course documentation
Token Classification
Token Classification

ကျွန်တော်တို့ လေ့လာမယ့် ပထမဆုံး application ကတော့ token classification ဖြစ်ပါတယ်။ ဒီ generic task က “စာကြောင်းတစ်ကြောင်းရှိ token တစ်ခုစီကို label တစ်ခု သတ်မှတ်ခြင်း” အဖြစ် ဖော်ပြနိုင်တဲ့ ပြဿနာအားလုံးကို ဖော်ပြပါတယ်၊ ဥပမာ…
- Named entity recognition (NER): စာကြောင်းတစ်ခုထဲက entities တွေ (ဥပမာ - လူပုဂ္ဂိုလ်၊ နေရာဒေသ၊ အဖွဲ့အစည်း) ကို ရှာဖွေပါ။ ဒါကို entity တစ်ခုစီအတွက် class တစ်ခုစီနဲ့ “no entity” အတွက် class တစ်ခုစီထားပြီး token တစ်ခုစီကို label တစ်ခု သတ်မှတ်ခြင်းအဖြစ် ဖော်ပြနိုင်ပါတယ်။
- Part-of-speech tagging (POS): စာကြောင်းတစ်ခုစီရှိ စကားလုံးတစ်လုံးစီကို သီးခြား part of speech တစ်ခု (ဥပမာ - noun, verb, adjective စသည်) နှင့် သက်ဆိုင်ကြောင်း မှတ်သားပါ။
- Chunking: တူညီတဲ့ entity ထဲမှာ ပါဝင်တဲ့ tokens တွေကို ရှာဖွေပါ။ ဒီ task (POS ဒါမှမဟုတ် NER နဲ့ ပေါင်းစပ်နိုင်ပါတယ်) ကို chunk တစ်ခုရဲ့အစမှာ ရှိတဲ့ tokens တွေအတွက် label တစ်ခု (ပုံမှန်အားဖြင့်
B-)၊ chunk အတွင်းမှာရှိတဲ့ tokens တွေအတွက် တခြား label တစ်ခု (ပုံမှန်အားဖြင့်I-)၊ ပြီးတော့ ဘယ် chunk နဲ့မှ မသက်ဆိုင်တဲ့ tokens တွေအတွက် တတိယ label တစ်ခု (ပုံမှန်အားဖြင့်O) သတ်မှတ်ခြင်းအဖြစ် ဖော်ပြနိုင်ပါတယ်။
ဟုတ်ပါတယ်။ token classification problem အမျိုးအစားများစွာ ရှိပါသေးတယ်၊ ဒါတွေက ကိုယ်စားပြုတဲ့ ဥပမာအနည်းငယ်မျှသာ ဖြစ်ပါတယ်။ ဒီအပိုင်းမှာ၊ ကျွန်တော်တို့ဟာ NER task တစ်ခုပေါ်မှာ model (BERT) တစ်ခုကို fine-tune လုပ်သွားမှာဖြစ်ပြီး၊ အဲဒါက အခုလို predictions တွေကို တွက်ချက်နိုင်ပါလိမ့်မယ်-
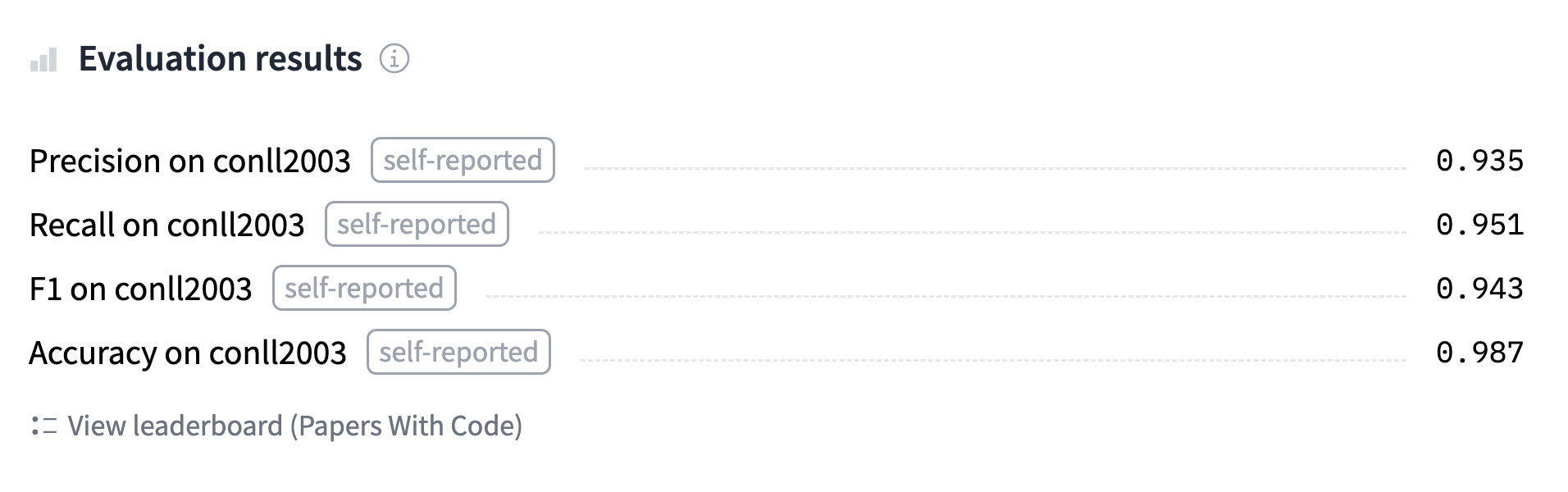
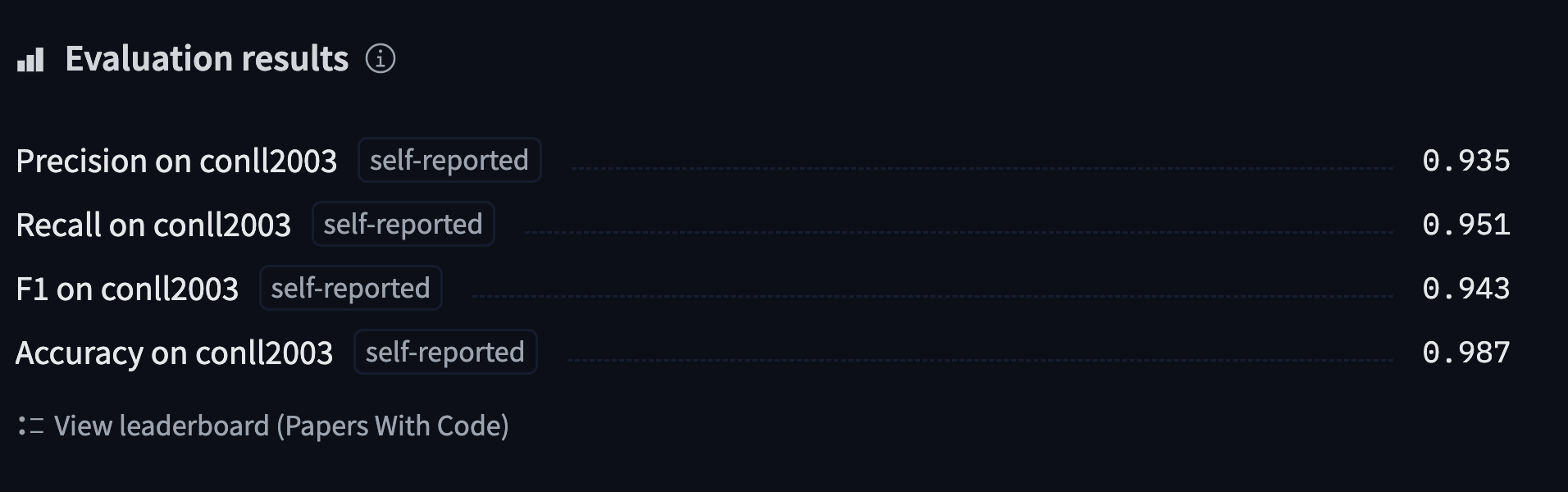
ကျွန်တော်တို့ train လုပ်ပြီး Hub ကို upload လုပ်မယ့် model ကို ဒီနေရာမှာ ရှာပြီး ၎င်းရဲ့ predictions တွေကို ထပ်မံစစ်ဆေးနိုင်ပါတယ်။
ဒေတာကို ပြင်ဆင်ခြင်း
ပထမဆုံးအနေနဲ့၊ ကျွန်တော်တို့မှာ token classification အတွက် သင့်လျော်တဲ့ dataset တစ်ခု လိုအပ်ပါတယ်။ ဒီအပိုင်းမှာ ကျွန်တော်တို့ CoNLL-2003 dataset ကို အသုံးပြုပါမယ်။ ဒါက Reuters က သတင်းများ ပါဝင်ပါတယ်။
💡 သင့် dataset က သက်ဆိုင်ရာ labels တွေနဲ့အတူ စကားလုံးတွေအဖြစ် ပိုင်းခြားထားတဲ့ texts တွေနဲ့ ဖွဲ့စည်းထားသရွေ့၊ ဒီနေရာမှာ ဖော်ပြထားတဲ့ data processing procedures တွေကို သင့်ကိုယ်ပိုင် dataset နဲ့ လိုက်လျောညီထွေဖြစ်အောင် ပြုလုပ်နိုင်ပါလိမ့်မယ်။ သင့်ကိုယ်ပိုင် custom data ကို
Datasetထဲမှာ ဘယ်လို load လုပ်ရမလဲဆိုတာ ပြန်လည်လေ့လာဖို့ လိုအပ်ရင် Chapter 5 ကို ပြန်ကြည့်ပါ။
CoNLL-2003 Dataset
CoNLL-2003 dataset ကို load လုပ်ဖို့၊ 🤗 Datasets library ကနေ load_dataset() method ကို ကျွန်တော်တို့ အသုံးပြုပါတယ်။
from datasets import load_dataset
raw_datasets = load_dataset("conll2003")ဒါက dataset ကို download လုပ်ပြီး cache လုပ်ပါလိမ့်မယ်၊ Chapter 3 မှာ GLUE MRPC dataset အတွက် ကျွန်တော်တို့ တွေ့ခဲ့ရသလိုပါပဲ။ ဒီ object ကို စစ်ဆေးကြည့်ခြင်းက ရှိနေတဲ့ columns တွေနဲ့ training, validation, test sets တွေကြားက split ကို ပြသပါတယ်။
raw_datasets
DatasetDict({
train: Dataset({
features: ['chunk_tags', 'id', 'ner_tags', 'pos_tags', 'tokens'],
num_rows: 14041
})
validation: Dataset({
features: ['chunk_tags', 'id', 'ner_tags', 'pos_tags', 'tokens'],
num_rows: 3250
})
test: Dataset({
features: ['chunk_tags', 'id', 'ner_tags', 'pos_tags', 'tokens'],
num_rows: 3453
})
})အထူးသဖြင့်၊ dataset မှာ ကျွန်တော်တို့ အစောပိုင်းက ဖော်ပြခဲ့တဲ့ tasks သုံးခု (NER, POS, chunking) အတွက် labels တွေ ပါဝင်တာကို မြင်နိုင်ပါတယ်။ တခြား datasets တွေနဲ့ အဓိက ကွာခြားချက်ကတော့ input texts တွေဟာ sentences သို့မဟုတ် documents တွေအဖြစ် မဟုတ်ဘဲ words list တွေအဖြစ် တင်ပြထားခြင်းပါပဲ (နောက်ဆုံး column ကို tokens လို့ခေါ်ပေမယ့်၊ subword tokenization အတွက် tokenizer ကို ထပ်မံဖြတ်သန်းဖို့ လိုအပ်နေသေးတဲ့ pre-tokenized inputs တွေဖြစ်တဲ့အတွက် ၎င်းမှာ words တွေ ပါဝင်ပါတယ်)။
training set ရဲ့ ပထမဆုံး element ကို ကြည့်ရအောင်…
raw_datasets["train"][0]["tokens"]['EU', 'rejects', 'German', 'call', 'to', 'boycott', 'British', 'lamb', '.']ကျွန်တော်တို့ named entity recognition ကို လုပ်ဆောင်ချင်တာဖြစ်လို့၊ NER tags တွေကို ကြည့်ပါမယ်။
raw_datasets["train"][0]["ner_tags"][3, 0, 7, 0, 0, 0, 7, 0, 0]ဒါတွေက training အတွက် အဆင်သင့်ဖြစ်နေတဲ့ integers တွေအဖြစ် labels တွေပါ၊ ဒါပေမယ့် data ကို စစ်ဆေးကြည့်ချင်တဲ့အခါ အသုံးဝင်မှာ မဟုတ်ပါဘူး။ text classification အတွက်လိုပဲ၊ အဲဒီ integers တွေနဲ့ label names တွေကြားက ဆက်စပ်မှုကို ကျွန်တော်တို့ရဲ့ dataset ရဲ့ features attribute ကို ကြည့်ခြင်းဖြင့် ဝင်ရောက်ကြည့်ရှုနိုင်ပါတယ်။
ner_feature = raw_datasets["train"].features["ner_tags"]
ner_featureSequence(feature=ClassLabel(num_classes=9, names=['O', 'B-PER', 'I-PER', 'B-ORG', 'I-ORG', 'B-LOC', 'I-LOC', 'B-MISC', 'I-MISC'], names_file=None, id=None), length=-1, id=None)ဒါကြောင့် ဒီ column မှာ ClassLabels တွေရဲ့ sequences တွေဖြစ်တဲ့ elements တွေ ပါဝင်ပါတယ်။ sequence ရဲ့ elements အမျိုးအစားက ဒီ ner_feature ရဲ့ feature attribute ထဲမှာ ရှိပြီး၊ names list ကို အဲဒီ feature ရဲ့ names attribute ကို ကြည့်ခြင်းဖြင့် ဝင်ရောက်ကြည့်ရှုနိုင်ပါတယ်။
label_names = ner_feature.feature.names label_names
['O', 'B-PER', 'I-PER', 'B-ORG', 'I-ORG', 'B-LOC', 'I-LOC', 'B-MISC', 'I-MISC']Chapter 6 မှာ token-classification pipeline ကို နက်နက်နဲနဲ လေ့လာတုန်းက ဒီ labels တွေကို ကျွန်တော်တို့ မြင်တွေ့ခဲ့ရပြီးပါပြီ၊ ဒါပေမယ့် လျင်မြန်စွာ ပြန်လည်လေ့လာဖို့-
Oက စကားလုံးဟာ ဘယ် entity နဲ့မှ မသက်ဆိုင်ဘူးလို့ ဆိုလိုပါတယ်။B-PER/I-PERက စကားလုံးဟာ person entity တစ်ခုရဲ့အစ ဒါမှမဟုတ် အတွင်းမှာ ရှိတယ်လို့ ဆိုလိုပါတယ်။B-ORG/I-ORGက စကားလုံးဟာ organization entity တစ်ခုရဲ့အစ ဒါမှမဟုတ် အတွင်းမှာ ရှိတယ်လို့ ဆိုလိုပါတယ်။B-LOC/I-LOCက စကားလုံးဟာ location entity တစ်ခုရဲ့အစ ဒါမှမဟုတ် အတွင်းမှာ ရှိတယ်လို့ ဆိုလိုပါတယ်။B-MISC/I-MISCက စကားလုံးဟာ miscellaneous entity တစ်ခုရဲ့အစ ဒါမှမဟုတ် အတွင်းမှာ ရှိတယ်လို့ ဆိုလိုပါတယ်။
အခု ကျွန်တော်တို့ အစောပိုင်းက တွေ့ခဲ့ရတဲ့ labels တွေကို decode လုပ်လိုက်ရင် အောက်ပါအတိုင်း ရပါတယ်။
words = raw_datasets["train"][0]["tokens"]
labels = raw_datasets["train"][0]["ner_tags"]
line1 = ""
line2 = ""
for word, label in zip(words, labels):
full_label = label_names[label]
max_length = max(len(word), len(full_label))
line1 += word + " " * (max_length - len(word) + 1)
line2 += full_label + " " * (max_length - len(full_label) + 1)
print(line1)
print(line2)'EU rejects German call to boycott British lamb .'
'B-ORG O B-MISC O O O B-MISC O O'ပြီးတော့ B- နဲ့ I- labels တွေ ရောနှောထားတဲ့ ဥပမာတစ်ခုအတွက်၊ training set ရဲ့ index 4 မှာရှိတဲ့ element ပေါ်မှာ အလားတူ code က ပေးတဲ့ ရလဒ်ကတော့…
'Germany \'s representative to the European Union \'s veterinary committee Werner Zwingmann said on Wednesday consumers should buy sheepmeat from countries other than Britain until the scientific advice was clearer .'
'B-LOC O O O O B-ORG I-ORG O O O B-PER I-PER O O O O O O O O O O O B-LOC O O O O O O O'ကျွန်တော်တို့ မြင်ရတဲ့အတိုင်း၊ “European Union” နဲ့ “Werner Zwingmann” လို စကားလုံးနှစ်လုံးပါတဲ့ entities တွေက ပထမစကားလုံးအတွက် B- label နဲ့ ဒုတိယစကားလုံးအတွက် I- label ကို ရရှိပါတယ်။
✏️ သင့်အလှည့်! အဲဒီစာကြောင်းနှစ်ကြောင်းကို ၎င်းတို့ရဲ့ POS ဒါမှမဟုတ် chunking labels တွေနဲ့အတူ ပုံနှိပ်ထုတ်ဝေပါ။
ဒေတာများကို စီမံဆောင်ရွက်ခြင်း
ပုံမှန်အတိုင်းပါပဲ၊ ကျွန်တော်တို့ရဲ့ texts တွေကို model က နားလည်နိုင်ဖို့ token IDs တွေအဖြစ် ပြောင်းလဲဖို့ လိုအပ်ပါတယ်။ Chapter 6 မှာ ကျွန်တော်တို့ တွေ့ခဲ့ရတဲ့အတိုင်း၊ token classification tasks တွေမှာ အဓိကကွာခြားချက်က pre-tokenized inputs တွေ ရှိနေခြင်းပါပဲ။ ကံကောင်းစွာနဲ့ပဲ၊ tokenizer API က ဒါကို အတော်လေး လွယ်ကူစွာ ကိုင်တွယ်နိုင်ပါတယ်၊ ကျွန်တော်တို့ tokenizer ကို special flag တစ်ခုနဲ့ သတိပေးဖို့ပဲ လိုပါတယ်။
စတင်ဖို့အတွက်၊ ကျွန်တော်တို့ရဲ့ tokenizer object ကို ဖန်တီးရအောင်။ အရင်က ပြောခဲ့တဲ့အတိုင်း၊ ကျွန်တော်တို့ဟာ BERT pretrained model တစ်ခုကို အသုံးပြုမှာဖြစ်လို့၊ သက်ဆိုင်ရာ tokenizer ကို download လုပ်ပြီး cache လုပ်ခြင်းဖြင့် စတင်ပါမယ်။
from transformers import AutoTokenizer
model_checkpoint = "bert-base-cased"
tokenizer = AutoTokenizer.from_pretrained(model_checkpoint)သင် model_checkpoint ကို Hub က သင်နှစ်သက်ရာ တခြား model တစ်ခုနဲ့၊ ဒါမှမဟုတ် pretrained model နဲ့ tokenizer တစ်ခုကို သိမ်းဆည်းထားတဲ့ local folder တစ်ခုနဲ့ အစားထိုးနိုင်ပါတယ်။ တစ်ခုတည်းသော ကန့်သတ်ချက်ကတော့ tokenizer ဟာ 🤗 Tokenizers library နဲ့ ထောက်ပံ့ထားရမှာဖြစ်ပြီး၊ ဒါကြောင့် “fast” version တစ်ခု ရရှိနိုင်ရပါမယ်။ fast version ပါဝင်တဲ့ architectures အားလုံးကို ဒီဇယားကြီး မှာ ကြည့်နိုင်ပြီး၊ သင်အသုံးပြုနေတဲ့ tokenizer object က 🤗 Tokenizers နဲ့ ထောက်ပံ့ထားခြင်းရှိမရှိ စစ်ဆေးဖို့အတွက် ၎င်းရဲ့ is_fast attribute ကို ကြည့်နိုင်ပါတယ်။
tokenizer.is_fast
Truepre-tokenized input တစ်ခုကို tokenize လုပ်ဖို့၊ ကျွန်တော်တို့ရဲ့ tokenizer ကို ပုံမှန်အတိုင်း အသုံးပြုပြီး is_split_into_words=True ကို ထပ်ထည့်ပေးရုံပါပဲ။
inputs = tokenizer(raw_datasets["train"][0]["tokens"], is_split_into_words=True)
inputs.tokens()['[CLS]', 'EU', 'rejects', 'German', 'call', 'to', 'boycott', 'British', 'la', '##mb', '.', '[SEP]']ကျွန်တော်တို့ မြင်ရတဲ့အတိုင်း၊ tokenizer က model အသုံးပြုတဲ့ special tokens တွေ ([CLS] ကို အစမှာနဲ့ [SEP] ကို အဆုံးမှာ) ထည့်သွင်းပေးပြီး စကားလုံးအများစုကို မပြောင်းလဲဘဲ ထားခဲ့ပါတယ်။ သို့သော်လည်း၊ lamb ဆိုတဲ့ စကားလုံးကို subwords နှစ်ခုဖြစ်တဲ့ la နဲ့ ##mb အဖြစ် tokenize လုပ်ခဲ့ပါတယ်။ ဒါက ကျွန်တော်တို့ရဲ့ inputs နဲ့ labels တွေကြား မကိုက်ညီမှုကို ဖြစ်ပေါ်စေပါတယ်။ labels စာရင်းမှာ elements ၉ ခုပဲ ရှိပေမယ့်၊ ကျွန်တော်တို့ရဲ့ input မှာ အခု tokens ၁၂ ခု ရှိနေပါတယ်။ special tokens တွေကို ထည့်သွင်းစဉ်းစားတာက လွယ်ပါတယ် (ဒါတွေက အစနဲ့ အဆုံးမှာ ရှိတယ်ဆိုတာ ကျွန်တော်တို့ သိပါတယ်)၊ ဒါပေမယ့် labels အားလုံးကို မှန်ကန်တဲ့ words တွေနဲ့ ချိန်ညှိဖို့လည်း သေချာစေဖို့ လိုပါတယ်။
ကံကောင်းစွာနဲ့ပဲ၊ ကျွန်တော်တို့ fast tokenizer ကို အသုံးပြုနေတာကြောင့် 🤗 Tokenizers ရဲ့ စွမ်းအားတွေကို ရရှိထားပါတယ်၊ ဒါက token တစ်ခုစီကို ၎င်းရဲ့ သက်ဆိုင်ရာ word နဲ့ အလွယ်တကူ map လုပ်နိုင်တယ်လို့ ဆိုလိုပါတယ် (Chapter 6 မှာ တွေ့ခဲ့ရတဲ့အတိုင်းပါပဲ)။
inputs.word_ids()
[None, 0, 1, 2, 3, 4, 5, 6, 7, 7, 8, None]အနည်းငယ်လုပ်ဆောင်ခြင်းဖြင့်၊ ကျွန်တော်တို့ရဲ့ label list ကို tokens တွေနဲ့ ကိုက်ညီအောင် ချဲ့ထွင်နိုင်ပါတယ်။ ကျွန်တော်တို့ အသုံးပြုမယ့် ပထမဆုံး စည်းမျဉ်းကတော့ special tokens တွေက -100 ဆိုတဲ့ label ကို ရရှိမှာ ဖြစ်ပါတယ်။ ဒါက default အားဖြင့် -100 က ကျွန်တော်တို့ အသုံးပြုမယ့် loss function (cross entropy) မှာ လျစ်လျူရှုခံရတဲ့ index တစ်ခုဖြစ်လို့ပါ။ ပြီးတော့၊ token တစ်ခုစီဟာ ၎င်းပါဝင်တဲ့ word ရဲ့ အစက token နဲ့ တူညီတဲ့ label ကို ရရှိပါတယ်။ ဘာလို့လဲဆိုတော့ ၎င်းတို့ဟာ entity တစ်ခုတည်းရဲ့ အစိတ်အပိုင်းဖြစ်လို့ပါပဲ။ word အတွင်းမှာရှိပေမယ့် အစမှာမရှိတဲ့ tokens တွေအတွက်တော့ B- ကို I- နဲ့ အစားထိုးပါမယ် (ဘာလို့လဲဆိုတော့ token က entity ရဲ့ အစမဟုတ်လို့ပါ)။
def align_labels_with_tokens(labels, word_ids):
new_labels = []
current_word = None
for word_id in word_ids:
if word_id != current_word:
# Start of a new word!
current_word = word_id
label = -100 if word_id is None else labels[word_id]
new_labels.append(label)
elif word_id is None:
# Special token
new_labels.append(-100)
else:
# Same word as previous token
label = labels[word_id]
# If the label is B-XXX we change it to I-XXX
if label % 2 == 1:
label += 1
new_labels.append(label)
return new_labelsကျွန်တော်တို့ရဲ့ ပထမဆုံးစာကြောင်းပေါ်မှာ စမ်းကြည့်ရအောင်…
labels = raw_datasets["train"][0]["ner_tags"]
word_ids = inputs.word_ids()
print(labels)
print(align_labels_with_tokens(labels, word_ids))[3, 0, 7, 0, 0, 0, 7, 0, 0]
[-100, 3, 0, 7, 0, 0, 0, 7, 0, 0, 0, -100]ကျွန်တော်တို့ မြင်ရတဲ့အတိုင်း၊ ကျွန်တော်တို့ရဲ့ function က အစနဲ့ အဆုံးမှာရှိတဲ့ special tokens နှစ်ခုအတွက် -100 ကို ထည့်သွင်းပေးခဲ့ပြီး၊ tokens နှစ်ခုအဖြစ် ပိုင်းခြားခံရတဲ့ ကျွန်တော်တို့ရဲ့ word အတွက် 0 အသစ်တစ်ခု ထည့်သွင်းပေးခဲ့ပါတယ်။
✏️ သင့်အလှည့်! သုတေသီအချို့က word တစ်ခုအတွက် label တစ်ခုတည်းကိုသာ သတ်မှတ်ပြီး၊ ပေးထားတဲ့ word ထဲက ကျန်ရှိတဲ့ subtokens တွေကို
-100သတ်မှတ်ဖို့ ပိုနှစ်သက်ကြပါတယ်။ ဒါက subtokens များစွာအဖြစ် ပိုင်းခြားတဲ့ ရှည်လျားတဲ့ words တွေက loss ကို အလွန်အမင်း ထိခိုက်စေတာကို ရှောင်ရှားဖို့ပါပဲ။ ဒီစည်းမျဉ်းကို လိုက်နာပြီး input IDs တွေနဲ့ labels တွေကို ချိန်ညှိဖို့ အရင် function ကို ပြောင်းလဲပါ။
ကျွန်တော်တို့ရဲ့ dataset တစ်ခုလုံးကို preprocess လုပ်ဖို့အတွက်၊ inputs အားလုံးကို tokenize လုပ်ပြီး labels အားလုံးပေါ်မှာ align_labels_with_tokens() ကို အသုံးပြုဖို့ လိုအပ်ပါတယ်။ ကျွန်တော်တို့ရဲ့ fast tokenizer ရဲ့ အမြန်နှုန်းကို အကျိုးယူဖို့အတွက်၊ texts များစွာကို တစ်ပြိုင်နက်တည်း tokenize လုပ်တာ အကောင်းဆုံးပါပဲ။ ဒါကြောင့် ကျွန်တော်တို့ဟာ examples list တစ်ခုကို process လုပ်မယ့် function တစ်ခုကို ရေးပြီး Dataset.map() method ကို batched=True option နဲ့ အသုံးပြုပါမယ်။ ကျွန်တော်တို့ရဲ့ ယခင်ဥပမာနဲ့ ကွာခြားတဲ့ တစ်ခုတည်းသောအရာကတော့ word_ids() function က tokenizer ရဲ့ inputs တွေက texts list (သို့မဟုတ် ကျွန်တော်တို့ရဲ့ ကိစ္စမှာ words list များ၏ list) တွေဖြစ်တဲ့အခါ၊ word IDs တွေရဲ့ index ကို ရယူဖို့ လိုအပ်တာကြောင့် ကျွန်တော်တို့ အဲဒါကိုလည်း ထည့်သွင်းထားပါတယ်။
def tokenize_and_align_labels(examples):
tokenized_inputs = tokenizer(
examples["tokens"], truncation=True, is_split_into_words=True
)
all_labels = examples["ner_tags"]
new_labels = []
for i, labels in enumerate(all_labels):
word_ids = tokenized_inputs.word_ids(i)
new_labels.append(align_labels_with_tokens(labels, word_ids))
tokenized_inputs["labels"] = new_labels
return tokenized_inputsကျွန်တော်တို့ inputs တွေကို အခုထိ padding မလုပ်ရသေးဘူးဆိုတာ သတိပြုပါ။ ဒါကို နောက်မှ data collator နဲ့ batches တွေ ဖန်တီးတဲ့အခါ လုပ်ပါမယ်။
အခုဆိုရင် ကျွန်တော်တို့ရဲ့ dataset ရဲ့ တခြား splits တွေပေါ်မှာ preprocessing အားလုံးကို တစ်ပြိုင်နက်တည်း အသုံးပြုနိုင်ပါပြီ။
tokenized_datasets = raw_datasets.map(
tokenize_and_align_labels,
batched=True,
remove_columns=raw_datasets["train"].column_names,
)အခက်ခဲဆုံးအပိုင်းကို ကျွန်တော်တို့ လုပ်ဆောင်ခဲ့ပြီးပါပြီ။ Data ကို preprocess လုပ်ပြီးပြီဆိုတော့၊ တကယ်တမ်း training လုပ်တာက Chapter 3 မှာ ကျွန်တော်တို့ လုပ်ခဲ့တာနဲ့ အတော်လေး ဆင်တူပါလိမ့်မယ်။
Trainer API ဖြင့် Model ကို Fine-tuning လုပ်ခြင်း
Trainer ကို အသုံးပြုတဲ့ code က အရင်ကလိုပဲ ဖြစ်ပါလိမ့်မယ်။ ပြောင်းလဲမှုတွေကတော့ data ကို batch တစ်ခုအဖြစ် စုစည်းပုံနဲ့ metric computation function တွေပဲ ဖြစ်ပါတယ်။
Data Collation
Chapter 3 မှာလိုပဲ DataCollatorWithPadding ကို အသုံးပြုလို့ မရပါဘူး။ ဘာလို့လဲဆိုတော့ အဲဒါက inputs (input IDs, attention mask, token type IDs) တွေကိုပဲ padding လုပ်ပေးလို့ပါ။ ဒီနေရာမှာ ကျွန်တော်တို့ရဲ့ labels တွေကို inputs တွေအတိုင်း အရွယ်အစားတူညီအောင် padding လုပ်သင့်ပြီး၊ -100 ကို value အဖြစ် အသုံးပြုသင့်ပါတယ်။ ဒါမှ သက်ဆိုင်ရာ predictions တွေကို loss computation မှာ လျစ်လျူရှုနိုင်မှာပါ။
ဒါတွေအားလုံးကို DataCollatorForTokenClassification က လုပ်ဆောင်ပေးပါတယ်။ DataCollatorWithPadding လိုပဲ၊ ဒါက inputs တွေကို preprocess လုပ်ဖို့ အသုံးပြုတဲ့ tokenizer ကို ယူပါတယ်။
from transformers import DataCollatorForTokenClassification
data_collator = DataCollatorForTokenClassification(tokenizer=tokenizer)examples အနည်းငယ်ပေါ်မှာ ဒါကို စမ်းသပ်ဖို့အတွက်၊ ကျွန်တော်တို့ရဲ့ tokenized training set ကနေ examples list တစ်ခုပေါ်မှာ ခေါ်လိုက်ရုံပါပဲ။
batch = data_collator([tokenized_datasets["train"][i] for i in range(2)])
batch["labels"]tensor([[-100, 3, 0, 7, 0, 0, 0, 7, 0, 0, 0, -100],
[-100, 1, 2, -100, -100, -100, -100, -100, -100, -100, -100, -100]])ကျွန်တော်တို့ရဲ့ dataset ထဲက ပထမဆုံးနဲ့ ဒုတိယ elements တွေအတွက် labels တွေနဲ့ နှိုင်းယှဉ်ကြည့်ရအောင်။
for i in range(2):
print(tokenized_datasets["train"][i]["labels"])[-100, 3, 0, 7, 0, 0, 0, 7, 0, 0, 0, -100]
[-100, 1, 2, -100]ကျွန်တော်တို့ မြင်ရတဲ့အတိုင်း၊ ဒုတိယ label set ကို -100 တွေကို အသုံးပြုပြီး ပထမဆုံး label set ရဲ့ အရှည်အထိ padding လုပ်ထားပါတယ်။
Metrics
Trainer က epoch တိုင်း metric တစ်ခုကို တွက်ချက်ဖို့အတွက်၊ predictions နဲ့ labels array တွေကို ယူပြီး metric names နဲ့ values ပါဝင်တဲ့ dictionary တစ်ခုကို ပြန်ပေးမယ့် compute_metrics() function တစ်ခုကို ကျွန်တော်တို့ သတ်မှတ်ဖို့ လိုအပ်ပါလိမ့်မယ်။
token classification prediction ကို အကဲဖြတ်ဖို့ အသုံးပြုတဲ့ traditional framework ကတော့ seqeval ဖြစ်ပါတယ်။ ဒီ metric ကို အသုံးပြုဖို့၊ ကျွန်တော်တို့ seqeval library ကို အရင်ဆုံး install လုပ်ဖို့ လိုအပ်ပါတယ်။
!pip install seqeval
ဒါဆိုရင် Chapter 3 မှာ လုပ်ခဲ့သလိုပဲ evaluate.load() function မှတစ်ဆင့် load လုပ်နိုင်ပါပြီ။
import evaluate
metric = evaluate.load("seqeval")ဒီ metric က standard accuracy လိုမျိုး အလုပ်မလုပ်ပါဘူး- ၎င်းက lists of labels တွေကို integers အဖြစ် မဟုတ်ဘဲ strings အဖြစ် ယူမှာဖြစ်လို့၊ metric ကို မပေးခင် predictions နဲ့ labels တွေကို အပြည့်အဝ decode လုပ်ဖို့ ကျွန်တော်တို့ လိုအပ်ပါလိမ့်မယ်။ ဒါက ဘယ်လိုအလုပ်လုပ်လဲဆိုတာ ကြည့်ရအောင်။ ပထမဆုံး၊ ကျွန်တော်တို့ရဲ့ ပထမဆုံး training example အတွက် labels တွေကို ရယူပါမယ်-
labels = raw_datasets["train"][0]["ner_tags"]
labels = [label_names[i] for i in labels]
labels['B-ORG', 'O', 'B-MISC', 'O', 'O', 'O', 'B-MISC', 'O', 'O']ဒါဆိုရင် index 2 မှာရှိတဲ့ value ကို ပြောင်းလဲခြင်းဖြင့် အဲဒီအတွက် fake predictions တွေကို ဖန်တီးနိုင်ပါတယ်။
predictions = labels.copy()
predictions[2] = "O"
metric.compute(predictions=[predictions], references=[labels])metric က predictions list တစ်ခု (တစ်ခုတည်းမဟုတ်) နဲ့ labels list တစ်ခုကို ယူတယ်ဆိုတာ သတိပြုပါ။ ဒီမှာ output ပါ…
{'MISC': {'precision': 1.0, 'recall': 0.5, 'f1': 0.67, 'number': 2},
'ORG': {'precision': 1.0, 'recall': 1.0, 'f1': 1.0, 'number': 1},
'overall_precision': 1.0,
'overall_recall': 0.67,
'overall_f1': 0.8,
'overall_accuracy': 0.89}ဒါက အချက်အလက်များစွာကို ပြန်လည်ပေးပို့နေပါတယ်။ ကျွန်တော်တို့ဟာ entity တစ်ခုစီအတွက် precision, recall, F1 score တွေအပြင် overall score တွေပါ ရရှိပါတယ်။ ကျွန်တော်တို့ရဲ့ metric computation အတွက် overall score ကိုပဲ ထားရှိပါမယ်၊ ဒါပေမယ့် သင် report လုပ်ချင်တဲ့ metrics အားလုံးကို ပြန်ပေးဖို့ compute_metrics() function ကို စိတ်ကြိုက်ပြင်ဆင်နိုင်ပါတယ်။
ဒီ compute_metrics() function က ပထမဆုံး logits တွေကို predictions တွေအဖြစ် ပြောင်းလဲဖို့ argmax ကို ယူပါတယ် (ပုံမှန်အတိုင်းပါပဲ၊ logits နဲ့ probabilities တွေက အစဉ်လိုက် တူညီတာကြောင့် softmax ကို အသုံးပြုဖို့ မလိုအပ်ပါဘူး)။ ဒါဆိုရင် labels နဲ့ predictions နှစ်ခုလုံးကို integers ကနေ strings တွေအဖြစ် ပြောင်းလဲရပါမယ်။ label က -100 ဖြစ်နေတဲ့ values အားလုံးကို ဖယ်ရှားပြီးမှ ရလဒ်တွေကို metric.compute() method ကို ပေးပို့ပါတယ်။
import numpy as np
def compute_metrics(eval_preds):
logits, labels = eval_preds
predictions = np.argmax(logits, axis=-1)
# လျစ်လျူရှုထားသော index (special tokens) များကို ဖယ်ရှားပြီး labels အဖြစ် ပြောင်းလဲပါ။
true_labels = [[label_names[l] for l in label if l != -100] for label in labels]
true_predictions = [
[label_names[p] for (p, l) in zip(prediction, label) if l != -100]
for prediction, label in zip(predictions, labels)
]
all_metrics = metric.compute(predictions=true_predictions, references=true_labels)
return {
"precision": all_metrics["overall_precision"],
"recall": all_metrics["overall_recall"],
"f1": all_metrics["overall_f1"],
"accuracy": all_metrics["overall_accuracy"],
}ဒါပြီးသွားပြီဆိုတော့၊ ကျွန်တော်တို့ Trainer ကို သတ်မှတ်ဖို့ နီးပါး အဆင်သင့်ဖြစ်ပါပြီ။ ကျွန်တော်တို့မှာ fine-tune လုပ်ဖို့ model တစ်ခုပဲ လိုအပ်ပါတော့တယ်။
Model ကို သတ်မှတ်ခြင်း
ကျွန်တော်တို့ token classification problem ပေါ်မှာ အလုပ်လုပ်နေတာကြောင့်၊ AutoModelForTokenClassification class ကို ကျွန်တော်တို့ အသုံးပြုပါမယ်။ ဒီ model ကို သတ်မှတ်တဲ့အခါ အဓိက မှတ်ထားရမယ့်အချက်ကတော့ ကျွန်တော်တို့မှာရှိတဲ့ labels အရေအတွက်အကြောင်း အချက်အလက်အချို့ကို ပေးပို့ဖို့ပါပဲ။ ဒီလိုလုပ်ဖို့ အလွယ်ကူဆုံးနည်းလမ်းကတော့ num_labels argument နဲ့ အဲဒီအရေအတွက်ကို ပေးဖို့ပါပဲ။ ဒါပေမယ့် ဒီအပိုင်းရဲ့ အစမှာ ကျွန်တော်တို့ မြင်တွေ့ခဲ့ရတဲ့ Inference widget ကဲ့သို့ ကောင်းမွန်တဲ့ widget တစ်ခု လိုချင်ရင်တော့ မှန်ကန်တဲ့ label correspondences တွေကို သတ်မှတ်တာက ပိုကောင်းပါတယ်။
၎င်းတို့ကို id2label နဲ့ label2id ဆိုတဲ့ dictionaries နှစ်ခုဖြင့် သတ်မှတ်သင့်ပါတယ်။ ဒါတွေက ID ကနေ label သို့၊ label ကနေ ID သို့ mapping တွေ ပါဝင်ပါတယ်။
id2label = {i: label for i, label in enumerate(label_names)}
label2id = {v: k for k, v in id2label.items()}အခုဆိုရင် ကျွန်တော်တို့ ဒါတွေကို AutoModelForTokenClassification.from_pretrained() method ကို ပေးလိုက်ရုံပါပဲ။ ဒါတွေက model ရဲ့ configuration မှာ သတ်မှတ်ခံရပြီး၊ ကောင်းမွန်စွာ သိမ်းဆည်းပြီး Hub ကို upload လုပ်ပါလိမ့်မယ်။
from transformers import AutoModelForTokenClassification
model = AutoModelForTokenClassification.from_pretrained(
model_checkpoint,
id2label=id2label,
label2id=label2id,
)Chapter 3 မှာ ကျွန်တော်တို့ AutoModelForSequenceClassification ကို သတ်မှတ်ခဲ့တုန်းကလိုပဲ၊ model ကို ဖန်တီးတာက weights အချို့ (pretraining head က weights တွေ) ကို အသုံးမပြုခဲ့ဘူး၊ တခြား weights အချို့ (new token classification head က weights တွေ) ကို random အဖြစ် initialized လုပ်ခဲ့တယ်ဆိုတဲ့ warning တစ်ခုကို ထုတ်ပေးပြီး၊ ဒီ model ကို train လုပ်သင့်တယ်လို့ ဆိုပါတယ်။ ကျွန်တော်တို့ ခဏအတွင်းမှာ ဒါကို လုပ်ပါမယ်၊ ဒါပေမယ့် ပထမဆုံး ကျွန်တော်တို့ရဲ့ model မှာ မှန်ကန်တဲ့ labels အရေအတွက် ရှိမရှိ ထပ်မံစစ်ဆေးကြည့်ရအောင်။
model.config.num_labels
9⚠️ သင့် model မှာ labels အရေအတွက် မှားနေတယ်ဆိုရင်၊ နောက်ပိုင်းမှာ
Trainer.train()method ကို ခေါ်တဲ့အခါ မရှင်းလင်းတဲ့ error တစ်ခု ရရှိပါလိမ့်မယ် (ဥပမာ “CUDA error: device-side assert triggered” လိုမျိုး)။ ဒီလို error တွေအတွက် users တွေက report လုပ်တဲ့ bug တွေရဲ့ နံပါတ်တစ် အကြောင်းအရင်းဖြစ်တာကြောင့်၊ မျှော်လင့်ထားတဲ့ labels အရေအတွက် ရှိမရှိ သေချာစေဖို့ ဒီစစ်ဆေးမှုကို လုပ်ဖို့ သေချာလုပ်ပါ။
Model ကို Fine-tuning လုပ်ခြင်း
ကျွန်တော်တို့ရဲ့ model ကို train လုပ်ဖို့ အခု အဆင်သင့်ဖြစ်ပါပြီ။ ကျွန်တော်တို့ Trainer ကို မသတ်မှတ်ခင် နောက်ဆုံးလုပ်ရမယ့် အလုပ်နှစ်ခုပဲ ကျန်ပါတော့တယ်၊ Hugging Face ကို login ဝင်ပြီး ကျွန်တော်တို့ရဲ့ training arguments တွေကို သတ်မှတ်ဖို့ပါပဲ။ သင် notebook မှာ အလုပ်လုပ်နေတယ်ဆိုရင်၊ ဒီအတွက် ကူညီပေးမယ့် convenience function တစ်ခု ရှိပါတယ်။
from huggingface_hub import notebook_login
notebook_login()ဒါက သင်ရဲ့ Hugging Face login credentials တွေကို ထည့်သွင်းနိုင်မယ့် widget တစ်ခုကို ပြသပါလိမ့်မယ်။
သင် notebook မှာ အလုပ်မလုပ်ဘူးဆိုရင်၊ သင့် terminal မှာ အောက်ပါစာကြောင်းကို ရိုက်ထည့်လိုက်ရုံပါပဲ။
huggingface-cli login
ဒါပြီးသွားတာနဲ့၊ ကျွန်တော်တို့ TrainingArguments တွေကို သတ်မှတ်နိုင်ပါပြီ။
from transformers import TrainingArguments
args = TrainingArguments(
"bert-finetuned-ner",
evaluation_strategy="epoch",
save_strategy="epoch",
learning_rate=2e-5,
num_train_epochs=3,
weight_decay=0.01,
push_to_hub=True,
)ဒါတွေအများစုကို သင်အရင်က မြင်ဖူးပြီးသားပါ၊ ကျွန်တော်တို့ hyperparameters အချို့ကို သတ်မှတ်ပါတယ် (learning rate, train လုပ်မယ့် epochs အရေအတွက်, weight decay လိုမျိုး)၊ ပြီးတော့ model ကို save လုပ်ပြီး epoch တိုင်းရဲ့အဆုံးမှာ evaluate လုပ်ချင်တယ်၊ ကျွန်တော်တို့ရဲ့ ရလဒ်တွေကို Model Hub ကို upload လုပ်ချင်တယ်ဆိုတာ ဖော်ပြဖို့ push_to_hub=True ကို သတ်မှတ်ပါတယ်။ သင် push လုပ်ချင်တဲ့ repository ရဲ့ နာမည်ကို hub_model_id argument နဲ့ သတ်မှတ်နိုင်တယ်ဆိုတာ သတိပြုပါ (အထူးသဖြင့်၊ organization တစ်ခုသို့ push လုပ်ဖို့အတွက် ဒီ argument ကို အသုံးပြုရပါလိမ့်မယ်)။ ဥပမာအားဖြင့်၊ ကျွန်တော်တို့ model ကို huggingface-course organization ကို push လုပ်ခဲ့တုန်းက၊ TrainingArguments မှာ hub_model_id="huggingface-course/bert-finetuned-ner" ကို ထပ်ထည့်ခဲ့ပါတယ်။ default အားဖြင့်၊ အသုံးပြုတဲ့ repository က သင့် namespace ထဲမှာရှိပြီး သင်သတ်မှတ်ထားတဲ့ output directory နာမည်အတိုင်း ဖြစ်ပါလိမ့်မယ်၊ ဒါကြောင့် ကျွန်တော်တို့ရဲ့ ကိစ္စမှာတော့ "sgugger/bert-finetuned-ner" ဖြစ်ပါလိမ့်မယ်။
💡 သင်အသုံးပြုနေတဲ့ output directory က ရှိပြီးသားဆိုရင်၊ ဒါက သင် push လုပ်ချင်တဲ့ repository ရဲ့ local clone တစ်ခု ဖြစ်ဖို့ လိုအပ်ပါတယ်။ မဟုတ်ဘူးဆိုရင်၊ သင့်
Trainerကို သတ်မှတ်တဲ့အခါ error တစ်ခု ရရှိမှာဖြစ်ပြီး နာမည်အသစ်တစ်ခု သတ်မှတ်ဖို့ လိုပါလိမ့်မယ်။
နောက်ဆုံးအနေနဲ့၊ အရာအားလုံးကို Trainer ကို ပေးပြီး training ကို စတင်လိုက်ရုံပါပဲ။
from transformers import Trainer
trainer = Trainer(
model=model,
args=args,
train_dataset=tokenized_datasets["train"],
eval_dataset=tokenized_datasets["validation"],
data_collator=data_collator,
compute_metrics=compute_metrics,
processing_class=tokenizer,
)
trainer.train()training ဖြစ်နေစဉ်မှာ၊ model ကို သိမ်းဆည်းတဲ့အခါတိုင်း (ဒီနေရာမှာတော့ epoch တိုင်း) ဒါကို နောက်ကွယ်မှာ Hub ကို upload လုပ်ပါတယ်ဆိုတာ သတိပြုပါ။ ဒီနည်းနဲ့၊ လိုအပ်ရင် တခြား machine တစ်ခုပေါ်မှာ သင်ရဲ့ training ကို ပြန်လည်စတင်နိုင်ပါလိမ့်မယ်။
training ပြီးသွားတာနဲ့၊ model ရဲ့ နောက်ဆုံး version ကို upload လုပ်ဖို့ push_to_hub() method ကို ကျွန်တော်တို့ အသုံးပြုပါတယ်။
trainer.push_to_hub(commit_message="Training complete")ဒီ command က သင်အခုလေးတင် လုပ်ခဲ့တဲ့ commit ရဲ့ URL ကို ပြန်ပေးပါတယ်။ သင်စစ်ဆေးကြည့်ချင်တယ်ဆိုရင်ပေါ့။
'https://huggingface.co/sgugger/bert-finetuned-ner/commit/26ab21e5b1568f9afeccdaed2d8715f571d786ed'Trainer က evaluation results အားလုံးပါဝင်တဲ့ model card တစ်ခုကိုလည်း ရေးဆွဲပြီး upload လုပ်ပါတယ်။ ဒီအဆင့်မှာ၊ Model Hub ပေါ်က inference widget ကို အသုံးပြုပြီး သင့် model ကို စမ်းသပ်ကာ သင့်သူငယ်ချင်းတွေနဲ့ မျှဝေနိုင်ပါတယ်။ သင်ဟာ token classification task တစ်ခုပေါ်မှာ model တစ်ခုကို အောင်မြင်စွာ fine-tune လုပ်ခဲ့ပြီးပါပြီ — ဂုဏ်ယူပါတယ်!
သင် training loop ကို နက်နက်နဲနဲ လေ့လာချင်တယ်ဆိုရင်၊ အခု ကျွန်တော်တို့ 🤗 Accelerate ကို အသုံးပြုပြီး အလားတူ လုပ်ဆောင်ပုံကို ပြသပါမယ်။
Custom Training Loop တစ်ခု
အခုဆိုရင် အပြည့်အစုံ training loop ကို ကြည့်ရအောင်၊ ဒါမှ သင်လိုအပ်တဲ့ အစိတ်အပိုင်းတွေကို အလွယ်တကူ customize လုပ်နိုင်မှာပါ။ ဒါက Chapter 3 မှာ ကျွန်တော်တို့ လုပ်ခဲ့တာနဲ့ အတော်လေး ဆင်တူပါလိမ့်မယ်။ evaluation အတွက် အပြောင်းအလဲ အနည်းငယ်ရှိပါမယ်။
Training အတွက် အရာအားလုံးကို ပြင်ဆင်ခြင်း
ပထမဆုံး ကျွန်တော်တို့ datasets တွေကနေ DataLoaders တွေကို တည်ဆောက်ဖို့ လိုပါတယ်။ ကျွန်တော်တို့ရဲ့ data_collator ကို collate_fn အဖြစ် ပြန်လည်အသုံးပြုပြီး training set ကို shuffle လုပ်ပါမယ်၊ ဒါပေမယ့် validation set ကိုတော့ shuffle လုပ်မှာ မဟုတ်ပါဘူး။
from torch.utils.data import DataLoader
train_dataloader = DataLoader(
tokenized_datasets["train"],
shuffle=True,
collate_fn=data_collator,
batch_size=8,
)
eval_dataloader = DataLoader(
tokenized_datasets["validation"], collate_fn=data_collator, batch_size=8
)နောက်ဆုံးအနေနဲ့ ကျွန်တော်တို့ model ကို ပြန်လည် instantiate လုပ်ပါမယ်။ ဒါက အရင်က fine-tuning ကို ဆက်လုပ်တာ မဟုတ်ဘဲ BERT pretrained model ကနေ ပြန်စတာ သေချာစေဖို့ပါ။
model = AutoModelForTokenClassification.from_pretrained(
model_checkpoint,
id2label=id2label,
label2id=label2id,
)ဒါဆိုရင် optimizer တစ်ခု လိုအပ်ပါလိမ့်မယ်။ AdamW ကို ကျွန်တော်တို့ အသုံးပြုပါမယ်။ ဒါက Adam နဲ့ ဆင်တူပေမယ့် weight decay ကို အသုံးပြုပုံမှာ ပြင်ဆင်ချက်တစ်ခု ပါဝင်ပါတယ်။
from torch.optim import AdamW
optimizer = AdamW(model.parameters(), lr=2e-5)အဲဒီ objects တွေအားလုံး ရပြီဆိုတာနဲ့၊ ၎င်းတို့ကို accelerator.prepare() method ကို ပေးပို့နိုင်ပါပြီ။
from accelerate import Accelerator
accelerator = Accelerator()
model, optimizer, train_dataloader, eval_dataloader = accelerator.prepare(
model, optimizer, train_dataloader, eval_dataloader
)🚨 သင် TPU ပေါ်မှာ train လုပ်နေတယ်ဆိုရင်၊ အထက်ပါ cell ကနေ စတင်တဲ့ code အားလုံးကို သီးခြား training function တစ်ခုထဲသို့ ရွှေ့ဖို့ လိုပါလိမ့်မယ်။ အသေးစိတ်အချက်အလက်တွေအတွက် Chapter 3 ကို ကြည့်ပါ။
ကျွန်တော်တို့ train_dataloader ကို accelerator.prepare() ကို ပေးပို့ပြီးတာနဲ့၊ training steps အရေအတွက်ကို တွက်ချက်ဖို့ ၎င်းရဲ့ length ကို အသုံးပြုနိုင်ပါတယ်။ dataloader ကို ပြင်ဆင်ပြီးမှ ဒါကို အမြဲတမ်းလုပ်သင့်တယ်ဆိုတာ မှတ်ထားပါ၊ ဘာလို့လဲဆိုတော့ အဲဒီ method က ၎င်းရဲ့ length ကို ပြောင်းလဲမှာ ဖြစ်လို့ပါပဲ။ learning rate ကနေ 0 အထိ classic linear schedule ကို ကျွန်တော်တို့ အသုံးပြုပါတယ်။
from transformers import get_scheduler
num_train_epochs = 3
num_update_steps_per_epoch = len(train_dataloader)
num_training_steps = num_train_epochs * num_update_steps_per_epoch
lr_scheduler = get_scheduler(
"linear",
optimizer=optimizer,
num_warmup_steps=0,
num_training_steps=num_training_steps,
)နောက်ဆုံးအနေနဲ့၊ ကျွန်တော်တို့ model ကို Hub ကို push လုပ်ဖို့အတွက်၊ working folder တစ်ခုထဲမှာ Repository object တစ်ခု ဖန်တီးဖို့ လိုအပ်ပါလိမ့်မယ်။ ပထမဆုံး Hugging Face ကို login ဝင်ပါ၊ အကယ်၍ သင် login မဝင်ရသေးဘူးဆိုရင်ပေါ့။ ကျွန်တော်တို့ model ကို ပေးချင်တဲ့ model ID ကနေ repository name ကို ကျွန်တော်တို့ သတ်မှတ်ပါမယ် (သင်နှစ်သက်ရာ repo_name ကို အစားထိုးနိုင်ပါတယ်၊ ၎င်းမှာ သင့် username ပါဝင်ဖို့ပဲ လိုအပ်ပါတယ်၊ ဒါက get_full_repo_name() function က လုပ်ဆောင်တာပါ)။
from huggingface_hub import Repository, get_full_repo_name
model_name = "bert-finetuned-ner-accelerate"
repo_name = get_full_repo_name(model_name)
repo_name'sgugger/bert-finetuned-ner-accelerate'ဒါဆိုရင် အဲဒီ repository ကို local folder တစ်ခုထဲမှာ clone လုပ်နိုင်ပါတယ်။ အဲဒါက ရှိပြီးသားဆိုရင်၊ ဒီ local folder က ကျွန်တော်တို့ အလုပ်လုပ်နေတဲ့ repository ရဲ့ ရှိပြီးသား clone တစ်ခု ဖြစ်ရပါမယ်။
output_dir = "bert-finetuned-ner-accelerate"
repo = Repository(output_dir, clone_from=repo_name)အခုဆိုရင် output_dir ထဲမှာ ကျွန်တော်တို့ သိမ်းဆည်းထားတဲ့ ဘယ်အရာကိုမဆို repo.push_to_hub() method ကို ခေါ်ခြင်းဖြင့် upload လုပ်နိုင်ပါပြီ။ ဒါက epoch တစ်ခုစီရဲ့အဆုံးမှာ intermediate models တွေကို upload လုပ်ဖို့ ကူညီပါလိမ့်မယ်။
Training Loop
အခုဆိုရင် အပြည့်အစုံ training loop ကို ရေးဖို့ အဆင်သင့်ဖြစ်ပါပြီ။ ၎င်းရဲ့ evaluation အပိုင်းကို ရိုးရှင်းစေဖို့၊ predictions နဲ့ labels တွေကို ကျွန်တော်တို့ရဲ့ metric object က မျှော်လင့်ထားတဲ့အတိုင်း strings list တွေအဖြစ် ပြောင်းလဲပေးတဲ့ postprocess() function ကို ကျွန်တော်တို့ သတ်မှတ်ပါတယ်။
def postprocess(predictions, labels):
predictions = predictions.detach().cpu().clone().numpy()
labels = labels.detach().cpu().clone().numpy()
# လျစ်လျူရှုထားသော index (special tokens) များကို ဖယ်ရှားပြီး labels အဖြစ် ပြောင်းလဲပါ
true_labels = [[label_names[l] for l in label if l != -100] for label in labels]
true_predictions = [
[label_names[p] for (p, l) in zip(prediction, label) if l != -100]
for prediction, label in zip(predictions, labels)
]
return true_labels, true_predictionsဒါဆိုရင် training loop ကို ရေးနိုင်ပါပြီ။ training ဘယ်လိုသွားလဲဆိုတာကို လိုက်နာဖို့ progress bar တစ်ခု သတ်မှတ်ပြီးနောက်၊ loop မှာ အပိုင်းသုံးပိုင်း ရှိပါတယ်။
- Training ကိုယ်တိုင်၊ ဒါက
train_dataloaderပေါ်မှာ classic iteration၊ model ကို forward pass လုပ်ခြင်း၊ ပြီးတော့ backward pass နဲ့ optimizer step တို့ ဖြစ်ပါတယ်။ - Evaluation မှာ၊ batch ပေါ်မှာ ကျွန်တော်တို့ရဲ့ model ရဲ့ outputs တွေကို ရပြီးနောက် ထူးခြားချက်တစ်ခု ရှိပါတယ်၊ processes နှစ်ခုက inputs တွေနဲ့ labels တွေကို မတူညီတဲ့ shapes တွေအထိ padding လုပ်ထားနိုင်တာကြောင့်၊
gather()method ကို မခေါ်ခင် predictions နဲ့ labels တွေကို တူညီတဲ့ shape ဖြစ်စေဖို့accelerator.pad_across_processes()ကို အသုံးပြုဖို့ လိုပါတယ်။ ဒါကို မလုပ်ဘူးဆိုရင်၊ evaluation က error ဖြစ်သွားမှာ ဒါမှမဟုတ် ထာဝရ ရပ်တန့်နေမှာပါ။ ပြီးရင် ရလဒ်တွေကိုmetric.add_batch()ကို ပေးပို့ပြီး evaluation loop ပြီးသွားတာနဲ့metric.compute()ကို ခေါ်ပါတယ်။ - Saving နဲ့ uploading မှာ၊ ကျွန်တော်တို့ model နဲ့ tokenizer ကို အရင်သိမ်းဆည်းပြီးမှ၊
repo.push_to_hub()ကို ခေါ်ပါတယ်။ 🤗 Hub library ကို asynchronous process မှာ push လုပ်ဖို့ ပြောဖို့blocking=Falseargument ကို ကျွန်တော်တို့ အသုံးပြုတယ်ဆိုတာ သတိပြုပါ။ ဒီနည်းနဲ့၊ training က ပုံမှန်အတိုင်း ဆက်လက်လုပ်ဆောင်ပြီး ဒီ (ရှည်လျားတဲ့) instruction က နောက်ကွယ်မှာ execute ဖြစ်ပါတယ်။
ဒီမှာ training loop အတွက် အပြည့်အစုံ code ပါ။
from tqdm.auto import tqdm
import torch
progress_bar = tqdm(range(num_training_steps))
for epoch in range(num_train_epochs):
# Training
model.train()
for batch in train_dataloader:
outputs = model(**batch)
loss = outputs.loss
accelerator.backward(loss)
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
progress_bar.update(1)
# Evaluation
model.eval()
for batch in eval_dataloader:
with torch.no_grad():
outputs = model(**batch)
predictions = outputs.logits.argmax(dim=-1)
labels = batch["labels"]
# predictions နဲ့ labels တွေကို gather လုပ်ဖို့ padding လုပ်ဖို့ လိုအပ်ပါတယ်
predictions = accelerator.pad_across_processes(predictions, dim=1, pad_index=-100)
labels = accelerator.pad_across_processes(labels, dim=1, pad_index=-100)
predictions_gathered = accelerator.gather(predictions)
labels_gathered = accelerator.gather(labels)
true_predictions, true_labels = postprocess(predictions_gathered, labels_gathered)
metric.add_batch(predictions=true_predictions, references=true_labels)
results = metric.compute()
print(
f"epoch {epoch}:",
{
key: results[f"overall_{key}"]
for key in ["precision", "recall", "f1", "accuracy"]
},
)
# သိမ်းဆည်းပြီး upload လုပ်ပါ
accelerator.wait_for_everyone()
unwrapped_model = accelerator.unwrap_model(model)
unwrapped_model.save_pretrained(output_dir, save_function=accelerator.save)
if accelerator.is_main_process:
tokenizer.save_pretrained(output_dir)
repo.push_to_hub(
commit_message=f"Training in progress epoch {epoch}", blocking=False
)ဒါက 🤗 Accelerate နဲ့ save လုပ်ထားတဲ့ model ကို သင်ပထမဆုံးအကြိမ် မြင်ဖူးတာဆိုရင်၊ ဒါနဲ့ပတ်သက်တဲ့ code သုံးကြောင်းကို စစ်ဆေးဖို့ ခဏရပ်ရအောင်-
accelerator.wait_for_everyone() unwrapped_model = accelerator.unwrap_model(model) unwrapped_model.save_pretrained(output_dir, save_function=accelerator.save)
ပထမဆုံးစာကြောင်းက ရှင်းပါတယ်။ ဒါက processes အားလုံးကို ဆက်မလုပ်ခင် ဒီအဆင့်မှာ ရှိနေဖို့ စောင့်ဆိုင်းခိုင်းတာပါ။ ဒါက save မလုပ်ခင် process တိုင်းမှာ model တူတူ ရှိနေဖို့ သေချာစေတာပါ။ ဒါဆိုရင် ကျွန်တော်တို့ သတ်မှတ်ခဲ့တဲ့ base model ဖြစ်တဲ့ unwrapped_model ကို ယူလိုက်ပါတယ်။ accelerator.prepare() method က distributed training မှာ အလုပ်လုပ်အောင် model ကို ပြောင်းလဲတာကြောင့်၊ ၎င်းမှာ save_pretrained() method ရှိတော့မှာ မဟုတ်ပါဘူး၊ accelerator.unwrap_model() method က အဲဒီအဆင့်ကို ပယ်ဖျက်လိုက်တာပါ။ နောက်ဆုံးအနေနဲ့၊ ကျွန်တော်တို့ save_pretrained() ကို ခေါ်ပေမယ့် torch.save() အစား accelerator.save() ကို အသုံးပြုဖို့ အဲဒီ method ကို ပြောပါတယ်။
ဒါပြီးသွားတာနဲ့၊ သင် Trainer နဲ့ train လုပ်ထားတဲ့ model နဲ့ အတော်လေးဆင်တူတဲ့ ရလဒ်တွေကို ထုတ်ပေးမယ့် model တစ်ခု ရရှိသင့်ပါတယ်။ ဒီ code ကို အသုံးပြုပြီး ကျွန်တော်တို့ train လုပ်ခဲ့တဲ့ model ကို huggingface-course/bert-finetuned-ner-accelerate မှာ စစ်ဆေးနိုင်ပါတယ်။ training loop မှာ ဘယ်လို tweak တွေကိုမဆို စမ်းသပ်ကြည့်ချင်တယ်ဆိုရင်၊ အပေါ်မှာ ပြသထားတဲ့ code ကို တိုက်ရိုက် ပြင်ဆင်ခြင်းဖြင့် အကောင်အထည်ဖော်နိုင်ပါတယ်!
Fine-tuned Model ကို အသုံးပြုခြင်း
ကျွန်တော်တို့ fine-tune လုပ်ခဲ့တဲ့ model ကို Model Hub ပေါ်မှာ inference widget နဲ့ ဘယ်လိုအသုံးပြုရမယ်ဆိုတာကို သင်ပြပြီးသားပါ။ ၎င်းကို pipeline ထဲမှာ locally အသုံးပြုဖို့အတွက်၊ သင့်လျော်တဲ့ model identifier ကို သတ်မှတ်ပေးရုံပါပဲ။
from transformers import pipeline
# ဒါကို သင်ရဲ့ကိုယ်ပိုင် checkpoint နဲ့ အစားထိုးပါ
model_checkpoint = "huggingface-course/bert-finetuned-ner"
token_classifier = pipeline(
"token-classification", model=model_checkpoint, aggregation_strategy="simple"
)
token_classifier("My name is Sylvain and I work at Hugging Face in Brooklyn.")[{'entity_group': 'PER', 'score': 0.9988506, 'word': 'Sylvain', 'start': 11, 'end': 18},
{'entity_group': 'ORG', 'score': 0.9647625, 'word': 'Hugging Face', 'start': 33, 'end': 45},
{'entity_group': 'LOC', 'score': 0.9986118, 'word': 'Brooklyn', 'start': 49, 'end': 57}]ကောင်းပါပြီ! ကျွန်တော်တို့ရဲ့ model က ဒီ pipeline အတွက် default model လိုပဲ ကောင်းကောင်း အလုပ်လုပ်နေပါတယ်။
ဝေါဟာရ ရှင်းလင်းချက် (Glossary)
- Token Classification: စာသား sequence တစ်ခုအတွင်းရှိ token တစ်ခုစီကို အမျိုးအစားခွဲခြားသတ်မှတ်ခြင်း လုပ်ငန်း (ဥပမာ- Named Entity Recognition)။
- Named Entity Recognition (NER): စာသားတစ်ခုထဲက entities တွေ (ဥပမာ- လူပုဂ္ဂိုလ်၊ နေရာဒေသ၊ အဖွဲ့အစည်း) ကို ရှာဖွေဖော်ထုတ်ခြင်း။
- Entity: စာသားထဲတွင် အရေးကြီးသော အရာဝတ္ထု သို့မဟုတ် သဘောတရား (ဥပမာ- လူအမည်၊ အဖွဲ့အစည်းအမည်)။
- Part-of-Speech Tagging (POS): စာကြောင်းတစ်ခုစီရှိ စကားလုံးတစ်လုံးစီကို သီးခြား part of speech တစ်ခု (ဥပမာ- noun, verb, adjective) နှင့် သက်ဆိုင်ကြောင်း မှတ်သားခြင်း။
- Chunking: တူညီသော entity ထဲတွင် ပါဝင်သော tokens များကို စုစည်းခြင်း။
B-(Beginning): Chunk သို့မဟုတ် entity တစ်ခု၏အစကို ဖော်ပြသော label။I-(Inside): Chunk သို့မဟုတ် entity တစ်ခု၏ အတွင်းပိုင်းကို ဖော်ပြသော label။O(Outside): Chunk သို့မဟုတ် entity တစ်ခုနှင့် မသက်ဆိုင်သော token ကို ဖော်ပြသော label။- Fine-tune: ကြိုတင်လေ့ကျင့်ထားပြီးသား (pre-trained) မော်ဒယ်တစ်ခုကို သီးခြားလုပ်ငန်းတစ်ခု (specific task) အတွက် အနည်းငယ်သော ဒေတာနဲ့ ထပ်မံလေ့ကျင့်ပေးခြင်းကို ဆိုလိုပါတယ်။
- BERT: Google မှ ဖန်တီးခဲ့သော Bidirectional Encoder Representations from Transformers (BERT) model။
- Predictions: Machine Learning မော်ဒယ်တစ်ခုက input data ကို အခြေခံပြီး ခန့်မှန်းထုတ်ပေးသော ရလဒ်များ။
- Model Hub (Hugging Face Hub): AI မော်ဒယ်တွေ၊ datasets တွေနဲ့ demo တွေကို အခြားသူတွေနဲ့ မျှဝေဖို့၊ ရှာဖွေဖို့နဲ့ ပြန်လည်အသုံးပြုဖို့အတွက် အွန်လိုင်း platform တစ်ခု ဖြစ်ပါတယ်။
GradioApp: Gradio library ကို အသုံးပြု၍ Machine Learning model များအတွက် web-based demo များကို လွယ်ကူလျင်မြန်စွာ ဖန်တီးရန် app။- Pre-tokenized Inputs: Tokenizer သို့ မပို့မီကတည်းက စကားလုံးများအဖြစ် ပိုင်းခြားထားပြီးဖြစ်သော စာသားများ။
Dataset(Hugging FaceDataset): Hugging Face Datasets library တွင် ဒေတာများကို ကိုယ်စားပြုသော class။- CoNLL-2003 Dataset: Named Entity Recognition (NER) အတွက် အသုံးများသော dataset တစ်ခုဖြစ်ပြီး Reuters သတင်းများ ပါဝင်သည်။
- News Stories (Reuters): Reuters သတင်းအေဂျင်စီမှ ထုတ်ဝေသော သတင်းများ။
load_dataset()Method: Hugging Face Datasets library မှ dataset များကို download လုပ်ပြီး cache လုပ်ရန် အသုံးပြုသော method။DatasetDictObject: Training set, validation set, နှင့် test set ကဲ့သို့သော dataset အများအပြားကို dictionary ပုံစံဖြင့် သိမ်းဆည်းထားသော object။trainSplit: Model ကို လေ့ကျင့်ရန်အတွက် အသုံးပြုသော dataset အပိုင်း။validationSplit: Training လုပ်နေစဉ် model ၏ စွမ်းဆောင်ရည်ကို အကဲဖြတ်ရန် အသုံးပြုသော dataset အပိုင်း။testSplit: Model ၏ နောက်ဆုံး စွမ်းဆောင်ရည်ကို တိုင်းတာရန် အသုံးပြုသော dataset အပိုင်း။chunk_tags: Chunking task အတွက် labels များ။id: Dataset ရှိ example တစ်ခုစီ၏ ID။ner_tags: Named Entity Recognition (NER) task အတွက် labels များ။pos_tags: Part-of-speech (POS) tagging task အတွက် labels များ။tokens: စာသားကို စကားလုံးများအဖြစ် ပိုင်းခြားထားသော list။- Subword Tokenization: စကားလုံးများကို သေးငယ်သော subword units (ဥပမာ- word pieces, byte-pair encodings) များအဖြစ် ပိုင်းခြားသော tokenization နည်းလမ်း။
- Integers (Labels): Labels များကို ဂဏန်းတန်ဖိုးများအဖြစ် ကိုယ်စားပြုခြင်း။
featuresAttribute: Dataset ၏ columns များ၏ အမျိုးအစားများနှင့် အချက်အလက်များကို ပြန်ပေးသော attribute။ClassLabel: Categorical labels များကို ကိုင်တွယ်ရန် 🤗 Datasets library မှ အသုံးပြုသော feature type။Sequence: 🤗 Datasets library တွင် sequences (list of values) များကို ကိုယ်စားပြုသော feature type။namesAttribute:ClassLabelသို့မဟုတ်Sequencefeature အတွင်းရှိ labels များ၏ နာမည်များကို ပြန်ပေးသော attribute။- Entity Spanning Two Words: စကားလုံးနှစ်လုံးဖြင့် ဖွဲ့စည်းထားသော entity (ဥပမာ- “New York”)။
AutoTokenizer: Hugging Face Transformers library မှာ ပါဝင်တဲ့ class တစ်ခုဖြစ်ပြီး မော်ဒယ်အမည်ကို အသုံးပြုပြီး သက်ဆိုင်ရာ tokenizer ကို အလိုအလျောက် load လုပ်ပေးသည်။model_checkpoint: pretrained model ၏ identifier (ဥပမာ-"bert-base-cased")။- 🤗 Tokenizers Library: Rust ဘာသာနဲ့ ရေးသားထားတဲ့ Hugging Face library တစ်ခုဖြစ်ပြီး မြန်ဆန်ထိရောက်တဲ့ tokenization ကို လုပ်ဆောင်ပေးသည်။
is_fastAttribute: tokenizer သည် fast (Rust-backed) version ဟုတ်မဟုတ် စစ်ဆေးသော attribute။is_split_into_words=True:tokenizer()function တွင် input text ကို စကားလုံးများအဖြစ် ပိုင်းခြားထားပြီးဖြစ်ကြောင်း ဖော်ပြသော argument။- Special Tokens: Model (ဥပမာ- BERT) မှ အဓိပ္ပာယ်ရှိသော သို့မဟုတ် ဖွဲ့စည်းတည်ဆောက်ပုံဆိုင်ရာ ရည်ရွယ်ချက်များအတွက် အသုံးပြုသော token များ (ဥပမာ-
[CLS],[SEP],[PAD])။ [CLS]Token: BERT model တွင် sequence ၏ အစကို ကိုယ်စားပြုသော special token။[SEP]Token: BERT model တွင် sentence တစ်ခု၏ အဆုံး သို့မဟုတ် sentence နှစ်ခုကြား ပိုင်းခြားရန် အသုံးပြုသော special token။##mb(Subword Token): BERT tokenizer မှ ထုတ်လုပ်သော subword token တစ်ခု။##က အရင် token ရဲ့ နောက်ဆက်တွဲဖြစ်ကြောင်း ဖော်ပြသည်။- Mismatch: အရာနှစ်ခုကြား မကိုက်ညီမှု သို့မဟုတ် ကွာခြားမှု။
word_ids()Method: fast tokenizer တွင် token တစ်ခုစီသည် မည်သည့်မူရင်း word နှင့် သက်ဆိုင်သည်ကို ပြန်ပေးသော method။-100(Label): Loss function တွင် လျစ်လျူရှုရန်အတွက် သတ်မှတ်ထားသော label index။- Loss Function (Cross Entropy): Model ၏ ခန့်မှန်းချက်များနှင့် အမှန်တကယ် labels များကြား ကွာခြားမှုကို တိုင်းတာသော function။
- Subtokens: စကားလုံးများကို ပိုင်းခြားထားသော အစိတ်အပိုင်းများ။
Dataset.map()Method: 🤗 Datasets library မှာ ပါဝင်တဲ့ method တစ်ခုဖြစ်ပြီး dataset ရဲ့ element တစ်ခုစီ ဒါမှမဟုတ် batch တစ်ခုစီပေါ်မှာ function တစ်ခုကို အသုံးပြုနိုင်စေသည်။batched=True:map()method မှာ အသုံးပြုသော argument တစ်ခုဖြစ်ပြီး function ကို dataset ရဲ့ element အများအပြားပေါ်မှာ တစ်ပြိုင်နက်တည်း အသုံးပြုစေသည်။truncation=True: tokenizer တွင် input sequence ကို model ၏ အများဆုံး input length အထိ ဖြတ်တောက်ရန် သတ်မှတ်ခြင်း။remove_columnsArgument:Dataset.map()method တွင် ပြုပြင်ပြီးနောက် မလိုအပ်သော columns များကို dataset မှ ဖယ်ရှားရန် အသုံးပြုသော argument။- Padding: sequence အရှည်များ ကွဲပြားသော inputs များကို တူညီသော အရှည်ဖြစ်စေရန် dummy values (ဥပမာ- 0 သို့မဟုတ် tokenizer ၏ pad token ID) များဖြင့် ဖြည့်ဆည်းခြင်း။
- Data Collator:
DataLoaderတစ်ခုမှာ အသုံးပြုတဲ့ function တစ်ခုဖြစ်ပြီး batch တစ်ခုအတွင်း samples တွေကို စုစည်းပေးသည်။ TrainerAPI: Hugging Face Transformers library မှ model များကို ထိရောက်စွာ လေ့ကျင့်ရန်အတွက် ဒီဇိုင်းထုတ်ထားသော မြင့်မားသောအဆင့် API။- Keras: TensorFlow library တွင် ပါဝင်သော မြင့်မားသောအဆင့် (high-level) API တစ်ခုဖြစ်ပြီး deep learning models များကို လွယ်ကူလျင်မြန်စွာ တည်ဆောက်ရန် အသုံးပြုသည်။
- Data Collation: Training အတွက် data samples များကို batch တစ်ခုအဖြစ် စုစည်းခြင်းလုပ်ငန်းစဉ်။
DataCollatorWithPadding: Hugging Face Transformers library မှ ပံ့ပိုးပေးသော class တစ်ခုဖြစ်ပြီး dynamic padding ကို အသုံးပြု၍ batch တစ်ခုအတွင်း samples များကို စုစည်းပေးသည်။DataCollatorForTokenClassification: Token classification task အတွက် အထူးဒီဇိုင်းထုတ်ထားသော data collator တစ်ခုဖြစ်ပြီး inputs များနှင့် labels နှစ်ခုလုံးကို သင့်လျော်စွာ padding လုပ်ပေးသည်။return_tensors="tf": TensorFlow tensors များကို ပြန်ပေးရန် သတ်မှတ်ခြင်း (TensorFlow framework အတွက်)။- Batch (Data Batch): Training သို့မဟုတ် evaluation အတွက် တစ်ပြိုင်နက်တည်း လုပ်ဆောင်သော data samples အုပ်စု။
- PyTorch
tensor: PyTorch framework မှာ data များကို သိမ်းဆည်းရန် အသုံးပြုတဲ့ multi-dimensional array (tensor) တစ်ခု။ tf.data.Dataset: TensorFlow တွင် data pipelines များကို တည်ဆောက်ရန် အသုံးပြုသော object။to_tf_dataset()Method: Hugging Face Dataset object ကိုtf.data.Datasetobject အဖြစ် ပြောင်းလဲပေးသော method (TensorFlow framework အတွက်)။model.prepare_tf_dataset()Method: TensorFlow တွင်tf.data.Datasetကို ဖန်တီးရန်အတွက် ပိုမိုရိုးရှင်းသော method။shuffle=True/False: dataset ကို shuffle လုပ်ခြင်းရှိမရှိ သတ်မှတ်ခြင်း။batch_size: training လုပ်ငန်းစဉ်တစ်ခုစီတွင် model သို့ ပေးပို့သော input samples အရေအတွက်။TFAutoModelForTokenClassification: Hugging Face Transformers library မှ token classification အတွက် TensorFlow model ကို အလိုအလျောက် load လုပ်ပေးသော class။num_labelsArgument: model configuration တွင် labels အရေအတွက်ကို သတ်မှတ်ရန် အသုံးပြုသော argument။id2labelDictionary: ID မှ label string သို့ mapping လုပ်သော dictionary။label2idDictionary: Label string မှ ID သို့ mapping လုပ်သော dictionary။model.config: model ၏ configuration အချက်အလက်များကို သိမ်းဆည်းထားသော object။model.fit()Method: Keras model တွင် training လုပ်ငန်းစဉ်ကို စတင်ရန် အသုံးပြုသော method။TFAutoModelForSequenceClassification: Hugging Face Transformers library မှ sequence classification အတွက် TensorFlow model ကို အလိုအလျောက် load လုပ်ပေးသော class။- Pretraining Head: pretrained model ၏ မူရင်း task (ဥပမာ- Masked Language Modeling) အတွက် output layer။
- Token Classification Head: token classification task အတွက် model တွင် ထပ်ထည့်ထားသော output layer။
- Randomly Initialized: weights များကို ကျပန်းတန်ဖိုးများဖြင့် စတင်သတ်မှတ်ခြင်း။
huggingface_hub.notebook_login(): Jupyter/Colab Notebooks များတွင် Hugging Face Hub သို့ login ဝင်ရန် အသုံးပြုသော function။- Login Credentials: အသုံးပြုသူအမည်နှင့် စကားဝှက်ကဲ့သို့သော authentication အချက်အလက်များ။
- Widget: Graphical User Interface (GUI) တွင် အသုံးပြုသူနှင့် အပြန်အလှန်တုံ့ပြန်နိုင်သော အစိတ်အပိုင်းများ။
huggingface-cli login: Hugging Face CLI (Command Line Interface) မှ Hugging Face Hub သို့ login ဝင်ရန် အသုံးပြုသော command။create_optimizer()Function: Hugging Face Transformers မှ TensorFlow models များအတွက်AdamWoptimizer ကို ဖန်တီးပေးသော utility function။AdamWOptimizer: Adam optimizer ၏ ပြုပြင်ထားသော ဗားရှင်းဖြစ်ပြီး weight decay ကို ပိုမိုထိရောက်စွာ ကိုင်တွယ်သည်။AdamOptimizer: Adaptive Moment Estimation (Adam) optimizer။- Weight Decay: Model ၏ weights များကို သေးငယ်စေရန် training လုပ်နေစဉ်အတွင်း အသုံးပြုသော regularization နည်းလမ်း။
- Learning Rate Decay: Training လုပ်နေစဉ်အတွင်း learning rate ကို တဖြည်းဖြည်း လျှော့ချသည့် နည်းလမ်း။
- Mixed-precision float16: Model training တွင် float16 (half-precision) နှင့် float32 (full-precision) data types များကို ရောနှောအသုံးပြုခြင်းဖြင့် training မြန်နှုန်းကို တိုးမြှင့်ပြီး memory အသုံးပြုမှုကို လျှော့ချသည်။
tf.keras.mixed_precision.set_global_policy("mixed_float16"): TensorFlow တွင် mixed-precision training ကို ဖွင့်ရန်။num_train_steps: training လုပ်ငန်းစဉ်တစ်ခုလုံး၏ စုစုပေါင်း training steps အရေအတွက်။init_lr: စတင် learning rate။num_warmup_steps: learning rate ကို တဖြည်းဖြည်း တိုးမြှင့်ပေးသည့် warmup steps အရေအတွက်။model.compile()Method: Keras model တွင် training လုပ်ရန်အတွက် optimizer, loss function နှင့် metrics များကို သတ်မှတ်ခြင်း။lossArgument (incompile()):compile()method တွင် loss function ကို သတ်မှတ်ရန် အသုံးပြုသော argument။PushToHubCallback: Keras Trainer တွင် အသုံးပြုသော callback တစ်ခုဖြစ်ပြီး training လုပ်နေစဉ်အတွင်း models, tokenizers, configuration များနှင့် model card draft များကို Hub သို့ ပုံမှန် update လုပ်ရန်။output_dir: model files များကို သိမ်းဆည်းမည့် directory။validation_data: training လုပ်နေစဉ် model ကို အကဲဖြတ်ရန် အသုံးပြုမည့် validation dataset။callbacks: training လုပ်နေစဉ်အတွင်း သတ်မှတ်ထားသော အချိန်များတွင် လုပ်ဆောင်မည့် functions များ။epochs: model ကို training dataset တစ်ခုလုံးဖြင့် လေ့ကျင့်သည့် အကြိမ်အရေအတွက်။hub_model_idArgument: Hugging Face Hub တွင် repository ID ကို သတ်မှတ်ရန်။- Organization: Hugging Face Hub ပေါ်ရှိ အဖွဲ့အစည်းအကောင့်။
- Namespace: Hugging Face Hub တွင် အသုံးပြုသူအမည် သို့မဟုတ် organization အမည်။
- Local Clone: Git repository ၏ ဒေသတွင်း ကွန်ပျူတာပေါ်ရှိ မိတ္တူ။
model.fit(): Keras model တွင် training လုပ်ငန်းစဉ်ကို စတင်ရန် အသုံးပြုသော method။- Resume Training: Training ကို ရပ်နားခဲ့သော နေရာမှ ပြန်လည်စတင်ခြင်း။
- Inference Widget: Model Hub ပေါ်တွင် model တစ်ခုကို interactive စမ်းသပ်နိုင်သည့် web UI အစိတ်အပိုင်း။
- Metrics: Model ၏ စွမ်းဆောင်ရည်ကို တိုင်းတာရန် အသုံးပြုသော တန်ဖိုးများ (ဥပမာ- accuracy, F1 score)။
compute_metrics()Function:Trainerကို အသုံးပြု၍ training လုပ်နေစဉ်အတွင်း metrics များကို တွက်ချက်ရန်အတွက် function။eval_preds:compute_metrics()function သို့ ပေးပို့သော predictions နှင့် labels။seqeval: token classification models များကို အကဲဖြတ်ရန်အတွက် အသုံးပြုသော Python library။evaluate.load()Function: Hugging Face Evaluate library မှ metric ကို load လုပ်ရန် အသုံးပြုသော function။- Precision: True positives အရေအတွက်ကို True positives နှင့် False positives ပေါင်းလဒ်ဖြင့် စားခြင်း။ Model ၏ မှန်ကန်စွာ ခန့်မှန်းနိုင်မှု။
- Recall: True positives အရေအတွက်ကို True positives နှင့် False negatives ပေါင်းလဒ်ဖြင့် စားခြင်း။ Model က လိုအပ်သော အရာအားလုံးကို ဘယ်လောက်ဖော်ထုတ်နိုင်လဲ။
- F1 Score: Precision နှင့် Recall တို့၏ harmonic mean ကို တွက်ချက်သော metric။
overall_precision: Overall precision score။overall_recall: Overall recall score။overall_f1: Overall F1 score။overall_accuracy: Overall accuracy score။np.argmax(logits, axis=-1): Logits များမှ အများဆုံးတန်ဖိုးရှိသော index ကို ရယူခြင်းဖြင့် prediction ကို တွက်ချက်ခြင်း။logits: Model ၏ output layer မှ ထွက်ပေါ်လာသော raw, unnormalized scores များ။labels: အမှန်တကယ် label များ။true_labels:-100labels များကို ဖယ်ရှားပြီး label strings အဖြစ် ပြောင်းလဲထားသော အမှန်တကယ် labels များ။true_predictions:-100labels များကို ဖယ်ရှားပြီး label strings အဖြစ် ပြောင်းလဲထားသော predictions များ။all_metrics:metric.compute()မှ ပြန်ပေးသော metrics အားလုံးပါဝင်သည့် dictionary။model.predict_on_batch(batch): TensorFlow model တွင် batch တစ်ခုပေါ်တွင် prediction များကို တွက်ချက်ရန်။tf_eval_dataset: TensorFlow evaluation dataset။AutoModelForTokenClassification: Hugging Face Transformers library မှ token classification အတွက် PyTorch model ကို အလိုအလျောက် load လုပ်ပေးသော class။TrainingArguments:Trainerကို အသုံးပြု၍ training လုပ်ရန်အတွက် hyperparameters များနှင့် အခြား settings များကို သတ်မှတ်သော class။evaluation_strategy="epoch": epoch တိုင်းပြီးဆုံးတိုင်း evaluation လုပ်ရန်။save_strategy="epoch": epoch တိုင်းပြီးဆုံးတိုင်း model ကို save လုပ်ရန်။learning_rate: training လုပ်နေစဉ်အတွင်း model ၏ weights များကို မည်မျှပြောင်းလဲရမည်ကို ထိန်းချုပ်သော parameter။num_train_epochs: model ကို training dataset တစ်ခုလုံးဖြင့် လေ့ကျင့်သည့် အကြိမ်အရေအတွက်။weight_decay: Model ၏ weights များကို သေးငယ်စေရန် training လုပ်နေစဉ်အတွင်း အသုံးပြုသော regularization နည်းလမ်း။push_to_hub=True: training ပြီးဆုံးပြီးနောက် model ကို Hugging Face Hub သို့ upload လုပ်ရန်။trainer.train():TrainerAPI ကို အသုံးပြု၍ training လုပ်ငန်းစဉ်ကို စတင်ရန်။trainer.push_to_hub()Method:Trainerမှ model ကို Hugging Face Hub သို့ commit message နှင့်အတူ upload လုပ်ရန်။- Commit Message: Git commit တစ်ခုတွင် ပြောင်းလဲမှုများကို ဖော်ပြသော မက်ဆေ့ချ်။
DataLoader: Dataset ကနေ data တွေကို batch အလိုက် load လုပ်ပေးတဲ့ PyTorch utility class။collate_fn:DataLoaderတွင် batch တစ်ခုအတွင်း samples များကို စုစည်းပေးသော function။torch.optim.AdamW: PyTorch မှာ အသုံးပြုတဲ့ AdamW optimizer။model.parameters(): model ၏ လေ့ကျင့်နိုင်သော parameters (weights နှင့် biases) များကို ပြန်ပေးသော method။accelerator(Hugging Face Accelerate): Distributed training နှင့် mixed-precision training ကို လွယ်ကူချောမွေ့စေသော object။accelerator.prepare()Method: models, optimizers, dataloaders များကို distributed training အတွက် ပြင်ဆင်ပေးသော method။- TPU (Tensor Processing Unit): Google မှ AI/ML workloads များအတွက် အထူးဒီဇိုင်းထုတ်ထားသော processor တစ်မျိုး။
- Dedicated Training Function: TPU training အတွက် လိုအပ်သော သီးခြား function။
- Linear Schedule: Learning rate ကို အစပိုင်းတွင် မြင့်မားစွာထားပြီး training လုပ်ငန်းစဉ်တစ်လျှောက် တဖြည်းဖြည်း လျှော့ချသည့် schedule။
get_scheduler()Function: Hugging Face Transformers မှ learning rate schedulers များကို ဖန်တီးပေးသော function။num_update_steps_per_epoch: epoch တစ်ခုစီရှိ update steps အရေအတွက်။num_training_steps: training လုပ်ငန်းစဉ်တစ်ခုလုံး၏ စုစုပေါင်း training steps အရေအတွက်။lr_scheduler: learning rate ကို ထိန်းချုပ်ရန် အသုံးပြုသော object။RepositoryObject:huggingface_hublibrary မှ Git repository များကို ကိုင်တွယ်ရန်အတွက် object။- Working Folder: project files များကို သိမ်းဆည်းထားသော folder။
get_full_repo_name()Function: Hugging Face Hub တွင် repository အပြည့်အစုံနာမည်ကို ရယူရန် utility function။repo_name: repository ၏ အမည် (ဥပမာ-"sgugger/my-awesome-model")။output_dir: model files များကို သိမ်းဆည်းမည့် directory။repo.push_to_hub()Method:Repositoryobject မှ အပြောင်းအလဲများကို Hugging Face Hub သို့ push လုပ်ရန်။- Intermediate Models: training လုပ်နေစဉ်အတွင်း သတ်မှတ်ထားသော အချိန်များတွင် သိမ်းဆည်းထားသော models များ။
postprocess()Function: Predictions နှင့် labels များကို metric calculation အတွက် သင့်လျော်သော ပုံစံသို့ ပြောင်းလဲပေးသော function။predictions.detach().cpu().clone().numpy(): PyTorch tensor မှ gradient tracking ကို ဖယ်ရှားပြီး CPU သို့ ရွှေ့ကာ clone လုပ်၍ NumPy array အဖြစ် ပြောင်းလဲခြင်း။tqdm.auto.tqdm: Python တွင် loops များအတွက် progress bar ကို ပြသရန် utility။torch: PyTorch library။model.train(): PyTorch model ကို training mode သို့ ပြောင်းလဲခြင်း။model.eval(): PyTorch model ကို evaluation mode သို့ ပြောင်းလဲခြင်း။- `outputs = model(batch)`**: model ၏ forward pass ကို batch data နှင့် လုပ်ဆောင်ခြင်း။
loss = outputs.loss: model မှ တွက်ချက်ထားသော loss ကို ရယူခြင်း။accelerator.backward(loss): Distributed training တွင် backpropagation ကို လုပ်ဆောင်ခြင်း။optimizer.step(): တွက်ချက်ထားသော gradients များကို အသုံးပြုပြီး model ၏ parameters များကို update လုပ်သော optimizer method။optimizer.zero_grad(): gradients များကို သုညသို့ ပြန်လည်သတ်မှတ်ခြင်း။torch.no_grad(): gradient တွက်ချက်မှုကို ပိတ်ထားရန် (evaluation mode တွင်)။outputs.logits.argmax(dim=-1): model ၏ output logits များမှ အများဆုံးတန်ဖိုးရှိသော index (prediction) ကို ရယူခြင်း။accelerator.pad_across_processes(): Distributed training တွင် မတူညီသော processes များမှ tensors များကို တူညီသော shape အဖြစ် padding လုပ်ခြင်း။accelerator.gather(): Distributed training တွင် မတူညီသော processes များမှ tensors များကို စုစည်းခြင်း။metric.add_batch():evaluatelibrary ၏ metric object တွင် batch အလိုက် predictions နှင့် references များကို ထည့်သွင်းခြင်း။metric.compute():evaluatelibrary ၏ metric object တွင် metrics များကို တွက်ချက်ခြင်း။accelerator.wait_for_everyone(): Distributed training တွင် processes အားလုံး အဆင့်တစ်ခုတည်းတွင် ရှိနေစေရန် စောင့်ဆိုင်းခြင်း။accelerator.unwrap_model(model): distributed training အတွက်acceleratorမှ wrap လုပ်ထားသော model ကို မူရင်း model အဖြစ် ပြန်လည်ရယူခြင်း။unwrapped_model.save_pretrained(output_dir, save_function=accelerator.save): model ကိုoutput_dirသို့ သိမ်းဆည်းပြီးaccelerator.save()ကို saving function အဖြစ် အသုံးပြုခြင်း။accelerator.is_main_process: လက်ရှိ process သည် main process ဟုတ်မဟုတ် စစ်ဆေးခြင်း။tokenizer.save_pretrained(output_dir): tokenizer ကိုoutput_dirသို့ သိမ်းဆည်းခြင်း။blocking=False:push_to_hub()method တွင် asynchronous (background) push လုပ်ငန်းစဉ်ကို ဖွင့်ရန်။torch.save(): PyTorch object များကို disk သို့ သိမ်းဆည်းရန် function။pipeline()(Hugging Face Pipeline):pipeline()function ကို အသုံးပြုပြီး model တစ်ခုကို အလွယ်တကူ အသုံးပြုနိုင်သော abstraction။aggregation_strategy="simple": token classification pipeline တွင် subword predictions များကို ပေါင်းစပ်ပုံ နည်းလမ်း။- Default Model: pipeline အတွက် ကြိုတင်သတ်မှတ်ထားသော model။