Transformers documentation
Nougat
This model was released on 2023-08-25 and added to Hugging Face Transformers on 2023-09-26.
Nougat
Overview
The Nougat model was proposed in Nougat: Neural Optical Understanding for Academic Documents by Lukas Blecher, Guillem Cucurull, Thomas Scialom, Robert Stojnic. Nougat uses the same architecture as Donut, meaning an image Transformer encoder and an autoregressive text Transformer decoder to translate scientific PDFs to markdown, enabling easier access to them.
The abstract from the paper is the following:
Scientific knowledge is predominantly stored in books and scientific journals, often in the form of PDFs. However, the PDF format leads to a loss of semantic information, particularly for mathematical expressions. We propose Nougat (Neural Optical Understanding for Academic Documents), a Visual Transformer model that performs an Optical Character Recognition (OCR) task for processing scientific documents into a markup language, and demonstrate the effectiveness of our model on a new dataset of scientific documents. The proposed approach offers a promising solution to enhance the accessibility of scientific knowledge in the digital age, by bridging the gap between human-readable documents and machine-readable text. We release the models and code to accelerate future work on scientific text recognition.
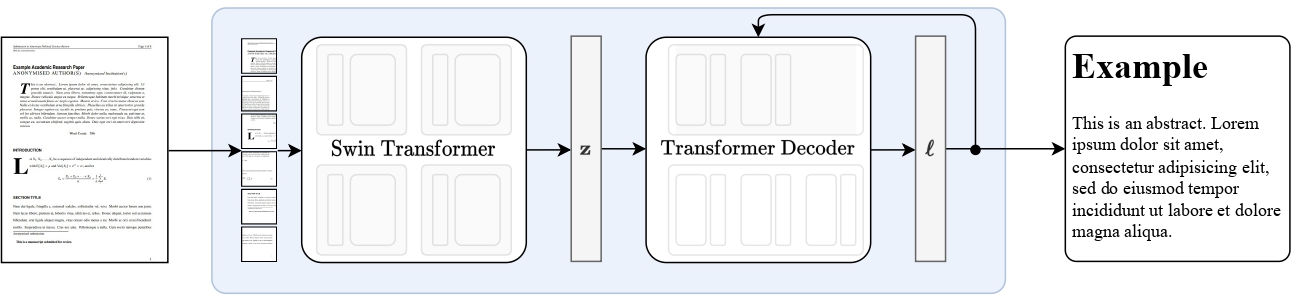 Nougat high-level overview. Taken from the original paper.
Nougat high-level overview. Taken from the original paper. This model was contributed by nielsr. The original code can be found here.
Usage tips
- The quickest way to get started with Nougat is by checking the tutorial notebooks, which show how to use the model at inference time as well as fine-tuning on custom data.
- Nougat is always used within the VisionEncoderDecoder framework. The model is identical to Donut in terms of architecture.
Inference
Nougat’s VisionEncoderDecoder model accepts images as input and makes use of
generate() to autoregressively generate text given the input image.
The NougatImageProcessor class is responsible for preprocessing the input image and NougatTokenizerFast decodes the generated target tokens to the target string. The NougatProcessor wraps NougatImageProcessor and NougatTokenizerFast classes into a single instance to both extract the input features and decode the predicted token ids.
- Step-by-step PDF transcription
>>> from huggingface_hub import hf_hub_download
>>> import re
>>> from PIL import Image
>>> from transformers import NougatProcessor, VisionEncoderDecoderModel, infer_device
>>> from datasets import load_dataset
>>> import torch
>>> processor = NougatProcessor.from_pretrained("facebook/nougat-base")
>>> model = VisionEncoderDecoderModel.from_pretrained("facebook/nougat-base")
>>> device = infer_device()
>>> model.to(device)
>>> # prepare PDF image for the model
>>> filepath = hf_hub_download(repo_id="hf-internal-testing/fixtures_docvqa", filename="nougat_paper.png", repo_type="dataset")
>>> image = Image.open(filepath)
>>> pixel_values = processor(image, return_tensors="pt").pixel_values
>>> # generate transcription (here we only generate 30 tokens)
>>> outputs = model.generate(
... pixel_values.to(device),
... min_length=1,
... max_new_tokens=30,
... bad_words_ids=[[processor.tokenizer.unk_token_id]],
... )
>>> sequence = processor.batch_decode(outputs, skip_special_tokens=True)[0]
>>> sequence = processor.post_process_generation(sequence, fix_markdown=False)
>>> # note: we're using repr here such for the sake of printing the \n characters, feel free to just print the sequence
>>> print(repr(sequence))
'\n\n# Nougat: Neural Optical Understanding for Academic Documents\n\n Lukas Blecher\n\nCorrespondence to: lblecher@'See the model hub to look for Nougat checkpoints.
The model is identical to Donut in terms of architecture.
NougatImageProcessor
class transformers.NougatImageProcessor
< source >( do_crop_margin: bool = True do_resize: bool = True size: typing.Optional[dict[str, int]] = None resample: Resampling = <Resampling.BILINEAR: 2> do_thumbnail: bool = True do_align_long_axis: bool = False do_pad: bool = True do_rescale: bool = True rescale_factor: typing.Union[int, float] = 0.00392156862745098 do_normalize: bool = True image_mean: typing.Union[float, list[float], NoneType] = None image_std: typing.Union[float, list[float], NoneType] = None **kwargs )
Parameters
- do_crop_margin (
bool, optional, defaults toTrue) — Whether to crop the image margins. - do_resize (
bool, optional, defaults toTrue) — Whether to resize the image’s (height, width) dimensions to the specifiedsize. Can be overridden bydo_resizein thepreprocessmethod. - size (
dict[str, int]optional, defaults to{"height" -- 896, "width": 672}): Size of the image after resizing. Can be overridden bysizein thepreprocessmethod. - resample (
PILImageResampling, optional, defaults toResampling.BILINEAR) — Resampling filter to use if resizing the image. Can be overridden byresamplein thepreprocessmethod. - do_thumbnail (
bool, optional, defaults toTrue) — Whether to resize the image using thumbnail method. - do_align_long_axis (
bool, optional, defaults toFalse) — Whether to align the long axis of the image with the long axis ofsizeby rotating by 90 degrees. - do_pad (
bool, optional, defaults toTrue) — Whether to pad the images to the largest image size in the batch. - do_rescale (
bool, optional, defaults toTrue) — Whether to rescale the image by the specified scalerescale_factor. Can be overridden by thedo_rescaleparameter in thepreprocessmethod. - rescale_factor (
intorfloat, optional, defaults to1/255) — Scale factor to use if rescaling the image. Can be overridden by therescale_factorparameter in thepreprocessmethod. - do_normalize (
bool, optional, defaults toTrue) — Whether to normalize the image. Can be overridden bydo_normalizein thepreprocessmethod. - image_mean (
floatorlist[float], optional, defaults toIMAGENET_DEFAULT_MEAN) — Mean to use if normalizing the image. This is a float or list of floats the length of the number of channels in the image. Can be overridden by theimage_meanparameter in thepreprocessmethod. - image_std (
floatorlist[float], optional, defaults toIMAGENET_DEFAULT_STD) — Image standard deviation.
Constructs a Nougat image processor.
preprocess
< source >( images: typing.Union[ForwardRef('PIL.Image.Image'), numpy.ndarray, ForwardRef('torch.Tensor'), list['PIL.Image.Image'], list[numpy.ndarray], list['torch.Tensor']] do_crop_margin: typing.Optional[bool] = None do_resize: typing.Optional[bool] = None size: typing.Optional[dict[str, int]] = None resample: typing.Optional[PIL.Image.Resampling] = None do_thumbnail: typing.Optional[bool] = None do_align_long_axis: typing.Optional[bool] = None do_pad: typing.Optional[bool] = None do_rescale: typing.Optional[bool] = None rescale_factor: typing.Union[int, float, NoneType] = None do_normalize: typing.Optional[bool] = None image_mean: typing.Union[float, list[float], NoneType] = None image_std: typing.Union[float, list[float], NoneType] = None return_tensors: typing.Union[str, transformers.utils.generic.TensorType, NoneType] = None data_format: typing.Optional[transformers.image_utils.ChannelDimension] = <ChannelDimension.FIRST: 'channels_first'> input_data_format: typing.Union[str, transformers.image_utils.ChannelDimension, NoneType] = None )
Parameters
- images (
ImageInput) — Image to preprocess. Expects a single or batch of images with pixel values ranging from 0 to 255. - do_crop_margin (
bool, optional, defaults toself.do_crop_margin) — Whether to crop the image margins. - do_resize (
bool, optional, defaults toself.do_resize) — Whether to resize the image. - size (
dict[str, int], optional, defaults toself.size) — Size of the image after resizing. Shortest edge of the image is resized to min(size[“height”], size[“width”]) with the longest edge resized to keep the input aspect ratio. - resample (
int, optional, defaults toself.resample) — Resampling filter to use if resizing the image. This can be one of the enumPILImageResampling. Only has an effect ifdo_resizeis set toTrue. - do_thumbnail (
bool, optional, defaults toself.do_thumbnail) — Whether to resize the image using thumbnail method. - do_align_long_axis (
bool, optional, defaults toself.do_align_long_axis) — Whether to align the long axis of the image with the long axis ofsizeby rotating by 90 degrees. - do_pad (
bool, optional, defaults toself.do_pad) — Whether to pad the images to the largest image size in the batch. - do_rescale (
bool, optional, defaults toself.do_rescale) — Whether to rescale the image by the specified scalerescale_factor. - rescale_factor (
intorfloat, optional, defaults toself.rescale_factor) — Scale factor to use if rescaling the image. - do_normalize (
bool, optional, defaults toself.do_normalize) — Whether to normalize the image. - image_mean (
floatorlist[float], optional, defaults toself.image_mean) — Image mean to use for normalization. - image_std (
floatorlist[float], optional, defaults toself.image_std) — Image standard deviation to use for normalization. - return_tensors (
strorTensorType, optional) — The type of tensors to return. Can be one of:- Unset: Return a list of
np.ndarray. TensorType.PYTORCHor'pt': Return a batch of typetorch.Tensor.TensorType.NUMPYor'np': Return a batch of typenp.ndarray.
- Unset: Return a list of
- data_format (
ChannelDimensionorstr, optional, defaults toChannelDimension.FIRST) — The channel dimension format for the output image. Can be one of:ChannelDimension.FIRST: image in (num_channels, height, width) format.ChannelDimension.LAST: image in (height, width, num_channels) format.- Unset: defaults to the channel dimension format of the input image.
- input_data_format (
ChannelDimensionorstr, optional) — The channel dimension format for the input image. If unset, the channel dimension format is inferred from the input image. Can be one of:"channels_first"orChannelDimension.FIRST: image in (num_channels, height, width) format."channels_last"orChannelDimension.LAST: image in (height, width, num_channels) format."none"orChannelDimension.NONE: image in (height, width) format.
Preprocess an image or batch of images.
NougatImageProcessorFast
class transformers.NougatImageProcessorFast
< source >( **kwargs: typing_extensions.Unpack[transformers.models.nougat.image_processing_nougat_fast.NougatFastImageProcessorKwargs] )
Constructs a fast Nougat image processor.
preprocess
< source >( images: typing.Union[ForwardRef('PIL.Image.Image'), numpy.ndarray, ForwardRef('torch.Tensor'), list['PIL.Image.Image'], list[numpy.ndarray], list['torch.Tensor']] **kwargs: typing_extensions.Unpack[transformers.models.nougat.image_processing_nougat_fast.NougatFastImageProcessorKwargs] ) → <class 'transformers.image_processing_base.BatchFeature'>
Parameters
- images (
Union[PIL.Image.Image, numpy.ndarray, torch.Tensor, list['PIL.Image.Image'], list[numpy.ndarray], list['torch.Tensor']]) — Image to preprocess. Expects a single or batch of images with pixel values ranging from 0 to 255. If passing in images with pixel values between 0 and 1, setdo_rescale=False. - do_resize (
bool, optional) — Whether to resize the image. - size (
dict[str, int], optional) — Describes the maximum input dimensions to the model. - default_to_square (
bool, optional) — Whether to default to a square image when resizing, if size is an int. - resample (
Union[PILImageResampling, F.InterpolationMode, NoneType]) — Resampling filter to use if resizing the image. This can be one of the enumPILImageResampling. Only has an effect ifdo_resizeis set toTrue. - do_center_crop (
bool, optional) — Whether to center crop the image. - crop_size (
dict[str, int], optional) — Size of the output image after applyingcenter_crop. - do_rescale (
bool, optional) — Whether to rescale the image. - rescale_factor (
Union[int, float, NoneType]) — Rescale factor to rescale the image by ifdo_rescaleis set toTrue. - do_normalize (
bool, optional) — Whether to normalize the image. - image_mean (
Union[float, list[float], NoneType]) — Image mean to use for normalization. Only has an effect ifdo_normalizeis set toTrue. - image_std (
Union[float, list[float], NoneType]) — Image standard deviation to use for normalization. Only has an effect ifdo_normalizeis set toTrue. - do_pad (
bool, optional) — Whether to pad the image. Padding is done either to the largest size in the batch or to a fixed square size per image. The exact padding strategy depends on the model. - pad_size (
dict[str, int], optional) — The size in{"height": int, "width" int}to pad the images to. Must be larger than any image size provided for preprocessing. Ifpad_sizeis not provided, images will be padded to the largest height and width in the batch. Applied only whendo_pad=True. - do_convert_rgb (
bool, optional) — Whether to convert the image to RGB. - return_tensors (
Union[str, ~utils.generic.TensorType, NoneType]) — Returns stacked tensors if set to `pt, otherwise returns a list of tensors. - data_format (
~image_utils.ChannelDimension, optional) — OnlyChannelDimension.FIRSTis supported. Added for compatibility with slow processors. - input_data_format (
Union[str, ~image_utils.ChannelDimension, NoneType]) — The channel dimension format for the input image. If unset, the channel dimension format is inferred from the input image. Can be one of:"channels_first"orChannelDimension.FIRST: image in (num_channels, height, width) format."channels_last"orChannelDimension.LAST: image in (height, width, num_channels) format."none"orChannelDimension.NONE: image in (height, width) format.
- device (
torch.device, optional) — The device to process the images on. If unset, the device is inferred from the input images. - disable_grouping (
bool, optional) — Whether to disable grouping of images by size to process them individually and not in batches. If None, will be set to True if the images are on CPU, and False otherwise. This choice is based on empirical observations, as detailed here: https://github.com/huggingface/transformers/pull/38157 - do_crop_margin (
bool, optional, defaults toTrue) — Whether to crop the image margins. - do_thumbnail (
bool, optional, defaults toTrue) — Whether to resize the image using thumbnail method. - do_align_long_axis (
bool, optional, defaults toFalse) — Whether to align the long axis of the image with the long axis ofsizeby rotating by 90 degrees.
Returns
<class 'transformers.image_processing_base.BatchFeature'>
- data (
dict) — Dictionary of lists/arrays/tensors returned by the call method (‘pixel_values’, etc.). - tensor_type (
Union[None, str, TensorType], optional) — You can give a tensor_type here to convert the lists of integers in PyTorch/Numpy Tensors at initialization.
NougatTokenizerFast
class transformers.NougatTokenizerFast
< source >( vocab_file = None tokenizer_file = None clean_up_tokenization_spaces = False unk_token = '<unk>' bos_token = '<s>' eos_token = '</s>' pad_token = '<pad>' **kwargs )
Parameters
- vocab_file (
str, optional) — SentencePiece file (generally has a .model extension) that contains the vocabulary necessary to instantiate a tokenizer. - tokenizer_file (
str, optional) — tokenizers file (generally has a .json extension) that contains everything needed to load the tokenizer. - clean_up_tokenization_spaces (
str, optional, defaults toFalse) — Whether to cleanup spaces after decoding, cleanup consists in removing potential artifacts like extra spaces. - unk_token (
str, optional, defaults to"<unk>") — The unknown token. A token that is not in the vocabulary cannot be converted to an ID and is set to be this token instead. - bos_token (
str, optional, defaults to"<s>") — The beginning of sequence token that was used during pretraining. Can be used a sequence classifier token. - eos_token (
str, optional, defaults to"</s>") — The end of sequence token. - pad_token (
str, optional, defaults to"<pad>") — The token used for padding, for example when batching sequences of different lengths. - model_max_length (
int, optional) — The maximum length (in number of tokens) for the inputs to the transformer model. When the tokenizer is loaded with from_pretrained(), this will be set to the value stored for the associated model inmax_model_input_sizes(see above). If no value is provided, will default to VERY_LARGE_INTEGER (int(1e30)). - padding_side (
str, optional) — The side on which the model should have padding applied. Should be selected between [‘right’, ‘left’]. Default value is picked from the class attribute of the same name. - truncation_side (
str, optional) — The side on which the model should have truncation applied. Should be selected between [‘right’, ‘left’]. Default value is picked from the class attribute of the same name. - chat_template (
str, optional) — A Jinja template string that will be used to format lists of chat messages. See https://huggingface.co/docs/transformers/chat_templating for a full description. - model_input_names (
list[string], optional) — The list of inputs accepted by the forward pass of the model (like"token_type_ids"or"attention_mask"). Default value is picked from the class attribute of the same name. - bos_token (
strortokenizers.AddedToken, optional) — A special token representing the beginning of a sentence. Will be associated toself.bos_tokenandself.bos_token_id. - eos_token (
strortokenizers.AddedToken, optional) — A special token representing the end of a sentence. Will be associated toself.eos_tokenandself.eos_token_id. - unk_token (
strortokenizers.AddedToken, optional) — A special token representing an out-of-vocabulary token. Will be associated toself.unk_tokenandself.unk_token_id. - sep_token (
strortokenizers.AddedToken, optional) — A special token separating two different sentences in the same input (used by BERT for instance). Will be associated toself.sep_tokenandself.sep_token_id. - pad_token (
strortokenizers.AddedToken, optional) — A special token used to make arrays of tokens the same size for batching purpose. Will then be ignored by attention mechanisms or loss computation. Will be associated toself.pad_tokenandself.pad_token_id. - cls_token (
strortokenizers.AddedToken, optional) — A special token representing the class of the input (used by BERT for instance). Will be associated toself.cls_tokenandself.cls_token_id. - mask_token (
strortokenizers.AddedToken, optional) — A special token representing a masked token (used by masked-language modeling pretraining objectives, like BERT). Will be associated toself.mask_tokenandself.mask_token_id. - additional_special_tokens (tuple or list of
strortokenizers.AddedToken, optional) — A tuple or a list of additional special tokens. Add them here to ensure they are skipped when decoding withskip_special_tokensis set to True. If they are not part of the vocabulary, they will be added at the end of the vocabulary. - clean_up_tokenization_spaces (
bool, optional, defaults toTrue) — Whether or not the model should cleanup the spaces that were added when splitting the input text during the tokenization process. - split_special_tokens (
bool, optional, defaults toFalse) — Whether or not the special tokens should be split during the tokenization process. Passing will affect the internal state of the tokenizer. The default behavior is to not split special tokens. This means that if<s>is thebos_token, thentokenizer.tokenize("<s>") = ['<s>]. Otherwise, ifsplit_special_tokens=True, thentokenizer.tokenize("<s>")will be give['<','s', '>']. - tokenizer_object (tokenizers.Tokenizer) — A tokenizers.Tokenizer object from 🤗 tokenizers to instantiate from. See Using tokenizers from 🤗 tokenizers for more information.
- tokenizer_file (
str) — A path to a local JSON file representing a previously serialized tokenizers.Tokenizer object from 🤗 tokenizers.
Fast tokenizer for Nougat (backed by HuggingFace tokenizers library).
This tokenizer inherits from PreTrainedTokenizerFast which contains most of the main methods. Users should refer to this superclass for more information regarding those methods. This class mainly adds Nougat-specific methods for postprocessing the generated text.
Class attributes (overridden by derived classes)
- vocab_files_names (
dict[str, str]) — A dictionary with, as keys, the__init__keyword name of each vocabulary file required by the model, and as associated values, the filename for saving the associated file (string). - pretrained_vocab_files_map (
dict[str, dict[str, str]]) — A dictionary of dictionaries, with the high-level keys being the__init__keyword name of each vocabulary file required by the model, the low-level being theshort-cut-namesof the pretrained models with, as associated values, theurlto the associated pretrained vocabulary file. - model_input_names (
list[str]) — A list of inputs expected in the forward pass of the model. - padding_side (
str) — The default value for the side on which the model should have padding applied. Should be'right'or'left'. - truncation_side (
str) — The default value for the side on which the model should have truncation applied. Should be'right'or'left'.
correct_tables
< source >( generation: str ) → str
Takes a generated string and fixes tables/tabulars to make them match the markdown format needed.
post_process_generation
< source >( generation: typing.Union[str, list[str]] fix_markdown: bool = True num_workers: typing.Optional[int] = None ) → Union[str, list[str]]
Parameters
- generation (Union[str, list[str]]) — The generated text or a list of generated texts.
- fix_markdown (
bool, optional, defaults toTrue) — Whether to perform Markdown formatting fixes. - num_workers (
int, optional) — Optional number of workers to pass to leverage multiprocessing (postprocessing several texts in parallel).
Returns
Union[str, list[str]]
The postprocessed text or list of postprocessed texts.
Postprocess a generated text or a list of generated texts.
This function can be used to perform postprocessing on generated text, such as fixing Markdown formatting.
Postprocessing is quite slow so it is recommended to use multiprocessing to speed up the process.
post_process_single
< source >( generation: str fix_markdown: bool = True ) → str
Postprocess a single generated text. Regular expressions used here are taken directly from the Nougat article authors. These expressions are commented for clarity and tested end-to-end in most cases.
remove_hallucinated_references
< source >( text: str ) → str
Remove hallucinated or missing references from the text.
This function identifies and removes references that are marked as missing or hallucinated from the input text.
NougatProcessor
class transformers.NougatProcessor
< source >( image_processor tokenizer )
Parameters
- image_processor (NougatImageProcessor) — An instance of NougatImageProcessor. The image processor is a required input.
- tokenizer (NougatTokenizerFast) — An instance of NougatTokenizerFast. The tokenizer is a required input.
Constructs a Nougat processor which wraps a Nougat image processor and a Nougat tokenizer into a single processor.
NougatProcessor offers all the functionalities of NougatImageProcessor and NougatTokenizerFast. See the call() and decode() for more information.
__call__
< source >( images = None text = None do_crop_margin: typing.Optional[bool] = None do_resize: typing.Optional[bool] = None size: typing.Optional[dict[str, int]] = None resample: PILImageResampling = None do_thumbnail: typing.Optional[bool] = None do_align_long_axis: typing.Optional[bool] = None do_pad: typing.Optional[bool] = None do_rescale: typing.Optional[bool] = None rescale_factor: typing.Union[int, float, NoneType] = None do_normalize: typing.Optional[bool] = None image_mean: typing.Union[float, list[float], NoneType] = None image_std: typing.Union[float, list[float], NoneType] = None data_format: typing.Optional[ForwardRef('ChannelDimension')] = 'channels_first' input_data_format: typing.Union[str, ForwardRef('ChannelDimension'), NoneType] = None text_pair: typing.Union[str, list[str], list[list[str]], NoneType] = None text_target: typing.Union[str, list[str], list[list[str]]] = None text_pair_target: typing.Union[str, list[str], list[list[str]], NoneType] = None add_special_tokens: bool = True padding: typing.Union[bool, str, transformers.utils.generic.PaddingStrategy] = False truncation: typing.Union[bool, str, transformers.tokenization_utils_base.TruncationStrategy] = None max_length: typing.Optional[int] = None stride: int = 0 is_split_into_words: bool = False pad_to_multiple_of: typing.Optional[int] = None return_tensors: typing.Union[str, transformers.utils.generic.TensorType, NoneType] = None return_token_type_ids: typing.Optional[bool] = None return_attention_mask: typing.Optional[bool] = None return_overflowing_tokens: bool = False return_special_tokens_mask: bool = False return_offsets_mapping: bool = False return_length: bool = False verbose: bool = True )
from_pretrained
< source >( pretrained_model_name_or_path: typing.Union[str, os.PathLike] cache_dir: typing.Union[str, os.PathLike, NoneType] = None force_download: bool = False local_files_only: bool = False token: typing.Union[str, bool, NoneType] = None revision: str = 'main' **kwargs )
Parameters
- pretrained_model_name_or_path (
stroros.PathLike) — This can be either:- a string, the model id of a pretrained feature_extractor hosted inside a model repo on huggingface.co.
- a path to a directory containing a feature extractor file saved using the
save_pretrained() method, e.g.,
./my_model_directory/. - a path or url to a saved feature extractor JSON file, e.g.,
./my_model_directory/preprocessor_config.json.
- **kwargs —
Additional keyword arguments passed along to both
from_pretrained() and
~tokenization_utils_base.PreTrainedTokenizer.from_pretrained.
Instantiate a processor associated with a pretrained model.
This class method is simply calling the feature extractor
from_pretrained(), image processor
ImageProcessingMixin and the tokenizer
~tokenization_utils_base.PreTrainedTokenizer.from_pretrained methods. Please refer to the docstrings of the
methods above for more information.
save_pretrained
< source >( save_directory push_to_hub: bool = False legacy_serialization: bool = True **kwargs )
Parameters
- save_directory (
stroros.PathLike) — Directory where the feature extractor JSON file and the tokenizer files will be saved (directory will be created if it does not exist). - push_to_hub (
bool, optional, defaults toFalse) — Whether or not to push your model to the Hugging Face model hub after saving it. You can specify the repository you want to push to withrepo_id(will default to the name ofsave_directoryin your namespace). - legacy_serialization (
bool, optional, defaults toTrue) — Whether or not to save processor attributes in separate config files (legacy) or in processor’s config file as a nested dict. Saving all attributes in a single dict will become the default in future versions. Set tolegacy_serialization=Trueuntil then. - kwargs (
dict[str, Any], optional) — Additional key word arguments passed along to the push_to_hub() method.
Saves the attributes of this processor (feature extractor, tokenizer…) in the specified directory so that it can be reloaded using the from_pretrained() method.
This class method is simply calling save_pretrained() and save_pretrained(). Please refer to the docstrings of the methods above for more information.
This method forwards all its arguments to PreTrainedTokenizer’s batch_decode(). Please refer to the docstring of this method for more information.
This method forwards all its arguments to PreTrainedTokenizer’s decode(). Please refer to the docstring of this method for more information.
This method forwards all its arguments to NougatTokenizer’s ~PreTrainedTokenizer.post_process_generation.
Please refer to the docstring of this method for more information.