Open-Source AI Cookbook documentation
How to use Inference Endpoints to Embed Documents
How to use Inference Endpoints to Embed Documents
Authored by: Derek Thomas
Goal
I have a dataset I want to embed for semantic search (or QA, or RAG), I want the easiest way to do embed this and put it in a new dataset.
Approach
I’m using a dataset from my favorite subreddit r/bestofredditorupdates. Because it has long entries, I will use the new jinaai/jina-embeddings-v2-base-en since it has an 8k context length. I will deploy this using Inference Endpoint to save time and money. To follow this tutorial, you will need to have already added a payment method. If you haven’t, you can add one here in billing. To make it even easier, I’ll make this fully API based.
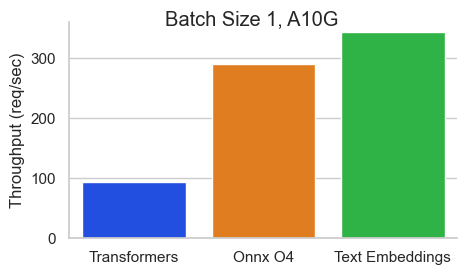
To make this MUCH faster I will use the Text Embeddings Inference image. This has many benefits like:
- No model graph compilation step
- Small docker images and fast boot times. Get ready for true serverless!
- Token based dynamic batching
- Optimized transformers code for inference using Flash Attention, Candle and cuBLASLt
- Safetensors weight loading
- Production ready (distributed tracing with Open Telemetry, Prometheus metrics)
Requirements
!pip install -q aiohttp==3.8.3 datasets==2.14.6 pandas==1.5.3 requests==2.31.0 tqdm==4.66.1 huggingface-hub>=0.20Imports
import asyncio
from getpass import getpass
import json
from pathlib import Path
import time
from typing import Optional
from aiohttp import ClientSession, ClientTimeout
from datasets import load_dataset, Dataset, DatasetDict
from huggingface_hub import notebook_login, create_inference_endpoint, list_inference_endpoints, whoami
import numpy as np
import pandas as pd
import requests
from tqdm.auto import tqdmConfig
DATASET_IN is where your text data is
DATASET_OUT is where your embeddings will be stored
Note I used 5 for the MAX_WORKERS since jina-embeddings-v2 are quite memory hungry.
DATASET_IN = 'derek-thomas/dataset-creator-reddit-bestofredditorupdates'
DATASET_OUT = "processed-subset-bestofredditorupdates"
ENDPOINT_NAME = "boru-jina-embeddings-demo-ie"
MAX_WORKERS = 5 # This is for how many async workers you want. Choose based on the model and hardware
ROW_COUNT = 100 # Choose None to use all rows, Im using 100 just for a demoInference Endpoints offers a number of GPUs that you can choose from. Check the documentation for GPU and alternative accelerators for information.
You may need to email us for access to some architectures.
| Provider | Instance Type | Instance Size | Hourly rate | GPUs | Memory | Architecture |
|---|---|---|---|---|---|---|
| aws | nvidia-a10g | x1 | \$1 | 1 | 24GB | NVIDIA A10G |
| aws | nvidia-t4 | x1 | \$0.5 | 1 | 14GB | NVIDIA T4 |
| aws | nvidia-t4 | x4 | \$3 | 4 | 56GB | NVIDIA T4 |
| gcp | nvidia-l4 | x1 | \$0.8 | 1 | 24GB | NVIDIA L4 |
| gcp | nvidia-l4 | x4 | \$3.8 | 4 | 96GB | NVIDIA L4 |
| aws | nvidia-a100 | x1 | \$4 | 1 | 80GB | NVIDIA A100 |
| aws | nvidia-a10g | x4 | \$5 | 4 | 96GB | NVIDIA A10G |
| aws | nvidia-a100 | x2 | \$8 | 2 | 160GB | NVIDIA A100 |
| aws | nvidia-a100 | x4 | \$16 | 4 | 320GB | NVIDIA A100 |
| aws | nvidia-a100 | x8 | \$32 | 8 | 640GB | NVIDIA A100 |
| gcp | nvidia-t4 | x1 | \$0.5 | 1 | 16GB | NVIDIA T4 |
| gcp | nvidia-l4 | x1 | \$1 | 1 | 24GB | NVIDIA L4 |
| gcp | nvidia-l4 | x4 | \$5 | 4 | 96GB | NVIDIA L4 |
| gcp | nvidia-a100 | x1 | \$6 | 1 | 80 GB | NVIDIA A100 |
| gcp | nvidia-a100 | x2 | \$12 | 2 | 160 GB | NVIDIA A100 |
| gcp | nvidia-a100 | x4 | \$24 | 4 | 320 GB | NVIDIA A100 |
| gcp | nvidia-a100 | x8 | \$48 | 8 | 640 GB | NVIDIA A100 |
| gcp | nvidia-h100 | x1 | \$12.5 | 1 | 80 GB | NVIDIA H100 |
| gcp | nvidia-h100 | x2 | \$25 | 2 | 160 GB | NVIDIA H100 |
| gcp | nvidia-h100 | x4 | \$50 | 4 | 320 GB | NVIDIA H100 |
| gcp | nvidia-h100 | x8 | \$100 | 8 | 640 GB | NVIDIA H100 |
| aws | inf2 | x1 | \$0.75 | 1 | 32GB | AWS Inferentia2 |
| aws | inf2 | x12 | \$12 | 12 | 384GB | AWS Inferentia2 |
# GPU Choice
VENDOR="aws"
REGION="us-east-1"
INSTANCE_SIZE="x1"
INSTANCE_TYPE="nvidia-a10g"notebook_login()
Some users might have payment registered in an organization. This allows you to connect to an organization (that you are a member of) with a payment method.
Leave it blank is you want to use your username.
>>> who = whoami()
>>> organization = getpass(prompt="What is your Hugging Face 🤗 username or organization? (with an added payment method)")
>>> namespace = organization or who['name']What is your Hugging Face 🤗 username or organization? (with an added payment method) ········
Get Dataset
dataset = load_dataset(DATASET_IN)
dataset['train']documents = dataset['train'].to_pandas().to_dict('records')[:ROW_COUNT]
len(documents), documents[0]Inference Endpoints
Create Inference Endpoint
We are going to use the API to create an Inference Endpoint. This should provide a few main benefits:
- It’s convenient (No clicking)
- It’s repeatable (We have the code to run it easily)
- It’s cheaper (No time spent waiting for it to load, and automatically shut it down)
try:
endpoint = create_inference_endpoint(
ENDPOINT_NAME,
repository="jinaai/jina-embeddings-v2-base-en",
revision="7302ac470bed880590f9344bfeee32ff8722d0e5",
task="sentence-embeddings",
framework="pytorch",
accelerator="gpu",
instance_size=INSTANCE_SIZE,
instance_type=INSTANCE_TYPE,
region=REGION,
vendor=VENDOR,
namespace=namespace,
custom_image={
"health_route": "/health",
"env": {
"MAX_BATCH_TOKENS": str(MAX_WORKERS * 2048),
"MAX_CONCURRENT_REQUESTS": "512",
"MODEL_ID": "/repository"
},
"url": "ghcr.io/huggingface/text-embeddings-inference:0.5.0",
},
type="protected",
)
except:
endpoint = [ie for ie in list_inference_endpoints(namespace=namespace) if ie.name == ENDPOINT_NAME][0]
print('Loaded endpoint')There are a few design choices here:
- As discussed before we are using
jinaai/jina-embeddings-v2-base-enas our model.- For reproducibility we are pinning it to a specific revision.
- If you are interested in more models, check out the supported list here.
- Note that most embedding models are based on the BERT architecture.
MAX_BATCH_TOKENSis chosen based on our number of workers and the context window of our embedding model.type="protected"utilized the security from Inference Endpoints detailed here.- I’m using 1x Nvidia A10 since
jina-embeddings-v2is memory hungry (remember the 8k context length). - You should consider further tuning
MAX_BATCH_TOKENSandMAX_CONCURRENT_REQUESTSif you have high workloads
Wait until it’s running
>>> %%time
>>> endpoint.wait()CPU times: user 48.1 ms, sys: 15.7 ms, total: 63.8 ms Wall time: 52.6 s
When we use endpoint.client.post we get a bytes string back. This is a little tedious because we need to convert this to an np.array, but it’s just a couple quick lines in python.
response = endpoint.client.post(json={"inputs": 'This sound track was beautiful! It paints the senery in your mind so well I would recomend it even to people who hate vid. game music!', 'truncate': True}, task="feature-extraction")
response = np.array(json.loads(response.decode()))
response[0][:20]You may have inputs that exceed the context. In such scenarios, it’s up to you to handle them. In my case, I’d like to truncate rather than have an error. Let’s test that it works.
>>> embedding_input = 'This input will get multiplied' * 10000
>>> print(f'The length of the embedding_input is: {len(embedding_input)}')
>>> response = endpoint.client.post(json={"inputs": embedding_input, 'truncate': True}, task="feature-extraction")
>>> response = np.array(json.loads(response.decode()))
>>> response[0][:20]The length of the embedding_input is: 300000
Get Embeddings
Here I send a document, update it with the embedding, and return it. This happens in parallel with MAX_WORKERS.
async def request(document, semaphore):
# Semaphore guard
async with semaphore:
result = await endpoint.async_client.post(json={"inputs": document['content'], 'truncate': True}, task="feature-extraction")
result = np.array(json.loads(result.decode()))
document['embedding'] = result[0] # Assuming the API's output can be directly assigned
return document
async def main(documents):
# Semaphore to limit concurrent requests. Adjust the number as needed.
semaphore = asyncio.BoundedSemaphore(MAX_WORKERS)
# Creating a list of tasks
tasks = [request(document, semaphore) for document in documents]
# Using tqdm to show progress. It's been integrated into the async loop.
for f in tqdm(asyncio.as_completed(tasks), total=len(documents)):
await f>>> start = time.perf_counter()
>>> # Get embeddings
>>> await main(documents)
>>> # Make sure we got it all
>>> count = 0
>>> for document in documents:
... if 'embedding' in document.keys() and len(document['embedding']) == 768:
... count += 1
>>> print(f'Embeddings = {count} documents = {len(documents)}')
>>> # Print elapsed time
>>> elapsed_time = time.perf_counter() - start
>>> minutes, seconds = divmod(elapsed_time, 60)
>>> print(f"{int(minutes)} min {seconds:.2f} sec")Embeddings = 100 documents = 100 0 min 21.33 sec
Pause Inference Endpoint
Now that we have finished, let’s pause the endpoint so we don’t incur any extra charges, this will also allow us to analyze the cost.
>>> endpoint = endpoint.pause()
>>> print(f"Endpoint Status: {endpoint.status}")Endpoint Status: paused
Push updated dataset to Hub
We now have our documents updated with the embeddings we wanted. First we need to convert it back to a Dataset format. I find it easiest to go from list of dicts -> pd.DataFrame -> Dataset
df = pd.DataFrame(documents)
dd = DatasetDict({'train': Dataset.from_pandas(df)})I’m uploading it to the user’s account by default (as opposed to uploading to an organization) but feel free to push to wherever you want by setting the user in the repo_id or in the config by setting DATASET_OUT
dd.push_to_hub(repo_id=DATASET_OUT)
>>> print(f'Dataset is at https://huggingface.co/datasets/{who["name"]}/{DATASET_OUT}')Dataset is at https://huggingface.co/datasets/derek-thomas/processed-subset-bestofredditorupdates
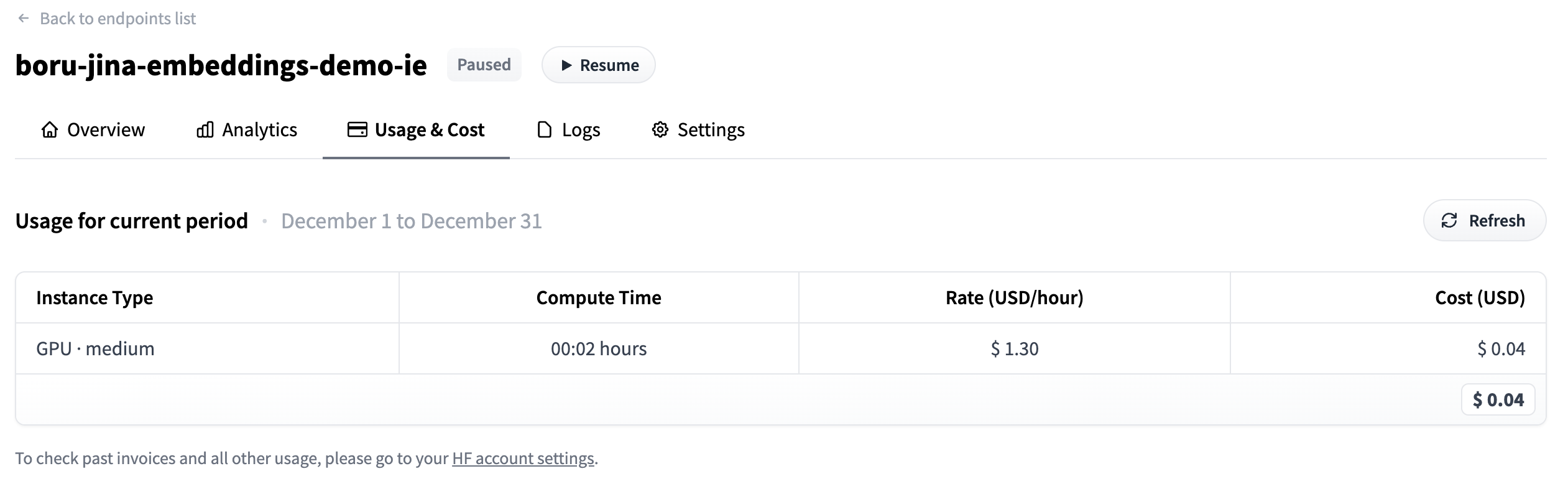
Analyze Usage
- Go to your
dashboard_urlprinted below - Click on the Usage & Cost tab
- See how much you have spent
>>> dashboard_url = f'https://ui.endpoints.huggingface.co/{namespace}/endpoints/{ENDPOINT_NAME}'
>>> print(dashboard_url)https://ui.endpoints.huggingface.co/HF-test-lab/endpoints/boru-jina-embeddings-demo-ie
>>> input("Hit enter to continue with the notebook")Hit enter to continue with the notebook
We can see that it only took $0.04 to pay for this!
Delete Endpoint
Now that we are done, we don’t need our endpoint anymore. We can delete our endpoint programmatically.
>>> endpoint = endpoint.delete()
>>> if not endpoint:
... print('Endpoint deleted successfully')
>>> else:
... print('Delete Endpoint in manually')Endpoint deleted successfullyUpdate on GitHub