course documentation
Error တစ်ခုရတဲ့အခါ ဘာလုပ်ရမလဲ။
Error တစ်ခုရတဲ့အခါ ဘာလုပ်ရမလဲ။

ဒီအပိုင်းမှာ သင် အသစ် tune လုပ်ထားတဲ့ Transformer model ကနေ predictions တွေ ထုတ်လုပ်ဖို့ ကြိုးစားတဲ့အခါ ဖြစ်ပေါ်နိုင်တဲ့ အဖြစ်များတဲ့ errors အချို့ကို ကြည့်ရပါမယ်။ ဒါက အပိုင်း ၄ အတွက် သင့်ကို ပြင်ဆင်ပေးပါလိမ့်မယ်။ အဲဒီမှာ ကျွန်တော်တို့ training phase ကို ဘယ်လို debug လုပ်ရမလဲဆိုတာ လေ့လာသွားမှာပါ။
ဒီအပိုင်းအတွက် template model repository တစ်ခုကို ကျွန်တော်တို့ ပြင်ဆင်ထားပါတယ်။ ဒီအခန်းမှာ code ကို run ချင်တယ်ဆိုရင် ပထမဆုံး model ကို သင်ရဲ့ account ပေါ်က Hugging Face Hub သို့ copy လုပ်ဖို့ လိုအပ်ပါလိမ့်မယ်။ ဒါကိုလုပ်ဖို့၊ Jupyter notebook မှာ အောက်ပါတို့ကို run ခြင်းဖြင့် အရင်ဆုံး log in ဝင်ပါ။
from huggingface_hub import notebook_login
notebook_login()သို့မဟုတ် သင်အကြိုက်ဆုံး terminal မှာ အောက်ပါတို့ကို run ပါ။
huggingface-cli login
ဒါက သင့် username နဲ့ password ကို ထည့်သွင်းဖို့ တောင်းဆိုပါလိမ့်မယ်၊ ပြီးတော့ token တစ်ခုကို ~/.cache/huggingface/ အောက်မှာ သိမ်းဆည်းပါလိမ့်မယ်။ log in ဝင်ပြီးတာနဲ့၊ အောက်ပါ function နဲ့ template repository ကို copy လုပ်နိုင်ပါတယ်။
from distutils.dir_util import copy_tree
from huggingface_hub import Repository, snapshot_download, create_repo, get_full_repo_name
def copy_repository_template():
# repo ကို clone လုပ်ပြီး local path ကို ထုတ်ယူပါ
template_repo_id = "lewtun/distilbert-base-uncased-finetuned-squad-d5716d28"
commit_hash = "be3eaffc28669d7932492681cd5f3e8905e358b4"
template_repo_dir = snapshot_download(template_repo_id, revision=commit_hash)
# Hub ပေါ်မှာ empty repo တစ်ခု ဖန်တီးပါ
model_name = template_repo_id.split("/")[1]
create_repo(model_name, exist_ok=True)
# empty repo ကို clone လုပ်ပါ
new_repo_id = get_full_repo_name(model_name)
new_repo_dir = model_name
repo = Repository(local_dir=new_repo_dir, clone_from=new_repo_id)
# ဖိုင်တွေကို copy လုပ်ပါ
copy_tree(template_repo_dir, new_repo_dir)
# Hub သို့ push လုပ်ပါ
repo.push_to_hub()အခု copy_repository_template() ကို ခေါ်လိုက်တဲ့အခါ၊ ဒါက template repository ရဲ့ copy တစ်ခုကို သင့် account အောက်မှာ ဖန်တီးပါလိမ့်မယ်။
🤗 Transformers ရဲ့ pipeline ကို Debug လုပ်ခြင်း
Transformer models တွေကို debug လုပ်တဲ့ အံ့ဖွယ်ကောင်းတဲ့ ကမ္ဘာဆီ ကျွန်တော်တို့ရဲ့ ခရီးကို စတင်ဖို့အတွက်၊ အောက်ပါအခြေအနေကို စဉ်းစားကြည့်ပါ- သင်ဟာ e-commerce website တစ်ခုက customers တွေကို consumer products တွေအကြောင်း အဖြေရှာဖို့ ကူညီဖို့အတွက် question answering project တစ်ခုမှာ လုပ်ဖော်ကိုင်ဖက်တစ်ဦးနဲ့ အလုပ်လုပ်နေပါတယ်။ သင့်လုပ်ဖော်ကိုင်ဖက်က သင့်ဆီကို အောက်ပါစာတစ်စောင် ပို့လိုက်ပါတယ်။
G’day! ကျွန်တော် Hugging Face course ရဲ့ Chapter 7 မှာပါတဲ့ နည်းလမ်းတွေကို အသုံးပြုပြီး experiment တစ်ခု run ခဲ့တာ SQuAD ပေါ်မှာ ရလဒ်ကောင်းတွေ ရခဲ့တယ်။ ကျွန်တော်တို့ ဒီ model ကို ကျွန်တော်တို့ project အတွက် starting point အဖြစ် အသုံးပြုနိုင်မယ်လို့ ထင်တယ်။ Hub ပေါ်က model ID က “lewtun/distillbert-base-uncased-finetuned-squad-d5716d28” ပါ။ စိတ်ကြိုက် စမ်းသပ်ကြည့်ပါ။ :)
ပြီးတော့ သင်ပထမဆုံး တွေးမိတာက 🤗 Transformers က pipeline ကို အသုံးပြုပြီး model ကို load လုပ်ဖို့ပါပဲ။
from transformers import pipeline
model_checkpoint = get_full_repo_name("distillbert-base-uncased-finetuned-squad-d5716d28")
reader = pipeline("question-answering", model=model_checkpoint)"""
OSError: Can't load config for 'lewtun/distillbert-base-uncased-finetuned-squad-d5716d28'. Make sure that:
- 'lewtun/distillbert-base-uncased-finetuned-squad-d5716d28' is a correct model identifier listed on 'https://huggingface.co/models'
- or 'lewtun/distillbert-base-uncased-finetuned-squad-d5716d28' is the correct path to a directory containing a config.json file
"""ဟာ မဟုတ်သေးဘူး၊ တစ်ခုခု မှားနေပုံရတယ်။ သင် programming နဲ့ အခုမှ စတင်သူဆိုရင် ဒီလို errors တွေက ပထမတော့ နားမလည်နိုင်ပုံရနိုင်ပါတယ် (OSError ဆိုတာ ဘာလဲ?! )။ ဒီမှာ ပြသထားတဲ့ error က Python traceback (aka stack trace) လို့ခေါ်တဲ့ အများကြီး ပိုကြီးတဲ့ error report ရဲ့ နောက်ဆုံးအပိုင်းပဲ ရှိပါသေးတယ်။ ဥပမာ၊ ဒီ code ကို Google Colab မှာ run နေတယ်ဆိုရင်၊ အောက်ပါ screenshot လိုမျိုး တစ်ခုခုကို သင်တွေ့ရပါလိမ့်မယ်။
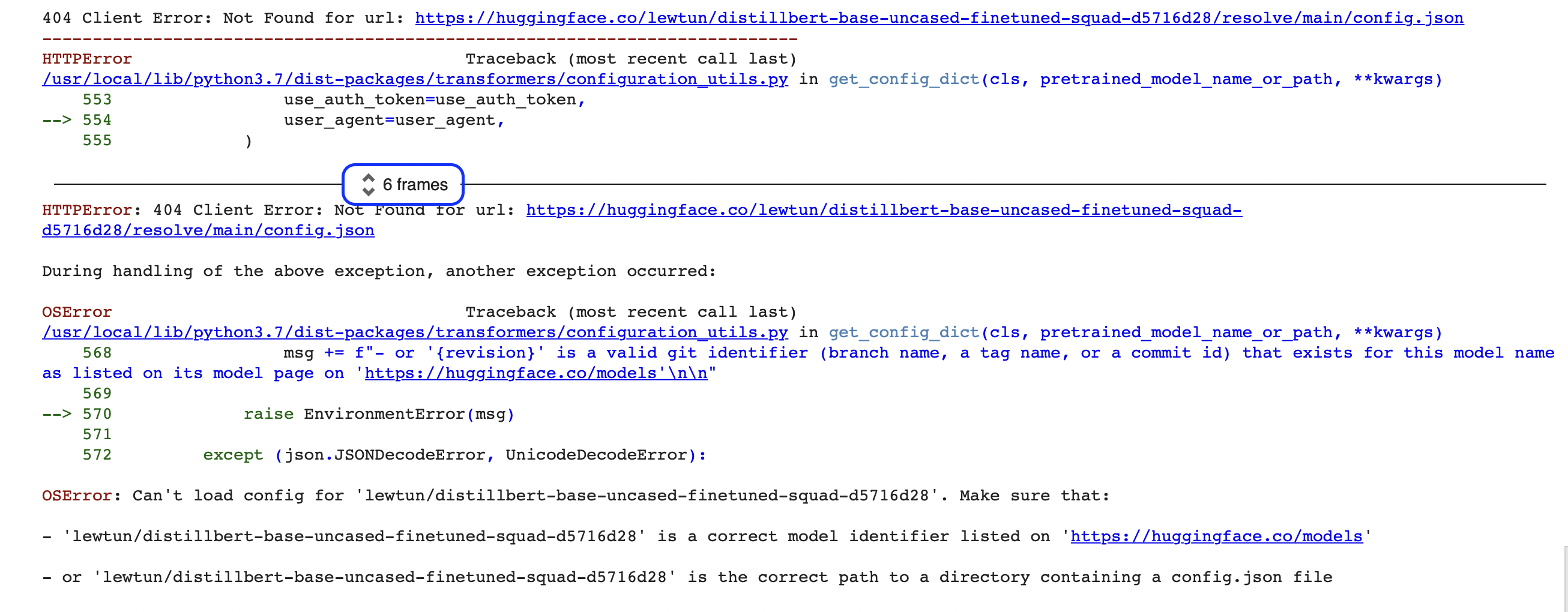
ဒီ reports တွေထဲမှာ အချက်အလက်များစွာ ပါဝင်တာကြောင့်၊ အဓိက အစိတ်အပိုင်းတွေကို အတူတူ လေ့လာကြည့်ရအောင်။ ပထမဆုံး သတိပြုရမယ့်အချက်က tracebacks တွေကို အောက်ကနေ အပေါ်သို့ ဖတ်ရတာပါပဲ။ English စာသားကို အပေါ်ကနေ အောက်ကို ဖတ်လေ့ရှိတဲ့ သင်အတွက် ဒါက ထူးဆန်းနိုင်ပါတယ်၊ ဒါပေမယ့် ဒါက model နဲ့ tokenizer ကို download လုပ်တဲ့အခါ pipeline က လုပ်ဆောင်တဲ့ function calls တွေရဲ့ sequence ကို traceback က ပြသနေတာကို ထင်ဟပ်ပါတယ်။ (pipeline က ဘယ်လိုအလုပ်လုပ်တယ်ဆိုတာ အသေးစိတ်သိရှိဖို့ Chapter 2 ကို ကြည့်ပါ)။
🚨 Google Colab က traceback မှာ “6 frames” ကို ဝန်းရံထားတဲ့ အပြာရောင် box ကို တွေ့လား? ဒါက Colab ရဲ့ special feature တစ်ခုဖြစ်ပြီး traceback ကို “frames” တွေအဖြစ် ဖိသိပ်ထားပါတယ်။ error ရဲ့ source ကို မရှာတွေ့ဘူးဆိုရင်၊ အဲဒီ မြှားနှစ်စင်းကို နှိပ်ပြီး traceback အပြည့်အစုံကို ချဲ့ကြည့်ဖို့ သေချာပါစေ။
ဒါက traceback ရဲ့ နောက်ဆုံးလိုင်းက နောက်ဆုံး error message ကို ဖော်ပြပြီး raise လုပ်ခဲ့တဲ့ exception ရဲ့ နာမည်ကို ပေးတယ်လို့ ဆိုလိုပါတယ်။ ဒီကိစ္စမှာ exception အမျိုးအစားက OSError ဖြစ်ပြီး၊ ဒါက system နဲ့ ဆက်စပ်တဲ့ error တစ်ခုကို ဖော်ပြပါတယ်။ အတူပါလာတဲ့ error message ကို ဖတ်ကြည့်မယ်ဆိုရင်၊ model ရဲ့ config.json file မှာ ပြဿနာတစ်ခုခု ရှိပုံရတယ်ဆိုတာ မြင်ရပြီး၊ ဒါကို ဖြေရှင်းဖို့ အကြံပြုချက်နှစ်ခု ပေးထားပါတယ်။
"""
Make sure that:
- 'lewtun/distillbert-base-uncased-finetuned-squad-d5716d28' is a correct model identifier listed on 'https://huggingface.co/models'
- or 'lewtun/distillbert-base-uncased-finetuned-squad-d5716d28' is the correct path to a directory containing a config.json file
"""💡 နားလည်ရခက်တဲ့ error message တစ်ခု ကြုံတွေ့ရရင်၊ message ကို Google ဒါမှမဟုတ် Stack Overflow ရဲ့ search bar ထဲကို copy လုပ်ပြီး paste လုပ်လိုက်ပါ (တကယ်ပါပဲ!)။ သင်ဟာ error ကို ပထမဆုံး ကြုံတွေ့ရသူ မဟုတ်နိုင်တာကြောင့်၊ community ထဲက တခြားသူတွေ တင်ထားတဲ့ ဖြေရှင်းနည်းတွေကို ရှာဖွေဖို့ ဒါက ကောင်းမွန်တဲ့ နည်းလမ်းတစ်ခုပါပဲ။ ဥပမာ၊ Stack Overflow ပေါ်မှာ
OSError: Can't load config forကို ရှာဖွေကြည့်မယ်ဆိုရင် ပြဿနာကို ဖြေရှင်းဖို့ starting point အဖြစ် အသုံးပြုနိုင်တဲ့ hits အချို့ကို ပေးပါလိမ့်မယ်။
ပထမဆုံး အကြံပြုချက်က model ID မှန်ကန်ခြင်းရှိမရှိ စစ်ဆေးခိုင်းတာကြောင့်၊ ပထမဆုံး လုပ်ရမယ့်အလုပ်က identifier ကို copy လုပ်ပြီး Hub ရဲ့ search bar ထဲကို paste လုပ်ဖို့ပါပဲ။

အင်း၊ ကျွန်တော်တို့ လုပ်ဖော်ကိုင်ဖက်ရဲ့ model က Hub မှာ မရှိပုံရတယ်… ဟာ၊ ဒါပေမယ့် model ရဲ့ နာမည်မှာ typo တစ်ခုရှိနေတယ်။ DistilBERT မှာ “l” တစ်လုံးပဲ ပါတာကြောင့်၊ ဒါကို ပြင်ပြီး “lewtun/distilbert-base-uncased-finetuned-squad-d5716d28” ကို အစားရှာကြည့်ရအောင်။

ကောင်းပြီ၊ ဒါက hit တစ်ခုရခဲ့တယ်။ အခုမှန်ကန်တဲ့ model ID နဲ့ model ကို ထပ်မံ download လုပ်ကြည့်ရအောင်…
model_checkpoint = get_full_repo_name("distilbert-base-uncased-finetuned-squad-d5716d28")
reader = pipeline("question-answering", model=model_checkpoint)"""
OSError: Can't load config for 'lewtun/distilbert-base-uncased-finetuned-squad-d5716d28'. Make sure that:
- 'lewtun/distilbert-base-uncased-finetuned-squad-d5716d28' is a correct model identifier listed on 'https://huggingface.co/models'
- or 'lewtun/distilbert-base-uncased-finetuned-squad-d5716d28' is the correct path to a directory containing a config.json file
"""ဟာ၊ ထပ်ပြီး ဖျက်ဆီးခံရပြန်ပြီ — machine learning engineer တစ်ယောက်ရဲ့ နေ့စဉ်ဘဝကို ကြိုဆိုပါတယ်။ model ID ကို ကျွန်တော်တို့ ပြင်ဆင်ပြီးသွားပြီဖြစ်တဲ့အတွက်၊ ပြဿနာက repository ထဲမှာ ရှိနေရပါမယ်။ 🤗 Hub ပေါ်က repository တစ်ခုရဲ့ အကြောင်းအရာတွေကို မြန်မြန်ဆန်ဆန် ဝင်ရောက်ကြည့်ရှုဖို့ နည်းလမ်းတစ်ခုက huggingface_hub library ရဲ့ list_repo_files() function ကို အသုံးပြုခြင်းပါပဲ။
from huggingface_hub import list_repo_files
list_repo_files(repo_id=model_checkpoint)['.gitattributes', 'README.md', 'pytorch_model.bin', 'special_tokens_map.json', 'tokenizer_config.json', 'training_args.bin', 'vocab.txt']စိတ်ဝင်စားစရာကောင်းတယ် — repository ထဲမှာ config.json file မရှိပုံရဘူး။ ကျွန်တော်တို့ရဲ့ pipeline က model ကို load မလုပ်နိုင်တာ အံ့သြစရာမရှိပါဘူး၊ ကျွန်တော်တို့ လုပ်ဖော်ကိုင်ဖက်က fine-tune လုပ်ပြီးနောက် ဒီ file ကို Hub သို့ push လုပ်ဖို့ မေ့သွားတာ ဖြစ်ရပါမယ်။ ဒီကိစ္စမှာ၊ ပြဿနာက ဖြေရှင်းရတာ ရိုးရှင်းပုံရပါတယ်- သူတို့ကို file ထည့်ဖို့ တောင်းဆိုနိုင်ပါတယ်၊ ဒါမှမဟုတ် model ID ကနေ pretrained model က distilbert-base-uncased ဖြစ်တယ်ဆိုတာ မြင်ရတာကြောင့်၊ ဒီ model အတွက် config ကို download လုပ်ပြီး ကျွန်တော်တို့ repo ကို push လုပ်ခြင်းဖြင့် ပြဿနာဖြေရှင်းနိုင်မလားဆိုတာ ကြည့်နိုင်ပါတယ်။ အဲဒါကို စမ်းကြည့်ရအောင်။ Chapter 2 မှာ ကျွန်တော်တို့ သင်ယူခဲ့တဲ့ နည်းလမ်းတွေကို အသုံးပြုပြီး၊ model ရဲ့ configuration ကို AutoConfig class နဲ့ download လုပ်နိုင်ပါတယ်။
from transformers import AutoConfig
pretrained_checkpoint = "distilbert-base-uncased"
config = AutoConfig.from_pretrained(pretrained_checkpoint)🚨 ကျွန်တော်တို့ ဒီနေရာမှာ အသုံးပြုနေတဲ့ နည်းလမ်းက အမြဲတမ်း မှန်ကန်တာ မဟုတ်ပါဘူး၊ ဘာလို့လဲဆိုတော့ ကျွန်တော်တို့ လုပ်ဖော်ကိုင်ဖက်က model ကို fine-tuning မလုပ်ခင်
distilbert-base-uncasedရဲ့ configuration ကို ပြောင်းလဲထားနိုင်လို့ပါပဲ။ တကယ့်ဘဝမှာတော့ ကျွန်တော်တို့ အရင်ဆုံး သူတို့နဲ့ စစ်ဆေးချင်ပါလိမ့်မယ်၊ ဒါပေမယ့် ဒီအပိုင်းရဲ့ ရည်ရွယ်ချက်အတွက်တော့ သူတို့က default configuration ကို အသုံးပြုခဲ့တယ်လို့ ယူဆပါမယ်။
ပြီးရင် ဒါကို configuration ရဲ့ push_to_hub() function နဲ့ ကျွန်တော်တို့ရဲ့ model repository ကို push လုပ်နိုင်ပါတယ်။
config.push_to_hub(model_checkpoint, commit_message="Add config.json")အခု main branch ပေါ်က နောက်ဆုံး commit ကနေ model ကို load လုပ်ခြင်းဖြင့် ဒါက အလုပ်ဖြစ်လားဆိုတာ စစ်ဆေးနိုင်ပါပြီ-
reader = pipeline("question-answering", model=model_checkpoint, revision="main")
context = r"""
Extractive Question Answering is the task of extracting an answer from a text
given a question. An example of a question answering dataset is the SQuAD
dataset, which is entirely based on that task. If you would like to fine-tune a
model on a SQuAD task, you may leverage the
examples/pytorch/question-answering/run_squad.py script.
🤗 Transformers is interoperable with the PyTorch, TensorFlow, and JAX
frameworks, so you can use your favourite tools for a wide variety of tasks!
"""
question = "What is extractive question answering?"
reader(question=question, context=context){'score': 0.38669535517692566,
'start': 34,
'end': 95,
'answer': 'the task of extracting an answer from a text given a question'}ဝိုး၊ အလုပ်ဖြစ်သွားပြီ! သင် ခုလေးတင် သင်ယူခဲ့တာတွေကို ပြန်လည်အကျဉ်းချုပ်ကြည့်ရအောင်…
- Python မှာ errors တွေကို tracebacks လို့သိကြပြီး အောက်ကနေ အပေါ်သို့ ဖတ်ရပါတယ်။ error message ရဲ့ နောက်ဆုံးလိုင်းက ပြဿနာရဲ့ source ကို ရှာဖွေဖို့ လိုအပ်တဲ့ အချက်အလက်တွေကို အများအားဖြင့် ပါဝင်ပါတယ်။
- နောက်ဆုံးလိုင်းမှာ လုံလောက်တဲ့ အချက်အလက်တွေ မပါဝင်ဘူးဆိုရင်၊ traceback ကို အပေါ်ကိုတက်ပြီး error ဘယ်နေရာမှာ ဖြစ်ခဲ့လဲဆိုတာ source code ထဲမှာ ဖော်ထုတ်နိုင်မလားဆိုတာ ကြည့်ပါ။
- error messages တွေထဲက တစ်ခုမှ သင့်ကို ပြဿနာ debug လုပ်ဖို့ မကူညီနိုင်ဘူးဆိုရင်၊ အလားတူပြဿနာအတွက် online မှာ ဖြေရှင်းနည်း ရှာဖွေကြည့်ပါ။
huggingface_hublibrary က Hub ပေါ်က repositories တွေနဲ့ အပြန်အလှန်တုံ့ပြန်ဖို့နဲ့ debug လုပ်ဖို့ အသုံးပြုနိုင်တဲ့ ကိရိယာအစုံအလင်ကို ပံ့ပိုးပေးပါတယ်။
အခု pipeline ကို ဘယ်လို debug လုပ်ရမလဲဆိုတာ သင်သိပြီဆိုတော့၊ model ရဲ့ forward pass မှာ ပိုမိုခက်ခဲတဲ့ ဥပမာတစ်ခုကို ကြည့်ရအောင်။
သင့် Model ၏ Forward Pass ကို Debug လုပ်ခြင်း
pipeline က predictions တွေကို မြန်မြန်ဆန်ဆန် ထုတ်လုပ်ဖို့ လိုအပ်တဲ့ applications အများစုအတွက် ကောင်းမွန်ပေမယ့်၊ တခါတလေ model ရဲ့ logits တွေကို ဝင်ရောက်ကြည့်ရှုဖို့ လိုအပ်ပါလိမ့်မယ် (ဥပမာ- သင်အသုံးပြုချင်တဲ့ custom post-processing အချို့ရှိရင်)။ ဒီကိစ္စမှာ ဘာတွေမှားနိုင်သလဲဆိုတာ ကြည့်ဖို့၊ ကျွန်တော်တို့ရဲ့ pipeline ကနေ model နဲ့ tokenizer ကို အရင်ဆုံး ယူလိုက်ရအောင်။
tokenizer = reader.tokenizer model = reader.model
နောက်ထပ် မေးခွန်းတစ်ခု လိုအပ်တာကြောင့်၊ ကျွန်တော်တို့ အကြိုက်ဆုံး frameworks တွေကို ထောက်ပံ့ပေးထားခြင်းရှိမရှိ ကြည့်ရအောင်။
question = "Which frameworks can I use?"Chapter 7 မှာ ကျွန်တော်တို့ တွေ့ခဲ့ရတဲ့အတိုင်း၊ ကျွန်တော်တို့ လုပ်ဆောင်ရမယ့် ပုံမှန်အဆင့်တွေက inputs တွေကို tokenize လုပ်တာ၊ start နဲ့ end tokens တွေရဲ့ logits တွေကို ထုတ်ယူတာ၊ ပြီးတော့ answer span ကို decode လုပ်တာတွေပါပဲ-
import torch
inputs = tokenizer(question, context, add_special_tokens=True)
input_ids = inputs["input_ids"][0]
outputs = model(**inputs)
answer_start_scores = outputs.start_logits
answer_end_scores = outputs.end_logits
# score ရဲ့ argmax နဲ့ answer ရဲ့ အဖြစ်နိုင်ဆုံး အစကို ရယူပါ
answer_start = torch.argmax(answer_start_scores)
# score ရဲ့ argmax နဲ့ answer ရဲ့ အဖြစ်နိုင်ဆုံး အဆုံးကို ရယူပါ
answer_end = torch.argmax(answer_end_scores) + 1
answer = tokenizer.convert_tokens_to_string(
tokenizer.convert_ids_to_tokens(input_ids[answer_start:answer_end])
)
print(f"Question: {question}")
print(f"Answer: {answer}")"""
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
/var/folders/28/k4cy5q7s2hs92xq7_h89_vgm0000gn/T/ipykernel_75743/2725838073.py in <module>
1 inputs = tokenizer(question, text, add_special_tokens=True)
2 input_ids = inputs["input_ids"]
----> 3 outputs = model(**inputs)
4 answer_start_scores = outputs.start_logits
5 answer_end_scores = outputs.end_logits
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs)
1049 if not (self._backward_hooks or self._forward_hooks or self._forward_pre_hooks or _global_backward_hooks
1050 or _global_forward_hooks or _global_forward_pre_hooks):
-> 1051 return forward_call(*input, **kwargs)
1052 # Do not call functions when jit is used
1053 full_backward_hooks, non_full_backward_hooks = [], []
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/transformers/models/distilbert/modeling_distilbert.py in forward(self, input_ids, attention_mask, head_mask, inputs_embeds, start_positions, end_positions, output_attentions, output_hidden_states, return_dict)
723 return_dict = return_dict if return_dict is not None else self.config.use_return_dict
724
--> 725 distilbert_output = self.distilbert(
725 distilbert_output = self.distilbert(
726 input_ids=input_ids,
727 attention_mask=attention_mask,
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs)
1049 if not (self._backward_hooks or self._forward_hooks or self._forward_pre_hooks or _global_backward_hooks
1050 or _global_forward_hooks or _global_forward_pre_hooks):
-> 1051 return forward_call(*input, **kwargs)
1052 # Do not call functions when jit is used
1053 full_backward_hooks, non_full_backward_hooks = [], []
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/transformers/models/distilbert/modeling_distilbert.py in forward(self, input_ids, attention_mask, head_mask, inputs_embeds, output_attentions, output_hidden_states, return_dict)
471 raise ValueError("You cannot specify both input_ids and inputs_embeds at the same time")
472 elif input_ids is not None:
--> 473 input_shape = input_ids.size()
474 elif inputs_embeds is not None:
475 input_shape = inputs_embeds.size()[:-1]
AttributeError: 'list' object has no attribute 'size'
"""ဟာ၊ ကျွန်တော်တို့ code ထဲမှာ bug တစ်ခုရှိပုံရတယ်။ ဒါပေမယ့် ကျွန်တော်တို့ debug လုပ်ရတာ မကြောက်ပါဘူး။ Python debugger ကို notebook မှာ အသုံးပြုနိုင်ပါတယ်။
ဒါမှမဟုတ် terminal မှာ-
ဒီနေရာမှာ error message က 'list' object has no attribute 'size' လို့ ပြောထားတာကို မြင်ရပြီး၊ model(**inputs) မှာ ပြဿနာဖြစ်ပွားခဲ့တဲ့ လိုင်းကို --> မြှားက ညွှန်ပြနေတာကို မြင်ရပါတယ်။ ဒါကို Python debugger ကို အသုံးပြုပြီး interactive mode နဲ့ debug လုပ်နိုင်ပါတယ်၊ ဒါပေမယ့် အခုတော့ ကျွန်တော်တို့ inputs ရဲ့ slice တစ်ခုကို ရိုးရှင်းစွာ print ထုတ်ပြီး ဘာတွေရှိသလဲဆိုတာ ကြည့်ရအောင်။
inputs["input_ids"][:5][101, 2029, 7705, 2015, 2064]ဒါက သာမန် Python list တစ်ခုလိုတော့ မြင်ရပါတယ်၊ ဒါပေမယ့် type ကို ထပ်စစ်ကြည့်ရအောင်။
type(inputs["input_ids"])listဟုတ်တယ်၊ ဒါက Python list တစ်ခု သေချာပါတယ်။ ဒါဆို ဘာမှားခဲ့တာလဲ။ Chapter 2 ကနေ မှတ်မိပါသေးလား၊ 🤗 Transformers မှာရှိတဲ့ AutoModelForXxx classes တွေက tensors (PyTorch ဒါမှမဟုတ် TensorFlow မှာ) ပေါ်မှာ အလုပ်လုပ်ပြီး၊ common operation တစ်ခုကတော့ PyTorch မှာဆိုရင် Tensor.size() ကို အသုံးပြုပြီး tensor ရဲ့ dimensions တွေကို ထုတ်ယူတာပါပဲ။ traceback ကို ထပ်ကြည့်ရအောင်၊ ဘယ်လိုင်းက exception ကို ဖြစ်စေခဲ့သလဲဆိုတာ ကြည့်ဖို့…
~/miniconda3/envs/huggingface/lib/python3.8/site-packages/transformers/models/distilbert/modeling_distilbert.py in forward(self, input_ids, attention_mask, head_mask, inputs_embeds, output_attentions, output_hidden_states, return_dict)
471 raise ValueError("You cannot specify both input_ids and inputs_embeds at the same time")
472 elif input_ids is not None:
--> 473 input_shape = input_ids.size()
474 elif inputs_embeds is not None:
475 input_shape = inputs_embeds.size()[:-1]
AttributeError: 'list' object has no attribute 'size'ကျွန်တော်တို့ code က input_ids.size() ကို ခေါ်ဖို့ ကြိုးစားခဲ့ပုံရပါတယ်။ ဒါပေမယ့် ဒါက list (container တစ်ခုသာ ဖြစ်တဲ့) Python list အတွက် အလုပ်လုပ်မှာ မဟုတ်ပါဘူး။ ဒီပြဿနာကို ဘယ်လိုဖြေရှင်းမလဲ။ Stack Overflow ပေါ်မှာ error message ကို ရှာကြည့်လိုက်တော့ သက်ဆိုင်ရာ hits အတော်များများ တွေ့ရပါတယ်။ ပထမဆုံးတစ်ခုကို နှိပ်လိုက်တဲ့အခါ ကျွန်တော်တို့ရဲ့ မေးခွန်းနဲ့ ဆင်တူတဲ့ မေးခွန်းတစ်ခုကို ပြသပြီး၊ အဖြေကို အောက်ပါ screenshot မှာ တွေ့ရပါလိမ့်မယ်။
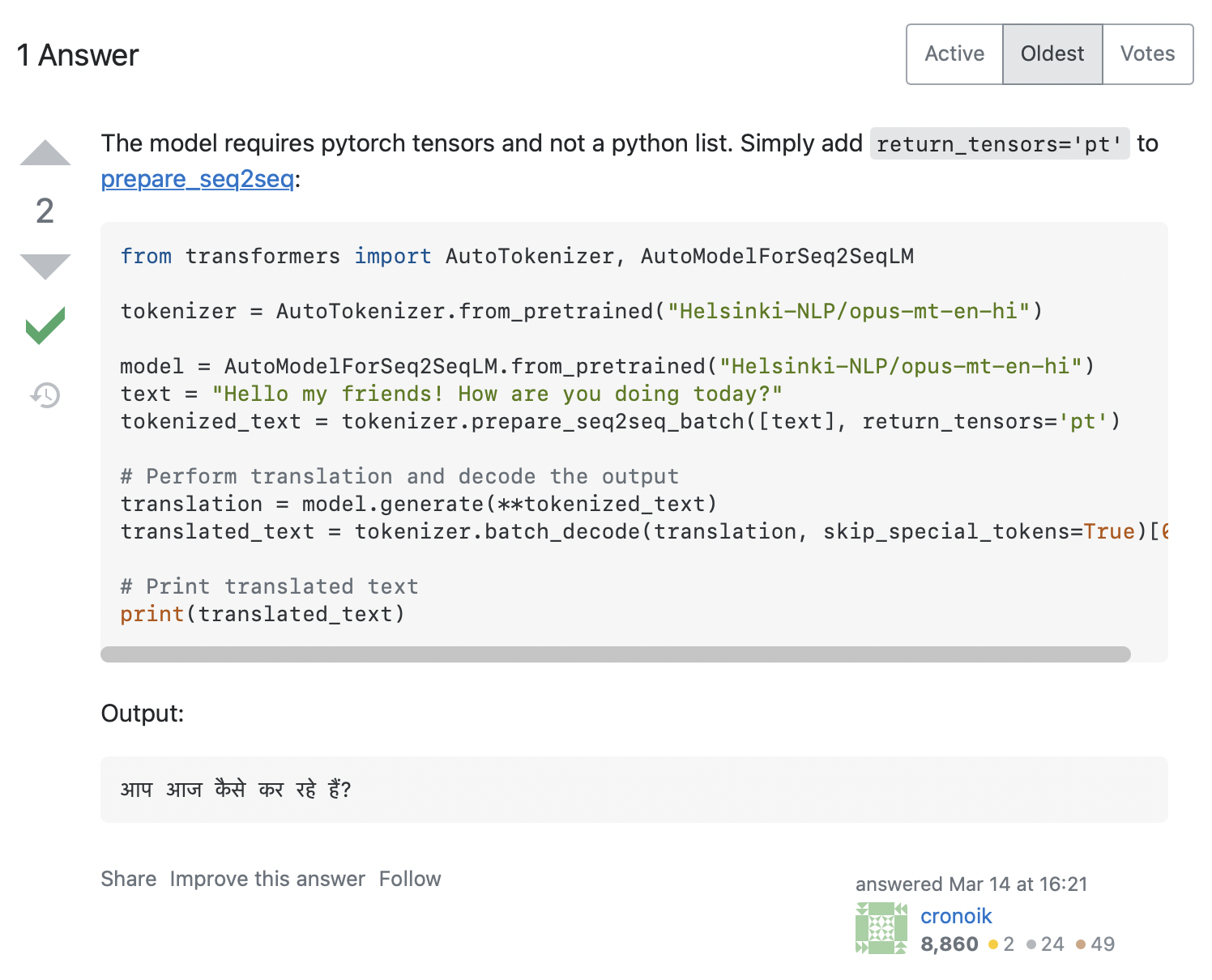
အဖြေက tokenizer မှာ return_tensors='pt' ကို ထည့်ဖို့ အကြံပြုထားတာကြောင့်၊ ဒါက ကျွန်တော်တို့အတွက် အလုပ်ဖြစ်မလားဆိုတာ ကြည့်ရအောင်-
inputs = tokenizer(question, context, add_special_tokens=True, return_tensors="pt")
input_ids = inputs["input_ids"][0]
outputs = model(**inputs)
answer_start_scores = outputs.start_logits
answer_end_scores = outputs.end_logits
# score ရဲ့ argmax နဲ့ answer ရဲ့ အဖြစ်နိုင်ဆုံး အစကို ရယူပါ
answer_start = torch.argmax(answer_start_scores)
# score ရဲ့ argmax နဲ့ answer ရဲ့ အဖြစ်နိုင်ဆုံး အဆုံးကို ရယူပါ
answer_end = torch.argmax(answer_end_scores) + 1
answer = tokenizer.convert_tokens_to_string(
tokenizer.convert_ids_to_tokens(input_ids[answer_start:answer_end])
)
print(f"Question: {question}")
print(f"Answer: {answer}")"""
Question: Which frameworks can I use?
Answer: pytorch, tensorflow, and jax
"""ကောင်းပြီ၊ အလုပ်ဖြစ်သွားပြီ! ဒါဟာ Stack Overflow က ဘယ်လောက်အသုံးဝင်တယ်ဆိုတာကို ပြသတဲ့ ဥပမာကောင်းတစ်ခုပါပဲ- အလားတူပြဿနာတစ်ခုကို ဖော်ထုတ်ခြင်းဖြင့်၊ community ထဲက တခြားသူတွေရဲ့ အတွေ့အကြုံကနေ ကျွန်တော်တို့ အကျိုးကျေးဇူး ရရှိခဲ့ပါတယ်။ ဒါပေမယ့် ဒီလို ရှာဖွေမှုမျိုးက အမြဲတမ်း သက်ဆိုင်ရာအဖြေကို ပေးမှာ မဟုတ်ပါဘူး၊ ဒါဆို ဒီလိုကိစ္စတွေမှာ သင်ဘာလုပ်နိုင်မလဲ။ ကံကောင်းစွာနဲ့ပဲ၊ Hugging Face forums မှာ ကြိုဆိုသော developers community တစ်ခု ရှိပြီး သင့်ကို ကူညီနိုင်ပါတယ်။ နောက်အပိုင်းမှာ၊ အဖြေရနိုင်ခြေရှိတဲ့ ကောင်းမွန်တဲ့ forum မေးခွန်းတွေကို ဘယ်လိုဖန်တီးရမလဲဆိုတာ ကြည့်ရပါမယ်။
ဝေါဟာရ ရှင်းလင်းချက် (Glossary)
- Error: ပရိုဂရမ်တစ်ခု အလုပ်လုပ်နေစဉ် ဖြစ်ပေါ်လာသော ပြဿနာတစ်ခုကြောင့် ၎င်းသည် ပုံမှန်အတိုင်း ဆက်လက်လုပ်ဆောင်နိုင်ခြင်းမရှိခြင်း။
- Predictions: Machine Learning မော်ဒယ်တစ်ခုက input data ကို အခြေခံပြီး ခန့်မှန်းထုတ်ပေးသော ရလဒ်များ။
- Transformer Model: Natural Language Processing (NLP) မှာ အောင်မြင်မှုများစွာရရှိခဲ့တဲ့ deep learning architecture တစ်မျိုးပါ။
- Debug: ကွန်ပျူတာပရိုဂရမ်တစ်ခုရှိ အမှားများ (bugs) ကို ရှာဖွေ၊ ဖော်ထုတ်ပြီး ပြင်ဆင်ခြင်း။
- Training Phase: Machine Learning မော်ဒယ်တစ်ခုကို ဒေတာများဖြင့် လေ့ကျင့်ပေးသည့် အချိန်အပိုင်းအခြား။
- Template Model Repository: နမူနာအဖြစ် အသုံးပြုရန် ပြင်ဆင်ထားသော model repository။
- Hugging Face Hub: AI မော်ဒယ်တွေ၊ datasets တွေနဲ့ demo တွေကို အခြားသူတွေနဲ့ မျှဝေဖို့၊ ရှာဖွေဖို့နဲ့ ပြန်လည်အသုံးပြုဖို့အတွက် အွန်လိုင်း platform တစ်ခု ဖြစ်ပါတယ်။
- Jupyter Notebook: code, text, images, နှင့် mathematical equations တို့ကို ပေါင်းစပ်နိုင်သော interactive computing environment။
notebook_login()Function: Jupyter/Colab Notebooks များတွင် Hugging Face Hub သို့ login ဝင်ရန် အသုံးပြုသော function။- Terminal: command-line interface မှတစ်ဆင့် ကွန်ပျူတာကို ထိန်းချုပ်ရန် အသုံးပြုသော interface။
huggingface-cli login: Hugging Face CLI (Command Line Interface) မှ Hugging Face Hub သို့ login ဝင်ရန် အသုံးပြုသော command။- Token: Hugging Face Hub တွင် အကောင့် authentication အတွက် အသုံးပြုသော ထူးခြားသည့် ကုဒ်။
~/.cache/huggingface/: Hugging Face libraries များက cache ဖိုင်များကို သိမ်းဆည်းသော default directory။distutils.dir_util.copy_tree: Python ရဲ့distutilslibrary ကနေ directory tree တစ်ခုလုံးကို copy လုပ်ဖို့အတွက် utility function။huggingface_hubLibrary: Hugging Face Hub နှင့် အပြန်အလှန်ဆက်သွယ်ရန် အသုံးပြုသော Python library။RepositoryClass:huggingface_hublibrary မှ Git repository များကို ကိုင်တွယ်ရန်အတွက် class။snapshot_download()Function: Hugging Face Hub မှ repository တစ်ခု၏ snapshot ကို download လုပ်ရန် function။create_repo()Function: Hugging Face Hub ပေါ်တွင် repository အသစ်တစ်ခု ဖန်တီးရန် function။get_full_repo_name()Function: Hugging Face Hub ပေါ်ရှိ repository ၏ full name (username/repo_name) ကို ရယူရန် function။local_dir: Repository ကို clone လုပ်မည့် local directory။clone_from: Repository ကို clone လုပ်မည့် remote URL သို့မဟုတ် ID။push_to_hub()Method: Hugging Face Transformers library မှ model, tokenizer, သို့မဟုတ် configuration များကို Hugging Face Hub သို့ upload လုပ်ရန် အသုံးပြုသော method။- Pipeline from 🤗 Transformers: Hugging Face Transformers library မှ model များကို သီးခြားလုပ်ငန်းများအတွက် အသုံးပြုရလွယ်ကူစေရန် အဆင့်မြင့် abstraction။
- Question Answering Project: မေးခွန်းတစ်ခုကို ဖြေကြားရန် AI model များကို အသုံးပြုသည့် project။
- E-commerce Website: အင်တာနက်မှတစ်ဆင့် ကုန်ပစ္စည်းများ သို့မဟုတ် ဝန်ဆောင်မှုများကို ဝယ်ယူရောင်းချနိုင်သော website။
- Consumer Products: ပုံမှန်စားသုံးသူများ အသုံးပြုသော ကုန်ပစ္စည်းများ။
- SQuAD (Stanford Question Answering Dataset): မေးခွန်းဖြေဆိုခြင်းအတွက် အသုံးပြုသော လူကြိုက်များသည့် dataset။
- Model ID: Hugging Face Hub ပေါ်ရှိ model တစ်ခု၏ ထူးခြားသော ဖော်ထုတ်ကိန်း (identifier)။
OSError: Python တွင် operating system-related error များကို ညွှန်ပြသော exception အမျိုးအစား။config.jsonFile: Transformer model ၏ configuration (ဥပမာ- hidden size, number of layers) ကို သိမ်းဆည်းထားသော JSON file။- Python Traceback (Stack Trace): Python ပရိုဂရမ်တစ်ခုတွင် error ဖြစ်ပွားခဲ့သည့်အခါ function calls ၏ sequence ကို ပြသသော error report။
- Exception: Python ပရိုဂရမ်တစ်ခု၏ ပုံမှန်စီးဆင်းမှုကို ပြတ်တောက်စေသော error တစ်မျိုး။
- Stack Overflow: programmer များအတွက် မေးခွန်းများမေးရန်နှင့် အဖြေများရှာဖွေရန် လူကြိုက်များသော Q&A website။
- Typo: စာလုံးပေါင်းမှားယွင်းမှု။
- DistilBERT: BERT model ၏ ပေါ့ပါးသော version။
.gitattributes: Git repository အတွင်းရှိ files များကို မည်သို့ ကိုင်တွယ်ရမည်ကို သတ်မှတ်ရန် အသုံးပြုသော Git configuration file။README.md: Markdown format ဖြင့် ရေးသားထားသော project ၏ အဓိက မှတ်တမ်းဖိုင်။pytorch_model.bin: PyTorch framework ဖြင့် trained လုပ်ထားသော model ၏ weights များကို သိမ်းဆည်းထားသော binary file။special_tokens_map.json: tokenizer ၏ special tokens များနှင့် ၎င်းတို့၏ mappings များကို သိမ်းဆည်းထားသော JSON file။tokenizer_config.json: tokenizer ၏ configuration ကို သိမ်းဆည်းထားသော JSON file။training_args.bin: training arguments များကို သိမ်းဆည်းထားသော binary file။vocab.txt: tokenizer ၏ vocabulary ကို သိမ်းဆည်းထားသော text file။AutoConfigClass: Hugging Face Transformers library မှာ ပါဝင်တဲ့ class တစ်ခုဖြစ်ပြီး မော်ဒယ်အမည်ကို အသုံးပြုပြီး သက်ဆိုင်ရာ configuration ကို အလိုအလျောက် load လုပ်ပေးသည်။from_pretrained()Method: Hugging Face Transformers library မှ model, tokenizer, သို့မဟုတ် configuration ကို pretrained version မှ load လုပ်ရန် အသုံးပြုသော method။- Default Configuration: model သို့မဟုတ် library တစ်ခု၏ မူရင်း (standard) configuration။
commit_message: Git repository သို့ ပြောင်းလဲမှုများကို push လုပ်သောအခါ ထည့်သွင်းသော message။mainBranch: Git repository ၏ ပင်မ development branch။revisionArgument:pipeline()function တွင် model ၏ သတ်မှတ်ထားသော revision (branch name, commit hash သို့မဟုတ် tag) မှ load လုပ်ရန်။- Extractive Question Answering: ပေးထားသော စာသားတစ်ခုမှ မေးခွန်း၏ အဖြေကို တိုက်ရိုက်ထုတ်ယူခြင်း။
- Interoperable: မတူညီသော စနစ်များ သို့မဟုတ် applications များကြား အတူတကွ အလုပ်လုပ်နိုင်ခြင်း။
- PyTorch: Facebook (ယခု Meta) က ဖန်တီးထားတဲ့ open-source machine learning library တစ်ခုဖြစ်ပြီး deep learning မော်ဒယ်တွေ တည်ဆောက်ဖို့အတွက် အသုံးပြုပါတယ်။
- TensorFlow: Google က ဖန်တီးထားတဲ့ open-source machine learning library တစ်ခုဖြစ်ပြီး deep learning မော်ဒယ်တွေ တည်ဆောက်ဖို့အတွက် အသုံးပြုပါတယ်။
- JAX: Google မှ ထုတ်လုပ်ထားသော high-performance numerical computing library တစ်ခုဖြစ်ပြီး Python မှာ automatic differentiation ကို ထောက်ပံ့ပေးသည်။
- Tracebacks: Python မှာ error ဖြစ်တဲ့အခါ function call sequence ကိုပြတဲ့ error report။
- Source Code: ပရိုဂရမ်တစ်ခု၏ မူရင်း code။
- Forward Pass: Neural network တစ်ခုသို့ input data ကို ပေးပို့ပြီး output ကို တွက်ချက်ခြင်း။
- Logits: Neural network ၏ နောက်ဆုံး output layer မှ ထုတ်ပေးသော raw, unnormalized scores များ။
- Custom Post-processing: model ၏ output များကို ပိုမိုအသုံးဝင်သော ပုံစံသို့ ပြောင်းလဲရန်အတွက် သီးခြားပြင်ဆင်ထားသော လုပ်ငန်းစဉ်။
- Tokenizer: စာသား (သို့မဟုတ် အခြားဒေတာ) ကို AI မော်ဒယ်များ စီမံဆောင်ရွက်နိုင်ရန် tokens တွေအဖြစ် ပိုင်းခြားပေးသည့် ကိရိယာ သို့မဟုတ် လုပ်ငန်းစဉ်။
torchLibrary: PyTorch framework အတွက် Python library။add_special_tokens=True: tokenizer ကို input sequence ထဲသို့ special tokens (ဥပမာ-[CLS],[SEP]) ထည့်သွင်းရန် ညွှန်ကြားခြင်း။input_ids: Tokenizer မှ ထုတ်ပေးသော tokens တစ်ခုစီ၏ ထူးခြားသော ဂဏန်းဆိုင်ရာ ID များ။outputs.start_logits: Question Answering model မှ အဖြေစတင်မည့် token အတွက် ထုတ်ပေးသော logits များ။outputs.end_logits: Question Answering model မှ အဖြေပြီးဆုံးမည့် token အတွက် ထုတ်ပေးသော logits များ။torch.argmax(): PyTorch tensor တစ်ခု၏ အမြင့်ဆုံးတန်ဖိုးရှိသော index ကို ရယူသော function။tokenizer.convert_tokens_to_string(): tokens စာရင်းကို string တစ်ခုအဖြစ် ပြန်ပြောင်းပေးသော tokenizer method။tokenizer.convert_ids_to_tokens(): ID စာရင်းကို tokens စာရင်းအဖြစ် ပြန်ပြောင်းပေးသော tokenizer method။- AttributeError: Python တွင် object တစ်ခု၌ မရှိသော attribute ကို ဝင်ရောက်ကြည့်ရှုရန် ကြိုးစားသောအခါ ဖြစ်ပေါ်လာသော exception။
- Python Debugger: Python code များကို step-by-step စစ်ဆေးပြီး debug လုပ်ရန် ကိရိယာ။
- Slice: list သို့မဟုတ် array ၏ အစိတ်အပိုင်းတစ်ခု။
Tensor.size()Method: PyTorch tensor တစ်ခု၏ dimensions များကို ပြန်ပေးသော method။return_tensors='pt': tokenizer ကို output များကို PyTorch tensors အဖြစ် ပြန်ပေးရန် ညွှန်ကြားခြင်း။- Community of Developers: ဆော့ဖ်ဝဲလ်ဖန်တီးသူများ၏ အဖွဲ့အစည်း။