Hub documentation
Dataset Cards
Dataset Cards
What are Dataset Cards?
Each dataset may be documented by the README.md file in the repository. This file is called a dataset card, and the Hugging Face Hub will render its contents on the dataset’s main page. To inform users about how to responsibly use the data, it’s a good idea to include information about any potential biases within the dataset. Generally, dataset cards help users understand the contents of the dataset and give context for how the dataset should be used.
You can also add dataset metadata to your card. The metadata describes important information about a dataset such as its license, language, and size. It also contains tags to help users discover a dataset on the Hub, and data files configuration options. Tags are defined in a YAML metadata section at the top of the README.md file.
Dataset card metadata
A dataset repo will render its README.md as a dataset card. To control how the Hub displays the card, you should create a YAML section in the README file to define some metadata. Start by adding three --- at the top, then include all of the relevant metadata, and close the section with another group of --- like the example below:
language:
- "List of ISO 639-1 code for your language"
- lang1
- lang2
pretty_name: "Pretty Name of the Dataset"
tags:
- tag1
- tag2
license: "any valid license identifier"
task_categories:
- task1
- task2The metadata that you add to the dataset card enables certain interactions on the Hub. For example:
- Allow users to filter and discover datasets at https://huggingface.co/datasets.
- If you choose a license using the keywords listed in the right column of this table, the license will be displayed on the dataset page.
When creating a README.md file in a dataset repository on the Hub, use Metadata UI to fill the main metadata:
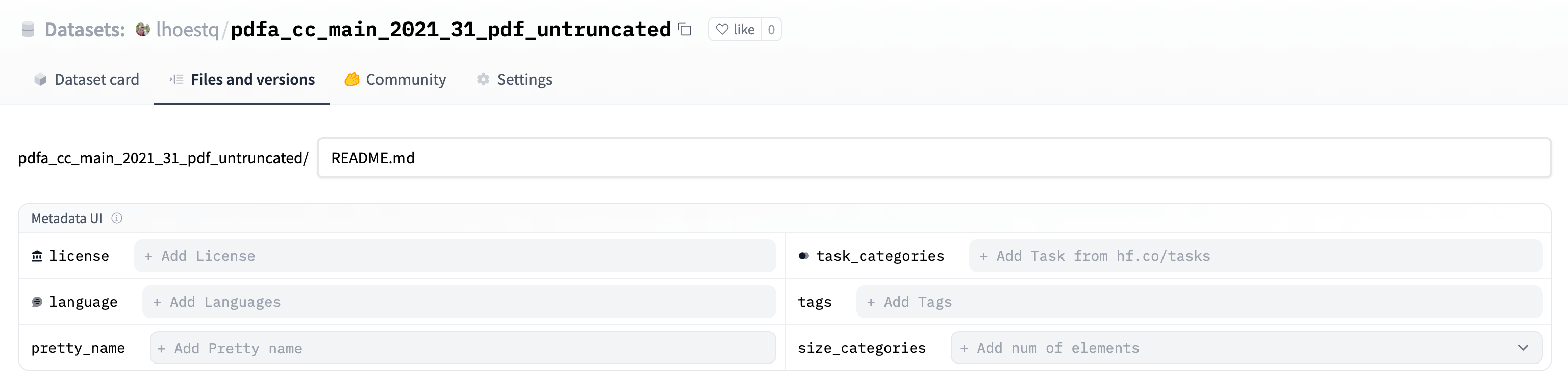

To see metadata fields, see the detailed Dataset Card specifications.
Dataset card creation guide
For a step-by-step guide on creating a dataset card, check out the Create a dataset card guide.
Reading through existing dataset cards, such as the ELI5 dataset card, is a great way to familiarize yourself with the common conventions.
Linking a Paper
If the dataset card includes a link to a paper on arXiv, the Hub will extract the arXiv ID and include it in the dataset tags with the format arxiv:<PAPER ID>. Clicking on the tag will let you:
- Visit the Paper page
- Filter for other models on the Hub that cite the same paper.
Read more about paper pages here.
Force set a dataset modality
The Hub will automatically detect the modality of a dataset based on the files it contains (audio, video, geospatial, etc.). If you want to force a specific modality, you can add a tag to the dataset card metadata: 3d, audio, geospatial, image, tabular, text, timeseries, video.
For example, to force the modality to audio, add the following to the dataset card metadata:
tags:
- audioAssociate a library to the dataset
The dataset page automatically shows libraries and tools that are able to natively load the dataset, but if you want to show another specific library, you can add a tag to the dataset card metadata: argilla, dask, datasets, distilabel, fiftyone, mlcroissant, pandas, webdataset. See the list of supported libraries for more information, or to propose to add a new library.
For example, to associate the argilla library to the dataset card, add the following to the dataset card metadata:
tags:
- argilla