Hub documentation
Model Cards
Model Cards
What are Model Cards?
Model cards are files that accompany the models and provide handy information. Under the hood, model cards are simple Markdown files with additional metadata. Model cards are essential for discoverability, reproducibility, and sharing! You can find a model card as the README.md file in any model repo.
The model card should describe:
- the model
- its intended uses & potential limitations, including biases and ethical considerations as detailed in Mitchell, 2018
- the training params and experimental info (you can embed or link to an experiment tracking platform for reference)
- which datasets were used to train your model
- the model’s evaluation results
The model card template is available here.
How to fill out each section of the model card is described in the Annotated Model Card.
Model Cards on the Hub have two key parts, with overlapping information:
Model card metadata
A model repo will render its README.md as a model card. The model card is a Markdown file, with a YAML section at the top that contains metadata about the model.
The metadata you add to the model card supports discovery and easier use of your model. For example:
- Allowing users to filter models at https://huggingface.co/models.
- Displaying the model’s license.
- Adding datasets to the metadata will add a message reading
Datasets used to train:to your model page and link the relevant datasets, if they’re available on the Hub.
Dataset, metric, and language identifiers are those listed on the Datasets, Metrics and Languages pages.
Adding metadata to your model card
There are a few different ways to add metadata to your model card including:
- Using the metadata UI
- Directly editing the YAML section of the
README.mdfile - Via the
huggingface_hubPython library, see the docs for more details.
Many libraries with Hub integration will automatically add metadata to the model card when you upload a model.
Using the metadata UI
You can add metadata to your model card using the metadata UI. To access the metadata UI, go to the model page and click on the Edit model card button in the top right corner of the model card. This will open an editor showing the model card README.md file, as well as a UI for editing the metadata.
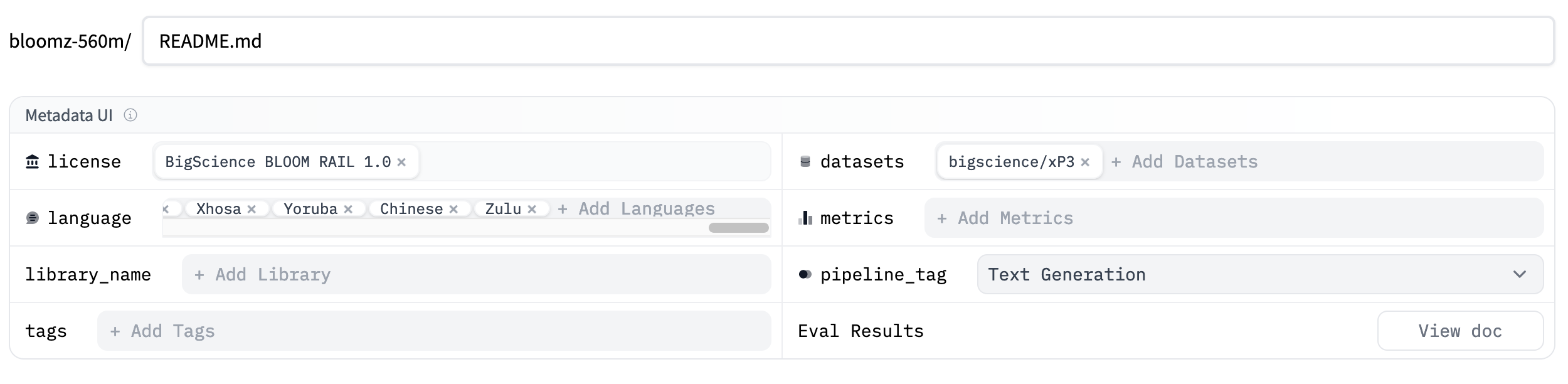
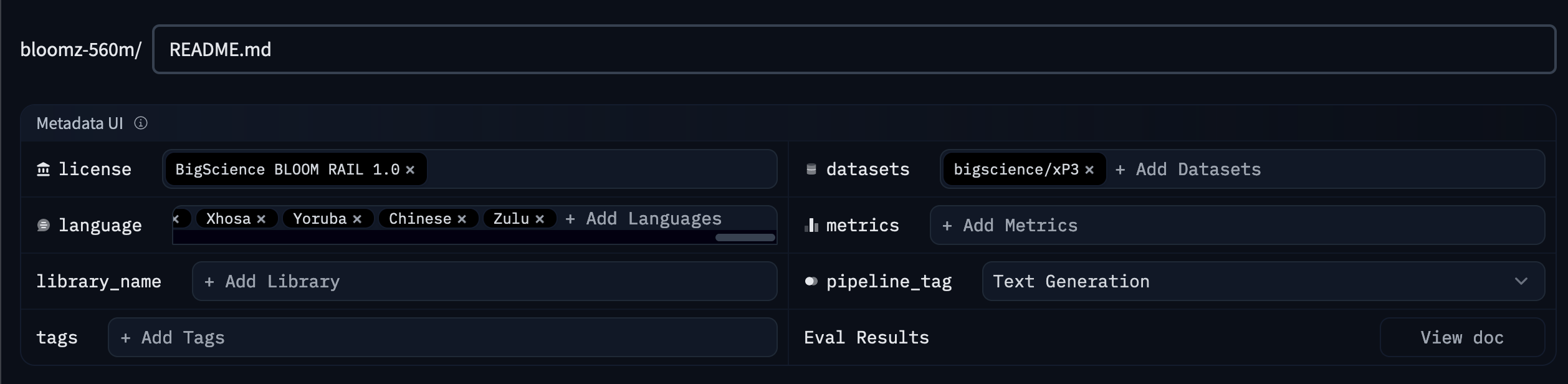
This UI will allow you to add key metadata to your model card and many of the fields will autocomplete based on the information you provide. Using the UI is the easiest way to add metadata to your model card, but it doesn’t support all of the metadata fields. If you want to add metadata that isn’t supported by the UI, you can edit the YAML section of the README.md file directly.
Editing the YAML section of the README.md file
You can also directly edit the YAML section of the README.md file. If the model card doesn’t already have a YAML section, you can add one by adding three --- at the top of the file, then include all of the relevant metadata, and close the section with another group of --- like the example below:
---
language:
- "List of ISO 639-1 code for your language"
- lang1
- lang2
thumbnail: "url to a thumbnail used in social sharing"
tags:
- tag1
- tag2
license: "any valid license identifier"
datasets:
- dataset1
- dataset2
metrics:
- metric1
- metric2
base_model: "base model Hub identifier"
---You can find the detailed model card metadata specification here.
Specifying a library
You can specify the supported libraries in the model card metadata section. Find more about our supported libraries here. The library will be specified in the following order of priority:
- Specifying
library_namein the model card (recommended if your model is not atransformersmodel). This information can be added via the metadata UI or directly in the model card YAML section:
library_name: flair- Having a tag with the name of a library that is supported
tags:
- flairIf it’s not specified, the Hub will try to automatically detect the library type. However, this approach is discouraged, and repo creators should use the explicit library_name as much as possible.
- By looking into the presence of files such as
*.nemoor*.mlmodel, the Hub can determine if a model is from NeMo or CoreML. - In the past, if nothing was detected and there was a
config.jsonfile, it was assumed the library wastransformers. For model repos created after August 2024, this is not the case anymore – so you need tolibrary_name: transformersexplicitly.
Specifying a base model
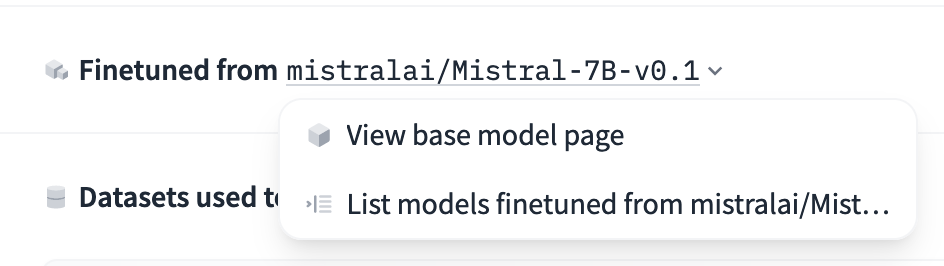
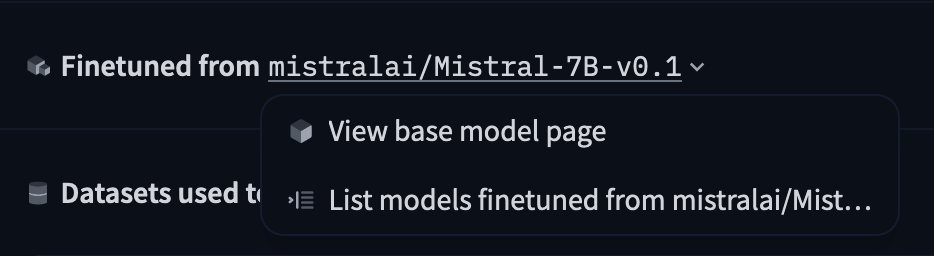
If your model is a fine-tune, an adapter, or a quantized version of a base model, you can specify the base model in the model card metadata section. This information can also be used to indicate if your model is a merge of multiple existing models. Hence, the base_model field can either be a single model ID, or a list of one or more base_models (specified by their Hub identifiers).
base_model: HuggingFaceH4/zephyr-7b-betaThis metadata will be used to display the base model on the model page. Users can also use this information to filter models by base model or find models that are derived from a specific base model:
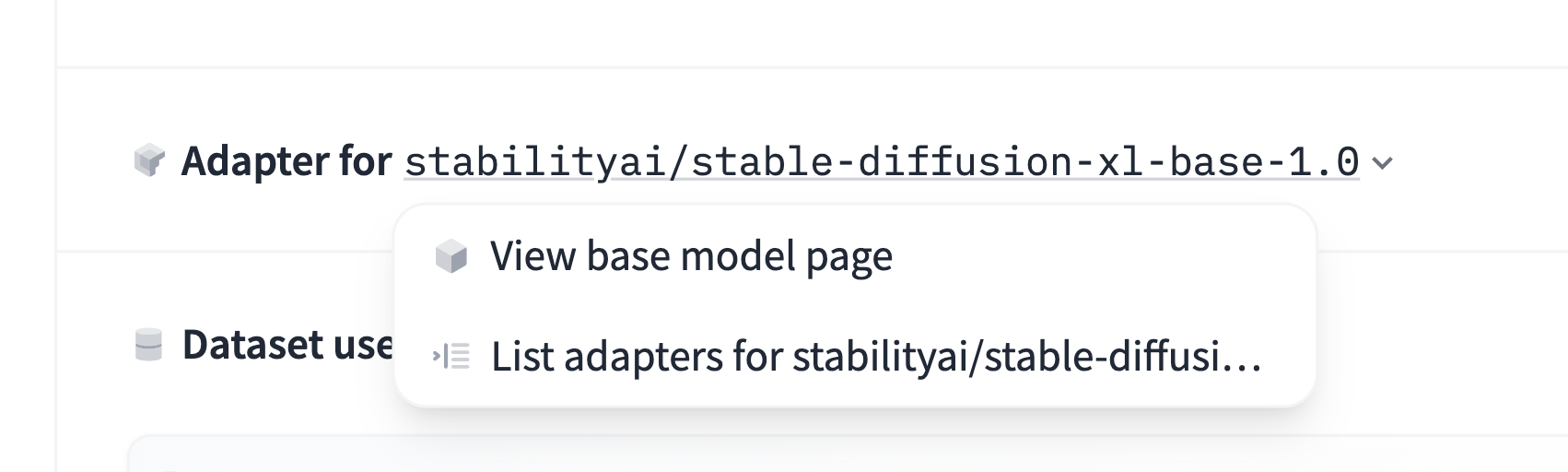
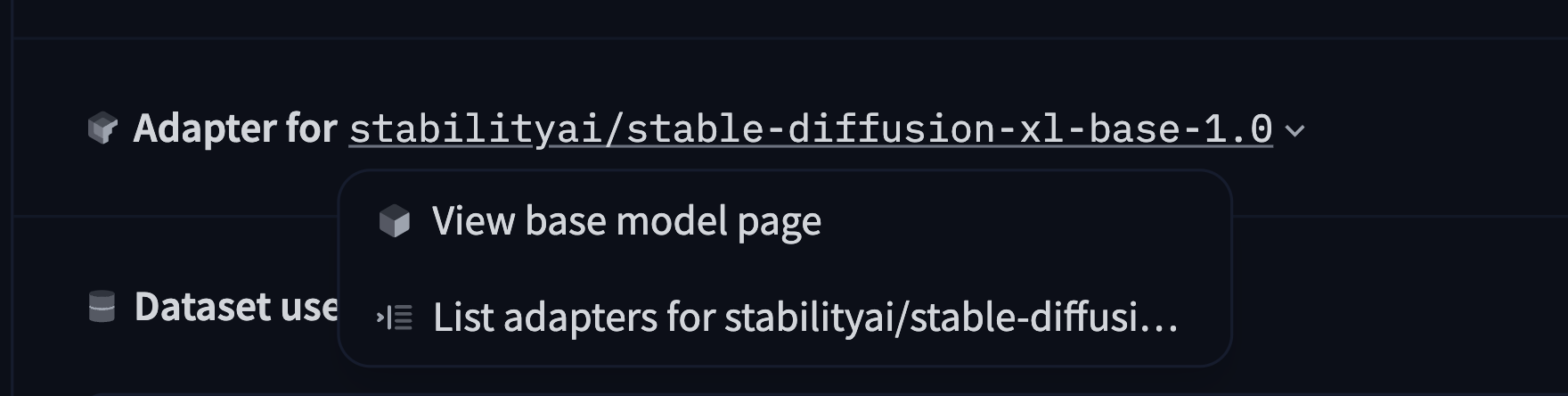
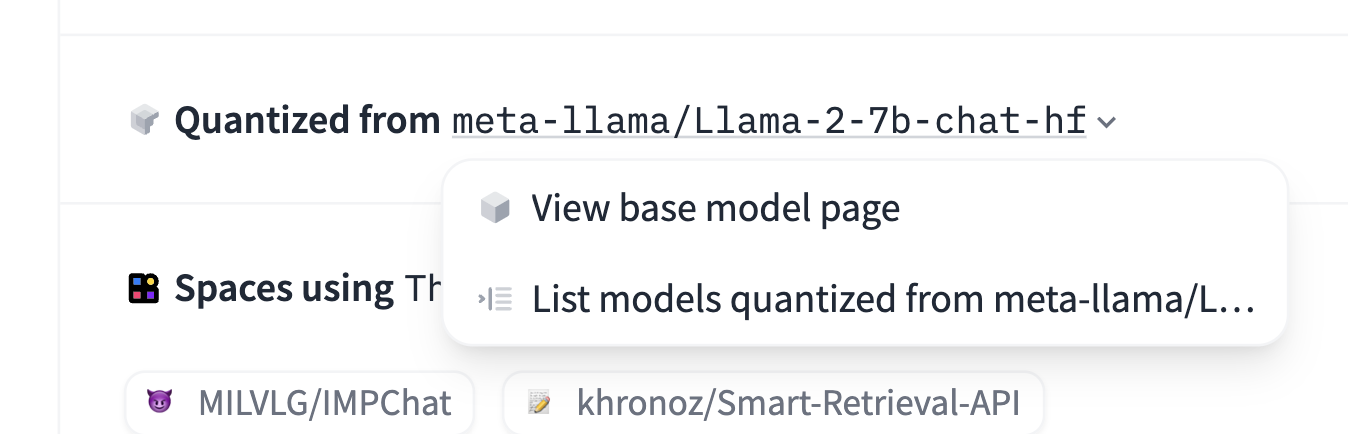

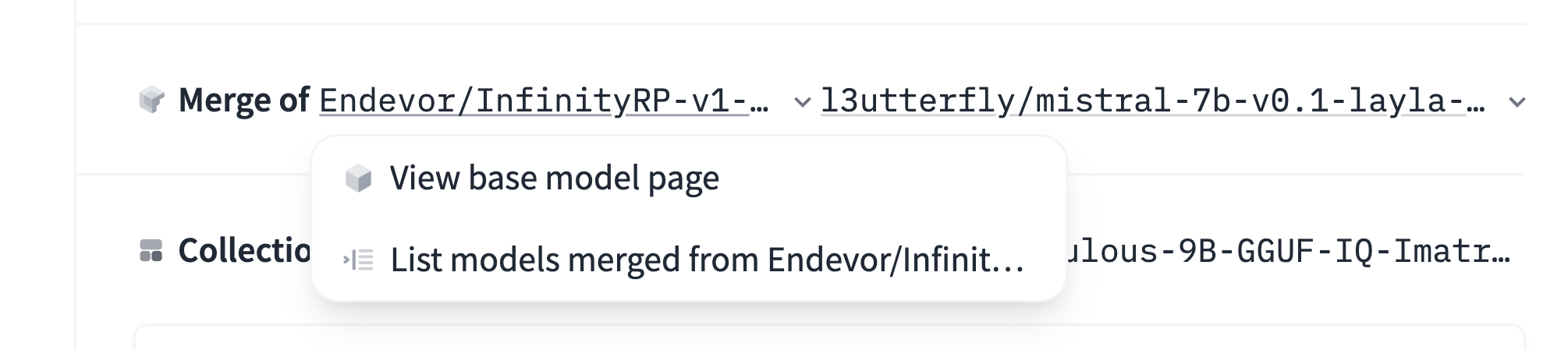
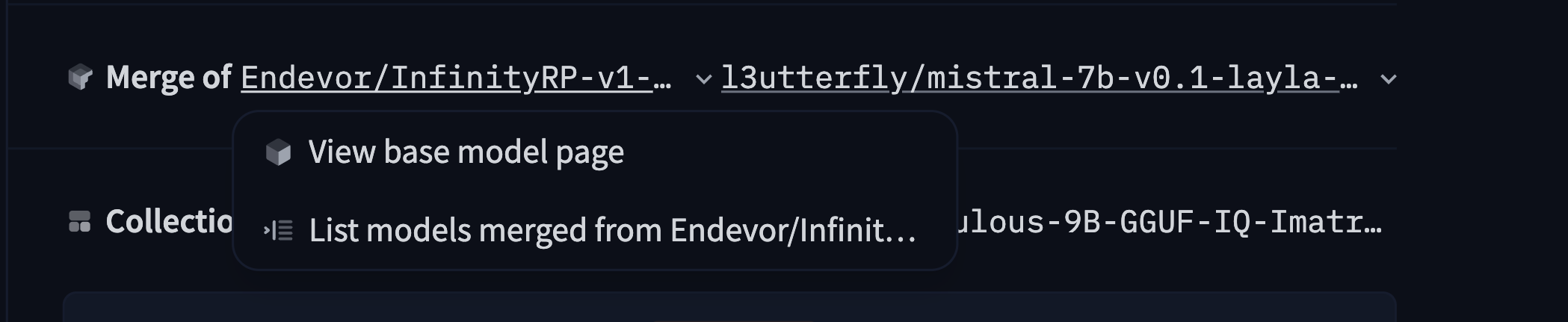
In the merge case, you specify a list of two or more base_models:
base_model:
- Endevor/InfinityRP-v1-7B
- l3utterfly/mistral-7b-v0.1-layla-v4The Hub will infer the type of relationship from the current model to the base model ("adapter", "merge", "quantized", "finetune") but you can also set it explicitly if needed: base_model_relation: quantized for instance.
Specifying a new version
If a new version of your model is available in the Hub, you can specify it in a new_version field.
For example, on l3utterfly/mistral-7b-v0.1-layla-v3:
new_version: l3utterfly/mistral-7b-v0.1-layla-v4This metadata will be used to display a link to the latest version of a model on the model page. If the model linked in new_version also has a new_version field, the very latest version will always be displayed.


Specifying a dataset
You can specify the datasets used to train your model in the model card metadata section. The datasets will be displayed on the model page and users will be able to filter models by dataset. You should use the Hub dataset identifier, which is the same as the dataset’s repo name as the identifier:
datasets:
- imdb
- HuggingFaceH4/no_robotsSpecifying a task ( pipeline_tag )
You can specify the pipeline_tag in the model card metadata. The pipeline_tag indicates the type of task the model is intended for. This tag will be displayed on the model page and users can filter models on the Hub by task. This tag is also used to determine which widget to use for the model and which APIs to use under the hood.
For transformers models, the pipeline tag is automatically inferred from the model’s config.json file but you can override it in the model card metadata if required. Editing this field in the metadata UI will ensure that the pipeline tag is valid. Some other libraries with Hub integration will also automatically add the pipeline tag to the model card metadata.
Specifying a license
You can specify the license in the model card metadata section. The license will be displayed on the model page and users will be able to filter models by license. Using the metadata UI, you will see a dropdown of the most common licenses.
If required, you can also specify a custom license by adding other as the license value and specifying the name and a link to the license in the metadata.
# Example from https://huggingface.co/coqui/XTTS-v1
---
license: other
license_name: coqui-public-model-license
license_link: https://coqui.ai/cpml
---If the license is not available via a URL you can link to a LICENSE stored in the model repo.
Evaluation Results
You can specify your model’s evaluation results in a structured way in the model card metadata. Results are parsed by the Hub and displayed in a widget on the model page. Here is an example on how it looks like for the bigcode/starcoder model:
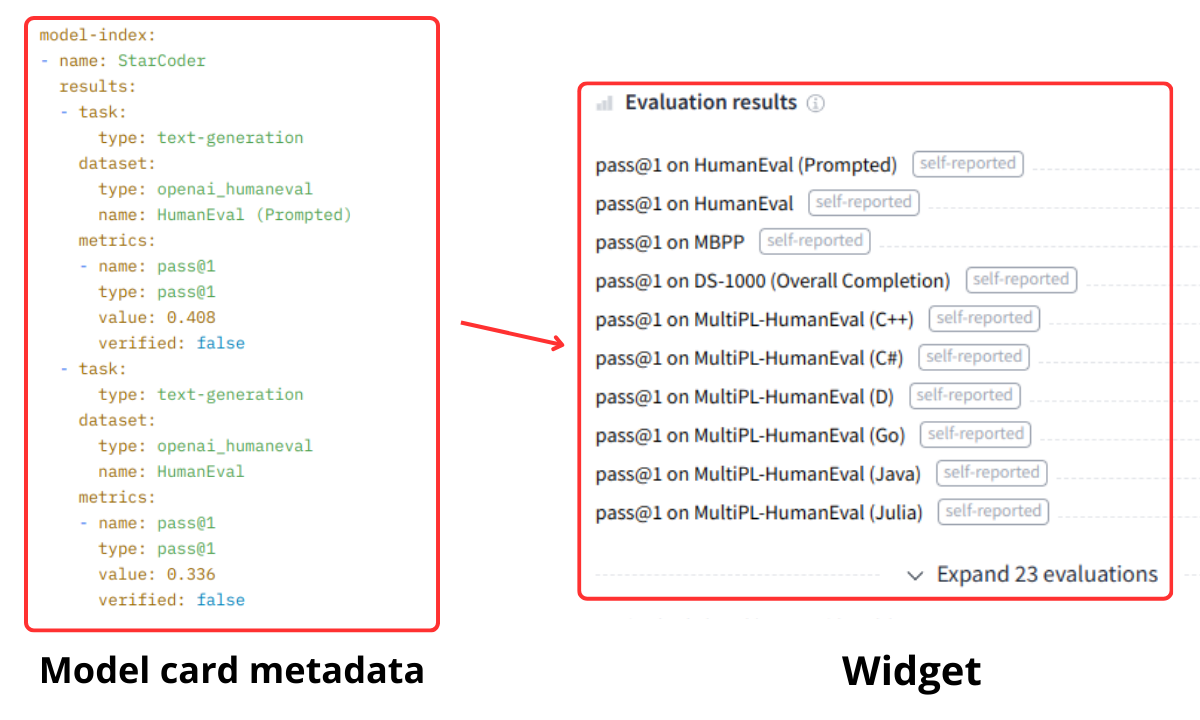

The metadata spec was based on Papers with code’s model-index specification. This allow us to directly index the results into Papers with code’s leaderboards when appropriate. You can also link the source from where the eval results has been computed.
Here is a partial example to describe 01-ai/Yi-34B’s score on the ARC benchmark. The result comes from the Open LLM Leaderboard which is defined as the source:
---
model-index:
- name: Yi-34B
results:
- task:
type: text-generation
dataset:
name: ai2_arc
type: ai2_arc
metrics:
- name: AI2 Reasoning Challenge (25-Shot)
type: AI2 Reasoning Challenge (25-Shot)
value: 64.59
source:
name: Open LLM Leaderboard
url: https://huggingface.co/spaces/open-llm-leaderboard/open_llm_leaderboard
---For more details on how to format this data, check out the Model Card specifications.
CO2 Emissions
The model card is also a great place to show information about the CO2 impact of your model. Visit our guide on tracking and reporting CO2 emissions to learn more.
Linking a Paper
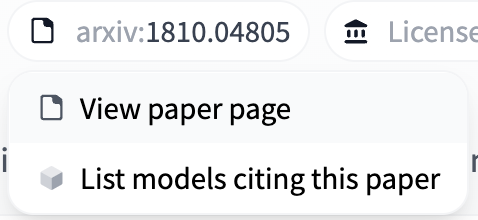
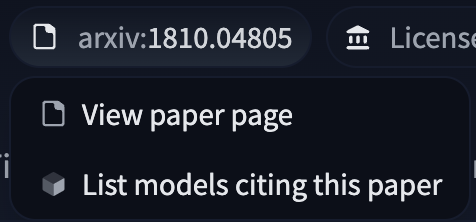
If the model card includes a link to a paper on arXiv, the Hugging Face Hub will extract the arXiv ID and include it in the model tags with the format arxiv:<PAPER ID>. Clicking on the tag will let you:
- Visit the Paper page
- Filter for other models on the Hub that cite the same paper.
Read more about Paper pages here.
Model Card text
Details on how to fill out a human-readable model card without Hub-specific metadata (so that it may be printed out, cut+pasted, etc.) is available in the Annotated Model Card.
FAQ
How are model tags determined?
Each model page lists all the model’s tags in the page header, below the model name. These are primarily computed from the model card metadata, although some are added automatically, as described in Enabling a Widget.
Can I add custom tags to my model?
Yes, you can add custom tags to your model by adding them to the tags field in the model card metadata. The metadata UI will suggest some popular tags, but you can add any tag you want. For example, you could indicate that your model is focused on finance by adding a finance tag.
How can I indicate that my model is not suitable for all audiences
You can add a not-for-all-audience tag to your model card metadata. When this tag is present, a message will be displayed on the model page indicating that the model is not for all audiences. Users can click through this message to view the model card.
Can I write LaTeX in my model card?
Yes! The Hub uses the KaTeX math typesetting library to render math formulas server-side before parsing the Markdown.
You have to use the following delimiters:
$$ ... $$for display mode\\(...\\)for inline mode (no space between the slashes and the parenthesis).
Then you’ll be able to write:
Update on GitHub