
energy-transformer
The pretrained model weights are available on Hugging Face due to their large size (∼750 MB).
SELYNE: Stable-Energy Lyapunov Net with Energy-Based Attention and Mahalanobis Distance for Anomaly Detection
Selyne (Stable-Energy Lyapunov Net) introduces a novel energy-based attention mechanism, Gloeba (Global Energy-Based Attention), designed to overcome the thermal-quenching instability observed in traditional energy-based models. This repository contains the official PyTorch implementation, pretrained models, and evaluation code.
![]()
Table of Contents
- Key Highlights
- Overview
- Core Concepts & Architecture
- Getting Started
- Usage
- Results Summary
- License
- Citation
- Acknowledgements
Key Highlights
- Addresses Thermal Quenching: Selyne removes the unstable MCMC sampling step inherent in classical Energy-Based Models, replacing it with a deterministic, closed-form energy minimization process.
- Novel Attention Mechanism: Introduces Gloeba (Global Energy-Based Attention), which uses a learnable, per-head bilinear compatibility matrix (
M_h) and an adaptive, per-head temperature (tau_h) as an out-of-equilibrium thermostat. - Robust Anomaly Detection under Severe Class Imbalance: Achieves strong, low-variance AUROC on unsupervised anomaly detection benchmarks (STL-10 and BRISC2025) in high-anomaly-rate regimes (90% / 86%), where reconstruction-based scores typically saturate, using a Mahalanobis distance score in the latent space.
- Continuous Representation: Operates directly on continuous patch embeddings, preserving the spatial geometry lost by binary latent codes in classical EBMs.
- Cross-Domain Transfer: Demonstrates effective transfer of a model pretrained on natural images (Tiny ImageNet) to the medical imaging domain (brain MRI) without requiring a large medical corpus.
Overview
Classical Energy-Based Models (EBMs), such as Restricted Boltzmann Machines (RBMs), learn data distributions via Gibbs or Langevin sampling. A critical flaw is thermal quenching: with a fixed sampling temperature in a changing energy landscape, the sampler can freeze in local modes, leading to unstable training and poor gradient estimates. Selyne addresses this by eliminating the sampler entirely.
Instead, Selyne interprets each attention layer as a single, closed-form energy-minimization step on continuous patch embeddings. This is achieved through its core component, Gloeba, which provides a stable, learnable, and non-equilibrium thermodynamic regulation.
Sample Reconstructions
The following figures show qualitative reconstruction results on the BRISC2025 brain MRI (left) and the STL-10 natural images (right).
- BRISC2025 experiment outputs: normal (left) and abnormal (right); in both panels, each cell is a triple (left: original, middle: reconstruction, right: difference map).
- STL-10 experiment outputs: left normal and right abnormal; in both panels, each cell is a pair (left: original, right: reconstruction).
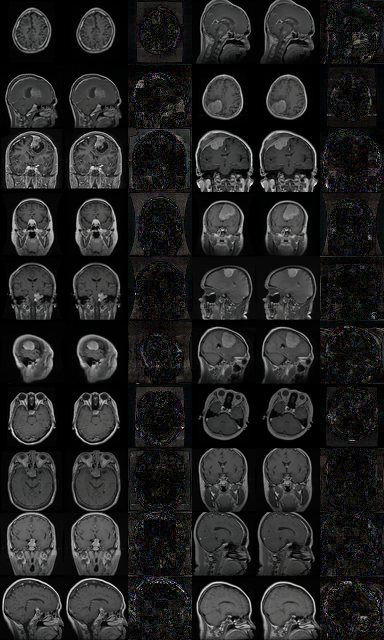
(a) BRISC2025 - Anomaly Reconstructions Open Anomaly |

(b) STL-10 - Normal Reconstructions Open Normal |
Core Concepts & Architecture
Why Not Traditional EBMs?
Traditional EBMs often suffer from:
- Binary Bottleneck: They force continuous visual data into binary latent codes, discarding crucial metric information like position, texture, and geometric proportion.
- Thermal Quenching: Fixed-temperature sampling in a non-stationary energy landscape is fundamentally unstable.
Selyne is designed to bypass both of these limitations.
Selyne Architecture
Selyne is built on a Transformer backbone and consists of:
- Patch Embedding: Splits the input image into patches and projects them into continuous token embeddings.
- Gloeba Encoder: A stack of 6 transformer blocks that utilize the novel Energy-Based Attention.
- Prototype Cross-Attention: Summarizes patch tokens into a fixed set of prototype vectors.
- Latent Encoder MLP: Projects the combined [CLS] token and prototype features into a continuous latent space.
- Reconstruction Decoder: Mirrors the encoder to reconstruct the original image from the latent representation.
Gloeba: The Core Attention Mechanism
For each head h:
Learnable Bilinear Compatibility: Replaces the standard dot product with a learnable bilinear form:
S_h = Q_h M_h K_h^THere,
M_his a head-specific, learnable matrix that learns a non-Euclidean similarity geometry.Adaptive Per-Head Temperature: Uses a learnable temperature
tau_h = e^(l_h), clamped to a minimum valueepsilon. This acts as a thermostat, adaptively controlling the sharpness/softness of the attention and preventing quenching.Closed-Form Energy Minimization: The resulting softmax operation is the exact minimizer of an entropy-regularized bilinear energy, providing deterministic stability.
The Latent Mahalanobis Scoring
After fine-tuning, anomaly detection is performed using two scores:
- Reconstruction Energy Score: A pixel-wise reconstruction error.
- Mahalanobis Distance (Primary): A distance metric in the latent space. A Ledoit-Wolf shrinkage covariance is estimated from the normal training data. The Mahalanobis distance of a new sample is then computed, with anomalies lying further from the normal distribution's mean.
Getting Started
Prerequisites
- Python 3.10+
- PyTorch 2.0+
- CUDA-capable GPU (minimum 8GB VRAM recommended)
- Required libraries (see requirements.txt)
Installation
Clone the repository:
git clone https://github.com/cagasolu/energy-transformer.git
cd energy-transformer
Set up a virtual environment (recommended):
python -m venv venv
source venv/bin/activate # On Windows, use venv\Scripts\activate
Install dependencies:
pip install -r requirements.txt
Dataset Preparation
- Tiny ImageNet: The script pretrain_selyne_recon.py will automatically download and use the dataset if it's not found. You can also place it in a ./data directory.
- STL-10: The globaleba_mahalanobis.py script will download it automatically via torchvision.
- BRISC2025: You need to download the dataset from its source. Ensure the directory structure matches the script's expectations (e.g., train/no_tumor, test/no_tumor, test/glioma, etc.)
Usage
Important: Before running any script, ensure you have downloaded the pretrained model files (.pt files) from the Hugging Face repository or Zenodo and placed them in the project root directory. Alternatively, you can train your own model.
1. Pretraining on Tiny ImageNet
This stage trains the full Selyne model from scratch on the Tiny ImageNet classification task.
python pretrain_selyne_recon.py
- This will run for up to 72 epochs.
- The best checkpoint (pretrained_selyne_full_recon_best.pt) and final checkpoint (pretrained_selyne_full_recon.pt) will be saved.
2. Anomaly Detection on STL-10
This script evaluates the model on the unsupervised anomaly detection task using the STL-10 dataset. It treats each of the 10 classes as the "normal" class in turn.
python globaleba_mahalanobis.py
- The script will automatically load the pretrained checkpoint, fine-tune the model for each class, and compute both Energy and Mahalanobis AUROC scores.
- The results (AUROC bar charts, ROC curves, score distributions) and sample reconstructions will be saved in the project directory.
3. Anomaly Detection on BRISC2025 Brain MRI
This script evaluates the model's ability to detect brain tumors. It treats the "no_tumor" class as normal and all tumor types (glioma, meningioma, pituitary) as anomalies.
python energetic_mahal_science.py
- The script loads the pretrained checkpoint, fine-tunes the model, and computes Energy and Mahalanobis AUROC scores.
- It also saves side-by-side reconstructions with difference maps for qualitative analysis.
Results Summary
The Selyne model demonstrates robust and stable anomaly detection performance across different domains and random seeds.
| Dataset / Score Type | Mean AUROC | Stability (CV) |
|---|---|---|
| STL-10 (90% Anomaly) / Energy (Reconstruction) | 0.517 | 0.45% |
| STL-10 (90% Anomaly) / Mahalanobis (Latent) | 0.891 | 0.06% |
| BRISC2025 (86% Anomaly) / Energy (Reconstruction) | 0.753 | 2.56% |
| BRISC2025 (86% Anomaly) / Mahalanobis (Latent) | 0.852 | 1.71% |
Key takeaway: The latent Mahalanobis score provides a highly discriminative and stable signal for anomaly detection, significantly outperforming the reconstruction energy score, which saturates due to the model's high reconstruction fidelity.
License
This project is licensed under the GNU General Public License v3.0. See the LICENSE file for more details.
Citation
If you find our work useful for your research, please consider citing it:
@misc{suleymanoglu2026selyne,
author = {Süleymanoğlu, Görkem Can},
title = {Selyne: Stable-Energy Lyapunov Net with Energy-Based Attention for Anomaly Detection},
year = {2026},
publisher = {Hugging Face},
howpublished = {\url{https://huggingface.co/cagasoluh/energy-transformer}},
doi = {10.5281/zenodo.20779017}
}
Acknowledgements
This work was made possible by the computing resources and support from Kuanka Publishing LLC. The code is available on:
- GitHub: https://github.com/cagasolu/energy-transformer
- Hugging Face: https://huggingface.co/cagasoluh/energy-transformer
- Zenodo: https://doi.org/10.5281/zenodo.20779017
Note: For the most up-to-date information, please refer to the code repository directly.