
{kind=link}
IndexCache: Accelerating Sparse Attention via Cross-Layer Index Reuse
Paper • 2603.12201 • Published • 60
GLM-5.2-W4AFP8 is a 4-bit quantization of GLM-5.2 that runs the full 1M-token context on a single 8×H200 node.
Two things make it useful:
This model keeps GLM-5.2's full 753B parameters. The ~387B in the sidebar is a counting quirk: two 4-bit weights share each int8 slot, so the metadata counts storage slots, not parameters.
Tested with SGLang only (v0.5.13.post1). The 4-bit layout and speculative-decoding path are SGLang-specific and untried on vLLM or other engines.
Update (2026-06-19): speculative-decoding (MTP) fix. Revisions of this repo before this date shipped a
model.safetensors.index.jsonthat did not reference the MTP / next-token-prediction layer shard (model-00041-of-00041.safetensors). The shard was present in the repo but unindexed, so SGLang's EAGLE speculative decoding loaded an uninitialized draft head and accepted almost nothing (0.1% acceptance — no speedup). Outputs were always correct regardless, because the target model verifies every drafted token. This is now fixed: the index references the full MTP layer (layer 78 — 256 experts +80%+ draft acceptance**. If you downloaded the repo before 2026-06-19, re-pulleh_proj/enorm/hnorm/shared_head), and speculative decoding reaches **model.safetensors.index.json— it is the only file that changed; the weights were already present.
Measured on 8×H200 with SGLang at GLM-5.2's recommended sampling (temperature 1.0, top_p 0.95) with reasoning enabled. The reference column shows the published GLM-5.2 results.
| Benchmark | GLM-5.2-W4AFP8 | GLM-5.2 reference |
|---|---|---|
| GPQA-Diamond (reasoning) | 90.9 | 91.2 |
| IFBench (instruction following, strict) | 75.0 | 74.3 |
| AA-LCR (long-context reasoning) | 76.0 | 69.7 |
| Needle-in-a-haystack at ~983K tokens | 3 / 3 retrieved | not published |
| BFCL (tool calling) | matches FP8 baseline | not published |
Reasoning (GPQA) and instruction following (IFBench) match the published results within evaluation tolerance. GLM-5.2 publishes no BFCL or needle reference, so those compare against the FP8 release: tool calling matches (84% vs 87% overall, within sampling noise) and needle retrieval hit all three depths near the 1M-token limit.
The model includes a quantized Multi-Token Prediction (MTP) layer, so SGLang's EAGLE speculative decoding works out of the box.
| Setting | No speculative decoding | EAGLE (MTP) |
|---|---|---|
| Single-stream decode | 75 tok/s | 118 tok/s |
| Throughput (8K in, 1K out, 16 concurrent) | 658 tok/s | 733 tok/s |
Requirements: Hopper GPUs (H100 or H200, SM90) and SGLang v0.5.13.post1 or later.
python -m sglang.launch_server \
--model-path PhalaCloud/GLM-5.2-W4AFP8 \
--quantization w4afp8 \
--disable-shared-experts-fusion \
--tp 8 \
--kv-cache-dtype fp8_e4m3 \
--reasoning-parser glm45 \
--tool-call-parser glm47 \
--context-length 1048576 \
--mem-fraction-static 0.85 \
--trust-remote-code
On 8×H200 (1128 GB) this serves the full 1M-token context. On 8×H100 (640 GB) the weights still fit and leave room for roughly 400K tokens; the FP8 release does not fit on 8×H100 at all.
To enable speculative decoding (the 118 tok/s single-stream path), add:
--speculative-algorithm EAGLE \
--speculative-num-steps 1 \
--speculative-eagle-topk 1 \
--speculative-num-draft-tokens 2
The server exposes the standard OpenAI-compatible API: chat completions, tool calls, and reasoning content.
The routed MoE experts use 4-bit integer weights (group size 128) with FP8 (E4M3) activations. Dense layers, shared experts, attention, the sparse-attention indexer, and the MTP layer's non-expert weights stay in FP8 or BF16. Activations are quantized at run time. This is the layout SGLang's w4afp8 path loads. Weight quantization used activation-aware scaling (AWQ) with a short calibration set.
MIT, inherited from GLM-5.2. Please cite the original GLM-5.2 work (citation in the original model card below).
The text below is the unmodified model card from the base model, zai-org/GLM-5.2-FP8.
👋 Join our WeChat or Discord community.
📖 Check out the GLM-5.2 blog and GLM-5 Technical report.
📍 Use GLM-5.2 API services on Z.ai API Platform.
🔜 Try GLM-5.2 here.
We're introducing GLM-5.2, our latest flagship model for long-horizon tasks. It marks a substantial leap in long-horizon task capability over its predecessor GLM-5.1 and, for the first time, delivers that capability on a solid 1M-token context. GLM-5.2's new capabilities include:
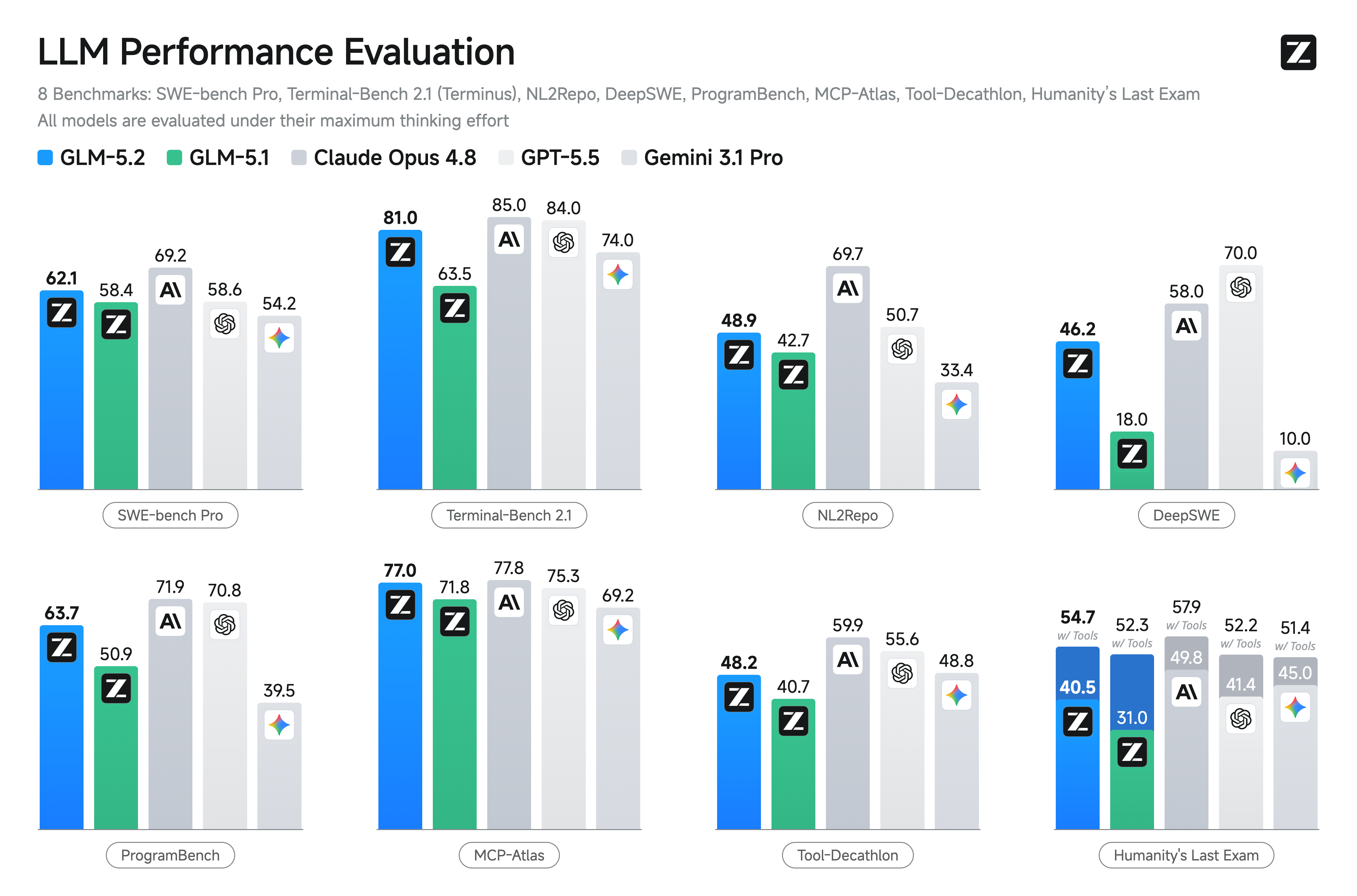
| Benchmark | GLM-5.2 | GLM-5.1 | Qwen3.7-Max | MiniMax M3 | DeepSeek-V4-Pro | Claude Opus 4.8 | GPT-5.5 | Gemini 3.1 Pro |
|---|---|---|---|---|---|---|---|---|
| Reasoning | ||||||||
| HLE | 40.5 | 31 | 41.4 | 37 | 37.7 | 49.8* | 41.4* | 45 |
| HLE (w/ Tools) | 54.7 | 52.3 | 53.5 | - | 48.2 | 57.9* | 52.2* | 51.4* |
| CritPt | 20.9 | 4.6 | 13.4 | 3.7 | 12.9 | 20.9 | 27.1 | 17.7 |
| AIME 2026 | 99.2 | 95.3 | 97 | - | 94.6 | 95.7 | 98.3 | 98.2 |
| HMMT Nov. 2025 | 94.4 | 94 | 95 | 84.4 | 94.4 | 96.5 | 96.5 | 94.8 |
| HMMT Feb. 2026 | 92.5 | 82.6 | 97.1 | 84.4 | 95.2 | 96.7 | 96.7 | 87.3 |
| IMOAnswerBench | 91.0 | 83.8 | 90 | - | 89.8 | 83.5 | - | 81 |
| GPQA-Diamond | 91.2 | 86.2 | 90 | 93 | 90.1 | 93.6 | 93.6 | 94.3 |
| Coding | ||||||||
| SWE-bench Pro | 62.1 | 58.4 | 60.6 | 59 | 55.4 | 69.2 | 58.6 | 54.2 |
| NL2Repo | 48.9 | 42.7 | 47.2 | 42.1 | 35.5 | 69.7 | 50.7 | 33.4 |
| DeepSWE | 46.2 | 18 | 18 | 20 | 8 | 58 | 70 | 10 |
| ProgramBench | 63.7 | 50.9 | - | - | 47.8 | 71.9 | 70.8 | 39.5 |
| Terminal Bench 2.1 (Terminus-2) | 81.0 | 63.5 | 75 | 65 | 64 | 85 | 84 | 74 |
| Terminal Bench 2.1 (Best Reported Harness) | 82.7 | 69 | - | - | - | 78.9 | 83.4 | 70.7 |
| FrontierSWE (Dominance) | 74.4 | 30.5 | - | - | 29.0 | 75.1 | 72.6 | 39.6 |
| PostTrainBench | 34.3 | 20.1 | - | - | - | 37.2 | 28.4 | 21.6 |
| SWE-Marathon | 13.0 | 1.0 | - | - | - | 26.0 | 12.0 | 4.0 |
| Agentic | ||||||||
| MCP-Atlas (Public Set) | 76.8 | 71.8 | 76.4 | 74.2 | 73.6 | 77.8 | 75.3 | 69.2 |
| Tool-Decathlon | 48.2 | 40.7 | - | - | 52.8 | 59.9 | 55.6 | 48.8 |
GLM-5.2 supports deployment with the following frameworks. Feel free to try them out:
Ascend NPU platform, inference frameworks such as vLLM-Ascend, xLLM and SGLang are supported — see here.If you find GLM-5.2 useful in your research, please cite our technical report:
@misc{glm5team2026glm5vibecodingagentic,
title={GLM-5: from Vibe Coding to Agentic Engineering},
author={GLM-5-Team and : and Aohan Zeng and Xin Lv and Zhenyu Hou and Zhengxiao Du and Qinkai Zheng and Bin Chen and Da Yin and Chendi Ge and Chenghua Huang and Chengxing Xie and Chenzheng Zhu and Congfeng Yin and Cunxiang Wang and Gengzheng Pan and Hao Zeng and Haoke Zhang and Haoran Wang and Huilong Chen and Jiajie Zhang and Jian Jiao and Jiaqi Guo and Jingsen Wang and Jingzhao Du and Jinzhu Wu and Kedong Wang and Lei Li and Lin Fan and Lucen Zhong and Mingdao Liu and Mingming Zhao and Pengfan Du and Qian Dong and Rui Lu and Shuang-Li and Shulin Cao and Song Liu and Ting Jiang and Xiaodong Chen and Xiaohan Zhang and Xuancheng Huang and Xuezhen Dong and Yabo Xu and Yao Wei and Yifan An and Yilin Niu and Yitong Zhu and Yuanhao Wen and Yukuo Cen and Yushi Bai and Zhongpei Qiao and Zihan Wang and Zikang Wang and Zilin Zhu and Ziqiang Liu and Zixuan Li and Bojie Wang and Bosi Wen and Can Huang and Changpeng Cai and Chao Yu and Chen Li and Chengwei Hu and Chenhui Zhang and Dan Zhang and Daoyan Lin and Dayong Yang and Di Wang and Ding Ai and Erle Zhu and Fangzhou Yi and Feiyu Chen and Guohong Wen and Hailong Sun and Haisha Zhao and Haiyi Hu and Hanchen Zhang and Hanrui Liu and Hanyu Zhang and Hao Peng and Hao Tai and Haobo Zhang and He Liu and Hongwei Wang and Hongxi Yan and Hongyu Ge and Huan Liu and Huanpeng Chu and Jia'ni Zhao and Jiachen Wang and Jiajing Zhao and Jiamin Ren and Jiapeng Wang and Jiaxin Zhang and Jiayi Gui and Jiayue Zhao and Jijie Li and Jing An and Jing Li and Jingwei Yuan and Jinhua Du and Jinxin Liu and Junkai Zhi and Junwen Duan and Kaiyue Zhou and Kangjian Wei and Ke Wang and Keyun Luo and Laiqiang Zhang and Leigang Sha and Liang Xu and Lindong Wu and Lintao Ding and Lu Chen and Minghao Li and Nianyi Lin and Pan Ta and Qiang Zou and Rongjun Song and Ruiqi Yang and Shangqing Tu and Shangtong Yang and Shaoxiang Wu and Shengyan Zhang and Shijie Li and Shuang Li and Shuyi Fan and Wei Qin and Wei Tian and Weining Zhang and Wenbo Yu and Wenjie Liang and Xiang Kuang and Xiangmeng Cheng and Xiangyang Li and Xiaoquan Yan and Xiaowei Hu and Xiaoying Ling and Xing Fan and Xingye Xia and Xinyuan Zhang and Xinze Zhang and Xirui Pan and Xu Zou and Xunkai Zhang and Yadi Liu and Yandong Wu and Yanfu Li and Yidong Wang and Yifan Zhu and Yijun Tan and Yilin Zhou and Yiming Pan and Ying Zhang and Yinpei Su and Yipeng Geng and Yong Yan and Yonglin Tan and Yuean Bi and Yuhan Shen and Yuhao Yang and Yujiang Li and Yunan Liu and Yunqing Wang and Yuntao Li and Yurong Wu and Yutao Zhang and Yuxi Duan and Yuxuan Zhang and Zezhen Liu and Zhengtao Jiang and Zhenhe Yan and Zheyu Zhang and Zhixiang Wei and Zhuo Chen and Zhuoer Feng and Zijun Yao and Ziwei Chai and Ziyuan Wang and Zuzhou Zhang and Bin Xu and Minlie Huang and Hongning Wang and Juanzi Li and Yuxiao Dong and Jie Tang},
year={2026},
eprint={2602.15763},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2602.15763},
}
Base model
zai-org/GLM-5.2-FP8