course documentation
🤗 Transformers တွေက လုပ်ငန်းတာဝန်တွေကို ဘယ်လိုဖြေရှင်းပေးလဲ။
🤗 Transformers တွေက လုပ်ငန်းတာဝန်တွေကို ဘယ်လိုဖြေရှင်းပေးလဲ။
”Transformers တွေက ဘာတွေလုပ်နိုင်လဲ။” မှာ Natural Language Processing (NLP)၊ speech and audio, computer vision လုပ်ငန်းတာဝန်တွေနဲ့ ၎င်းတို့ရဲ့ အရေးကြီးတဲ့ အသုံးချမှုတွေအကြောင်းကို သင်ယူခဲ့ပြီးပါပြီ။ ဒီစာမျက်နှာကတော့ မော်ဒယ်တွေက ဒီလုပ်ငန်းတာဝန်တွေကို ဘယ်လိုဖြေရှင်းပေးလဲဆိုတာကို အသေးစိတ်လေ့လာပြီး၊ အတွင်းပိုင်းမှာ ဘာတွေဖြစ်ပျက်နေလဲဆိုတာကို ရှင်းပြပေးမှာပါ။ လုပ်ငန်းတာဝန်တစ်ခုကို ဖြေရှင်းဖို့ နည်းလမ်းများစွာရှိပါတယ်။ အချို့မော်ဒယ်တွေက နည်းစနစ်အချို့ကို အသုံးပြုနိုင်သလို လုပ်ငန်းတာဝန်ကို ချဉ်းကပ်ပုံအသစ်တစ်ခုကနေတောင် ချဉ်းကပ်နိုင်ပါတယ်။ ဒါပေမယ့် Transformer မော်ဒယ်တွေအတွက်တော့ အခြေခံသဘောတရားက အတူတူပါပဲ။ ၎င်းတို့ရဲ့ ပြောင်းလွယ်ပြင်လွယ်ရှိတဲ့ architecture ကြောင့် မော်ဒယ်အများစုဟာ encoder, decoder သို့မဟုတ် encoder-decoder ဖွဲ့စည်းပုံရဲ့ အမျိုးအစားခွဲ (variant) တစ်ခု ဖြစ်ပါတယ်။
သီးခြား architectural variants တွေထဲ မဝင်ခင်မှာ၊ လုပ်ငန်းတာဝန်အများစုဟာ အလားတူ ပုံစံတစ်ခုကို လိုက်နာတယ်ဆိုတာ နားလည်ထားဖို့ အထောက်အကူဖြစ်ပါတယ်။ input data ကို မော်ဒယ်ကနေတစ်ဆင့် လုပ်ဆောင်ပြီး output ကို သီးခြားလုပ်ငန်းတစ်ခုအတွက် အနက်ပြန်ပါတယ်။ ကွာခြားချက်တွေကတော့ data ကို ဘယ်လိုပြင်ဆင်ထားလဲ၊ ဘယ်မော်ဒယ် architecture variant ကို အသုံးပြုထားလဲ၊ ပြီးတော့ output ကို ဘယ်လို လုပ်ဆောင်ထားလဲဆိုတာတွေပါပဲ။
လုပ်ငန်းတာဝန်တွေကို ဘယ်လိုဖြေရှင်းလဲဆိုတာ ရှင်းပြဖို့အတွက် မော်ဒယ်အတွင်းမှာ ဘာတွေဖြစ်ပျက်ပြီး အသုံးဝင်တဲ့ ခန့်မှန်းချက်တွေကို ထုတ်ပေးလဲဆိုတာကို ကြည့်သွားပါမယ်။ ကျွန်တော်တို့ အောက်ပါမော်ဒယ်တွေနဲ့ ၎င်းတို့ရဲ့ လုပ်ငန်းတာဝန်တွေကို လေ့လာပါမယ်။
- Wav2Vec2 ကို audio classification နဲ့ automatic speech recognition (ASR) အတွက်
- Vision Transformer (ViT) နဲ့ ConvNeXT ကို image classification အတွက်
- DETR ကို object detection အတွက်
- Mask2Former ကို image segmentation အတွက်
- GLPN ကို depth estimation အတွက်
- BERT ကို encoder ကိုအသုံးပြုတဲ့ text classification, token classification နဲ့ question answering လို NLP လုပ်ငန်းတာဝန်တွေအတွက်
- GPT2 ကို decoder ကိုအသုံးပြုတဲ့ text generation လို NLP လုပ်ငန်းတာဝန်တွေအတွက်
- BART ကို encoder-decoder ကိုအသုံးပြုတဲ့ summarization နဲ့ translation လို NLP လုပ်ငန်းတာဝန်တွေအတွက်
ဆက်မသွားခင်မှာ မူရင်း Transformer architecture ရဲ့ အခြေခံအသိပညာအချို့ ရှိထားတာ ကောင်းပါတယ်။ encoders, decoders နဲ့ attention တွေ ဘယ်လိုအလုပ်လုပ်လဲဆိုတာကို သိထားရင် Transformer မော်ဒယ်အမျိုးမျိုး ဘယ်လိုအလုပ်လုပ်လဲဆိုတာ နားလည်ဖို့ အထောက်အကူဖြစ်ပါလိမ့်မယ်။ အသေးစိတ်အချက်အလက်တွေအတွက် ကျွန်တော်တို့ရဲ့ အရင်အခန်း ကို သေချာကြည့်ရှုပေးပါ။
ဘာသာစကားအတွက် Transformer မော်ဒယ်များ
ဘာသာစကားမော်ဒယ်တွေဟာ ခေတ်သစ် NLP ရဲ့ အဓိကအချက်အချာမှာ ရှိပါတယ်။ ၎င်းတို့ကို စာသားတွေထဲက စကားလုံးတွေ ဒါမှမဟုတ် tokens တွေကြားက စာရင်းအင်းဆိုင်ရာ ပုံစံတွေနဲ့ ဆက်နွယ်မှုတွေကို သင်ယူခြင်းဖြင့် လူသားဘာသာစကားကို နားလည်ပြီး ဖန်တီးနိုင်အောင် ဒီဇိုင်းထုတ်ထားပါတယ်။
Transformer ကို မူလက machine translation အတွက် ဒီဇိုင်းထုတ်ခဲ့တာဖြစ်ပြီး၊ အဲဒီအချိန်ကတည်းက AI လုပ်ငန်းတာဝန်အားလုံးကို ဖြေရှင်းဖို့အတွက် အခြေခံ architecture တစ်ခု ဖြစ်လာခဲ့ပါတယ်။ အချို့လုပ်ငန်းတာဝန်တွေက Transformer ရဲ့ encoder ဖွဲ့စည်းပုံနဲ့ ပိုသင့်တော်ပြီး အချို့ကတော့ decoder နဲ့ ပိုလိုက်ဖက်ပါတယ်။ သို့သော် အချို့လုပ်ငန်းတာဝန်တွေကတော့ Transformer ရဲ့ encoder-decoder ဖွဲ့စည်းပုံ နှစ်ခုလုံးကို အသုံးပြုပါတယ်။
ဘာသာစကားမော်ဒယ်(language models)တွေ ဘယ်လိုအလုပ်လုပ်လဲ။
ဘာသာစကားမော်ဒယ်တွေဟာ ပတ်ဝန်းကျင်ရှိ စကားလုံးတွေရဲ့ အကြောင်းအရာ (context) ကို ပေးထားပြီး စကားလုံးတစ်လုံးရဲ့ ဖြစ်နိုင်ခြေ (probability) ကို ခန့်မှန်းဖို့ လေ့ကျင့်ပေးခြင်းဖြင့် အလုပ်လုပ်ပါတယ်။ ဒါက ၎င်းတို့ကို ဘာသာစကားကို အခြေခံနားလည်စေပြီး အခြားလုပ်ငန်းတာဝန်တွေဆီကို ယေဘုယျ (generalize) လုပ်နိုင်စေပါတယ်။
Transformer မော်ဒယ်တစ်ခုကို လေ့ကျင့်ဖို့အတွက် အဓိက ချဉ်းကပ်ပုံနှစ်မျိုးရှိပါတယ်။
Masked language modeling (MLM): BERT လို encoder မော်ဒယ်တွေ အသုံးပြုတဲ့ ဒီချဉ်းကပ်ပုံက input မှာရှိတဲ့ tokens အချို့ကို ကျပန်းဖုံးကွယ်ထားပြီး၊ ပတ်ဝန်းကျင်ရှိ context ပေါ် အခြေခံပြီး မူရင်း tokens တွေကို ခန့်မှန်းဖို့ မော်ဒယ်ကို လေ့ကျင့်ပေးပါတယ်။ ဒါက မော်ဒယ်ကို နှစ်လမ်းသွား context (ဖုံးကွယ်ထားတဲ့ စကားလုံးရဲ့ အရှေ့နဲ့ အနောက် နှစ်ဖက်လုံးက စကားလုံးတွေကို ကြည့်ခြင်း) ကို သင်ယူနိုင်စေပါတယ်။
Causal language modeling (CLM): GPT လို decoder မော်ဒယ်တွေ အသုံးပြုတဲ့ ဒီချဉ်းကပ်ပုံကတော့ sequence ထဲမှာရှိတဲ့ အရင် tokens အားလုံးပေါ် အခြေခံပြီး နောက် token ကို ခန့်မှန်းပါတယ်။ မော်ဒယ်ဟာ နောက် token ကို ခန့်မှန်းဖို့ ဘယ်ဘက် (အရင် tokens) က context ကိုသာ အသုံးပြုနိုင်ပါတယ်။
ဘာသာစကားမော်ဒယ် အမျိုးအစားများ
Transformers library မှာ ဘာသာစကားမော်ဒယ်တွေဟာ အများအားဖြင့် architectural categories သုံးမျိုးအောက်မှာ ရှိပါတယ်။
Encoder-only models (BERT ကဲ့သို့): ဒီမော်ဒယ်တွေဟာ နှစ်လမ်းသွား ချဉ်းကပ်ပုံကို အသုံးပြုပြီး context ကို နှစ်ဖက်လုံးကနေ နားလည်ပါတယ်။ ၎င်းတို့ဟာ classification, named entity recognition နဲ့ question answering လို စာသားကို နက်နက်နဲနဲ နားလည်ဖို့ လိုအပ်တဲ့ လုပ်ငန်းတာဝန်တွေအတွက် အသင့်တော်ဆုံး ဖြစ်ပါတယ်။
Decoder-only models (GPT, Llama ကဲ့သို့): ဒီမော်ဒယ်တွေဟာ စာသားကို ဘယ်မှညာသို့ လုပ်ဆောင်ပြီး text generation လုပ်ငန်းတာဝန်တွေမှာ အထူးကောင်းမွန်ပါတယ်။ ၎င်းတို့ဟာ စာကြောင်းတွေ ဖြည့်စွက်တာ၊ စာစီစာကုံးရေးတာ ဒါမှမဟုတ် prompt ပေါ် အခြေခံပြီး code ရေးတာမျိုးတွေတောင် လုပ်နိုင်ပါတယ်။
Encoder-decoder models (T5, BART ကဲ့သို့): ဒီမော်ဒယ်တွေဟာ ချဉ်းကပ်ပုံနှစ်မျိုးလုံးကို ပေါင်းစပ်ထားပါတယ်။ input ကို နားလည်ဖို့ encoder ကို အသုံးပြုပြီး output ကို ထုတ်ပေးဖို့ decoder ကို အသုံးပြုပါတယ်။ ၎င်းတို့ဟာ translation, summarization နဲ့ question answering လို sequence-to-sequence လုပ်ငန်းတာဝန်တွေမှာ ထူးချွန်ပါတယ်။

အရင်အခန်းမှာ ဆွေးနွေးခဲ့သလိုပဲ ဘာသာစကားမော်ဒယ်တွေကို များပြားလှတဲ့ စာသားဒေတာတွေနဲ့ self-supervised နည်းလမ်း (human annotations မပါဘဲ) နဲ့ ကြိုတင်လေ့ကျင့်လေ့ရှိပြီး၊ ပြီးမှ သီးခြားလုပ်ငန်းတာဝန်တွေအတွက် fine-tune လုပ်ပါတယ်။ transfer learning လို့ခေါ်တဲ့ ဒီချဉ်းကပ်ပုံက မော်ဒယ်တွေကို သီးခြားလုပ်ငန်းတာဝန်အတွက် နည်းပါးတဲ့ ဒေတာပမာဏနဲ့ မတူညီတဲ့ NLP လုပ်ငန်းတာဝန်များစွာကို လိုက်လျောညီထွေဖြစ်အောင် လုပ်ဆောင်နိုင်စေပါတယ်။
အောက်ပါအခန်းတွေမှာတော့ သီးခြားမော်ဒယ် architecture တွေကို ဘယ်လိုအသုံးပြုပြီး speech, vision နဲ့ text domains တွေတစ်လျှောက် လုပ်ငန်းတာဝန်အမျိုးမျိုးကို ဘယ်လိုဖြေရှင်းတယ်ဆိုတာကို လေ့လာသွားပါမယ်။
Transformer architecture ရဲ့ ဘယ်အပိုင်း (encoder, decoder ဒါမှမဟုတ် နှစ်ခုလုံး) က သီးခြား NLP လုပ်ငန်းတာဝန်တစ်ခုအတွက် အသင့်တော်ဆုံးလဲဆိုတာ နားလည်ထားတာဟာ မှန်ကန်တဲ့မော်ဒယ်ကို ရွေးချယ်ဖို့ အဓိကကျပါတယ်။ ယေဘုယျအားဖြင့် နှစ်လမ်းသွား context လိုအပ်တဲ့ လုပ်ငန်းတာဝန်တွေက encoders ကို အသုံးပြုပြီး၊ text generate လုပ်တဲ့ လုပ်ငန်းတာဝန်တွေက decoders ကို အသုံးပြုကာ၊ sequence တစ်ခုကို နောက် sequence တစ်ခုသို့ ပြောင်းလဲတဲ့ လုပ်ငန်းတာဝန်တွေကတော့ encoder-decoders ကို အသုံးပြုပါတယ်။
စာသား ဖန်တီးခြင်း (Text generation)
စာသား ဖန်တီးခြင်းဆိုတာက prompt ဒါမှမဟုတ် input တစ်ခုအပေါ် အခြေခံပြီး ဆက်စပ်မှုရှိတဲ့ စာသားတွေကို ဖန်တီးတာကို ဆိုလိုပါတယ်။
GPT-2 ဟာ များပြားလှတဲ့ စာသားတွေနဲ့ ကြိုတင်လေ့ကျင့်ထားတဲ့ decoder-only မော်ဒယ်တစ်ခုပါ။ ၎င်းဟာ prompt တစ်ခုပေးထားရင် ယုံကြည်နိုင်လောက်တဲ့ (အမြဲတမ်းတော့ မဟုတ်ဘူး) စာသားတွေကို ဖန်တီးနိုင်ပြီး၊ မေးခွန်းဖြေတာလို အခြား NLP လုပ်ငန်းတာဝန်တွေကိုလည်း ရှင်းရှင်းလင်းလင်း လေ့ကျင့်ထားခြင်းမရှိဘဲ လုပ်ဆောင်နိုင်ပါတယ်။
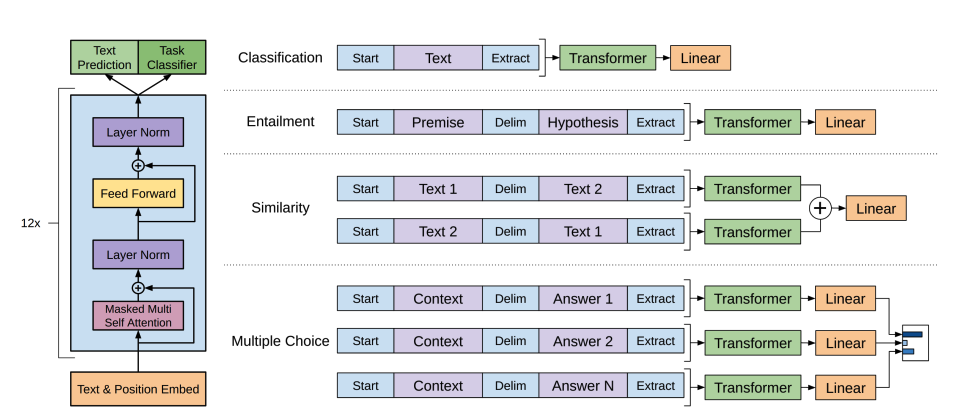
GPT-2 ဟာ စကားလုံးတွေကို tokenize လုပ်ပြီး token embedding တွေ ထုတ်ပေးဖို့အတွက် byte pair encoding (BPE) ကို အသုံးပြုပါတယ်။ sequence ထဲမှာ token တစ်ခုချင်းစီရဲ့ နေရာကို ပြသဖို့ positional encodings တွေကို token embeddings တွေမှာ ထပ်ထည့်ပါတယ်။ input embeddings တွေကို decoder blocks အများအပြားကနေတဆင့် ဖြတ်သန်းပြီး final hidden state အချို့ကို ထုတ်ပေးပါတယ်။ decoder block တစ်ခုစီအတွင်းမှာ GPT-2 က masked self-attention layer ကို အသုံးပြုပါတယ်။ ဆိုလိုတာက GPT-2 ဟာ နောက်လာမယ့် tokens တွေကို မကြည့်နိုင်ပါဘူး။ ဘယ်ဘက် (အရင် tokens) က tokens တွေကိုသာ ကြည့်ခွင့်ရှိပါတယ်။ ဒါက BERT ရဲ့ [
mask] token နဲ့ မတူပါဘူး။ ဘာလို့လဲဆိုတော့ masked self-attention မှာ future tokens တွေအတွက် score ကို0သတ်မှတ်ဖို့ attention mask ကို အသုံးပြုထားလို့ပါ။Decoder ကနေ ထွက်လာတဲ့ output ကို language modeling head ကို ပေးပို့ပါတယ်။ အဲဒီကနေ linear transformation တစ်ခုကို လုပ်ဆောင်ပြီး hidden states တွေကို logits အဖြစ် ပြောင်းလဲပေးပါတယ်။ label ကတော့ sequence ထဲမှာရှိတဲ့ နောက် token ဖြစ်ပြီး logits တွေကို ညာဘက်သို့ တစ်နေရာ ရွှေ့ခြင်းဖြင့် ဖန်တီးပါတယ်။ shifted logits တွေနဲ့ labels တွေကြားက cross-entropy loss ကို တွက်ချက်ပြီး နောက်လာမယ့် အဖြစ်နိုင်ဆုံး token ကို ထုတ်ပေးပါတယ်။
GPT-2 ရဲ့ pretraining ရည်ရွယ်ချက်က causal language modeling ပေါ် အခြေခံပြီး sequence ထဲက နောက်စကားလုံးကို ခန့်မှန်းတာပါ။ ဒါက GPT-2 ကို စာသားဖန်တီးခြင်းနဲ့ ပတ်သက်တဲ့ လုပ်ငန်းတာဝန်တွေမှာ အထူးကောင်းမွန်စေပါတယ်။
စာသား ဖန်တီးခြင်းကို ကိုယ်တိုင်စမ်းကြည့်ဖို့ အဆင်သင့်ဖြစ်ပြီလား။ DistilGPT-2 ကို ဘယ်လို fine-tune လုပ်ပြီး inference အတွက် ဘယ်လိုအသုံးပြုရမလဲဆိုတာ လေ့လာဖို့ ကျွန်တော်တို့ရဲ့ ပြည့်စုံတဲ့ causal language modeling guide ကို ကြည့်ရှုပါ။
စာသား ဖန်တီးခြင်းနဲ့ ပတ်သက်တဲ့ အချက်အလက်အများကြီးအတွက် text generation strategies guide ကို ကြည့်ရှုပါ။
စာသား အမျိုးအစားခွဲခြားခြင်း (Text classification)
စာသား အမျိုးအစားခွဲခြားခြင်းဆိုတာ စာသားမှတ်တမ်းတွေကို ကြိုတင်သတ်မှတ်ထားတဲ့ အမျိုးအစားတွေ (ဥပမာ- sentiment analysis, topic classification, spam detection) သို့ သတ်မှတ်ပေးတာကို ဆိုလိုပါတယ်။
BERT ဟာ encoder-only မော်ဒယ်တစ်ခုဖြစ်ပြီး စာသားကို နှစ်ဖက်စလုံးက စကားလုံးတွေကို ကြည့်ရှုခြင်းဖြင့် ပိုမိုကြွယ်ဝတဲ့ ကိုယ်စားပြုမှု (representations) တွေကို သင်ယူဖို့အတွက် deep bidirectionality ကို ထိရောက်စွာ အကောင်အထည်ဖော်ခဲ့တဲ့ ပထမဆုံးမော်ဒယ် ဖြစ်ပါတယ်။
BERT ဟာ စာသားရဲ့ token embedding ကို ထုတ်ပေးဖို့အတွက် WordPiece tokenization ကို အသုံးပြုပါတယ်။ စာကြောင်းတစ်ကြောင်းနဲ့ စာကြောင်းနှစ်ကြောင်းရဲ့ ကွာခြားချက်ကို ပြောပြဖို့အတွက် အထူး
[SEP]token တစ်ခုကို ခွဲခြားဖို့ ထပ်ထည့်ပါတယ်။ sequence of text တိုင်းရဲ့ အစမှာ အထူး[CLS]token တစ်ခုကို ထပ်ထည့်ပါတယ်။[CLS]token ပါတဲ့ နောက်ဆုံး output ကို classification လုပ်ငန်းတာဝန်တွေအတွက် classification head ရဲ့ input အဖြစ် အသုံးပြုပါတယ်။ BERT ဟာ token တစ်ခုက စာကြောင်းတစ်စုံမှာ ပထမစာကြောင်း ဒါမှမဟုတ် ဒုတိယစာကြောင်းမှာ ပါဝင်တယ်ဆိုတာကို ဖော်ပြဖို့ segment embedding တစ်ခုကိုလည်း ထပ်ထည့်ပါတယ်။BERT ကို masked language modeling နဲ့ next-sentence prediction ဆိုတဲ့ ရည်ရွယ်ချက်နှစ်ခုနဲ့ ကြိုတင်လေ့ကျင့်ထားပါတယ်။ masked language modeling မှာ input tokens အချို့ ရာခိုင်နှုန်းကို ကျပန်းဖုံးကွယ်ထားပြီး မော်ဒယ်က ဒါတွေကို ခန့်မှန်းဖို့ လိုပါတယ်။ ဒါက မော်ဒယ်က စကားလုံးအားလုံးကို မြင်ပြီး နောက်စကားလုံးကို “ခန့်မှန်း” နိုင်တဲ့ bidirectionality ပြဿနာကို ဖြေရှင်းပေးပါတယ်။ ခန့်မှန်းထားတဲ့ masked tokens တွေရဲ့ final hidden states တွေကို feedforward network တစ်ခုကို ပေးပို့ပြီး vocabulary ပေါ်က softmax နဲ့ ဖုံးကွယ်ထားတဲ့ စကားလုံးကို ခန့်မှန်းပါတယ်။
ဒုတိယ pretraining object က next-sentence prediction ဖြစ်ပါတယ်။ မော်ဒယ်ဟာ စာကြောင်း B က စာကြောင်း A နောက်က လိုက်သလားဆိုတာကို ခန့်မှန်းရပါမယ်။ အချိန်ရဲ့ ထက်ဝက်မှာ စာကြောင်း B က နောက်လာမယ့် စာကြောင်းဖြစ်ပြီး ကျန်ထက်ဝက်မှာတော့ စာကြောင်း B က ကျပန်းစာကြောင်းတစ်ကြောင်း ဖြစ်ပါတယ်။ နောက်လာမယ့် စာကြောင်းဟုတ်မဟုတ်ဆိုတဲ့ ခန့်မှန်းချက်ကို feedforward network တစ်ခုကို ပေးပို့ပြီး class နှစ်ခု (
IsNextနဲ့NotNext) ပေါ်က softmax နဲ့ တွက်ချက်ပါတယ်။input embeddings တွေကို encoder layers အများအပြားကနေတဆင့် ဖြတ်သန်းပြီး final hidden states အချို့ကို ထုတ်ပေးပါတယ်။
ကြိုတင်လေ့ကျင့်ထားတဲ့ မော်ဒယ်ကို စာသား အမျိုးအစားခွဲခြားခြင်းအတွက် အသုံးပြုဖို့အတွက် base BERT မော်ဒယ်ရဲ့ ထိပ်မှာ sequence classification head တစ်ခုကို ထပ်ထည့်ရပါမယ်။ sequence classification head က linear layer တစ်ခုဖြစ်ပြီး final hidden states တွေကို လက်ခံကာ linear transformation တစ်ခုကို လုပ်ဆောင်ပြီး ၎င်းတို့ကို logits အဖြစ် ပြောင်းလဲပေးပါတယ်။ logits တွေနဲ့ target တွေကြားက cross-entropy loss ကို တွက်ချက်ပြီး အဖြစ်နိုင်ဆုံး label ကို ရှာဖွေပါတယ်။
စာသား အမျိုးအစားခွဲခြားခြင်းကို ကိုယ်တိုင်စမ်းကြည့်ဖို့ အဆင်သင့်ဖြစ်ပြီလား။ DistilBERT ကို ဘယ်လို fine-tune လုပ်ပြီး inference အတွက် ဘယ်လိုအသုံးပြုရမလဲဆိုတာ လေ့လာဖို့ ကျွန်တော်တို့ရဲ့ ပြည့်စုံတဲ့ text classification guide ကို ကြည့်ရှုပါ။
Token classification
Token classification ဆိုတာ sequence တစ်ခုစီရှိ token တစ်ခုစီကို label တစ်ခု သတ်မှတ်ပေးတာကို ဆိုလိုပါတယ်။ ဥပမာအားဖြင့် named entity recognition သို့မဟုတ် part-of-speech tagging တို့ ဖြစ်ပါတယ်။
BERT ကို named entity recognition (NER) လို token classification လုပ်ငန်းတာဝန်တွေအတွက် အသုံးပြုဖို့အတွက် base BERT မော်ဒယ်ရဲ့ ထိပ်မှာ token classification head တစ်ခုကို ထပ်ထည့်ရပါမယ်။ token classification head က linear layer တစ်ခုဖြစ်ပြီး final hidden states တွေကို လက်ခံကာ linear transformation တစ်ခုကို လုပ်ဆောင်ပြီး ၎င်းတို့ကို logits အဖြစ် ပြောင်းလဲပေးပါတယ်။ logits တွေနဲ့ token တစ်ခုစီကြားက cross-entropy loss ကို တွက်ချက်ပြီး အဖြစ်နိုင်ဆုံး label ကို ရှာဖွေပါတယ်။
token classification ကို ကိုယ်တိုင်စမ်းကြည့်ဖို့ အဆင်သင့်ဖြစ်ပြီလား။ DistilBERT ကို ဘယ်လို fine-tune လုပ်ပြီး inference အတွက် ဘယ်လိုအသုံးပြုရမလဲဆိုတာ လေ့လာဖို့ ကျွန်တော်တို့ရဲ့ ပြည့်စုံတဲ့ token classification guide ကို ကြည့်ရှုပါ။
မေးခွန်းဖြေခြင်း (Question answering)
မေးခွန်းဖြေခြင်းဆိုတာက ပေးထားတဲ့ context ဒါမှမဟုတ် စာပိုဒ်တစ်ခုအတွင်းမှာ မေးခွန်းရဲ့အဖြေကို ရှာဖွေတာကို ဆိုလိုပါတယ်။
BERT ကို မေးခွန်းဖြေခြင်းအတွက် အသုံးပြုဖို့အတွက် base BERT မော်ဒယ်ရဲ့ ထိပ်မှာ span classification head တစ်ခုကို ထပ်ထည့်ရပါမယ်။ ဒီ linear layer က final hidden states တွေကို လက်ခံကာ linear transformation တစ်ခုကို လုပ်ဆောင်ပြီး အဖြေနဲ့ ကိုက်ညီတဲ့ span start နဲ့ end logits တွေကို တွက်ချက်ပေးပါတယ်။ logits တွေနဲ့ label position တွေကြားက cross-entropy loss ကို တွက်ချက်ပြီး အဖြေနဲ့ ကိုက်ညီတဲ့ အဖြစ်နိုင်ဆုံး စာသားအပိုင်းကို ရှာဖွေပါတယ်။
မေးခွန်းဖြေခြင်းကို ကိုယ်တိုင်စမ်းကြည့်ဖို့ အဆင်သင့်ဖြစ်ပြီလား။ DistilBERT ကို ဘယ်လို fine-tune လုပ်ပြီး inference အတွက် ဘယ်လိုအသုံးပြုရမလဲဆိုတာ လေ့လာဖို့ ကျွန်တော်တို့ရဲ့ ပြည့်စုံတဲ့ question answering guide ကို ကြည့်ရှုပါ။
💡 BERT ကို ကြိုတင်လေ့ကျင့်ပြီးတာနဲ့ မတူညီတဲ့ လုပ်ငန်းတာဝန်တွေအတွက် အသုံးပြုဖို့ ဘယ်လောက်လွယ်ကူလဲဆိုတာ သတိထားမိလား။ သင်လိုချင်တဲ့ output ကို ရရှိဖို့အတွက် ကြိုတင်လေ့ကျင့်ထားတဲ့ မော်ဒယ်ရဲ့ ထိပ်မှာ သီးခြား head တစ်ခုကို ထပ်ထည့်ဖို့ပဲ လိုအပ်ပါတယ်။
အနှစ်ချုပ်ခြင်း (Summarization)
အနှစ်ချုပ်ခြင်းဆိုတာက ပိုရှည်တဲ့ စာသားတစ်ခုကို အဓိကအချက်အလက်တွေနဲ့ အဓိပ္ပာယ်ကို ထိန်းသိမ်းထားရင်း ပိုတိုတဲ့ပုံစံအဖြစ် ပြောင်းလဲတာကို ဆိုလိုပါတယ်။
BART နဲ့ T5 လို encoder-decoder မော်ဒယ်တွေကို summarization လုပ်ငန်းတာဝန်ရဲ့ sequence-to-sequence ပုံစံအတွက် ဒီဇိုင်းထုတ်ထားပါတယ်။ ဒီအပိုင်းမှာ BART ဘယ်လိုအလုပ်လုပ်လဲဆိုတာကို ရှင်းပြပြီး၊ ပြီးရင် T5 ကို fine-tune လုပ်တာကို သင် ကိုယ်တိုင် စမ်းကြည့်နိုင်ပါတယ်။
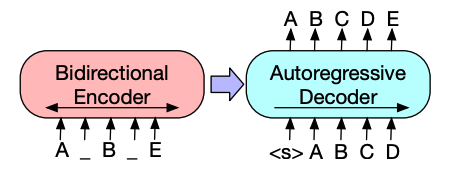
BART ရဲ့ encoder architecture က BERT နဲ့ အတော်လေး ဆင်တူပြီး စာသားရဲ့ token နဲ့ positional embedding ကို လက်ခံပါတယ်။ BART ကို input ကို ဖျက်စီးပြီး decoder နဲ့ ပြန်လည်တည်ဆောက်ခြင်းဖြင့် ကြိုတင်လေ့ကျင့်ထားပါတယ်။ သီးခြား corruption strategies တွေပါတဲ့ အခြား encoders တွေနဲ့မတူဘဲ BART က ဘယ်လို corruption အမျိုးအစားမဆို အသုံးပြုနိုင်ပါတယ်။ သို့သော် text infilling corruption strategy က အကောင်းဆုံး အလုပ်လုပ်ပါတယ်။ text infilling မှာ စာသားအပိုင်းအချို့ကို တစ်ခုတည်းသော [
mask] token နဲ့ အစားထိုးပါတယ်။ ဒါက အရေးကြီးပါတယ်၊ ဘာလို့လဲဆိုတော့ မော်ဒယ်က ဖုံးကွယ်ထားတဲ့ tokens တွေကို ခန့်မှန်းရမှာဖြစ်ပြီး၊ ပျောက်ဆုံးနေတဲ့ tokens အရေအတွက်ကို ခန့်မှန်းဖို့ မော်ဒယ်ကို သင်ကြားပေးပါတယ်။ input embeddings နဲ့ masked spans တွေကို encoder ကနေတဆင့် ဖြတ်သန်းပြီး final hidden states အချို့ကို ထုတ်ပေးပါတယ်။ ဒါပေမယ့် BERT နဲ့မတူဘဲ BART က စကားလုံးတစ်လုံးကို ခန့်မှန်းဖို့ နောက်ဆုံး feedforward network ကို ထပ်ထည့်ထားခြင်း မရှိပါဘူး။encoder ရဲ့ output ကို decoder ကို ပေးပို့ပါတယ်။ decoder က ဖုံးကွယ်ထားတဲ့ tokens တွေနဲ့ encoder ရဲ့ output ကနေ uncorrupted tokens တွေကို ခန့်မှန်းရပါမယ်။ ဒါက decoder ကို မူရင်းစာသားကို ပြန်လည်တည်ဆောက်ဖို့ အပို context တွေ ပေးပါတယ်။ decoder ကနေ ထွက်လာတဲ့ output ကို language modeling head ကို ပေးပို့ပါတယ်။ အဲဒီကနေ linear transformation တစ်ခုကို လုပ်ဆောင်ပြီး hidden states တွေကို logits အဖြစ် ပြောင်းလဲပေးပါတယ်။ logits တွေနဲ့ label (ညာဘက်သို့ ရွှေ့ထားတဲ့ token) ကြားက cross-entropy loss ကို တွက်ချက်ပါတယ်။
အနှစ်ချုပ်ခြင်းကို ကိုယ်တိုင်စမ်းကြည့်ဖို့ အဆင်သင့်ဖြစ်ပြီလား။ T5 ကို ဘယ်လို fine-tune လုပ်ပြီး inference အတွက် ဘယ်လိုအသုံးပြုရမလဲဆိုတာ လေ့လာဖို့ ကျွန်တော်တို့ရဲ့ ပြည့်စုံတဲ့ summarization guide ကို ကြည့်ရှုပါ။
စာသား ဖန်တီးခြင်းနဲ့ ပတ်သက်တဲ့ အချက်အလက်အများကြီးအတွက် text generation strategies guide ကို ကြည့်ရှုပါ။
ဘာသာပြန်ခြင်း (Translation)
ဘာသာပြန်ခြင်းဆိုတာ စာသားတစ်ခုကို အခြားဘာသာစကားတစ်ခုသို့ အဓိပ္ပာယ်ကို ထိန်းသိမ်းထားရင်း ပြောင်းလဲတာကို ဆိုလိုပါတယ်။ ဘာသာပြန်ခြင်းက sequence-to-sequence လုပ်ငန်းတာဝန်တစ်ခုရဲ့ နောက်ထပ်ဥပမာတစ်ခု ဖြစ်ပါတယ်။ ဆိုလိုတာက BART ဒါမှမဟုတ် T5 လို encoder-decoder မော်ဒယ်ကို အသုံးပြုနိုင်ပါတယ်။ ဒီအပိုင်းမှာ BART ဘယ်လိုအလုပ်လုပ်လဲဆိုတာကို ရှင်းပြပြီး၊ ပြီးရင် T5 ကို fine-tune လုပ်တာကို သင် ကိုယ်တိုင် စမ်းကြည့်နိုင်ပါတယ်။
BART ဟာ source ဘာသာစကားတစ်ခုကို target ဘာသာစကားသို့ decode လုပ်နိုင်တဲ့ input အဖြစ် map လုပ်ဖို့အတွက် သီးခြား၊ ကျပန်းစတင်ထားတဲ့ encoder တစ်ခုကို ထပ်ထည့်ခြင်းဖြင့် ဘာသာပြန်ခြင်းကို လိုက်လျောညီထွေဖြစ်အောင် လုပ်ဆောင်ပါတယ်။ ဒီ encoder အသစ်ရဲ့ embeddings တွေကို မူရင်း word embeddings အစား ကြိုတင်လေ့ကျင့်ထားတဲ့ encoder ကို ပေးပို့ပါတယ်။ source encoder ကို မော်ဒယ် output ကနေ cross-entropy loss နဲ့ source encoder, positional embeddings နဲ့ input embeddings တွေကို update လုပ်ခြင်းဖြင့် လေ့ကျင့်ပေးပါတယ်။ ဒီပထမအဆင့်မှာ မော်ဒယ် parameters တွေကို freeze ထားပြီး၊ ဒုတိယအဆင့်မှာတော့ မော်ဒယ် parameters အားလုံးကို အတူတကွ လေ့ကျင့်ပေးပါတယ်။ BART ကိုတော့ ဘာသာပြန်ခြင်းအတွက် ရည်ရွယ်ပြီး မတူညီတဲ့ ဘာသာစကားများစွာနဲ့ ကြိုတင်လေ့ကျင့်ထားတဲ့ multilingual version ဖြစ်တဲ့ mBART က ဆက်ခံခဲ့ပါတယ်။
ဘာသာပြန်ခြင်းကို ကိုယ်တိုင်စမ်းကြည့်ဖို့ အဆင်သင့်ဖြစ်ပြီလား။ T5 ကို ဘယ်လို fine-tune လုပ်ပြီး inference အတွက် ဘယ်လိုအသုံးပြုရမလဲဆိုတာ လေ့လာဖို့ ကျွန်တော်တို့ရဲ့ ပြည့်စုံတဲ့ translation guide ကို ကြည့်ရှုပါ။
ဒီ guide တစ်လျှောက်လုံးမှာ သင်တွေ့ခဲ့ရတဲ့အတိုင်း မော်ဒယ်များစွာဟာ မတူညီတဲ့ လုပ်ငန်းတာဝန်တွေကို ဖြေရှင်းနေရရင်တောင် အလားတူ ပုံစံတွေကို လိုက်နာကြပါတယ်။ ဒီလို အခြေခံပုံစံတွေကို နားလည်ထားတာက မော်ဒယ်အသစ်တွေ ဘယ်လိုအလုပ်လုပ်လဲဆိုတာကို အမြန်နားလည်ဖို့နဲ့ ရှိပြီးသားမော်ဒယ်တွေကို သင်ရဲ့လိုအပ်ချက်တွေနဲ့ လိုက်လျောညီထွေဖြစ်အောင် လုပ်ဆောင်ဖို့ ကူညီပေးနိုင်ပါတယ်။
စာသားပြင်ပရှိ Modalities များ
Transformers တွေဟာ စာသားအတွက်သာ ကန့်သတ်ထားတာ မဟုတ်ပါဘူး။ ၎င်းတို့ကို speech and audio, images နဲ့ video လို အခြား modalities တွေမှာလည်း အသုံးပြုနိုင်ပါတယ်။ ဒီသင်တန်းမှာတော့ ကျွန်တော်တို့က စာသားကို အဓိကထားမှာဖြစ်ပေမယ့် အခြား modalities တွေကို အတိုချုပ် မိတ်ဆက်ပေးပါမယ်။
စကားပြောနှင့် အသံ (Speech and audio)
Transformer မော်ဒယ်တွေက စာသား ဒါမှမဟုတ် ပုံတွေနဲ့ယှဉ်ရင် ထူးခြားတဲ့ စိန်ခေါ်မှုတွေရှိတဲ့ speech နဲ့ audio data တွေကို ဘယ်လိုကိုင်တွယ်လဲဆိုတာကို စလေ့လာရအောင်။
Whisper ဟာ 680,000 နာရီကြာ မှတ်သားထားတဲ့ audio data တွေနဲ့ ကြိုတင်လေ့ကျင့်ထားတဲ့ encoder-decoder (sequence-to-sequence) transformer တစ်ခုဖြစ်ပါတယ်။ ဒီလိုများပြားတဲ့ pretraining data ပမာဏက English နဲ့ အခြားဘာသာစကားများစွာရှိ audio လုပ်ငန်းတာဝန်တွေမှာ zero-shot performance ကို ရရှိစေပါတယ်။ decoder က Whisper ကို encoders တွေ သင်ယူထားတဲ့ speech representations တွေကို စာသားလို အသုံးဝင်တဲ့ outputs တွေအဖြစ် ထပ်မံ fine-tune လုပ်စရာမလိုဘဲ map လုပ်နိုင်စေပါတယ်။ Whisper က box ထဲကနေ တန်းအလုပ်လုပ်နိုင်ပါတယ်။

ပုံကြမ်းကို Whisper paper မှ ရယူထားပါသည်။
ဒီမော်ဒယ်မှာ အဓိက အစိတ်အပိုင်းနှစ်ခု ပါဝင်ပါတယ်။
Encoder: input audio ကို လုပ်ဆောင်ပေးပါတယ်။ ကနဦး audio ကို log-Mel spectrogram အဖြစ် ပြောင်းလဲပါတယ်။ ဒီ spectrogram ကို Transformer encoder network ကနေတဆင့် ဖြတ်သန်းပါတယ်။
Decoder: encoded audio representation ကို ယူပြီး သက်ဆိုင်ရာ text tokens တွေကို autoregressively ခန့်မှန်းပါတယ်။ ဒါဟာ အရင် tokens တွေနဲ့ encoder output ကို ပေးထားပြီး နောက် text token ကို ခန့်မှန်းဖို့ လေ့ကျင့်ထားတဲ့ standard Transformer decoder တစ်ခုပါ။ transcription, translation ဒါမှမဟုတ် language identification လို သီးခြားလုပ်ငန်းတာဝန်တွေဆီ မော်ဒယ်ကို ဦးတည်စေဖို့ decoder input ရဲ့ အစမှာ အထူး tokens တွေကို အသုံးပြုပါတယ်။
Whisper ကို ဝက်ဘ်မှ စုဆောင်းထားတဲ့ 680,000 နာရီကြာ မှတ်သားထားတဲ့ audio data များစွာနဲ့ မတူညီတဲ့ dataset တစ်ခုပေါ်မှာ ကြိုတင်လေ့ကျင့်ထားပါတယ်။ ဒီလို ကြီးမားတဲ့၊ weakly supervised pretraining ဟာ မတူညီတဲ့ ဘာသာစကားတွေ၊ လေယူလေသိမ်းတွေနဲ့ လုပ်ငန်းတာဝန်တွေမှာ task-specific finetuning မပါဘဲ အစွမ်းထက်တဲ့ zero-shot performance ကို ရရှိစေတဲ့ အဓိကအချက်ပါ။
Whisper ကို ကြိုတင်လေ့ကျင့်ပြီးပြီဆိုတော့ zero-shot inference အတွက် တိုက်ရိုက်အသုံးပြုနိုင်သလို automatic speech recognition ဒါမှမဟုတ် speech translation လို သီးခြားလုပ်ငန်းတာဝန်တွေမှာ စွမ်းဆောင်ရည်ပိုမိုကောင်းမွန်စေဖို့ သင်ရဲ့ data ပေါ်မှာ fine-tune လုပ်နိုင်ပါပြီ။
Whisper ရဲ့ အဓိက ဆန်းသစ်တီထွင်မှုကတော့ အင်တာနက်ကနေ ရရှိတဲ့ မတူညီတဲ့၊ weakly supervised audio data တွေကို အစဉ်အလာမရှိတဲ့ ပမာဏနဲ့ လေ့ကျင့်ထားခြင်း ဖြစ်ပါတယ်။ ဒါက မတူညီတဲ့ ဘာသာစကားတွေ၊ လေယူလေသိမ်းတွေနဲ့ လုပ်ငန်းတာဝန်တွေဆီကို task-specific finetuning မပါဘဲ ထူးထူးခြားခြား ကောင်းမွန်စွာ ယေဘုယျလုပ်ဆောင်နိုင်စေပါတယ်။
အလိုအလျောက် စကားပြော မှတ်သားခြင်း (Automatic speech recognition)
ကြိုတင်လေ့ကျင့်ထားတဲ့ မော်ဒယ်ကို automatic speech recognition အတွက် အသုံးပြုဖို့အတွက် ၎င်းရဲ့ ပြည့်စုံတဲ့ encoder-decoder ဖွဲ့စည်းပုံကို အသုံးချရပါမယ်။ encoder က audio input ကို လုပ်ဆောင်ပြီး decoder ကတော့ text token တစ်ခုချင်းစီကို autoregressively ထုတ်ပေးပါတယ်။ fine-tuning လုပ်တဲ့အခါ မော်ဒယ်ကို audio input ပေါ် အခြေခံပြီး မှန်ကန်တဲ့ text tokens တွေကို ခန့်မှန်းဖို့အတွက် standard sequence-to-sequence loss (cross-entropy ကဲ့သို့) ကို အသုံးပြုပြီး လေ့ကျင့်လေ့ရှိပါတယ်။
Fine-tuned model ကို inference အတွက် အသုံးပြုဖို့ အလွယ်ဆုံးနည်းလမ်းကတော့ pipeline အတွင်းမှာပဲ ဖြစ်ပါတယ်။
from transformers import pipeline
transcriber = pipeline(
task="automatic-speech-recognition", model="openai/whisper-base.en"
)
transcriber("https://huggingface.co/datasets/Narsil/asr_dummy/resolve/main/mlk.flac")
# Output: {'text': ' I have a dream that one day this nation will rise up and live out the true meaning of its creed.'}Automatic speech recognition ကို ကိုယ်တိုင်စမ်းကြည့်ဖို့ အဆင်သင့်ဖြစ်ပြီလား။ Whisper ကို ဘယ်လို fine-tune လုပ်ပြီး inference အတွက် ဘယ်လိုအသုံးပြုရမလဲဆိုတာ လေ့လာဖို့ ကျွန်တော်တို့ရဲ့ ပြည့်စုံတဲ့ automatic speech recognition guide ကို ကြည့်ရှုပါ။
Computer vision
အခုတော့ computer vision လုပ်ငန်းတာဝန်တွေဆီ ဆက်သွားရအောင်။ ဒါတွေကတော့ ပုံတွေ ဒါမှမဟုတ် ဗီဒီယိုတွေကနေ မြင်နိုင်တဲ့ အချက်အလက်တွေကို နားလည်ပြီး အနက်ပြန်ခြင်းနဲ့ သက်ဆိုင်ပါတယ်။
computer vision လုပ်ငန်းတာဝန်တွေကို ချဉ်းကပ်ဖို့ နည်းလမ်းနှစ်မျိုးရှိပါတယ်။
- ပုံတစ်ပုံကို patches အစုအဝေးအဖြစ် ခွဲခြမ်းပြီး Transformer နဲ့ တစ်ပြိုင်နက်တည်း လုပ်ဆောင်ခြင်း။
- convolutional layers တွေကို အသုံးပြုပေမယ့် ခေတ်မီ network designs တွေကို လက်ခံထားတဲ့ ConvNeXT လို ခေတ်မီ CNN တစ်ခုကို အသုံးပြုခြင်း။
တတိယချဉ်းကပ်ပုံကတော့ Transformers တွေကို convolutions တွေနဲ့ ရောစပ်ခြင်း (ဥပမာ- Convolutional Vision Transformer သို့မဟုတ် LeViT) ဖြစ်ပါတယ်။ ဒါတွေကိုတော့ ကျွန်တော်တို့ ဆွေးနွေးမှာ မဟုတ်ပါဘူး၊ ဘာလို့လဲဆိုတော့ ၎င်းတို့ဟာ ဒီနေရာမှာ စစ်ဆေးထားတဲ့ ချဉ်းကပ်ပုံနှစ်ခုကို ပေါင်းစပ်ထားတာပဲ ဖြစ်လို့ပါ။
ViT နဲ့ ConvNeXT တို့နှစ်ခုလုံးကို image classification အတွက် အများအားဖြင့် အသုံးပြုပေမယ့် object detection, segmentation နဲ့ depth estimation လို အခြား vision လုပ်ငန်းတာဝန်တွေအတွက်တော့ DETR, Mask2Former နဲ့ GLPN တို့ကို အသီးသီး ကြည့်ရှုသွားပါမယ်။ ဒီမော်ဒယ်တွေကတော့ အဲဒီလုပ်ငန်းတာဝန်တွေအတွက် ပိုမိုသင့်လျော်ပါတယ်။
ရုပ်ပုံ အမျိုးအစားခွဲခြားခြင်း (Image classification)
ရုပ်ပုံ အမျိုးအစားခွဲခြားခြင်းက အခြေခံကျတဲ့ computer vision လုပ်ငန်းတာဝန်တွေထဲက တစ်ခုပါ။ မတူညီတဲ့ မော်ဒယ် architecture တွေက ဒီပြဿနာကို ဘယ်လိုချဉ်းကပ်လဲဆိုတာ ကြည့်ရအောင်။
ViT နဲ့ ConvNeXT တို့နှစ်ခုလုံးကို image classification အတွက် အသုံးပြုနိုင်ပါတယ်။ အဓိက ကွာခြားချက်ကတော့ ViT က attention mechanism ကို အသုံးပြုပြီး ConvNeXT က convolutions တွေကို အသုံးပြုတာပါပဲ။
ViT ဟာ convolutions တွေကို Transformer architecture သန့်သန့်နဲ့ အစားထိုးထားပါတယ်။ မူရင်း Transformer နဲ့ ရင်းနှီးပြီးသားဆိုရင် ViT ကို နားလည်ဖို့ အများကြီး ကျန်တော့မှာ မဟုတ်ပါဘူး။

ViT က မိတ်ဆက်ခဲ့တဲ့ အဓိကပြောင်းလဲမှုက ပုံတွေကို Transformer ကို ဘယ်လို ထည့်သွင်းလဲဆိုတာပါပဲ။
ပုံတစ်ပုံကို လေးထောင့်မကျအောင် မထပ်တဲ့ patches တွေအဖြစ် ခွဲခြမ်းပြီး၊ patch တစ်ခုစီကို vector ဒါမှမဟုတ် patch embedding အဖြစ် ပြောင်းလဲပါတယ်။ patch embeddings တွေကို convolutional 2D layer ကနေ ထုတ်ပေးပြီး မှန်ကန်တဲ့ input dimensions (base Transformer အတွက် patch embedding တစ်ခုစီအတွက် 768 values) ကို ဖန်တီးပေးပါတယ်။ 224x224 pixel ပုံတစ်ပုံရှိရင် 196 16x16 ပုံ patches တွေအဖြစ် ခွဲခြမ်းနိုင်ပါတယ်။ စာသားကို စကားလုံးတွေအဖြစ် tokenize လုပ်သလိုမျိုး ပုံတစ်ပုံကိုလည်း patches sequence အဖြစ် “tokenize” လုပ်ပါတယ်။
learnable embedding - အထူး
[CLS]token - ကို BERT လိုပဲ patch embeddings ရဲ့ အစမှာ ထပ်ထည့်ပါတယ်။[CLS]token ရဲ့ final hidden state ကို တွဲထားတဲ့ classification head ရဲ့ input အဖြစ် အသုံးပြုပြီး အခြား outputs တွေကိုတော့ လျစ်လျူရှုပါတယ်။ ဒီ token က မော်ဒယ်ကို ပုံတစ်ပုံရဲ့ representation ကို ဘယ်လို encode လုပ်ရမယ်ဆိုတာ သင်ယူဖို့ ကူညီပေးပါတယ်။patch နဲ့ learnable embeddings တွေမှာ ထပ်ထည့်ရမယ့် နောက်ဆုံးအရာကတော့ position embeddings တွေ ဖြစ်ပါတယ်။ ဘာလို့လဲဆိုတော့ မော်ဒယ်က image patches တွေရဲ့ အစီအစဉ်ကို မသိလို့ပါပဲ။ position embeddings တွေကလည်း learnable ဖြစ်ပြီး patch embeddings တွေနဲ့ အရွယ်အစားတူညီပါတယ်။ နောက်ဆုံးတော့ embeddings အားလုံးကို Transformer encoder ကို ပေးပို့ပါတယ်။
output ကို၊ အထူးသဖြင့်
[CLS]token ပါတဲ့ output ကိုပဲ multilayer perceptron head (MLP) ကို ပေးပို့ပါတယ်။ ViT ရဲ့ pretraining ရည်ရွယ်ချက်ကတော့ classification ပါပဲ။ အခြား classification heads တွေလိုပဲ MLP head က output ကို class labels တွေပေါ်က logits အဖြစ် ပြောင်းလဲပြီး အဖြစ်နိုင်ဆုံး class ကို ရှာဖွေဖို့ cross-entropy loss ကို တွက်ချက်ပါတယ်။
ရုပ်ပုံ အမျိုးအစားခွဲခြားခြင်းကို ကိုယ်တိုင်စမ်းကြည့်ဖို့ အဆင်သင့်ဖြစ်ပြီလား။ ViT ကို ဘယ်လို fine-tune လုပ်ပြီး inference အတွက် ဘယ်လိုအသုံးပြုရမလဲဆိုတာ လေ့လာဖို့ ကျွန်တော်တို့ရဲ့ ပြည့်စုံတဲ့ image classification guide ကို ကြည့်ရှုပါ။
ViT နဲ့ BERT ကြားက တူညီမှုကို သတိထားမိပါလိမ့်မယ်။ နှစ်ခုလုံးဟာ အလုံးစုံ ကိုယ်စားပြုမှု (overall representation) ကို ဖမ်းယူဖို့ အထူး token (
[CLS]) ကို အသုံးပြုကြပြီး၊ နှစ်ခုလုံးက ၎င်းတို့ရဲ့ embeddings တွေမှာ position information ကို ထပ်ထည့်ကြကာ၊ နှစ်ခုလုံးက tokens/patches တွေရဲ့ sequence ကို လုပ်ဆောင်ဖို့ Transformer encoder ကို အသုံးပြုကြပါတယ်။
ဝေါဟာရ ရှင်းလင်းချက် (Glossary)
- Natural Language Processing (NLP): ကွန်ပျူတာတွေ လူသားဘာသာစကားကို နားလည်၊ အဓိပ္ပာယ်ဖော်ပြီး၊ ဖန်တီးနိုင်အောင် လုပ်ဆောင်ပေးတဲ့ Artificial Intelligence (AI) ရဲ့ နယ်ပယ်ခွဲတစ်ခု ဖြစ်ပါတယ်။ ဥပမာအားဖြင့် စာသားခွဲခြမ်းစိတ်ဖြာခြင်း၊ ဘာသာပြန်ခြင်း စသည်တို့ ပါဝင်ပါတယ်။
- Large Language Models (LLMs): လူသားဘာသာစကားကို နားလည်ပြီး ထုတ်လုပ်ပေးနိုင်တဲ့ အလွန်ကြီးမားတဲ့ Artificial Intelligence (AI) မော်ဒယ်တွေ ဖြစ်ပါတယ်။ ၎င်းတို့ဟာ ဒေတာအမြောက်အမြားနဲ့ သင်ကြားလေ့ကျင့်ထားပြီး စာရေးတာ၊ မေးခွန်းဖြေတာ စတဲ့ ဘာသာစကားဆိုင်ရာ လုပ်ငန်းမျိုးစုံကို လုပ်ဆောင်နိုင်ပါတယ်။
- Transformer Models: Natural Language Processing (NLP) မှာ အောင်မြင်မှုများစွာရရှိခဲ့တဲ့ deep learning architecture တစ်မျိုးပါ။ ၎င်းတို့ဟာ စာသားတွေထဲက စကားလုံးတွေရဲ့ ဆက်နွယ်မှုတွေကို “attention mechanism” သုံးပြီး နားလည်အောင် သင်ကြားပေးပါတယ်။
- Encoder: Transformer Architecture ရဲ့ အစိတ်အပိုင်းတစ်ခုဖြစ်ပြီး input data (ဥပမာ- စာသား) ကို နားလည်ပြီး ကိုယ်စားပြုတဲ့ အချက်အလက် (representation) အဖြစ် ပြောင်းလဲပေးပါတယ်။
- Decoder: Transformer Architecture ရဲ့ အစိတ်အပိုင်းတစ်ခုဖြစ်ပြီး encoder ကနေ ရရှိတဲ့ အချက်အလက် (representation) ကို အသုံးပြုပြီး output data (ဥပမာ- ဘာသာပြန်ထားတဲ့ စာသား) ကို ထုတ်ပေးပါတယ်။
- Encoder-Decoder Structure: Encoder နှင့် Decoder နှစ်ခုစလုံး ပါဝင်သော Transformer architecture တစ်မျိုးဖြစ်ပြီး ဘာသာပြန်ခြင်းကဲ့သို့သော input sequence မှ output sequence တစ်ခုသို့ ပြောင်းလဲခြင်း လုပ်ငန်းများအတွက် အသုံးပြုပါတယ်။
- Architecture: Machine Learning မော်ဒယ်တစ်ခု၏ ဒီဇိုင်း သို့မဟုတ် ဖွဲ့စည်းတည်ဆောက်ပုံ။
- Input Data: မော်ဒယ်တစ်ခုကို ပေးသွင်းသည့် အချက်အလက်များ။
- Output: မော်ဒယ်တစ်ခုမှ ထုတ်ပေးသော ရလဒ်များ။
- Predictions: မော်ဒယ်တစ်ခုမှ ခန့်မှန်းထားသော ရလဒ်များ။
- Audio Classification: အသံနမူနာများကို ကြိုတင်သတ်မှတ်ထားသော အမျိုးအစားများအဖြစ် ခွဲခြားခြင်း။
- Automatic Speech Recognition (ASR): ပြောဆိုသော ဘာသာစကားကို စာသားအဖြစ် အလိုအလျောက် ပြောင်းလဲပေးသည့် နည်းပညာ။
- Image Classification: ရုပ်ပုံများကို ကြိုတင်သတ်မှတ်ထားသော အမျိုးအစားများအဖြစ် ခွဲခြားခြင်း။
- Object Detection: ပုံတစ်ပုံအတွင်းရှိ အရာဝတ္ထုများကို ရှာဖွေဖော်ထုတ်ပြီး ၎င်းတို့၏ တည်နေရာကို သတ်မှတ်ခြင်း။
- Image Segmentation: ပုံတစ်ပုံအတွင်းရှိ pixel များကို သီးခြားအရာဝတ္ထုများ သို့မဟုတ် ဒေသများအဖြစ် ခွဲခြားခြင်း။
- Depth Estimation: ပုံတစ်ပုံအတွင်းရှိ အရာဝတ္ထုများ၏ ကင်မရာနှင့် ဝေးကွာသော အကွာအဝေးကို ခန့်မှန်းခြင်း။
- Text Classification: စာသားမှတ်တမ်းများကို ကြိုတင်သတ်မှတ်ထားသော အမျိုးအစားများအဖြစ် ခွဲခြားခြင်း။
- Token Classification: စာသား sequence တစ်ခုရှိ token တစ်ခုစီကို label တစ်ခု သတ်မှတ်ပေးခြင်း။
- Question Answering: ပေးထားသော စာသားတစ်ခုအတွင်းမှ မေးခွန်းတစ်ခု၏ အဖြေကို ရှာဖွေခြင်း။
- Text Generation: AI မော်ဒယ်များကို အသုံးပြု၍ လူသားကဲ့သို့သော စာသားအသစ်များ ဖန်တီးခြင်း။
- Summarization: ရှည်လျားသော စာသားတစ်ခုကို အဓိကအချက်အလက်များနှင့် အဓိပ္ပာယ်ကို မပျက်စီးစေဘဲ တိုတောင်းအောင်ပြုလုပ်ခြင်း။
- Translation: စာသားကို ဘာသာစကားတစ်ခုမှ အခြားဘာသာစကားတစ်ခုသို့ အဓိပ္ပာယ်မပျက် ဘာသာပြန်ခြင်း။
- Attention Mechanism: Transformer မော်ဒယ်များတွင် အသုံးပြုသော နည်းစနစ်တစ်ခုဖြစ်ပြီး input sequence ၏ မတူညီသော အစိတ်အပိုင်းများအပေါ် အာရုံစိုက်ပြီး ဆက်နွယ်မှုများကို သင်ယူစေသည်။
- Language Models: လူသားဘာသာစကားကို နားလည်ပြီး ထုတ်ပေးနိုင်ရန် ဒီဇိုင်းထုတ်ထားသော Machine Learning မော်ဒယ်များ။
- Tokens: စာသားတစ်ခု၏ အသေးငယ်ဆုံးသော အစိတ်အပိုင်းများ (ဥပမာ- စကားလုံးများ၊ စာလုံးများ)။
- Machine Translation: ဘာသာစကားတစ်ခုကနေ အခြားဘာသာစကားတစ်ခုကို စာသားတွေ ဒါမှမဟုတ် စကားပြောတွေကို အလိုအလျောက် ဘာသာပြန်ဆိုခြင်း။
- Bidirectional Context: စာသားတစ်ခုကို စကားလုံးတစ်လုံးရဲ့ အရှေ့နဲ့ အနောက် နှစ်ဖက်လုံးကနေ ကြည့်ရှုပြီး နားလည်ခြင်း။
- Masked Language Modeling (MLM): input tokens အချို့ကို ဖုံးကွယ်ထားပြီး မော်ဒယ်ကို ၎င်းတို့ကို ခန့်မှန်းစေရန် လေ့ကျင့်သော pretraining နည်းလမ်း။
- Causal Language Modeling (CLM): input sequence ၏ အရင် tokens များပေါ် အခြေခံပြီး နောက် token ကို ခန့်မှန်းစေရန် မော်ဒယ်ကို လေ့ကျင့်သော pretraining နည်းလမ်း။
- Named Entity Recognition (NER): စာသားထဲက လူအမည်၊ နေရာအမည်၊ အဖွဲ့အစည်းအမည် စတဲ့ သီးခြားအမည်တွေကို ရှာဖွေဖော်ထုတ်ခြင်း။
- Part-of-Speech (POS) Tagging: စာကြောင်းတစ်ခုရှိ စကားလုံးတစ်လုံးစီကို သက်ဆိုင်ရာ သဒ္ဒါအမျိုးအစား (ဥပမာ- နာမ်၊ ကြိယာ၊ နာမဝိသေသန) ကို သတ်မှတ်ပေးခြင်း။
- Self-supervised: ဒေတာများကို လူသားများက လက်ဖြင့် မှတ်သား (annotate) ရန် မလိုအပ်ဘဲ ဒေတာကိုယ်တိုင်ကနေ သင်ယူနိုင်သော လေ့ကျင့်မှုနည်းလမ်း။
- Human Annotations: လူသားများက ဒေတာများကို လက်ဖြင့် မှတ်သားခြင်း သို့မဟုတ် အညွှန်းတပ်ခြင်း။
- Transfer Learning: ကြိုတင်လေ့ကျင့်ထားပြီးသား မော်ဒယ် (pre-trained model) တစ်ခုကို အခြားလုပ်ငန်းတာဝန်အသစ်တစ်ခုအတွက် ပြန်လည်အသုံးပြုခြင်း။
- Byte Pair Encoding (BPE): စာသားများကို tokens အဖြစ် ပြောင်းလဲရန် အသုံးပြုသော tokenization နည်းလမ်းတစ်ခု။
- Token Embedding: tokens များကို vector ပုံစံဖြင့် ကိုယ်စားပြုခြင်း။
- Positional Encodings: sequence တစ်ခုရှိ token တစ်ခုချင်းစီ၏ တည်နေရာ အချက်အလက်များကို ထပ်ထည့်ပေးခြင်း။
- Decoder Blocks: Transformer decoder ၏ အစိတ်အပိုင်းများ။
- Masked Self-Attention: Transformer decoder တွင် အသုံးပြုသော attention mechanism တစ်မျိုးဖြစ်ပြီး မော်ဒယ်ကို future tokens များသို့ ကြည့်ရှုခွင့်မပြုပါ။
- Attention Mask: attention mechanism တွင် အချို့ tokens များကို လျစ်လျူရှုရန် သို့မဟုတ် ၎င်းတို့၏ score ကို သုညသတ်မှတ်ရန် အသုံးပြုသော mask တစ်ခု။
- Language Modeling Head: မော်ဒယ်၏ hidden states များကို logits အဖြစ် ပြောင်းလဲပေးသည့် layer။
- Linear Transformation: သင်္ချာဆိုင်ရာ အပြောင်းအလဲတစ်ခုဖြစ်ပြီး input vector ကို output vector အဖြစ် ပြောင်းလဲပေးသည်။
- Logits: မော်ဒယ်၏ output မတိုင်မီ raw, unnormalized prediction scores များ။
- Cross-Entropy Loss: classification လုပ်ငန်းတာဝန်များတွင် အသုံးပြုသော loss function တစ်ခုဖြစ်ပြီး မော်ဒယ်၏ ခန့်မှန်းချက်များနှင့် အမှန်တကယ် labels များကြား ခြားနားချက်ကို တိုင်းတာသည်။
- WordPiece: စာသားများကို tokens အဖြစ် ပြောင်းလဲရန် BERT မှ အသုံးပြုသော tokenization နည်းလမ်းတစ်ခု။
[SEP]Token: စာကြောင်းများကြား ခွဲခြားရန် အသုံးပြုသော အထူး token ။[CLS]Token: စာကြောင်းတစ်ခု၏ အစတွင် ထည့်သွင်းပြီး စာကြောင်းတစ်ခုလုံး၏ ကိုယ်စားပြုမှုကို ဖမ်းယူရန် အသုံးပြုသော အထူး token ။- Segment Embedding: token တစ်ခုက စာကြောင်းတစ်စုံမှာ ပထမ သို့မဟုတ် ဒုတိယစာကြောင်းမှာ ပါဝင်သည်ကို ဖော်ပြသော embedding။
- Feedforward Network: neural network တစ်ခု၏ အခြေခံ layer တစ်ခု။
- Softmax: multi-class classification တွင် ဖြစ်နိုင်ခြေများကို တွက်ချက်ရန် အသုံးပြုသော activation function တစ်ခု။
- Next-Sentence Prediction: မော်ဒယ်ကို စာကြောင်း B က စာကြောင်း A နောက်က လိုက်သလားဆိုတာ ခန့်မှန်းစေရန် လေ့ကျင့်သော pretraining လုပ်ငန်းတာဝန်။
- Sequence Classification Head: sequence classification လုပ်ငန်းတာဝန်များအတွက် မော်ဒယ်၏ output တွင် ထပ်ထည့်သော linear layer။
- Token Classification Head: token classification လုပ်ငန်းတာဝန်များအတွက် မော်ဒယ်၏ output တွင် ထပ်ထည့်သော linear layer။
- Span Classification Head: question answering လုပ်ငန်းတာဝန်များအတွက် မော်ဒယ်၏ output တွင် ထပ်ထည့်သော linear layer ဖြစ်ပြီး အဖြေ၏ start/end positions များကို ခန့်မှန်းသည်။
- Corrupting: မော်ဒယ်ကို လေ့ကျင့်ရန်အတွက် input data တွင် ရည်ရွယ်ချက်ရှိရှိ အပြောင်းအလဲများ ပြုလုပ်ခြင်း။
- Text Infilling: စာသားအပိုင်းအချို့ကို ဖုံးကွယ်ထားပြီး မော်ဒယ်ကို ၎င်းတို့ကို ခန့်မှန်းစေရန် လေ့ကျင့်သော corruption strategy။
- Log-Mel Spectrogram: အသံအချက်ပြမှုတစ်ခု၏ ကြိမ်နှုန်းနှင့် အချိန်အလိုက် ပြောင်းလဲမှုများကို ပုံရိပ်အဖြစ် ကိုယ်စားပြုခြင်း။
- Autoregressively: အရင်က ခန့်မှန်းထားတဲ့ outputs တွေပေါ် အခြေခံပြီး နောက် output ကို ခန့်မှန်းတဲ့ လုပ်ငန်းစဉ်။
- Zero-shot Performance: မော်ဒယ်တစ်ခုကို သီးခြားလုပ်ငန်းအတွက် လေ့ကျင့်ထားခြင်းမရှိဘဲ လုပ်ငန်းအသစ်တစ်ခုကို လုပ်ဆောင်နိုင်စွမ်း။
- Weakly Supervised Pretraining: လူသားမှတ်သားမှု (human annotations) နည်းပါးသော သို့မဟုတ် မရှိသော ဒေတာများကို အသုံးပြု၍ မော်ဒယ်ကို ကြိုတင်လေ့ကျင့်ခြင်း။
- Pipeline: Hugging Face Transformers library တွင် ပါဝင်သော လုပ်ဆောင်ချက်တစ်ခုဖြစ်ပြီး မော်ဒယ်များကို သီးခြားလုပ်ငန်းတာဝန်များအတွက် အသုံးပြုရလွယ်ကူစေရန် ကူညီပေးသည်။
- Patches: ပုံတစ်ပုံကို ခွဲခြမ်းထားသော သေးငယ်သော အစိတ်အပိုင်းများ။
- Convolutional 2D Layer: ပုံများကို လုပ်ဆောင်ရန် အသုံးပြုသော neural network layer တစ်မျိုး။
- Multilayer Perceptron (MLP) Head: classification လုပ်ငန်းတာဝန်များအတွက် အသုံးပြုသော feedforward neural network layer။
- Convolutional Neural Network (CNN): ပုံများနှင့် ဗီဒီယိုများကို လုပ်ဆောင်ရန် အထူးဒီဇိုင်းထုတ်ထားသော neural network အမျိုးအစားတစ်ခု။
- Convolutional Layers: CNN ၏ အဓိက အစိတ်အပိုင်းများဖြစ်ပြီး ပုံများမှ features များကို ထုတ်ယူရန် အသုံးပြုသည်။