Transformers documentation
GPT-NeoX
This model was released on 2022-04-14 and added to Hugging Face Transformers on 2022-05-24.
GPT-NeoX
Overview
We introduce GPT-NeoX-20B, a 20 billion parameter autoregressive language model trained on the Pile, whose weights will be made freely and openly available to the public through a permissive license. It is, to the best of our knowledge, the largest dense autoregressive model that has publicly available weights at the time of submission. In this work, we describe GPT-NeoX-20B’s architecture and training and evaluate its performance on a range of language-understanding, mathematics, and knowledge-based tasks. We find that GPT-NeoX-20B is a particularly powerful few-shot reasoner and gains far more in performance when evaluated five-shot than similarly sized GPT-3 and FairSeq models. We open-source the training and evaluation code, as well as the model weights, at https://github.com/EleutherAI/gpt-neox.
Development of the model was led by Sid Black, Stella Biderman and Eric Hallahan, and the model was trained with generous the support of CoreWeave.
GPT-NeoX-20B was trained with fp16, thus it is recommended to initialize the model as follows:
model = GPTNeoXForCausalLM.from_pretrained("EleutherAI/gpt-neox-20b", device_map="auto", dtype=torch.float16)GPT-NeoX-20B also has a different tokenizer from the one used in GPT-J-6B and GPT-Neo. The new tokenizer allocates additional tokens to whitespace characters, making the model more suitable for certain tasks like code generation.
Usage example
The generate() method can be used to generate text using GPT Neo model.
>>> from transformers import GPTNeoXForCausalLM, GPTNeoXTokenizerFast
>>> model = GPTNeoXForCausalLM.from_pretrained("EleutherAI/gpt-neox-20b")
>>> tokenizer = GPTNeoXTokenizerFast.from_pretrained("EleutherAI/gpt-neox-20b")
>>> prompt = "GPTNeoX20B is a 20B-parameter autoregressive Transformer model developed by EleutherAI."
>>> input_ids = tokenizer(prompt, return_tensors="pt").input_ids
>>> gen_tokens = model.generate(
... input_ids,
... do_sample=True,
... temperature=0.9,
... max_length=100,
... )
>>> gen_text = tokenizer.batch_decode(gen_tokens)[0]Using Flash Attention 2
Flash Attention 2 is an faster, optimized version of the model.
Installation
First, check whether your hardware is compatible with Flash Attention 2. The latest list of compatible hardware can be found in the official documentation.
Next, install the latest version of Flash Attention 2:
pip install -U flash-attn --no-build-isolation
Usage
To load a model using Flash Attention 2, we can pass the argument attn_implementation="flash_attention_2" to .from_pretrained. We’ll also load the model in half-precision (e.g. torch.float16), since it results in almost no degradation to audio quality but significantly lower memory usage and faster inference:
>>> from transformers import GPTNeoXForCausalLM, GPTNeoXTokenizerFast
model = GPTNeoXForCausalLM.from_pretrained("EleutherAI/gpt-neox-20b", dtype=torch.float16, attn_implementation="flash_attention_2").to(device)
...Expected speedups
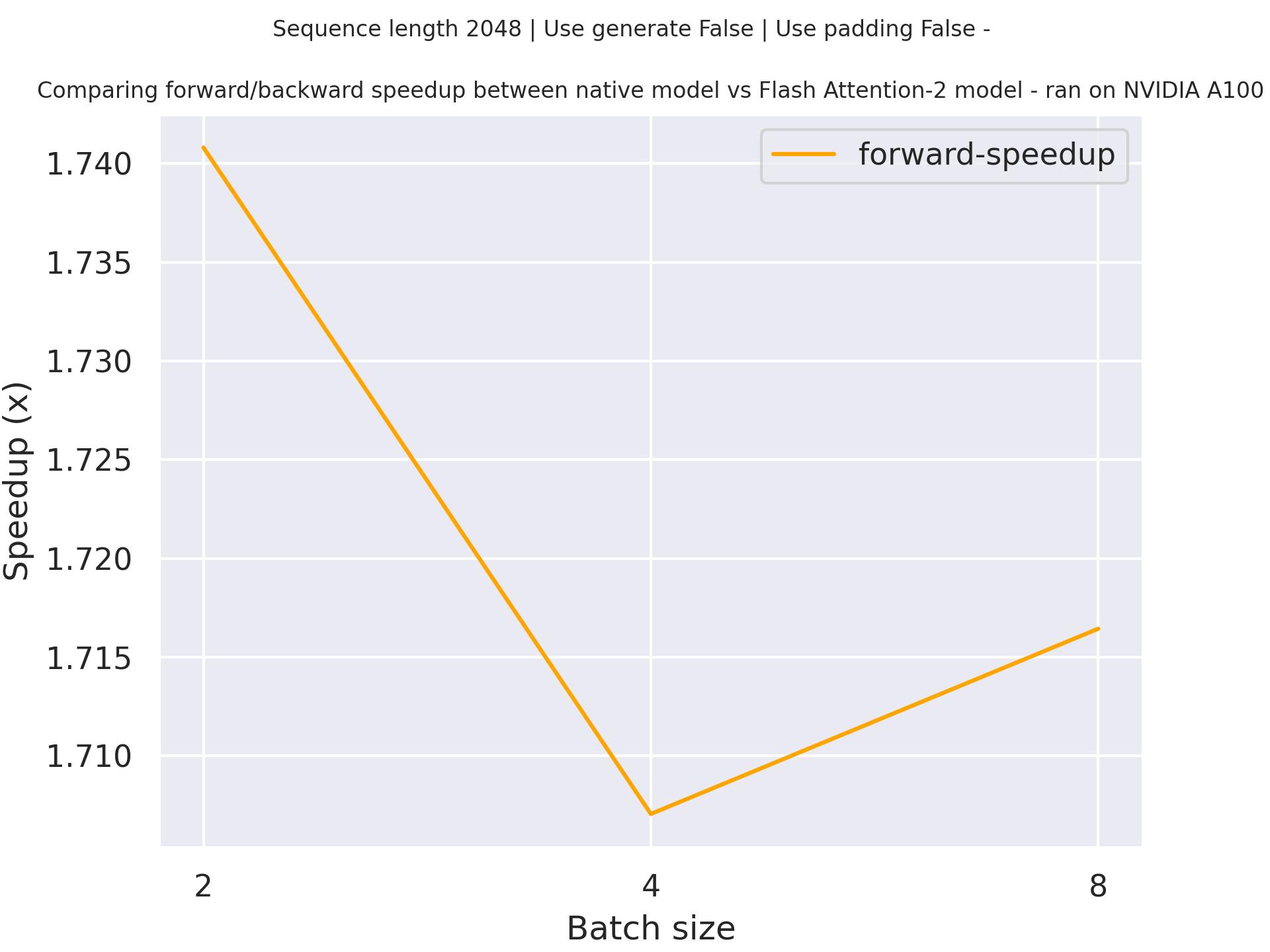
Below is an expected speedup diagram that compares pure inference time between the native implementation in transformers using stockmark/gpt-neox-japanese-1.4b checkpoint and the Flash Attention 2 version of the model using a sequence length of 2048.
Using Scaled Dot Product Attention (SDPA)
PyTorch includes a native scaled dot-product attention (SDPA) operator as part of torch.nn.functional. This function
encompasses several implementations that can be applied depending on the inputs and the hardware in use. See the
official documentation
or the GPU Inference
page for more information.
SDPA is used by default for torch>=2.1.1 when an implementation is available, but you may also set
attn_implementation="sdpa" in from_pretrained() to explicitly request SDPA to be used.
from transformers import GPTNeoXForCausalLM
model = GPTNeoXForCausalLM.from_pretrained("EleutherAI/gpt-neox-20b", dtype=torch.float16, attn_implementation="sdpa")
...For the best speedups, we recommend loading the model in half-precision (e.g. torch.float16 or torch.bfloat16).
On a local benchmark (rtx3080ti-16GB, PyTorch 2.2.1, OS Ubuntu 22.04) using float16 with
pythia-410m-deduped, we saw the
following speedups during training and inference.
Training
| Batch size | Seq len | Time per batch (Eager - s) | Time per batch (SDPA - s) | Speedup (%) | Eager peak mem (MB) | SDPA peak mem (MB) | Mem saving (%) |
|---|---|---|---|---|---|---|---|
| 1 | 128 | 0.024 | 0.019 | 28.945 | 1789.95 | 1789.95 | 0 |
| 1 | 256 | 0.039 | 0.031 | 23.18 | 1845.83 | 1844.84 | 0.053 |
| 1 | 512 | 0.08 | 0.055 | 45.524 | 2278.38 | 1953.76 | 16.615 |
| 1 | 1024 | 0.19 | 0.102 | 86.777 | 4772.36 | 2408.35 | 98.159 |
| 1 | 2048 | 0.565 | 0.204 | 177.098 | 13484.1 | 3882.01 | 247.348 |
| 2 | 128 | 0.037 | 0.032 | 15.121 | 1843.86 | 1844.78 | -0.05 |
| 2 | 256 | 0.067 | 0.055 | 21.706 | 1999.72 | 1951.67 | 2.462 |
| 2 | 512 | 0.144 | 0.096 | 50.046 | 3613.16 | 2406.77 | 50.125 |
| 2 | 1024 | 0.366 | 0.193 | 89.666 | 8707.55 | 3878.86 | 124.487 |
| 2 | 2048 | OOM | 0.379 | / | OOM | 6825.13 | SDPA does not OOM |
| 4 | 128 | 0.06 | 0.054 | 11.539 | 1947.6 | 1952.06 | -0.228 |
| 4 | 256 | 0.119 | 0.093 | 28.072 | 3008.39 | 2405.99 | 25.038 |
| 4 | 512 | 0.275 | 0.187 | 47.145 | 6290.58 | 3877.29 | 62.242 |
| 4 | 1024 | OOM | 0.36 | / | OOM | 6821.98 | SDPA does not OOM |
| 4 | 2048 | OOM | 0.731 | / | OOM | 12705.1 | SDPA does not OOM |
Inference
| Batch size | Seq len | Per token latency Eager (ms) | Per token latency SDPA (ms) | Speedup (%) | Mem Eager (MB) | Mem SDPA (MB) | Mem saved (%) |
|---|---|---|---|---|---|---|---|
| 1 | 128 | 6.569 | 5.858 | 12.14 | 974.831 | 974.826 | 0 |
| 1 | 256 | 7.009 | 5.863 | 19.542 | 1029.01 | 1028.08 | 0.09 |
| 1 | 512 | 7.157 | 5.965 | 19.983 | 1137.54 | 1137.52 | 0.001 |
| 1 | 1024 | 7.523 | 6.506 | 15.637 | 1329.3 | 1329.26 | 0.003 |
| 1 | 2048 | 9.271 | 9.205 | 0.713 | 1752.47 | 1734.51 | 1.036 |
| 2 | 128 | 7.239 | 5.959 | 21.493 | 1044.8 | 1028.37 | 1.597 |
| 2 | 256 | 7.228 | 6.036 | 19.757 | 1167.32 | 1137.73 | 2.601 |
| 2 | 512 | 7.538 | 6.693 | 12.628 | 1352.93 | 1329.55 | 1.758 |
| 2 | 1024 | 8.916 | 8.632 | 3.291 | 1752.56 | 1734.62 | 1.034 |
| 2 | 2048 | 12.628 | 12.606 | 0.181 | 2558.72 | 2545.8 | 0.508 |
| 4 | 128 | 7.278 | 6.046 | 20.373 | 1168.41 | 1137.79 | 2.691 |
| 4 | 256 | 7.614 | 6.588 | 15.574 | 1353.1 | 1329.79 | 1.753 |
| 4 | 512 | 8.798 | 8.144 | 8.028 | 1752.76 | 1734.85 | 1.032 |
| 4 | 1024 | 11.765 | 11.303 | 4.09 | 2558.96 | 2546.04 | 0.508 |
| 4 | 2048 | 19.568 | 17.735 | 10.33 | 4175.5 | 4165.26 | 0.246 |
Resources
GPTNeoXConfig
class transformers.GPTNeoXConfig
< source >( vocab_size: typing.Optional[int] = 50432 hidden_size: typing.Optional[int] = 6144 num_hidden_layers: typing.Optional[int] = 44 num_attention_heads: typing.Optional[int] = 64 intermediate_size: typing.Optional[int] = 24576 hidden_act: typing.Optional[str] = 'gelu' attention_dropout: typing.Optional[float] = 0.0 hidden_dropout: typing.Optional[float] = 0.0 classifier_dropout: typing.Optional[float] = 0.1 max_position_embeddings: typing.Optional[int] = 2048 initializer_range: typing.Optional[float] = 0.02 layer_norm_eps: typing.Optional[int] = 1e-05 use_cache: typing.Optional[bool] = True bos_token_id: typing.Optional[int] = 0 eos_token_id: typing.Optional[int] = 2 tie_word_embeddings: typing.Optional[bool] = False use_parallel_residual: typing.Optional[bool] = True rope_parameters: typing.Union[transformers.modeling_rope_utils.RopeParameters, dict[str, transformers.modeling_rope_utils.RopeParameters], NoneType] = None attention_bias: typing.Optional[bool] = True **kwargs )
Parameters
- vocab_size (
int, optional, defaults to 50432) — Vocabulary size of the GPTNeoX model. Defines the number of different tokens that can be represented by theinputs_idspassed when calling GPTNeoXModel. - hidden_size (
int, optional, defaults to 6144) — Dimension of the encoder layers and the pooler layer. - num_hidden_layers (
int, optional, defaults to 44) — Number of hidden layers in the Transformer encoder. - num_attention_heads (
int, optional, defaults to 64) — Number of attention heads for each attention layer in the Transformer encoder. - intermediate_size (
int, optional, defaults to 24576) — Dimension of the “intermediate” (i.e., feed-forward) layer in the Transformer encoder. - hidden_act (
strorfunction, optional, defaults to"gelu") — The non-linear activation function (function or string) in the encoder and pooler. If string,"gelu","relu","selu"and"gelu_new"are supported. - attention_dropout (
float, optional, defaults to 0.0) — The dropout ratio probability of the attention score. - hidden_dropout (
float, optional, defaults to 0.0) — The dropout ratio of (1) the word embeddings, (2) the post-attention hidden states, and (3) the post-mlp hidden states. - classifier_dropout (
float, optional, defaults to 0.1) — Argument used when doing token classification, used in the model GPTNeoXForTokenClassification. The dropout ratio for the c;assifier head. - max_position_embeddings (
int, optional, defaults to 2048) — The maximum sequence length that this model might ever be used with. Typically set this to something large just in case (e.g., 512 or 1024 or 2048). - initializer_range (
float, optional, defaults to 1e-5) — The standard deviation of the truncated_normal_initializer for initializing all weight matrices. - layer_norm_eps (
float, optional, defaults to 1e-12) — The epsilon used by the layer normalization layers. - use_cache (
bool, optional, defaults toTrue) — Whether or not the model should return the last key/values attentions (not used by all models). Only relevant ifconfig.is_decoder=True. - use_parallel_residual (
bool, optional, defaults toTrue) — Whether to use a “parallel” formulation in each Transformer layer, which can provide a slight training speedup at large scales (e.g. 20B). - rope_parameters (
RopeParameters, optional) — Dictionary containing the configuration parameters for the RoPE embeddings. The dictionary should contain a value forrope_thetaand optionally parameters used for scaling in case you want to use RoPE with longermax_position_embeddings. - attention_bias (
bool, optional, defaults toTrue) — Whether to use a bias in the query, key, value and output projection layers during self-attention. - Example —
This is the configuration class to store the configuration of a GPTNeoXModel. It is used to instantiate an GPTNeoX model according to the specified arguments, defining the model architecture. Instantiating a configuration with the defaults will yield a similar configuration to that of the GPTNeoX EleutherAI/gpt-neox-20b architecture.
Configuration objects inherit from PreTrainedConfig and can be used to control the model outputs. Read the documentation from PreTrainedConfig for more information.
>>> from transformers import GPTNeoXConfig, GPTNeoXModel
>>> # Initializing a GPTNeoX gpt-neox-20b style configuration
>>> configuration = GPTNeoXConfig()
>>> # Initializing a model (with random weights) from the gpt-neox-20b style configuration
>>> model = GPTNeoXModel(configuration)
>>> # Accessing the model configuration
>>> configuration = model.configGPTNeoXTokenizer
class transformers.GPTNeoXTokenizer
< source >( errors: str = 'replace' unk_token: str = '<|endoftext|>' bos_token: str = '<|endoftext|>' eos_token: str = '<|endoftext|>' pad_token: str = '<|padding|>' add_bos_token: bool = False add_eos_token: bool = False add_prefix_space: bool = False trim_offsets: bool = True vocab: typing.Optional[dict] = None merges: typing.Optional[list] = None **kwargs )
Parameters
- vocab_file (
str, optional) — Path to the vocabulary file. - merges_file (
str, optional) — Path to the merges file. - tokenizer_file (
str, optional) — Path to a tokenizers JSON file containing the serialization of a tokenizer. - errors (
str, optional, defaults to"replace") — Paradigm to follow when decoding bytes to UTF-8. See bytes.decode for more information. - unk_token (
str, optional, defaults to"<|endoftext|>") — The unknown token. A token that is not in the vocabulary cannot be converted to an ID and is set to be this token instead. - bos_token (
str, optional, defaults to"<|endoftext|>") — The beginning of sequence token. - eos_token (
str, optional, defaults to"<|endoftext|>") — The end of sequence token. - pad_token (
str, optional, defaults to"<|padding|>") — Token for padding a sequence. - add_prefix_space (
bool, optional, defaults toFalse) — Whether or not to add an initial space to the input. This allows to treat the leading word just as any other word. (GPTNeoX tokenizer detect beginning of words by the preceding space). - add_bos_token (
bool, optional, defaults toFalse) — Whether or not to add abos_tokenat the start of sequences. - add_eos_token (
bool, optional, defaults toFalse) — Whether or not to add aneos_tokenat the end of sequences. - trim_offsets (
bool, optional, defaults toTrue) — Whether or not the post-processing step should trim offsets to avoid including whitespaces. - vocab (
dict, optional) — Custom vocabulary dictionary. If not provided, vocabulary is loaded from vocab_file. - merges (
list, optional) — Custom merges list. If not provided, merges are loaded from merges_file.
Construct a GPT-NeoX-20B tokenizer (backed by HuggingFace’s tokenizers library). Based on byte-level Byte-Pair-Encoding.
This tokenizer has been trained to treat spaces like parts of the tokens (a bit like sentencepiece) so a word will
be encoded differently whether it is at the beginning of the sentence (without space) or not:
>>> from transformers import GPTNeoXTokenizer
>>> tokenizer = GPTNeoXTokenizer.from_pretrained("EleutherAI/gpt-neox-20b")
>>> tokenizer("Hello world")["input_ids"]
[15496, 995]
>>> tokenizer(" Hello world")["input_ids"]
[18435, 995]You can get around that behavior by passing add_prefix_space=True when instantiating this tokenizer, but since
the model was not pretrained this way, it might yield a decrease in performance.
When used with
is_split_into_words=True, this tokenizer needs to be instantiated withadd_prefix_space=True.
This tokenizer inherits from TokenizersBackend which contains most of the main methods. Users should refer to this superclass for more information regarding those methods.
GPTNeoXTokenizerFast
class transformers.GPTNeoXTokenizer
< source >( errors: str = 'replace' unk_token: str = '<|endoftext|>' bos_token: str = '<|endoftext|>' eos_token: str = '<|endoftext|>' pad_token: str = '<|padding|>' add_bos_token: bool = False add_eos_token: bool = False add_prefix_space: bool = False trim_offsets: bool = True vocab: typing.Optional[dict] = None merges: typing.Optional[list] = None **kwargs )
Parameters
- vocab_file (
str, optional) — Path to the vocabulary file. - merges_file (
str, optional) — Path to the merges file. - tokenizer_file (
str, optional) — Path to a tokenizers JSON file containing the serialization of a tokenizer. - errors (
str, optional, defaults to"replace") — Paradigm to follow when decoding bytes to UTF-8. See bytes.decode for more information. - unk_token (
str, optional, defaults to"<|endoftext|>") — The unknown token. A token that is not in the vocabulary cannot be converted to an ID and is set to be this token instead. - bos_token (
str, optional, defaults to"<|endoftext|>") — The beginning of sequence token. - eos_token (
str, optional, defaults to"<|endoftext|>") — The end of sequence token. - pad_token (
str, optional, defaults to"<|padding|>") — Token for padding a sequence. - add_prefix_space (
bool, optional, defaults toFalse) — Whether or not to add an initial space to the input. This allows to treat the leading word just as any other word. (GPTNeoX tokenizer detect beginning of words by the preceding space). - add_bos_token (
bool, optional, defaults toFalse) — Whether or not to add abos_tokenat the start of sequences. - add_eos_token (
bool, optional, defaults toFalse) — Whether or not to add aneos_tokenat the end of sequences. - trim_offsets (
bool, optional, defaults toTrue) — Whether or not the post-processing step should trim offsets to avoid including whitespaces. - vocab (
dict, optional) — Custom vocabulary dictionary. If not provided, vocabulary is loaded from vocab_file. - merges (
list, optional) — Custom merges list. If not provided, merges are loaded from merges_file.
Construct a GPT-NeoX-20B tokenizer (backed by HuggingFace’s tokenizers library). Based on byte-level Byte-Pair-Encoding.
This tokenizer has been trained to treat spaces like parts of the tokens (a bit like sentencepiece) so a word will
be encoded differently whether it is at the beginning of the sentence (without space) or not:
>>> from transformers import GPTNeoXTokenizer
>>> tokenizer = GPTNeoXTokenizer.from_pretrained("EleutherAI/gpt-neox-20b")
>>> tokenizer("Hello world")["input_ids"]
[15496, 995]
>>> tokenizer(" Hello world")["input_ids"]
[18435, 995]You can get around that behavior by passing add_prefix_space=True when instantiating this tokenizer, but since
the model was not pretrained this way, it might yield a decrease in performance.
When used with
is_split_into_words=True, this tokenizer needs to be instantiated withadd_prefix_space=True.
This tokenizer inherits from TokenizersBackend which contains most of the main methods. Users should refer to this superclass for more information regarding those methods.
GPTNeoXModel
class transformers.GPTNeoXModel
< source >( config )
Parameters
- config (GPTNeoXModel) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the from_pretrained() method to load the model weights.
The bare Gpt Neox Model outputting raw hidden-states without any specific head on top.
This model inherits from PreTrainedModel. Check the superclass documentation for the generic methods the library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads etc.)
This model is also a PyTorch torch.nn.Module subclass. Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and behavior.
forward
< source >( input_ids: typing.Optional[torch.LongTensor] = None attention_mask: typing.Optional[torch.FloatTensor] = None position_ids: typing.Optional[torch.LongTensor] = None inputs_embeds: typing.Optional[torch.FloatTensor] = None past_key_values: typing.Optional[transformers.cache_utils.Cache] = None use_cache: typing.Optional[bool] = None output_attentions: typing.Optional[bool] = None output_hidden_states: typing.Optional[bool] = None cache_position: typing.Optional[torch.LongTensor] = None **kwargs: typing_extensions.Unpack[transformers.utils.generic.TransformersKwargs] ) → transformers.modeling_outputs.BaseModelOutputWithPast or tuple(torch.FloatTensor)
Parameters
- input_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Indices of input sequence tokens in the vocabulary. Padding will be ignored by default.Indices can be obtained using AutoTokenizer. See PreTrainedTokenizer.encode() and PreTrainedTokenizer.call() for details.
- attention_mask (
torch.FloatTensorof shape(batch_size, sequence_length), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
- position_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Indices of positions of each input sequence tokens in the position embeddings. Selected in the range[0, config.n_positions - 1]. - inputs_embeds (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size), optional) — Optionally, instead of passinginput_idsyou can choose to directly pass an embedded representation. This is useful if you want more control over how to convertinput_idsindices into associated vectors than the model’s internal embedding lookup matrix. - past_key_values (
~cache_utils.Cache, optional) — Pre-computed hidden-states (key and values in the self-attention blocks and in the cross-attention blocks) that can be used to speed up sequential decoding. This typically consists in thepast_key_valuesreturned by the model at a previous stage of decoding, whenuse_cache=Trueorconfig.use_cache=True.Only Cache instance is allowed as input, see our kv cache guide. If no
past_key_valuesare passed, DynamicCache will be initialized by default.The model will output the same cache format that is fed as input.
If
past_key_valuesare used, the user is expected to input only unprocessedinput_ids(those that don’t have their past key value states given to this model) of shape(batch_size, unprocessed_length)instead of allinput_idsof shape(batch_size, sequence_length). - use_cache (
bool, optional) — If set toTrue,past_key_valueskey value states are returned and can be used to speed up decoding (seepast_key_values). - output_attentions (
bool, optional) — Whether or not to return the attentions tensors of all attention layers. Seeattentionsunder returned tensors for more detail. - output_hidden_states (
bool, optional) — Whether or not to return the hidden states of all layers. Seehidden_statesunder returned tensors for more detail. - cache_position (
torch.LongTensorof shape(sequence_length), optional) — Indices depicting the position of the input sequence tokens in the sequence. Contrarily toposition_ids, this tensor is not affected by padding. It is used to update the cache in the correct position and to infer the complete sequence length.
Returns
transformers.modeling_outputs.BaseModelOutputWithPast or tuple(torch.FloatTensor)
A transformers.modeling_outputs.BaseModelOutputWithPast or a tuple of
torch.FloatTensor (if return_dict=False is passed or when config.return_dict=False) comprising various
elements depending on the configuration (GPTNeoXConfig) and inputs.
-
last_hidden_state (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size)) — Sequence of hidden-states at the output of the last layer of the model.If
past_key_valuesis used only the last hidden-state of the sequences of shape(batch_size, 1, hidden_size)is output. -
past_key_values (
Cache, optional, returned whenuse_cache=Trueis passed or whenconfig.use_cache=True) — It is a Cache instance. For more details, see our kv cache guide.Contains pre-computed hidden-states (key and values in the self-attention blocks and optionally if
config.is_encoder_decoder=Truein the cross-attention blocks) that can be used (seepast_key_valuesinput) to speed up sequential decoding. -
hidden_states (
tuple(torch.FloatTensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftorch.FloatTensor(one for the output of the embeddings, if the model has an embedding layer, + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size).Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
-
attentions (
tuple(torch.FloatTensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length).Attentions weights after the attention softmax, used to compute the weighted average in the self-attention heads.
The GPTNeoXModel forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the pre and post processing steps while the latter silently ignores them.
GPTNeoXForCausalLM
class transformers.GPTNeoXForCausalLM
< source >( config )
Parameters
- config (GPTNeoXForCausalLM) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the from_pretrained() method to load the model weights.
GPTNeoX Model with a language modeling head on top for CLM fine-tuning.
This model inherits from PreTrainedModel. Check the superclass documentation for the generic methods the library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads etc.)
This model is also a PyTorch torch.nn.Module subclass. Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and behavior.
forward
< source >( input_ids: typing.Optional[torch.LongTensor] = None attention_mask: typing.Optional[torch.FloatTensor] = None position_ids: typing.Optional[torch.LongTensor] = None inputs_embeds: typing.Optional[torch.FloatTensor] = None past_key_values: typing.Optional[transformers.cache_utils.Cache] = None labels: typing.Optional[torch.LongTensor] = None use_cache: typing.Optional[bool] = None output_attentions: typing.Optional[bool] = None output_hidden_states: typing.Optional[bool] = None cache_position: typing.Optional[torch.LongTensor] = None logits_to_keep: typing.Union[int, torch.Tensor] = 0 **kwargs: typing_extensions.Unpack[transformers.utils.generic.TransformersKwargs] ) → transformers.modeling_outputs.CausalLMOutputWithPast or tuple(torch.FloatTensor)
Parameters
- input_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Indices of input sequence tokens in the vocabulary. Padding will be ignored by default.Indices can be obtained using AutoTokenizer. See PreTrainedTokenizer.encode() and PreTrainedTokenizer.call() for details.
- attention_mask (
torch.FloatTensorof shape(batch_size, sequence_length), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
- position_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Indices of positions of each input sequence tokens in the position embeddings. Selected in the range[0, config.n_positions - 1]. - inputs_embeds (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size), optional) — Optionally, instead of passinginput_idsyou can choose to directly pass an embedded representation. This is useful if you want more control over how to convertinput_idsindices into associated vectors than the model’s internal embedding lookup matrix. - past_key_values (
~cache_utils.Cache, optional) — Pre-computed hidden-states (key and values in the self-attention blocks and in the cross-attention blocks) that can be used to speed up sequential decoding. This typically consists in thepast_key_valuesreturned by the model at a previous stage of decoding, whenuse_cache=Trueorconfig.use_cache=True.Only Cache instance is allowed as input, see our kv cache guide. If no
past_key_valuesare passed, DynamicCache will be initialized by default.The model will output the same cache format that is fed as input.
If
past_key_valuesare used, the user is expected to input only unprocessedinput_ids(those that don’t have their past key value states given to this model) of shape(batch_size, unprocessed_length)instead of allinput_idsof shape(batch_size, sequence_length). - labels (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Labels for computing the left-to-right language modeling loss (next word prediction). Indices should be in[-100, 0, ..., config.vocab_size](seeinput_idsdocstring) Tokens with indices set to-100are ignored (masked), the loss is only computed for the tokens with labels n[0, ..., config.vocab_size]. - use_cache (
bool, optional) — If set toTrue,past_key_valueskey value states are returned and can be used to speed up decoding (seepast_key_values). - output_attentions (
bool, optional) — Whether or not to return the attentions tensors of all attention layers. Seeattentionsunder returned tensors for more detail. - output_hidden_states (
bool, optional) — Whether or not to return the hidden states of all layers. Seehidden_statesunder returned tensors for more detail. - cache_position (
torch.LongTensorof shape(sequence_length), optional) — Indices depicting the position of the input sequence tokens in the sequence. Contrarily toposition_ids, this tensor is not affected by padding. It is used to update the cache in the correct position and to infer the complete sequence length. - logits_to_keep (
Union[int, torch.Tensor], defaults to0) — If anint, compute logits for the lastlogits_to_keeptokens. If0, calculate logits for allinput_ids(special case). Only last token logits are needed for generation, and calculating them only for that token can save memory, which becomes pretty significant for long sequences or large vocabulary size. If atorch.Tensor, must be 1D corresponding to the indices to keep in the sequence length dimension. This is useful when using packed tensor format (single dimension for batch and sequence length).
Returns
transformers.modeling_outputs.CausalLMOutputWithPast or tuple(torch.FloatTensor)
A transformers.modeling_outputs.CausalLMOutputWithPast or a tuple of
torch.FloatTensor (if return_dict=False is passed or when config.return_dict=False) comprising various
elements depending on the configuration (GPTNeoXConfig) and inputs.
-
loss (
torch.FloatTensorof shape(1,), optional, returned whenlabelsis provided) — Language modeling loss (for next-token prediction). -
logits (
torch.FloatTensorof shape(batch_size, sequence_length, config.vocab_size)) — Prediction scores of the language modeling head (scores for each vocabulary token before SoftMax). -
past_key_values (
Cache, optional, returned whenuse_cache=Trueis passed or whenconfig.use_cache=True) — It is a Cache instance. For more details, see our kv cache guide.Contains pre-computed hidden-states (key and values in the self-attention blocks) that can be used (see
past_key_valuesinput) to speed up sequential decoding. -
hidden_states (
tuple(torch.FloatTensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftorch.FloatTensor(one for the output of the embeddings, if the model has an embedding layer, + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size).Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
-
attentions (
tuple(torch.FloatTensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length).Attentions weights after the attention softmax, used to compute the weighted average in the self-attention heads.
The GPTNeoXForCausalLM forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the pre and post processing steps while the latter silently ignores them.
Example:
>>> from transformers import AutoTokenizer, GPTNeoXForCausalLM, GPTNeoXConfig
>>> import torch
>>> tokenizer = AutoTokenizer.from_pretrained("EleutherAI/gpt-neox-20b")
>>> config = GPTNeoXConfig.from_pretrained("EleutherAI/gpt-neox-20b")
>>> config.is_decoder = True
>>> model = GPTNeoXForCausalLM.from_pretrained("EleutherAI/gpt-neox-20b", config=config)
>>> inputs = tokenizer("Hello, my dog is cute", return_tensors="pt")
>>> outputs = model(**inputs)
>>> prediction_logits = outputs.logitsGPTNeoXForQuestionAnswering
class transformers.GPTNeoXForQuestionAnswering
< source >( config )
Parameters
- config (GPTNeoXForQuestionAnswering) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the from_pretrained() method to load the model weights.
The Gpt Neox transformer with a span classification head on top for extractive question-answering tasks like
SQuAD (a linear layer on top of the hidden-states output to compute span start logits and span end logits).
This model inherits from PreTrainedModel. Check the superclass documentation for the generic methods the library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads etc.)
This model is also a PyTorch torch.nn.Module subclass. Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and behavior.
forward
< source >( input_ids: typing.Optional[torch.LongTensor] = None attention_mask: typing.Optional[torch.FloatTensor] = None token_type_ids: typing.Optional[torch.LongTensor] = None position_ids: typing.Optional[torch.LongTensor] = None inputs_embeds: typing.Optional[torch.FloatTensor] = None start_positions: typing.Optional[torch.LongTensor] = None end_positions: typing.Optional[torch.LongTensor] = None output_attentions: typing.Optional[bool] = None output_hidden_states: typing.Optional[bool] = None ) → transformers.modeling_outputs.QuestionAnsweringModelOutput or tuple(torch.FloatTensor)
Parameters
- input_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Indices of input sequence tokens in the vocabulary. Padding will be ignored by default.Indices can be obtained using AutoTokenizer. See PreTrainedTokenizer.encode() and PreTrainedTokenizer.call() for details.
- attention_mask (
torch.FloatTensorof shape(batch_size, sequence_length), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
- token_type_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Segment token indices to indicate first and second portions of the inputs. Indices are selected in[0, 1]:- 0 corresponds to a sentence A token,
- 1 corresponds to a sentence B token.
- position_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Indices of positions of each input sequence tokens in the position embeddings. Selected in the range[0, config.n_positions - 1]. - inputs_embeds (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size), optional) — Optionally, instead of passinginput_idsyou can choose to directly pass an embedded representation. This is useful if you want more control over how to convertinput_idsindices into associated vectors than the model’s internal embedding lookup matrix. - start_positions (
torch.LongTensorof shape(batch_size,), optional) — Labels for position (index) of the start of the labelled span for computing the token classification loss. Positions are clamped to the length of the sequence (sequence_length). Position outside of the sequence are not taken into account for computing the loss. - end_positions (
torch.LongTensorof shape(batch_size,), optional) — Labels for position (index) of the end of the labelled span for computing the token classification loss. Positions are clamped to the length of the sequence (sequence_length). Position outside of the sequence are not taken into account for computing the loss. - output_attentions (
bool, optional) — Whether or not to return the attentions tensors of all attention layers. Seeattentionsunder returned tensors for more detail. - output_hidden_states (
bool, optional) — Whether or not to return the hidden states of all layers. Seehidden_statesunder returned tensors for more detail.
Returns
transformers.modeling_outputs.QuestionAnsweringModelOutput or tuple(torch.FloatTensor)
A transformers.modeling_outputs.QuestionAnsweringModelOutput or a tuple of
torch.FloatTensor (if return_dict=False is passed or when config.return_dict=False) comprising various
elements depending on the configuration (GPTNeoXConfig) and inputs.
-
loss (
torch.FloatTensorof shape(1,), optional, returned whenlabelsis provided) — Total span extraction loss is the sum of a Cross-Entropy for the start and end positions. -
start_logits (
torch.FloatTensorof shape(batch_size, sequence_length)) — Span-start scores (before SoftMax). -
end_logits (
torch.FloatTensorof shape(batch_size, sequence_length)) — Span-end scores (before SoftMax). -
hidden_states (
tuple(torch.FloatTensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftorch.FloatTensor(one for the output of the embeddings, if the model has an embedding layer, + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size).Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
-
attentions (
tuple(torch.FloatTensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length).Attentions weights after the attention softmax, used to compute the weighted average in the self-attention heads.
The GPTNeoXForQuestionAnswering forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the pre and post processing steps while the latter silently ignores them.
Example:
>>> from transformers import AutoTokenizer, GPTNeoXForQuestionAnswering
>>> import torch
>>> tokenizer = AutoTokenizer.from_pretrained("EleutherAI/gpt-neox-20b")
>>> model = GPTNeoXForQuestionAnswering.from_pretrained("EleutherAI/gpt-neox-20b")
>>> question, text = "Who was Jim Henson?", "Jim Henson was a nice puppet"
>>> inputs = tokenizer(question, text, return_tensors="pt")
>>> with torch.no_grad():
... outputs = model(**inputs)
>>> answer_start_index = outputs.start_logits.argmax()
>>> answer_end_index = outputs.end_logits.argmax()
>>> predict_answer_tokens = inputs.input_ids[0, answer_start_index : answer_end_index + 1]
>>> tokenizer.decode(predict_answer_tokens, skip_special_tokens=True)
...
>>> # target is "nice puppet"
>>> target_start_index = torch.tensor([14])
>>> target_end_index = torch.tensor([15])
>>> outputs = model(**inputs, start_positions=target_start_index, end_positions=target_end_index)
>>> loss = outputs.loss
>>> round(loss.item(), 2)
...GPTNeoXForSequenceClassification
class transformers.GPTNeoXForSequenceClassification
< source >( config )
Parameters
- config (GPTNeoXForSequenceClassification) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the from_pretrained() method to load the model weights.
The GPTNeoX Model transformer with a sequence classification head on top (linear layer).
GPTNeoXForSequenceClassification uses the last token in order to do the classification, as other causal models (e.g. GPT-1) do.
Since it does classification on the last token, it requires to know the position of the last token. If a
pad_token_id is defined in the configuration, it finds the last token that is not a padding token in each row. If
no pad_token_id is defined, it simply takes the last value in each row of the batch. Since it cannot guess the
padding tokens when inputs_embeds are passed instead of input_ids, it does the same (take the last value in
each row of the batch).
This model inherits from PreTrainedModel. Check the superclass documentation for the generic methods the library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads etc.)
This model is also a PyTorch torch.nn.Module subclass. Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and behavior.
forward
< source >( input_ids: typing.Optional[torch.LongTensor] = None attention_mask: typing.Optional[torch.FloatTensor] = None position_ids: typing.Optional[torch.LongTensor] = None inputs_embeds: typing.Optional[torch.FloatTensor] = None past_key_values: typing.Optional[transformers.cache_utils.Cache] = None labels: typing.Optional[torch.LongTensor] = None use_cache: typing.Optional[bool] = None output_attentions: typing.Optional[bool] = None output_hidden_states: typing.Optional[bool] = None ) → transformers.modeling_outputs.SequenceClassifierOutputWithPast or tuple(torch.FloatTensor)
Parameters
- input_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Indices of input sequence tokens in the vocabulary. Padding will be ignored by default.Indices can be obtained using AutoTokenizer. See PreTrainedTokenizer.encode() and PreTrainedTokenizer.call() for details.
- attention_mask (
torch.FloatTensorof shape(batch_size, sequence_length), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
- position_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Indices of positions of each input sequence tokens in the position embeddings. Selected in the range[0, config.n_positions - 1]. - inputs_embeds (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size), optional) — Optionally, instead of passinginput_idsyou can choose to directly pass an embedded representation. This is useful if you want more control over how to convertinput_idsindices into associated vectors than the model’s internal embedding lookup matrix. - past_key_values (
~cache_utils.Cache, optional) — Pre-computed hidden-states (key and values in the self-attention blocks and in the cross-attention blocks) that can be used to speed up sequential decoding. This typically consists in thepast_key_valuesreturned by the model at a previous stage of decoding, whenuse_cache=Trueorconfig.use_cache=True.Only Cache instance is allowed as input, see our kv cache guide. If no
past_key_valuesare passed, DynamicCache will be initialized by default.The model will output the same cache format that is fed as input.
If
past_key_valuesare used, the user is expected to input only unprocessedinput_ids(those that don’t have their past key value states given to this model) of shape(batch_size, unprocessed_length)instead of allinput_idsof shape(batch_size, sequence_length). - labels (
torch.LongTensorof shape(batch_size,), optional) — Labels for computing the sequence classification/regression loss. Indices should be in[0, ..., config.num_labels - 1]. Ifconfig.num_labels == 1a regression loss is computed (Mean-Square loss), Ifconfig.num_labels > 1a classification loss is computed (Cross-Entropy). - use_cache (
bool, optional) — If set toTrue,past_key_valueskey value states are returned and can be used to speed up decoding (seepast_key_values). - output_attentions (
bool, optional) — Whether or not to return the attentions tensors of all attention layers. Seeattentionsunder returned tensors for more detail. - output_hidden_states (
bool, optional) — Whether or not to return the hidden states of all layers. Seehidden_statesunder returned tensors for more detail.
Returns
transformers.modeling_outputs.SequenceClassifierOutputWithPast or tuple(torch.FloatTensor)
A transformers.modeling_outputs.SequenceClassifierOutputWithPast or a tuple of
torch.FloatTensor (if return_dict=False is passed or when config.return_dict=False) comprising various
elements depending on the configuration (GPTNeoXConfig) and inputs.
-
loss (
torch.FloatTensorof shape(1,), optional, returned whenlabelsis provided) — Classification (or regression if config.num_labels==1) loss. -
logits (
torch.FloatTensorof shape(batch_size, config.num_labels)) — Classification (or regression if config.num_labels==1) scores (before SoftMax). -
past_key_values (
Cache, optional, returned whenuse_cache=Trueis passed or whenconfig.use_cache=True) — It is a Cache instance. For more details, see our kv cache guide.Contains pre-computed hidden-states (key and values in the self-attention blocks) that can be used (see
past_key_valuesinput) to speed up sequential decoding. -
hidden_states (
tuple(torch.FloatTensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftorch.FloatTensor(one for the output of the embeddings, if the model has an embedding layer, + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size).Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
-
attentions (
tuple(torch.FloatTensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length).Attentions weights after the attention softmax, used to compute the weighted average in the self-attention heads.
The GPTNeoXForSequenceClassification forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the pre and post processing steps while the latter silently ignores them.
Example of single-label classification:
>>> import torch
>>> from transformers import AutoTokenizer, GPTNeoXForSequenceClassification
>>> tokenizer = AutoTokenizer.from_pretrained("EleutherAI/gpt-neox-20b")
>>> model = GPTNeoXForSequenceClassification.from_pretrained("EleutherAI/gpt-neox-20b")
>>> inputs = tokenizer("Hello, my dog is cute", return_tensors="pt")
>>> with torch.no_grad():
... logits = model(**inputs).logits
>>> predicted_class_id = logits.argmax().item()
>>> model.config.id2label[predicted_class_id]
...
>>> # To train a model on `num_labels` classes, you can pass `num_labels=num_labels` to `.from_pretrained(...)`
>>> num_labels = len(model.config.id2label)
>>> model = GPTNeoXForSequenceClassification.from_pretrained("EleutherAI/gpt-neox-20b", num_labels=num_labels)
>>> labels = torch.tensor([1])
>>> loss = model(**inputs, labels=labels).loss
>>> round(loss.item(), 2)
...Example of multi-label classification:
>>> import torch
>>> from transformers import AutoTokenizer, GPTNeoXForSequenceClassification
>>> tokenizer = AutoTokenizer.from_pretrained("EleutherAI/gpt-neox-20b")
>>> model = GPTNeoXForSequenceClassification.from_pretrained("EleutherAI/gpt-neox-20b", problem_type="multi_label_classification")
>>> inputs = tokenizer("Hello, my dog is cute", return_tensors="pt")
>>> with torch.no_grad():
... logits = model(**inputs).logits
>>> predicted_class_ids = torch.arange(0, logits.shape[-1])[torch.sigmoid(logits).squeeze(dim=0) > 0.5]
>>> # To train a model on `num_labels` classes, you can pass `num_labels=num_labels` to `.from_pretrained(...)`
>>> num_labels = len(model.config.id2label)
>>> model = GPTNeoXForSequenceClassification.from_pretrained(
... "EleutherAI/gpt-neox-20b", num_labels=num_labels, problem_type="multi_label_classification"
... )
>>> labels = torch.sum(
... torch.nn.functional.one_hot(predicted_class_ids[None, :].clone(), num_classes=num_labels), dim=1
... ).to(torch.float)
>>> loss = model(**inputs, labels=labels).lossGPTNeoXForTokenClassification
forward
< source >( input_ids: typing.Optional[torch.LongTensor] = None past_key_values: typing.Optional[transformers.cache_utils.Cache] = None attention_mask: typing.Optional[torch.FloatTensor] = None token_type_ids: typing.Optional[torch.LongTensor] = None position_ids: typing.Optional[torch.LongTensor] = None inputs_embeds: typing.Optional[torch.FloatTensor] = None labels: typing.Optional[torch.LongTensor] = None use_cache: typing.Optional[bool] = None output_attentions: typing.Optional[bool] = None output_hidden_states: typing.Optional[bool] = None ) → transformers.modeling_outputs.TokenClassifierOutput or tuple(torch.FloatTensor)
Parameters
- input_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Indices of input sequence tokens in the vocabulary. Padding will be ignored by default.Indices can be obtained using AutoTokenizer. See PreTrainedTokenizer.encode() and PreTrainedTokenizer.call() for details.
- past_key_values (
~cache_utils.Cache, optional) — Pre-computed hidden-states (key and values in the self-attention blocks and in the cross-attention blocks) that can be used to speed up sequential decoding. This typically consists in thepast_key_valuesreturned by the model at a previous stage of decoding, whenuse_cache=Trueorconfig.use_cache=True.Only Cache instance is allowed as input, see our kv cache guide. If no
past_key_valuesare passed, DynamicCache will be initialized by default.The model will output the same cache format that is fed as input.
If
past_key_valuesare used, the user is expected to input only unprocessedinput_ids(those that don’t have their past key value states given to this model) of shape(batch_size, unprocessed_length)instead of allinput_idsof shape(batch_size, sequence_length). - attention_mask (
torch.FloatTensorof shape(batch_size, sequence_length), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
- token_type_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Segment token indices to indicate first and second portions of the inputs. Indices are selected in[0, 1]:- 0 corresponds to a sentence A token,
- 1 corresponds to a sentence B token.
- position_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Indices of positions of each input sequence tokens in the position embeddings. Selected in the range[0, config.n_positions - 1]. - inputs_embeds (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size), optional) — Optionally, instead of passinginput_idsyou can choose to directly pass an embedded representation. This is useful if you want more control over how to convertinput_idsindices into associated vectors than the model’s internal embedding lookup matrix. - labels (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Labels for computing the sequence classification/regression loss. Indices should be in[0, ..., config.num_labels - 1]. Ifconfig.num_labels == 1a regression loss is computed (Mean-Square loss), Ifconfig.num_labels > 1a classification loss is computed (Cross-Entropy). - use_cache (
bool, optional) — If set toTrue,past_key_valueskey value states are returned and can be used to speed up decoding (seepast_key_values). - output_attentions (
bool, optional) — Whether or not to return the attentions tensors of all attention layers. Seeattentionsunder returned tensors for more detail. - output_hidden_states (
bool, optional) — Whether or not to return the hidden states of all layers. Seehidden_statesunder returned tensors for more detail.
Returns
transformers.modeling_outputs.TokenClassifierOutput or tuple(torch.FloatTensor)
A transformers.modeling_outputs.TokenClassifierOutput or a tuple of
torch.FloatTensor (if return_dict=False is passed or when config.return_dict=False) comprising various
elements depending on the configuration (GPTNeoXConfig) and inputs.
-
loss (
torch.FloatTensorof shape(1,), optional, returned whenlabelsis provided) — Classification loss. -
logits (
torch.FloatTensorof shape(batch_size, sequence_length, config.num_labels)) — Classification scores (before SoftMax). -
hidden_states (
tuple(torch.FloatTensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftorch.FloatTensor(one for the output of the embeddings, if the model has an embedding layer, + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size).Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
-
attentions (
tuple(torch.FloatTensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length).Attentions weights after the attention softmax, used to compute the weighted average in the self-attention heads.
The GPTNeoXForTokenClassification forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the pre and post processing steps while the latter silently ignores them.
Example:
>>> from transformers import AutoTokenizer, GPTNeoXForTokenClassification
>>> import torch
>>> tokenizer = AutoTokenizer.from_pretrained("EleutherAI/gpt-neox-20b")
>>> model = GPTNeoXForTokenClassification.from_pretrained("EleutherAI/gpt-neox-20b")
>>> inputs = tokenizer(
... "HuggingFace is a company based in Paris and New York", add_special_tokens=False, return_tensors="pt"
... )
>>> with torch.no_grad():
... logits = model(**inputs).logits
>>> predicted_token_class_ids = logits.argmax(-1)
>>> # Note that tokens are classified rather then input words which means that
>>> # there might be more predicted token classes than words.
>>> # Multiple token classes might account for the same word
>>> predicted_tokens_classes = [model.config.id2label[t.item()] for t in predicted_token_class_ids[0]]
>>> predicted_tokens_classes
...
>>> labels = predicted_token_class_ids
>>> loss = model(**inputs, labels=labels).loss
>>> round(loss.item(), 2)
...