course documentation
လက်တွေ့ လေ့ကျင့်ခန်း- GRPO ဖြင့် မော်ဒယ်တစ်ခုကို Fine-tune လုပ်ခြင်း
လက်တွေ့ လေ့ကျင့်ခန်း- GRPO ဖြင့် မော်ဒယ်တစ်ခုကို Fine-tune လုပ်ခြင်း
သီအိုရီကို သင်သိပြီဆိုတော့ လက်တွေ့အကောင်အထည်ဖော်ကြည့်ရအောင်! ဒီလေ့ကျင့်ခန်းမှာ၊ သင်ဟာ GRPO ဖြင့် model တစ်ခုကို fine-tune လုပ်ရပါလိမ့်မယ်။
ဒီလေ့ကျင့်ခန်းကို LLM fine-tuning ကျွမ်းကျင်သူ @mlabonne က ရေးသားခဲ့တာပါ။
Dependencies များကို Install လုပ်ခြင်း
ပထမဆုံး၊ ဒီလေ့ကျင့်ခန်းအတွက် dependencies တွေကို install လုပ်ကြရအောင်။
!pip install -qqq datasets==3.2.0 transformers==4.47.1 trl==0.14.0 peft==0.14.0 accelerate==1.2.1 bitsandbytes==0.45.2 wandb==0.19.7 --progress-bar off !pip install -qqq flash-attn --no-build-isolation --progress-bar off
အခု လိုအပ်တဲ့ libraries တွေကို import လုပ်ပါမယ်။
import torch
from datasets import load_dataset
from peft import LoraConfig, get_peft_model
from transformers import AutoModelForCausalLM, AutoTokenizer
from trl import GRPOConfig, GRPOTrainerWeights & Biases သို့ Import လုပ်ပြီး Login ဝင်ခြင်း
Weights & Biases ဟာ သင်၏ experiments များကို log လုပ်ရန်နှင့် monitor လုပ်ရန် ကိရိယာတစ်ခု ဖြစ်ပါတယ်။ ကျွန်တော်တို့က fine-tuning လုပ်ငန်းစဉ်ကို log လုပ်ဖို့ အဲဒါကို အသုံးပြုပါမယ်။
import wandb
wandb.login()Weights & Biases သို့ login ဝင်စရာမလိုဘဲ ဒီလေ့ကျင့်ခန်းကို လုပ်ဆောင်နိုင်ပါတယ်၊ ဒါပေမယ့် သင်၏ experiments တွေကို ခြေရာခံပြီး ရလဒ်တွေကို နားလည်နိုင်ဖို့ Login ဝင်ဖို့ အကြံပြုထားပါတယ်။
Dataset ကို Load လုပ်ခြင်း
အခု dataset ကို load လုပ်ကြရအောင်။ ဒီအခြေအနေမှာ၊ ကျွန်တော်တို့ဟာ တိုတောင်းသော ဇာတ်လမ်းတိုများပါဝင်တဲ့ mlabonne/smoltldr dataset ကို အသုံးပြုပါမယ်။
dataset = load_dataset("mlabonne/smoltldr")
print(dataset)Model ကို Load လုပ်ခြင်း
အခု model ကို load လုပ်ကြရအောင်။
ဒီလေ့ကျင့်ခန်းအတွက်၊ ကျွန်တော်တို့ SmolLM2-135M model ကို အသုံးပြုပါမယ်။
ဒါက limited hardware တွေမှာ run နိုင်တဲ့ 135M parameter သေးငယ်တဲ့ model တစ်ခုပါ။ ဒါက model ကို သင်ယူဖို့အတွက် အကောင်းဆုံးဖြစ်စေပေမယ့်၊ အပြင်မှာရှိတဲ့ အစွမ်းအထက်ဆုံး model တော့ မဟုတ်ပါဘူး။ သင်ပိုမိုအားကောင်းတဲ့ hardware ကို အသုံးပြုနိုင်တယ်ဆိုရင်၊ SmolLM2-1.7B လိုမျိုး ပိုကြီးတဲ့ model တစ်ခုကို fine-tune လုပ်ကြည့်နိုင်ပါတယ်။
model_id = "HuggingFaceTB/SmolLM-135M-Instruct"
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype="auto",
device_map="auto",
attn_implementation="flash_attention_2",
)
tokenizer = AutoTokenizer.from_pretrained(model_id)LoRA ကို Load လုပ်ခြင်း
အခု LoRA configuration ကို load လုပ်ကြရအောင်။ trainable parameters အရေအတွက်ကို လျှော့ချဖို့အတွက် LoRA ရဲ့ အားသာချက်ကို ယူပါမယ်၊ ဒါ့အပြင် model ကို fine-tune လုပ်ဖို့ လိုအပ်တဲ့ memory footprint ကိုလည်း လျှော့ချပါမယ်။
သင် LoRA နဲ့ မရင်းနှီးသေးဘူးဆိုရင်၊ Chapter 11 မှာ ဒါအကြောင်း ပိုပြီးဖတ်ရှုနိုင်ပါတယ်။
# LoRA ကို Load လုပ်ပါ
lora_config = LoraConfig(
task_type="CAUSAL_LM",
r=16,
lora_alpha=32,
target_modules="all-linear",
)
model = get_peft_model(model, lora_config)
print(model.print_trainable_parameters())Total trainable parameters: 135M
Reward Function ကို သတ်မှတ်ခြင်း
ယခင်အပိုင်းမှာ ဖော်ပြခဲ့တဲ့အတိုင်း၊ GRPO က model ကို တိုးတက်အောင် လုပ်ဆောင်ဖို့ မည်သည့် reward function ကိုမဆို အသုံးပြုနိုင်ပါတယ်။ ဒီအခြေအနေမှာ၊ model ကို tokens ၅၀ ရှည်လျားတဲ့ text တွေ ထုတ်လုပ်ဖို့ တိုက်တွန်းတဲ့ ရိုးရှင်းတဲ့ reward function တစ်ခုကို ကျွန်တော်တို့ အသုံးပြုပါမယ်။
# Reward function
ideal_length = 50
def reward_len(completions, **kwargs):
return [-abs(ideal_length - len(completion)) for completion in completions]Training Arguments များကို သတ်မှတ်ခြင်း
အခု training arguments တွေကို သတ်မှတ်ကြရအောင်။ transformers style ပုံစံအတိုင်း training arguments တွေကို သတ်မှတ်ဖို့ GRPOConfig class ကို ကျွန်တော်တို့ အသုံးပြုပါမယ်။
ဒါက သင် training arguments တွေကို ပထမဆုံးအကြိမ် သတ်မှတ်တာဖြစ်တယ်ဆိုရင်၊ အသေးစိတ်အချက်အလက်တွေအတွက် TrainingArguments class ကို ကြည့်နိုင်ပါတယ်။ ဒါမှမဟုတ် အသေးစိတ်နိဒါန်းအတွက် Chapter 2 ကို ကြည့်နိုင်ပါတယ်။
# Training arguments
training_args = GRPOConfig(
output_dir="GRPO",
learning_rate=2e-5,
per_device_train_batch_size=8,
gradient_accumulation_steps=2,
max_prompt_length=512,
max_completion_length=96,
num_generations=8,
optim="adamw_8bit",
num_train_epochs=1,
bf16=True,
report_to=["wandb"],
remove_unused_columns=False,
logging_steps=1,
)အခု model၊ dataset နဲ့ training arguments တွေနဲ့ trainer ကို initialize လုပ်ပြီး training စတင်နိုင်ပါပြီ။
# Trainer
trainer = GRPOTrainer(
model=model,
reward_funcs=[reward_len],
args=training_args,
train_dataset=dataset["train"],
)
# Train model
wandb.init(project="GRPO")
trainer.train()Training က Google Colab ဒါမှမဟုတ် Hugging Face Spaces မှာ ရရှိနိုင်တဲ့ single A10G GPU တစ်ခုပေါ်မှာ ၁ နာရီခန့် ကြာပါတယ်။
Training လုပ်နေစဉ် Model ကို Hub သို့ Push လုပ်ခြင်း
အကယ်၍ ကျွန်တော်တို့ push_to_hub argument ကို True အဖြစ် သတ်မှတ်ပြီး model_id argument ကို မှန်ကန်တဲ့ model name တစ်ခုအဖြစ် သတ်မှတ်ထားရင်၊ training လုပ်နေစဉ် model ကို Hugging Face Hub သို့ push လုပ်ပါလိမ့်မယ်။ model ကို ချက်ချင်း စမ်းသပ်ကြည့်ချင်တယ်ဆိုရင် ဒါက အသုံးဝင်ပါတယ်။
Training ရလဒ်များကို နားလည်ခြင်း
GRPOTrainer က သင့် reward function ကနေ reward၊ loss နဲ့ အခြား metrics အမျိုးမျိုးကို log လုပ်ပါတယ်။
ကျွန်တော်တို့ reward function ကနေ reward နဲ့ loss ကို အာရုံစိုက်ပါမယ်။
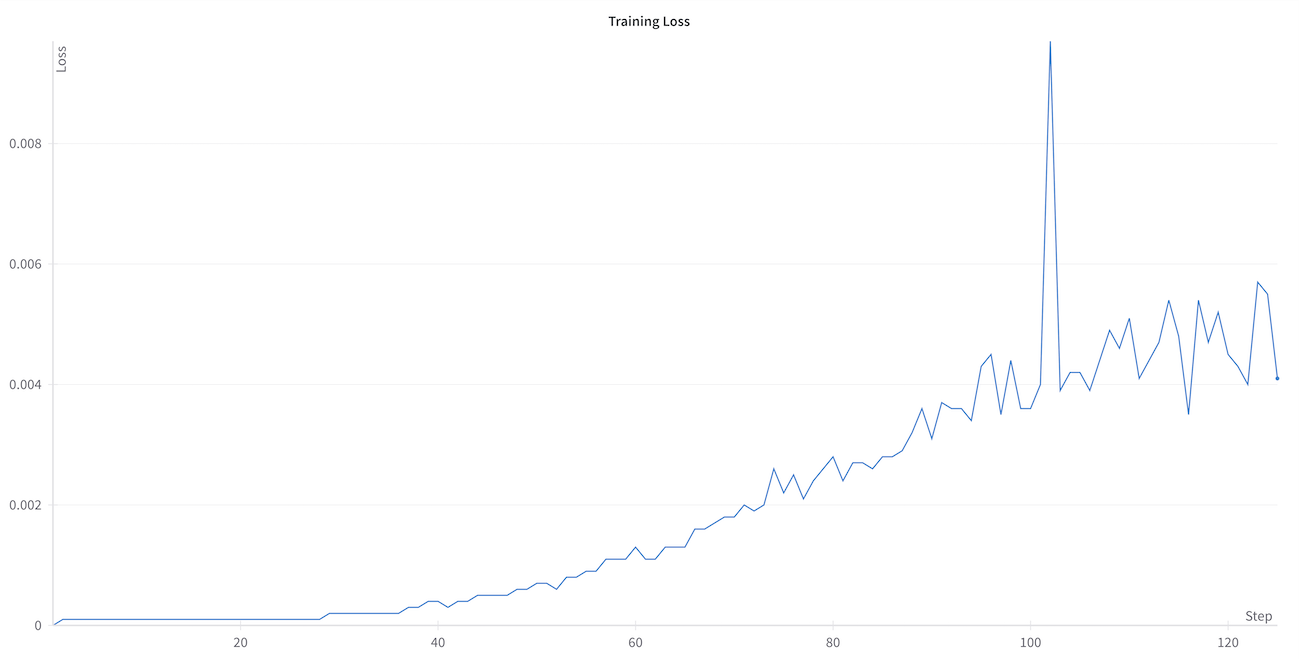
သင်မြင်ရတဲ့အတိုင်း၊ reward function ကနေ reward က model သင်ယူလာတာနဲ့အမျှ 0 နဲ့ ပိုနီးလာပါတယ်။ ဒါက model ဟာ မှန်ကန်တဲ့အရှည်ရှိတဲ့ text တွေ ထုတ်လုပ်ဖို့ သင်ယူနေတယ်ဆိုတဲ့ ကောင်းမွန်တဲ့ လက္ခဏာတစ်ခုပါပဲ။

loss က သုညကနေ စတင်ပြီး training လုပ်နေစဉ် တိုးလာတာကို သင်သတိထားမိနိုင်ပါတယ်။ ဒါက ပုံမှန်မဟုတ်ဘူးလို့ ထင်ရနိုင်ပါတယ်။ ဒီ behavior ဟာ GRPO မှာ မျှော်လင့်ထားတဲ့အရာဖြစ်ပြီး algorithm ရဲ့ mathematical formulation နဲ့ တိုက်ရိုက်သက်ဆိုင်ပါတယ်။ GRPO ရဲ့ loss က KL divergence (မူရင်း policy နဲ့ ဆက်စပ်တဲ့ cap) နဲ့ အချိုးကျပါတယ်။ Training လုပ်ငန်းစဉ် တိုးတက်လာတာနဲ့အမျှ၊ model က reward function နဲ့ ပိုမိုကိုက်ညီတဲ့ text တွေ ထုတ်လုပ်ဖို့ သင်ယူပြီး၊ ၎င်းရဲ့ မူရင်း policy ကနေ ပိုပြီး ကွဲလွဲလာပါတယ်။ ဒီတိုးလာတဲ့ ကွဲလွဲမှုက မြင့်တက်လာတဲ့ loss value မှာ ထင်ဟပ်နေပြီး၊ ဒါက model ဟာ reward function ကို optimize လုပ်ဖို့ အောင်မြင်စွာ လိုက်လျောညီထွေဖြစ်အောင် လုပ်ဆောင်နေတယ်ဆိုတာကို အမှန်တကယ် ပြသနေပါတယ်။
Model ကို Save လုပ်ပြီး Publish လုပ်ခြင်း
model ကို community နဲ့ မျှဝေကြရအောင်!
merged_model = trainer.model.merge_and_unload()
merged_model.push_to_hub(
"SmolGRPO-135M", private=False, tags=["GRPO", "Reasoning-Course"]
)Text ကို Generate လုပ်ခြင်း
🎉 သင်ဟာ GRPO ဖြင့် model တစ်ခုကို အောင်မြင်စွာ fine-tune လုပ်ခဲ့ပါပြီ။ အခု model နဲ့ text အချို့ကို generate လုပ်ကြရအောင်။
ပထမဆုံး၊ အရှည်ကြီးတဲ့ document တစ်ခုကို သတ်မှတ်ပါမယ်။
prompt = """
# A long document about the Cat
The cat (Felis catus), also referred to as the domestic cat or house cat, is a small
domesticated carnivorous mammal. It is the only domesticated species of the family Felidae.
Advances in archaeology and genetics have shown that the domestication of the cat occurred
in the Near East around 7500 BC. It is commonly kept as a pet and farm cat, but also ranges
freely as a feral cat avoiding human contact. It is valued by humans for companionship and
its ability to kill vermin. Its retractable claws are adapted to killing small prey species
such as mice and rats. It has a strong, flexible body, quick reflexes, and sharp teeth,
and its night vision and sense of smell are well developed. It is a social species,
but a solitary hunter and a crepuscular predator. Cat communication includes
vocalizations—including meowing, purring, trilling, hissing, growling, and grunting—as
well as body language. It can hear sounds too faint or too high in frequency for human ears,
such as those made by small mammals. It secretes and perceives pheromones.
"""
messages = [
{"role": "user", "content": prompt},
]အခု model နဲ့ text ကို generate လုပ်နိုင်ပါပြီ။
# Text ကို Generate လုပ်ပါ
from transformers import pipeline
generator = pipeline("text-generation", model="SmolGRPO-135M")
## ဒါမှမဟုတ် ကျွန်တော်တို့ အရင်က သတ်မှတ်ခဲ့တဲ့ model နဲ့ tokenizer ကို အသုံးပြုပါ
# generator = pipeline("text-generation", model=model, tokenizer=tokenizer)
generate_kwargs = {
"max_new_tokens": 256,
"do_sample": True,
"temperature": 0.5,
"min_p": 0.1,
}
generated_text = generator(messages, generate_kwargs=generate_kwargs)
print(generated_text)နိဂုံးချုပ်
ဒီအခန်းမှာ၊ GRPO ဖြင့် model တစ်ခုကို fine-tune လုပ်နည်းကို ကျွန်တော်တို့ တွေ့မြင်ခဲ့ရပါတယ်။ training ရလဒ်တွေကို ဘယ်လိုအဓိပ္ပာယ်ဖွင့်ရမလဲ၊ ပြီးတော့ model နဲ့ text ကို ဘယ်လို generate လုပ်ရမလဲဆိုတာလည်း ကျွန်တော်တို့ တွေ့မြင်ခဲ့ရပါတယ်။
ဝေါဟာရ ရှင်းလင်းချက် (Glossary)
- GRPO (Generalized Reweighted Policy Optimization): Reinforcement Learning (RL) မှ Policy Optimization algorithm တစ်မျိုးဖြစ်ပြီး၊ Language Models (LLMs) များကို reward function တစ်ခုကို အခြေခံ၍ fine-tune လုပ်ရာတွင် အသုံးပြုသည်။
- Fine-tune: ကြိုတင်လေ့ကျင့်ထားပြီးသား (pre-trained) မော်ဒယ်တစ်ခုကို သီးခြားလုပ်ငန်းတစ်ခု (specific task) အတွက် အနည်းငယ်သော ဒေတာနဲ့ ထပ်မံလေ့ကျင့်ပေးခြင်းကို ဆိုလိုပါတယ်။
- Model: Artificial Intelligence (AI) နယ်ပယ်တွင် အချက်အလက်များကို လေ့လာပြီး ခန့်မှန်းချက်များ ပြုလုပ်ရန် ဒီဇိုင်းထုတ်ထားသော သင်္ချာဆိုင်ရာဖွဲ့စည်းပုံများ။
- LLM (Large Language Model): လူသားဘာသာစကားကို နားလည်ပြီး ထုတ်လုပ်ပေးနိုင်တဲ့ အလွန်ကြီးမားတဲ့ Artificial Intelligence (AI) မော်ဒယ်တွေ ဖြစ်ပါတယ်။
- Dependencies: ဆော့ဖ်ဝဲလ်တစ်ခု သို့မဟုတ် library တစ်ခု အလုပ်လုပ်ရန် လိုအပ်သော အခြား library များနှင့် modules များ။
pip install -qqq: Python packages များကို တိတ်တဆိတ် (quietly) install လုပ်ရန် command။-qqqက output ကို ပိုမိုလျှော့ချသည်။datasetsLibrary: Hugging Face က ထုတ်လုပ်ထားတဲ့ library တစ်ခုဖြစ်ပြီး AI မော်ဒယ်တွေ လေ့ကျင့်ဖို့အတွက် ဒေတာအစုအဝေး (datasets) တွေကို လွယ်လွယ်ကူကူ ဝင်ရောက်ရယူ၊ စီမံခန့်ခွဲပြီး အသုံးပြုနိုင်စေပါတယ်။transformersLibrary: Hugging Face က ထုတ်လုပ်ထားတဲ့ library တစ်ခုဖြစ်ပြီး Transformer မော်ဒယ်တွေကို အသုံးပြုပြီး Natural Language Processing (NLP), computer vision, audio processing စတဲ့ နယ်ပယ်တွေမှာ အဆင့်မြင့် AI မော်ဒယ်တွေကို တည်ဆောက်ပြီး အသုံးပြုနိုင်စေပါတယ်။trlLibrary (Transformer Reinforcement Learning): Hugging Face မှထုတ်လုပ်သော library တစ်ခုဖြစ်ပြီး Reinforcement Learning (RL) ကို အသုံးပြု၍ Large Language Models (LLMs) များကို လေ့ကျင့်ရာတွင် အထောက်အကူပြုသည်။peftLibrary (Parameter-Efficient Fine-Tuning): Hugging Face မှထုတ်လုပ်သော library တစ်ခုဖြစ်ပြီး parameters နည်းပါးစွာဖြင့် fine-tuning လုပ်နိုင်စေသော နည်းလမ်းများကို ပံ့ပိုးပေးသည်။accelerateLibrary: Hugging Face က ထုတ်လုပ်ထားတဲ့ library တစ်ခုဖြစ်ပြီး PyTorch code တွေကို မတူညီတဲ့ training environment (ဥပမာ - GPU အများအပြား၊ distributed training) တွေမှာ အလွယ်တကူ run နိုင်အောင် ကူညီပေးပါတယ်။bitsandbytesLibrary: PyTorch အတွက် low-precision (8-bit) training နှင့် inference ကို ပံ့ပိုးပေးသော library။wandb(Weights & Biases): Machine Learning experiments များကို logging, monitoring, နှင့် visualization လုပ်ရန်အတွက် platform။flash-attn: Flash Attention algorithm ကို အကောင်အထည်ဖော်ထားသော library ဖြစ်ပြီး Transformer models များ၏ memory use နှင့် speed ကို တိုးမြှင့်ပေးသည်။--no-build-isolation:pip installcommand တွင် build isolation ကို ပိတ်ရန်အတွက် option။torch: PyTorch framework ကို ကိုယ်စားပြုသော Python library။load_dataset()Function: Hugging Face Datasets library မှ dataset များကို download လုပ်ပြီး cache လုပ်ရန် အသုံးပြုသော function။LoraConfig: LoRA (Low-Rank Adaptation) ၏ configuration များကို သတ်မှတ်ရန်peftlibrary မှ class။get_peft_model():peftlibrary မှ function တစ်ခုဖြစ်ပြီး base model ပေါ်တွင် PEFT (Parameter-Efficient Fine-Tuning) model ကို တည်ဆောက်သည်။AutoModelForCausalLM: Hugging Face Transformers library မှာ ပါဝင်တဲ့ class တစ်ခုဖြစ်ပြီး causal language modeling အတွက် model ကို အလိုအလျောက် load လုပ်ပေးသည်။AutoTokenizer: Hugging Face Transformers library မှာ ပါဝင်တဲ့ class တစ်ခုဖြစ်ပြီး model အမည်ကို အသုံးပြုပြီး သက်ဆိုင်ရာ tokenizer ကို အလိုအလျောက် load လုပ်ပေးသည်။GRPOConfig: GRPO algorithm ၏ training arguments များကို သတ်မှတ်ရန်trllibrary မှ class။GRPOTrainer: GRPO algorithm ကို အသုံးပြု၍ model ကို fine-tune လုပ်ရန်trllibrary မှ class။- Weights & Biases: Machine Learning experiments များကို မှတ်တမ်းတင်၊ စောင့်ကြည့်ပြီး ပုံရိပ်ယောင်ဖော်ပြရန် ကိရိယာတစ်ခု။
wandb.login(): Weights & Biases အကောင့်သို့ login ဝင်ရန် function။mlabonne/smoltldrDataset: Hugging Face Hub ပေါ်ရှိ short stories စာရင်းများပါဝင်သော dataset။SmolLM2-135MModel: Hugging FaceTB မှ ထုတ်လုပ်ထားသော 135M parameters ရှိသည့် Small Language Model (SLM)။SmolLM2-1.7BModel: Hugging FaceTB မှ ထုတ်လုပ်ထားသော 1.7B parameters ရှိသည့် Small Language Model (SLM)။model_id: Hugging Face Hub တွင် model တစ်ခုကို ဖော်ပြသော ထူးခြားသည့် နာမည်။torch_dtype="auto": PyTorch tensors များအတွက် data type ကို အလိုအလျောက် သတ်မှတ်ရန်။device_map="auto": model layers များကို အလိုအလျောက် available devices (CPU/GPU) များသို့ ဖြန့်ဝေရန်။attn_implementation="flash_attention_2": Flash Attention 2 ကို အသုံးပြု၍ attention mechanism ကို အကောင်အထည်ဖော်ရန်။- LoRA (Low-Rank Adaptation): Large Language Models များကို fine-tune လုပ်ရာတွင် parameters အရေအတွက်ကို လျှော့ချသော Parameter-Efficient Fine-Tuning (PEFT) နည်းလမ်း။
- Trainable Parameters: Model အတွင်းရှိ လေ့ကျင့်နိုင်သော weights နှင့် biases များ၏ အရေအတွက်။
- Memory Footprint: Program တစ်ခု သို့မဟုတ် model တစ်ခု အလုပ်လုပ်ရန် လိုအပ်သော memory ပမာဏ။
task_type="CAUSAL_LM": LoRA ကို Causal Language Modeling task အတွက် အသုံးပြုရန် သတ်မှတ်သည်။rParameter (LoRA): LoRA matrices များ၏ rank ကို သတ်မှတ်သည်။lora_alphaParameter: LoRA adaptation ၏ scaling factor။target_modules="all-linear": LoRA ကို model အတွင်းရှိ linear layers အားလုံးတွင် အသုံးပြုရန် သတ်မှတ်သည်။model.print_trainable_parameters(): PEFT model တွင် လေ့ကျင့်နိုင်သော parameters အရေအတွက်ကို print ထုတ်ရန်။- Reward Function: Reinforcement Learning (RL) တွင် agent ၏ လုပ်ဆောင်မှုများကို အကဲဖြတ်ပြီး reward value တစ်ခု ပြန်ပေးသော function။
- Completions: Model မှ ထုတ်လုပ်လိုက်သော စာသားများ။
output_dir: Training ရလဒ်များနှင့် model checkpoints များကို သိမ်းဆည်းမည့် directory။learning_rate: Training လုပ်ငန်းစဉ်အတွင်း model ၏ parameters များကို မည်မျှပြောင်းလဲရမည်ကို ထိန်းချုပ်သော parameter။per_device_train_batch_size: device တစ်ခုစီ (ဥပမာ- GPU) ပေါ်တွင် training batch တစ်ခုအတွက် samples အရေအတွက်။gradient_accumulation_steps: gradients များကို update မလုပ်ခင် ဘယ်နှစ် step စုဆောင်းမလဲ။max_prompt_length: prompt အတွက် အများဆုံး token အရှည်။max_completion_length: completion အတွက် အများဆုံး token အရှည်။num_generations: reward ကို တွက်ချက်ရန်အတွက် model မှ မည်မျှ completions များကို generate လုပ်မည်။optim="adamw_8bit": AdamW 8-bit optimizer ကို အသုံးပြုရန် သတ်မှတ်သည်။num_train_epochs: training dataset တစ်ခုလုံးကို model က ဘယ်နှစ်ကြိမ် လေ့ကျင့်မည်။bf16=True: bfloat16 mixed-precision training ကို အသုံးပြုရန်။report_to=["wandb"]: training metrics များကို Weights & Biases သို့ report လုပ်ရန်။remove_unused_columns=False: dataset မှ မသုံးသော columns များကို မဖယ်ရှားရန်။logging_steps: training metrics များကို log လုပ်မည့် step interval။trainer.train(): model ကို စတင်လေ့ကျင့်ရန် method။- A10G GPU: NVIDIA မှ ထုတ်လုပ်သော GPU တစ်မျိုးဖြစ်ပြီး AI/ML workloads များအတွက် အသုံးပြုသည်။
- Google Colab: Google မှ ပံ့ပိုးပေးထားသော cloud-based Jupyter Notebook environment တစ်ခု။
- Hugging Face Spaces: Hugging Face Hub ၏ အစိတ်အပိုင်းတစ်ခုဖြစ်ပြီး Gradio ကဲ့သို့သော library များကို အသုံးပြု၍ Machine Learning demos များကို host လုပ်ပြီး မျှဝေနိုင်သည်။
push_to_hubArgument: training လုပ်နေစဉ် model ကို Hugging Face Hub သို့ push လုပ်ရန် သတ်မှတ်သော argument။model_idArgument: Hugging Face Hub တွင် model အတွက် အမည်ကို သတ်မှတ်သော argument။- Vibe Testing: model ၏ စွမ်းဆောင်ရည်ကို အမြန်စစ်ဆေးခြင်း သို့မဟုတ် အကဲဖြတ်ခြင်း။
- Interpret Training Results: training လုပ်ငန်းစဉ်မှ ထွက်ပေါ်လာသော ကိန်းဂဏန်းများ သို့မဟုတ် ဂရပ်များကို နားလည်ပြီး အဓိပ္ပာယ်ဖွင့်ဆိုခြင်း။
- Loss: Model ၏ ခန့်မှန်းချက်များနှင့် အမှန်တကယ် labels များကြား ကွာခြားမှုကို တိုင်းတာသော တန်ဖိုး။
- KL Divergence (Kullback-Leibler Divergence): probability distributions နှစ်ခုကြား မည်မျှ ကွာခြားသည်ကို တိုင်းတာသော metric။
- Original Policy: Reinforcement Learning (RL) တွင် agent ၏ ကနဦး behavior သို့မဟုတ် model ၏ အစောပိုင်းဗားရှင်း။
trainer.model.merge_and_unload(): LoRA layers များကို base model ထဲသို့ ပေါင်းစပ်ပြီး memory မှ unload လုပ်ရန်peftlibrary မှ method။merged_model.push_to_hub(): ပေါင်းစပ်ထားသော model ကို Hugging Face Hub သို့ upload လုပ်ရန် method။private=False: model ကို public အဖြစ် မျှဝေရန် သတ်မှတ်သည်။tags: model ကို Hugging Face Hub တွင် ဖော်ပြရန် သို့မဟုတ် ရှာဖွေရန် အသုံးပြုသော keywords များ။pipeline("text-generation", model="SmolGRPO-135M"): Hugging Face Transformers library မှ text generation pipeline ကို SmolGRPO-135M model ဖြင့် အသုံးပြုရန်။max_new_tokens: model မှ generate လုပ်မည့် tokens အသစ်များ၏ အများဆုံးအရေအတွက်။do_sample=True: generate လုပ်နေစဉ် sampling ကို အသုံးပြုရန်။temperature: sampling ၏ randomness ကို ထိန်းချုပ်သည်။ တန်ဖိုးနိမ့်ပါက ပိုမိုခန့်မှန်းနိုင်သော text ကို ထုတ်လုပ်ပြီး၊ တန်ဖိုးမြင့်ပါက ပိုမိုဖန်တီးနိုင်သော text ကို ထုတ်လုပ်သည်။min_p: top-p sampling တွင် ထည့်သွင်းစဉ်းစားမည့် tokens များ၏ အနည်းဆုံး probability။generated_text: model မှ ထုတ်လုပ်လိုက်သော text။