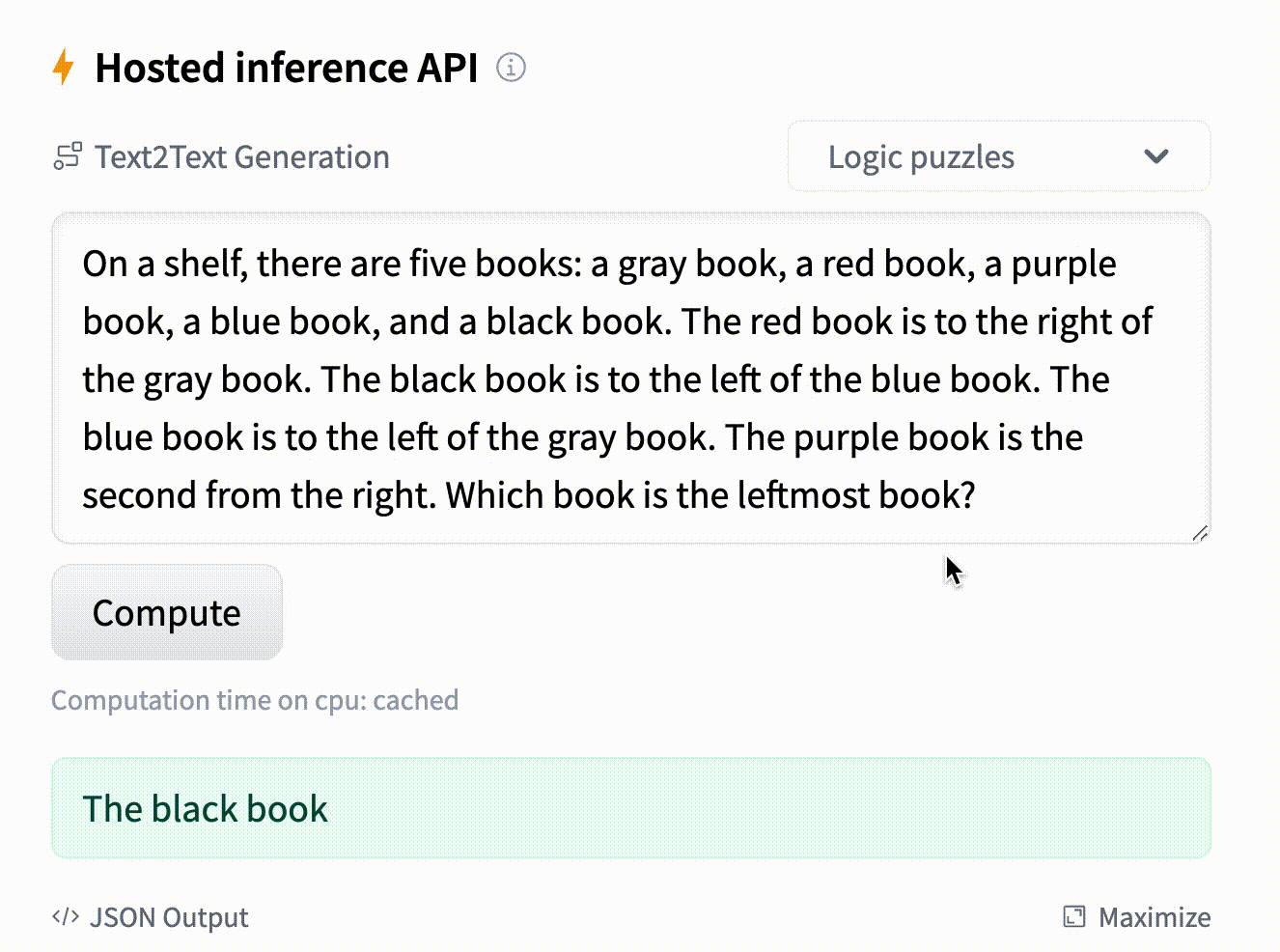
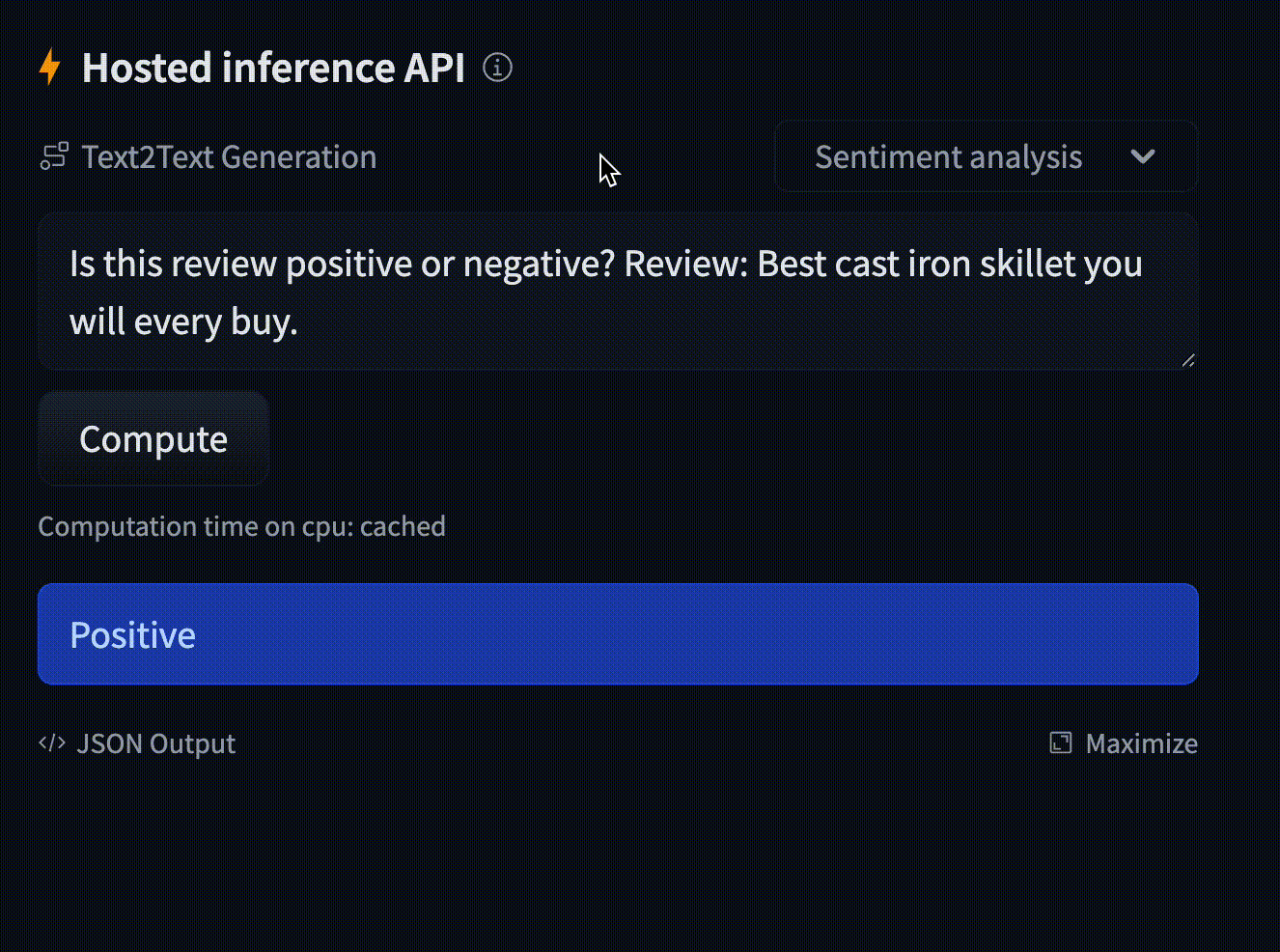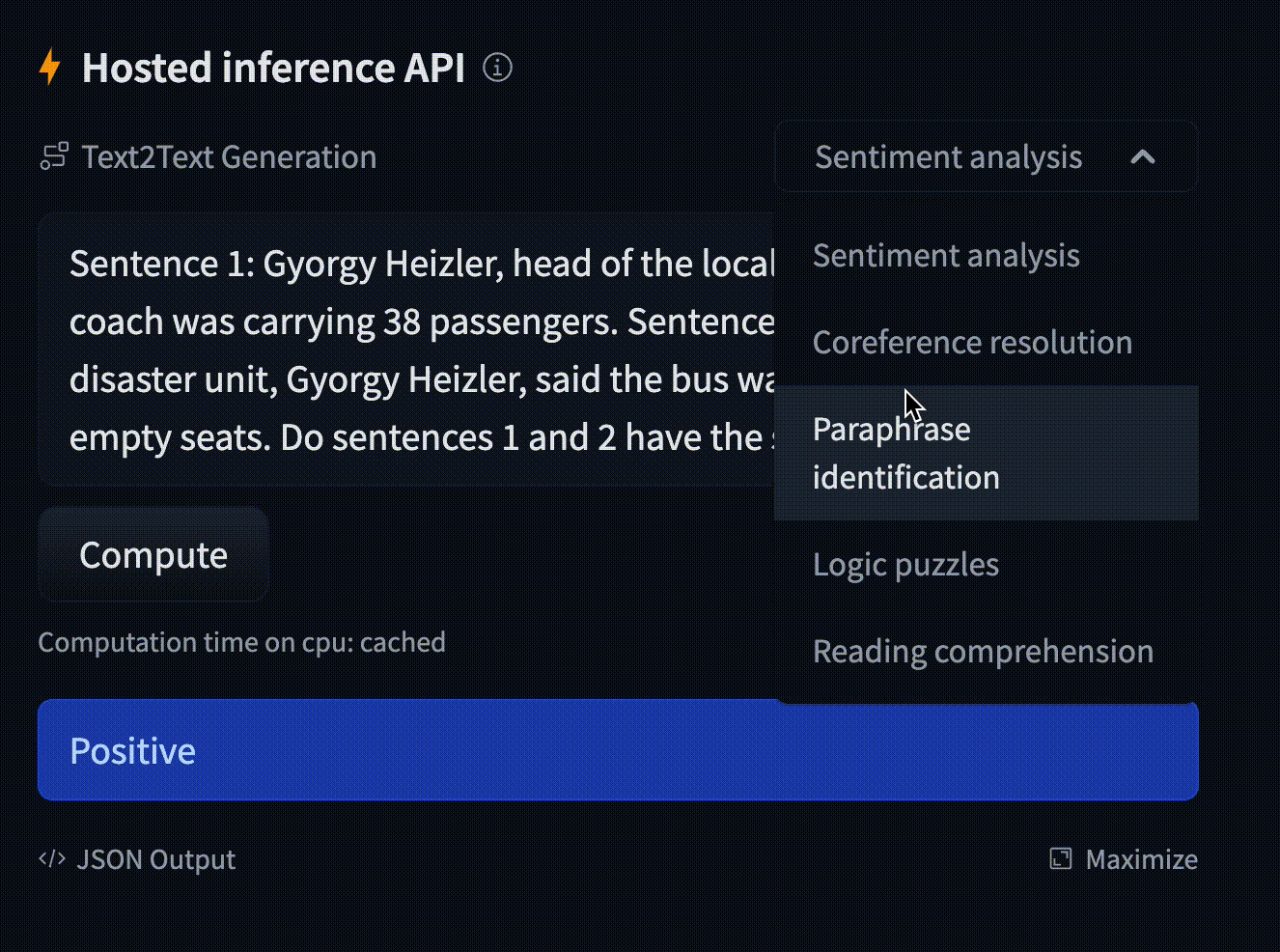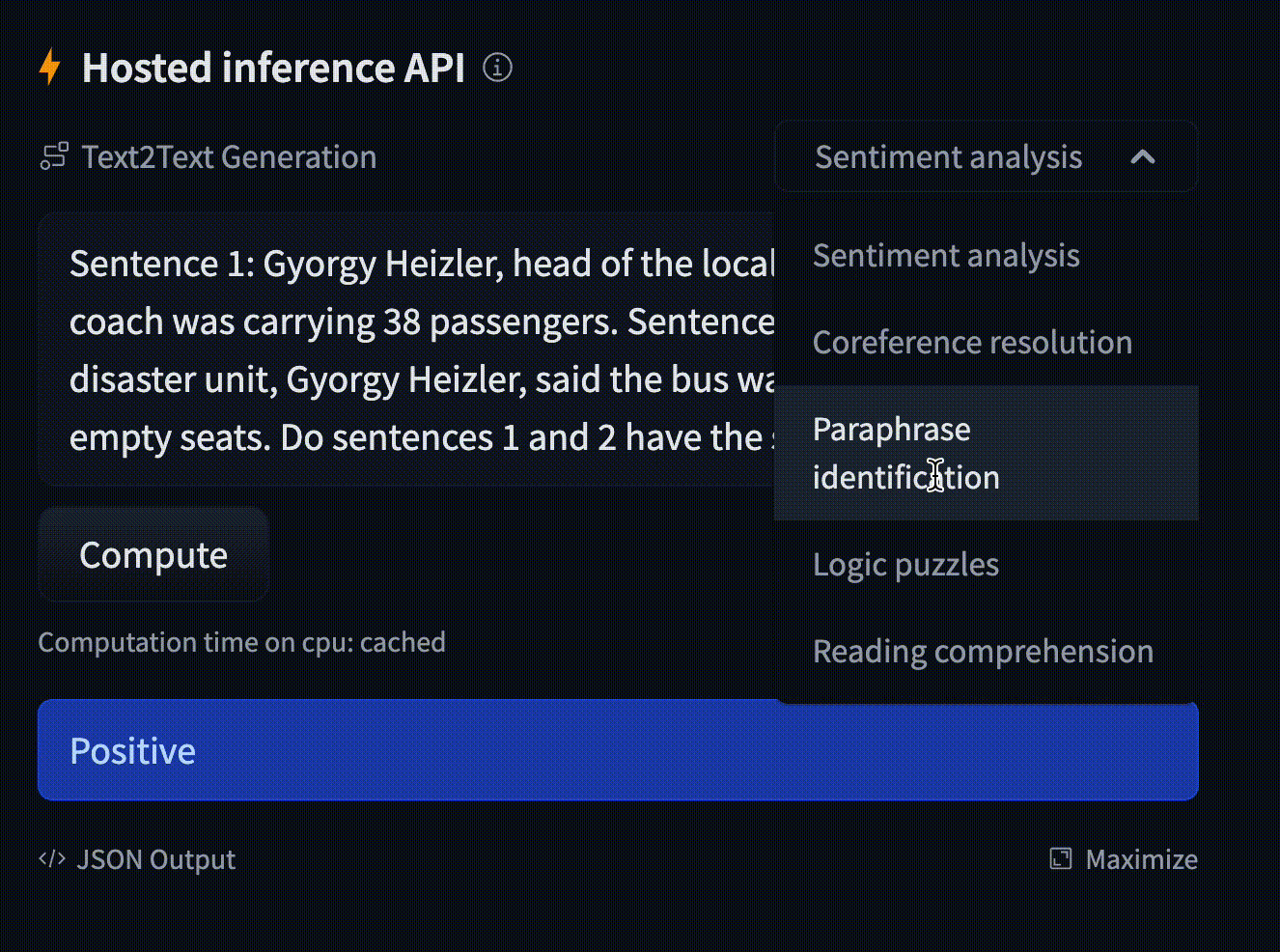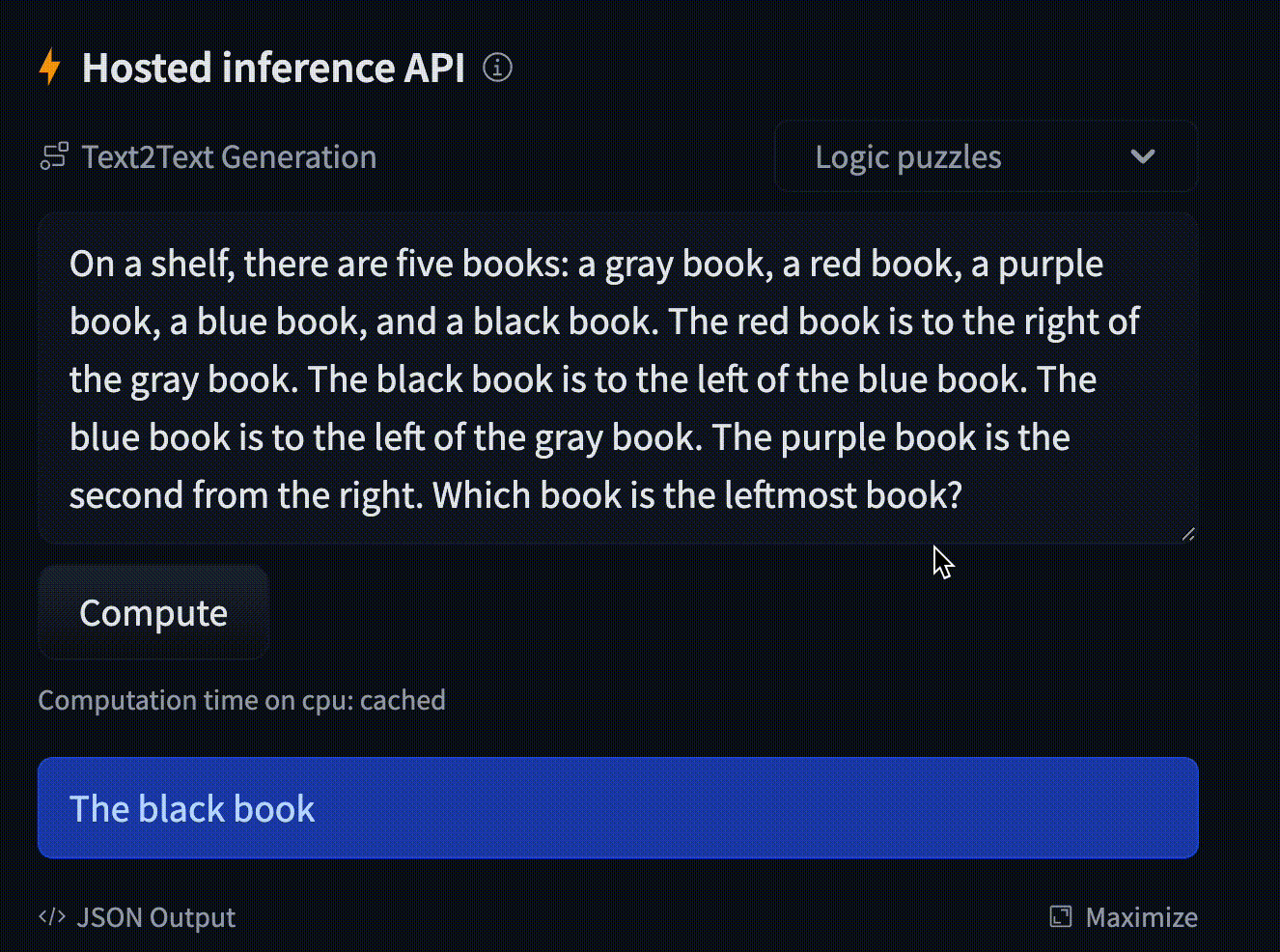
- text: "Is this review positive or negative? Review: Best cast iron skillet you will ever buy."
example_title: "Sentiment analysis"
- text: "Barack Obama nominated Hilary Clinton as his secretary of state on Monday. He chose her because she had ..."
example_title: "Coreference resolution"
- text: "On a shelf, there are five books: a gray book, a red book, a purple book, a blue book, and a black book ..."
example_title: "Logic puzzles"
- text: "The two men running to become New York City's next mayor will face off in their first debate Wednesday night ..."
example_title: "Reading comprehension"Moreover, you can specify non-text example inputs in the model card metadata. Refer here for a complete list of sample input formats for all widget types. For vision & audio widget types, provide example inputs with src rather than text.
For example, allow users to choose from two sample audio files for automatic speech recognition tasks by:
widget:
- src: https://example.org/somewhere/speech_samples/sample1.flac
example_title: Speech sample 1
- src: https://example.org/somewhere/speech_samples/sample2.flac
example_title: Speech sample 2Note that you can also include example files in your model repository and use them as:
widget:
- src: https://huggingface.co/username/model_repo/resolve/main/sample1.flac
example_title: Custom Speech Sample 1But even more convenient, if the file lives in the corresponding model repo, you can just use the filename or file path inside the repo:
widget:
- src: sample1.flac
example_title: Custom Speech Sample 1or if it was nested inside the repo:
widget:
- src: nested/directory/sample1.flacWe provide example inputs for some languages and most widget types in default-widget-inputs.ts file. If some examples are missing, we welcome PRs from the community to add them!
Example outputs
As an extension to example inputs, for each widget example, you can also optionally describe the corresponding model output, directly in the output property.
This is useful when the model is not yet supported by Inference Providers, so that the model page can still showcase how the model works and what results it gives.
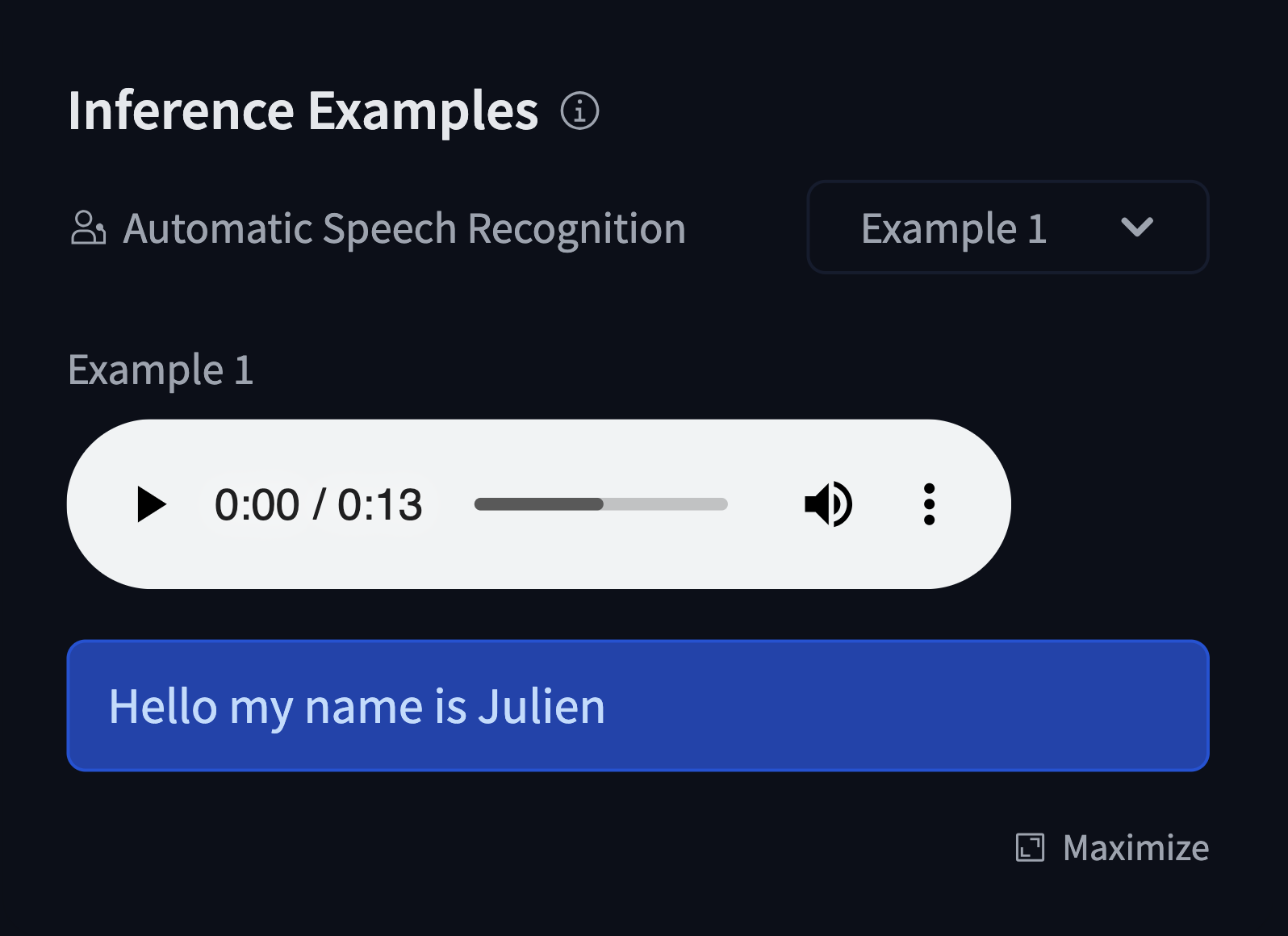
For instance, for an automatic-speech-recognition model:
widget:
- src: sample1.flac
output:
text: "Hello my name is Julien"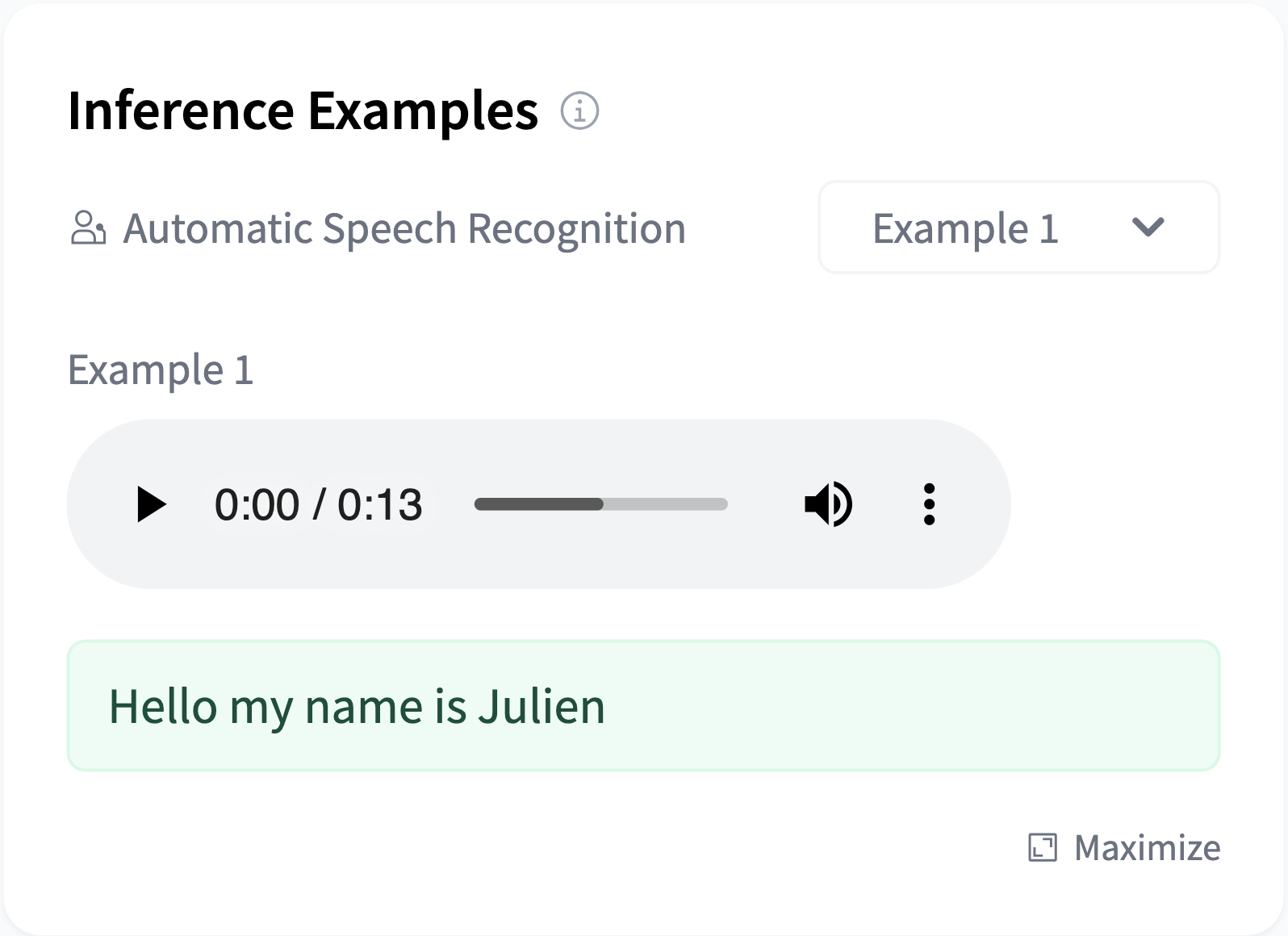
The output property should be a YAML dictionary that represents the output format from Inference Providers.
For a model that outputs text, see the example above.
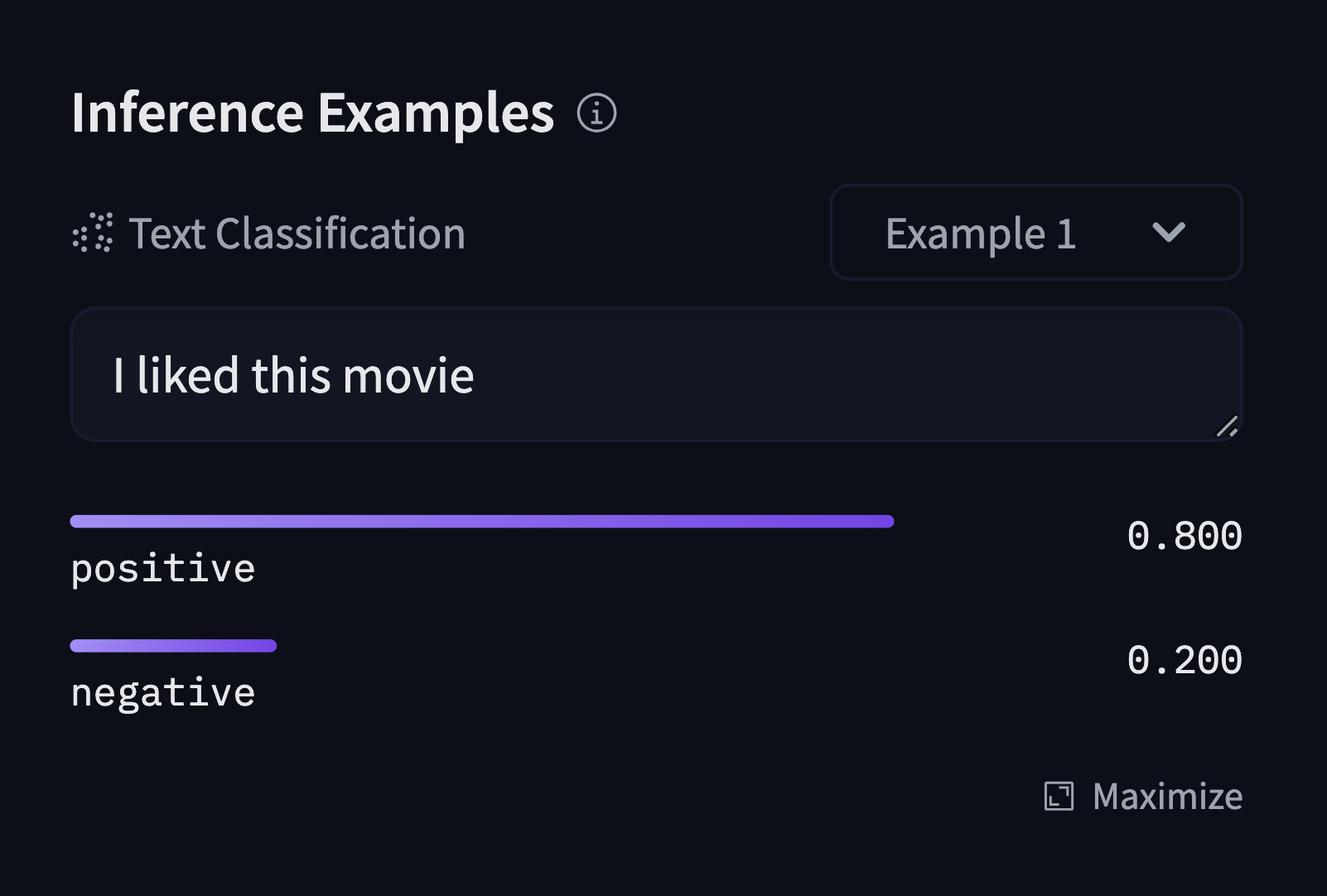
For a model that outputs labels (like a text-classification model for instance), output should look like this:
widget:
- text: "I liked this movie"
output:
- label: POSITIVE
score: 0.8
- label: NEGATIVE
score: 0.2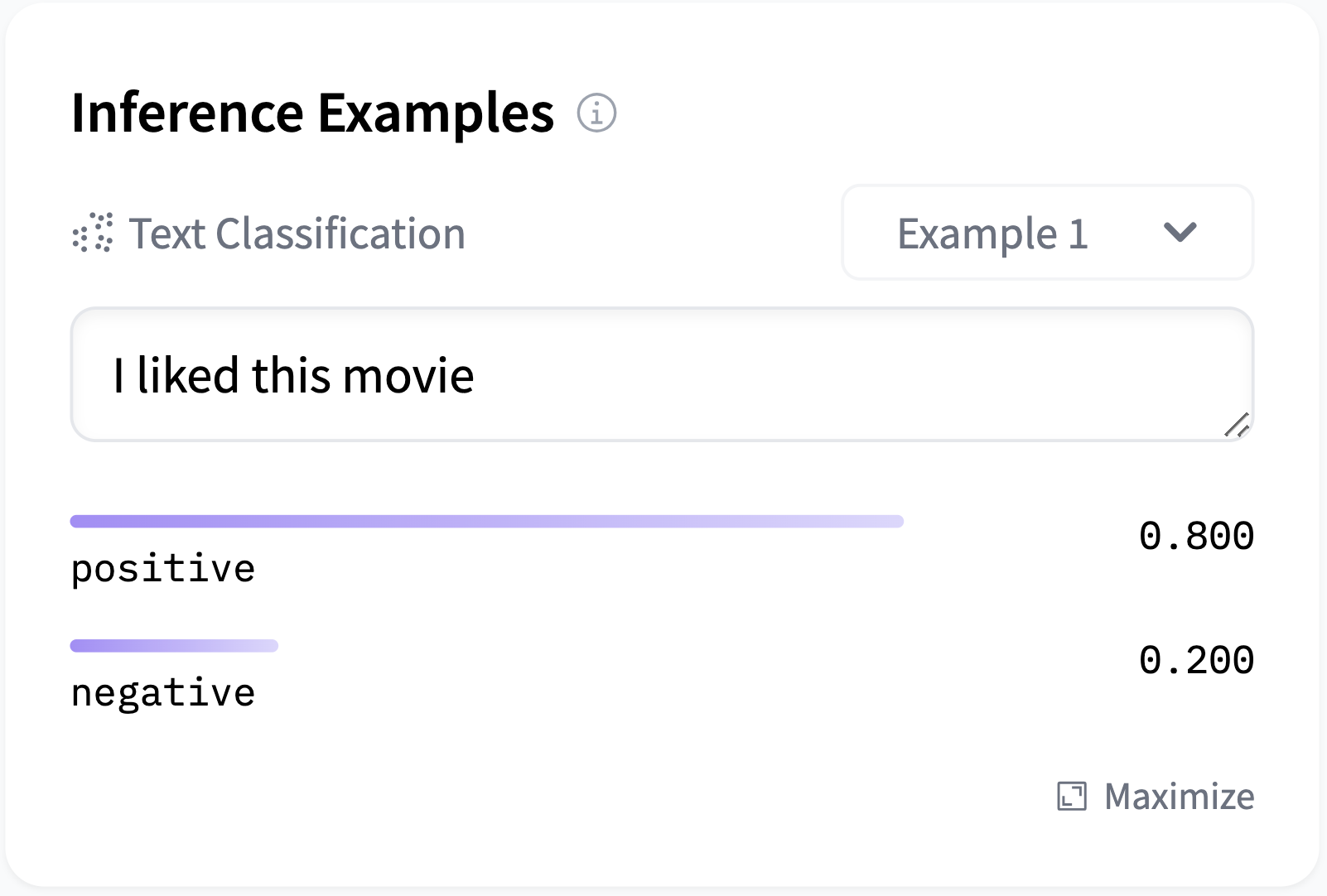
Finally, for a model that outputs an image, audio, or any other kind of asset, the output should include a url property linking to either a file name or path inside the repo or a remote URL. For example, for a text-to-image model:
widget:
- text: "picture of a futuristic tiger, artstation"
output:
url: images/tiger.jpg

We can also surface the example outputs in the Hugging Face UI, for instance, for a text-to-image model to display a gallery of cool image generations.
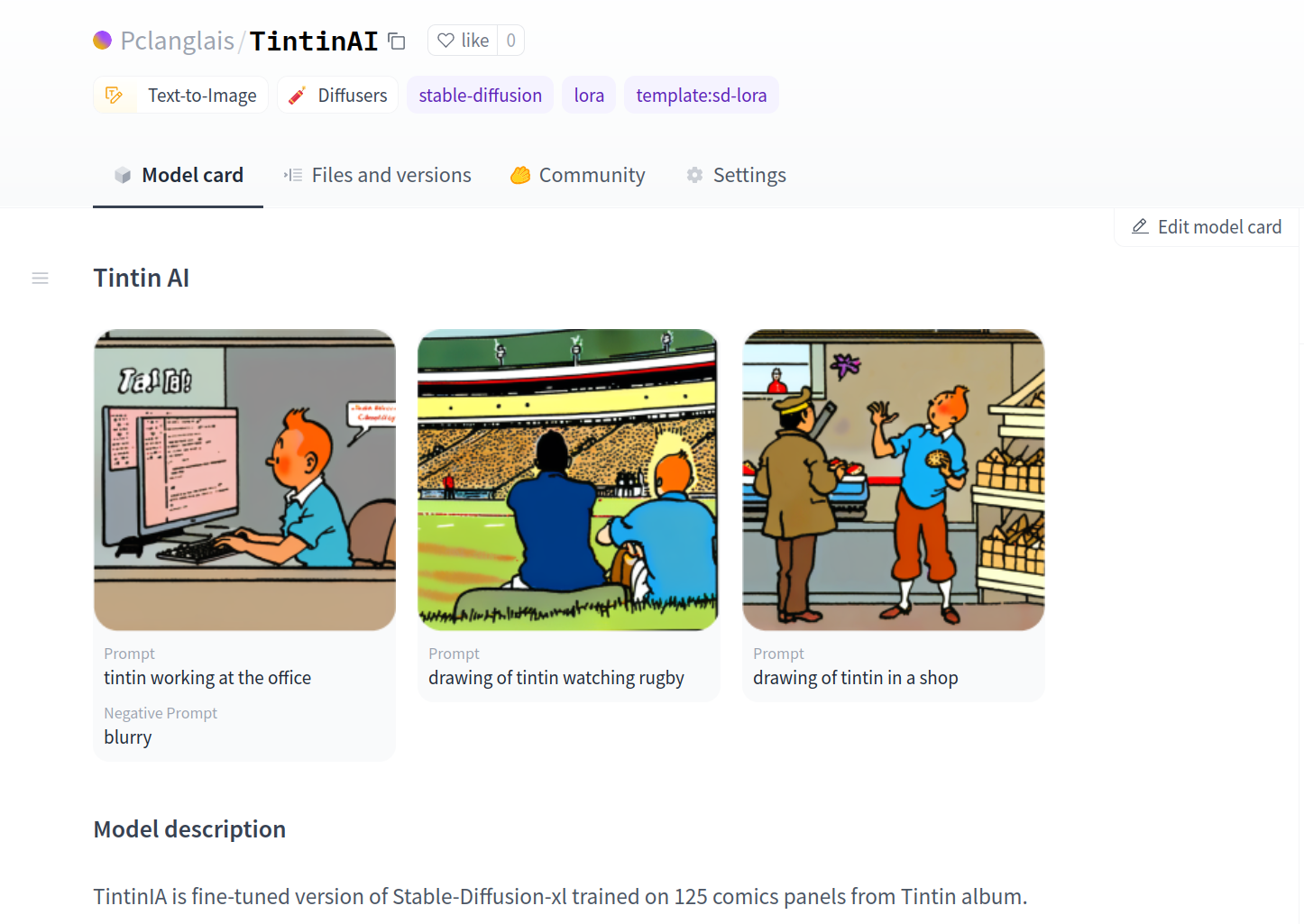
Widget Availability and Provider Support
Not all models have widgets available. Widget availability depends on:
- Task Support: The model’s task must be supported by at least one provider in the Inference Providers network
- Provider Availability: At least one provider must be serving the specific model
- Model Configuration: The model must have proper metadata and configuration files
To view the full list of supported tasks, check out our dedicated documentation page.
The list of all providers and the tasks they support is available in this documentation page.
For models without provider support, you can still showcase functionality using example outputs in your model card.
You can also click Ask for provider support directly on the model page to encourage providers to serve the model, given there is enough community interest.
Exploring Models with the Inference Playground
Before integrating models into your applications, you can test them interactively with the Inference Playground. The playground allows you to:
- Test different chat completion models with custom prompts
- Compare responses across different models
- Experiment with inference parameters like temperature, max tokens, and more
- Find the perfect model for your specific use case
The playground uses the same Inference Providers infrastructure that powers the widgets, so you can expect similar performance and capabilities when you integrate the models into your own applications.
