Hub documentation
Data Studio
Data Studio
Each dataset page includes a table with the contents of the dataset, arranged by pages of 100 rows. You can navigate between pages using the buttons at the bottom of the table.


Inspect data distributions
At the top of the columns you can see the graphs representing the distribution of their data. This gives you a quick insight on how balanced your classes are, what are the range and distribution of numerical data and lengths of texts, and what portion of the column data is missing.
Filter by value
If you click on a bar of a histogram from a numerical column, the dataset viewer will filter the data and show only the rows with values that fall in the selected range. Similarly, if you select one class from a categorical column, it will show only the rows from the selected category.


Search a word in the dataset
You can search for a word in the dataset by typing it in the search bar at the top of the table. The search is case-insensitive and will match any row containing the word. The text is searched in the columns of string, even if the values are nested in a dictionary or a list.
Run SQL queries on the dataset
You can run SQL queries on the dataset in the browser using the SQL Console. This feature also leverages our auto-conversion to Parquet.


For more information see our guide on SQL Console.
Share a specific row
You can share a specific row by clicking on it, and then copying the URL in the address bar of your browser. For example https://huggingface.co/datasets/nyu-mll/glue/viewer/mrpc/test?p=2&row=241 will open the dataset studio on the MRPC dataset, on the test split, and on the 241st row.


Large scale datasets
The Dataset Viewer supports large scale datasets, but depending on the data format it may only show the first 5GB of the dataset:
- For Parquet datasets: the Dataset Viewer shows the full dataset, but sorting, filtering and search are only enabled on the first 5GB.
- For datasets >5GB in other formats (e.g. WebDataset or JSON Lines): the Dataset Viewer only shows the first 5GB, and sorting, filtering and search are enabled on these first 5GB.
In this case, an informational message lets you know that the Viewer is partial. This should be a large enough sample to represent the full dataset accurately, let us know if you need a bigger sample.
Access the parquet files
To power the dataset viewer, the first 5GB of every dataset are auto-converted to the Parquet format (unless it was already a Parquet dataset). In the dataset viewer (for example, see GLUE), you can click on “Auto-converted to Parquet” to access the Parquet files. Please, refer to the dataset viewer docs to learn how to query the dataset parquet files with libraries such as Polars, Pandas or DuckDB.
Parquet is a columnar storage format optimized for querying and processing large datasets. Parquet is a popular choice for big data processing and analytics and is widely used for data processing and machine learning. You can learn more about the advantages associated with this format in the documentation.
Conversion bot
When you create a new dataset, the parquet-converter bot notifies you once it converts the dataset to Parquet. The discussion it opens in the repository provides details about the Parquet format and links to the Parquet files.
Programmatic access
You can also access the list of Parquet files programmatically using the Hub API; for example, endpoint https://huggingface.co/api/datasets/nyu-mll/glue/parquet lists the parquet files of the nyu-mll/glue dataset.
We also have a specific documentation about the Dataset Viewer API, which you can call directly. That API lets you access the contents, metadata and basic statistics of all Hugging Face Hub datasets, and powers the Dataset viewer frontend.
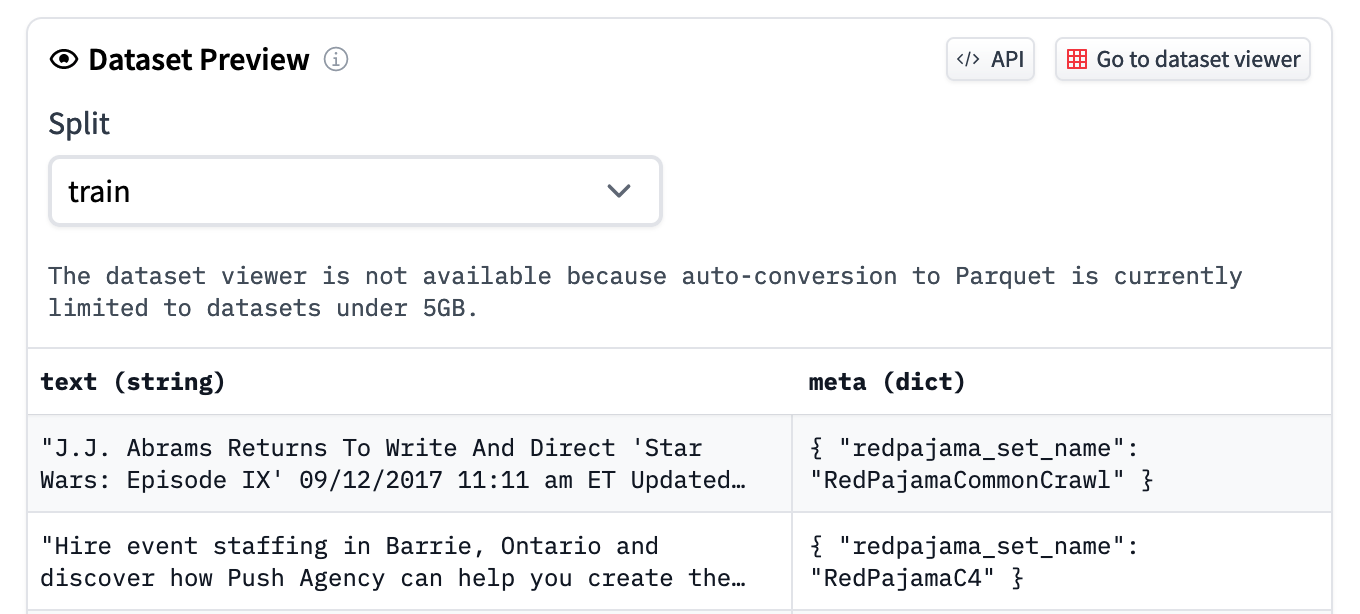
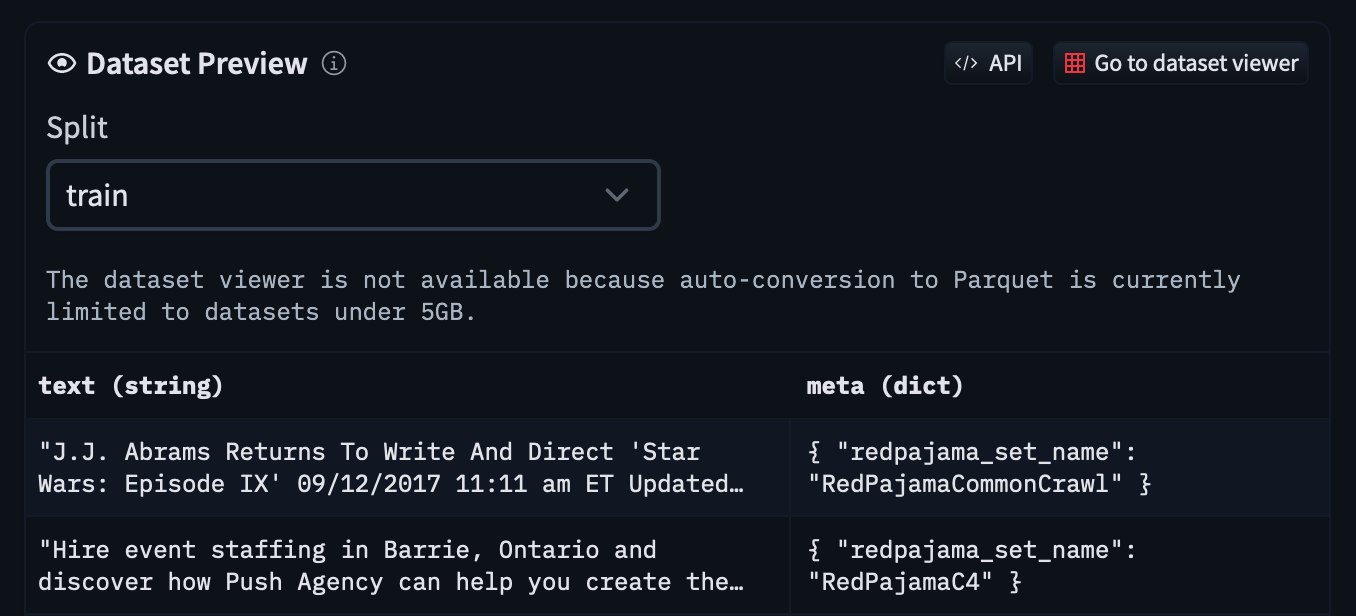
Dataset preview
For the biggest datasets, the page shows a preview of the first 100 rows instead of a full-featured viewer. This restriction only applies for datasets over 5GB that are not natively in Parquet format or that have not been auto-converted to Parquet.
Embed the Dataset Viewer in a webpage
You can embed the Dataset Viewer in your own webpage using an iframe. The URL to use is https://huggingface.co/datasets/<namespace>/<dataset-name>/embed/viewer, where <namespace> is the owner of the dataset and <dataset-name> is the name of the dataset. You can also pass other parameters like the subset, split, filter, search or selected row.
For more information see our guide on How to embed the Dataset Viewer in a webpage.
Configure the Dataset Viewer
To have a properly working Dataset Viewer for your dataset, make sure your dataset is in a supported format and structure. There is also an option to configure your dataset using YAML.
For private datasets, the Dataset Viewer is enabled for PRO users and Team or Enterprise organizations.
For more information see our guide on How to configure the Dataset Viewer.
Update on GitHub