Summer At Hugging Face 😎

Summer is now officially over and these last few months have been quite busy at Hugging Face. From new features in the Hub to research and Open Source development, our team has been working hard to empower the community through open and collaborative technology.
In this blog post you'll catch up on everything that happened at Hugging Face in June, July and August!

This post covers a wide range of areas our team has been working on, so don't hesitate to skip to the parts that interest you the most 🤗
New Features
In the last few months, the Hub went from 10,000 public model repositories to over 16,000 models! Kudos to our community for sharing so many amazing models with the world. And beyond the numbers, we have a ton of cool new features to share with you!
Spaces Beta (hf.co/spaces)
Spaces is a simple and free solution to host Machine Learning demo applications directly on your user profile or your organization hf.co profile. We support two awesome SDKs that let you build cool apps easily in Python: Gradio and Streamlit. In a matter of minutes you can deploy an app and share it with the community! 🚀
Spaces lets you set up secrets, permits custom requirements, and can even be managed directly from GitHub repos. You can sign up for the beta at hf.co/spaces. Here are some of our favorites!
- Create recipes with the help of Chef Transformer
- Transcribe speech to text with HuBERT
- Do segmentation in a video with the DINO model
- Use Paint Transformer to make paintings from a given picture
- Or you can just explore any of the over 100 existing Spaces!
Share Some Love
You can now like any model, dataset, or Space on http://huggingface.co, meaning you can share some love with the community ❤️. You can also keep an eye on who's liking what by clicking on the likes box 👀. Go ahead and like your own repos, we're not judging 😉.
TensorBoard Integration
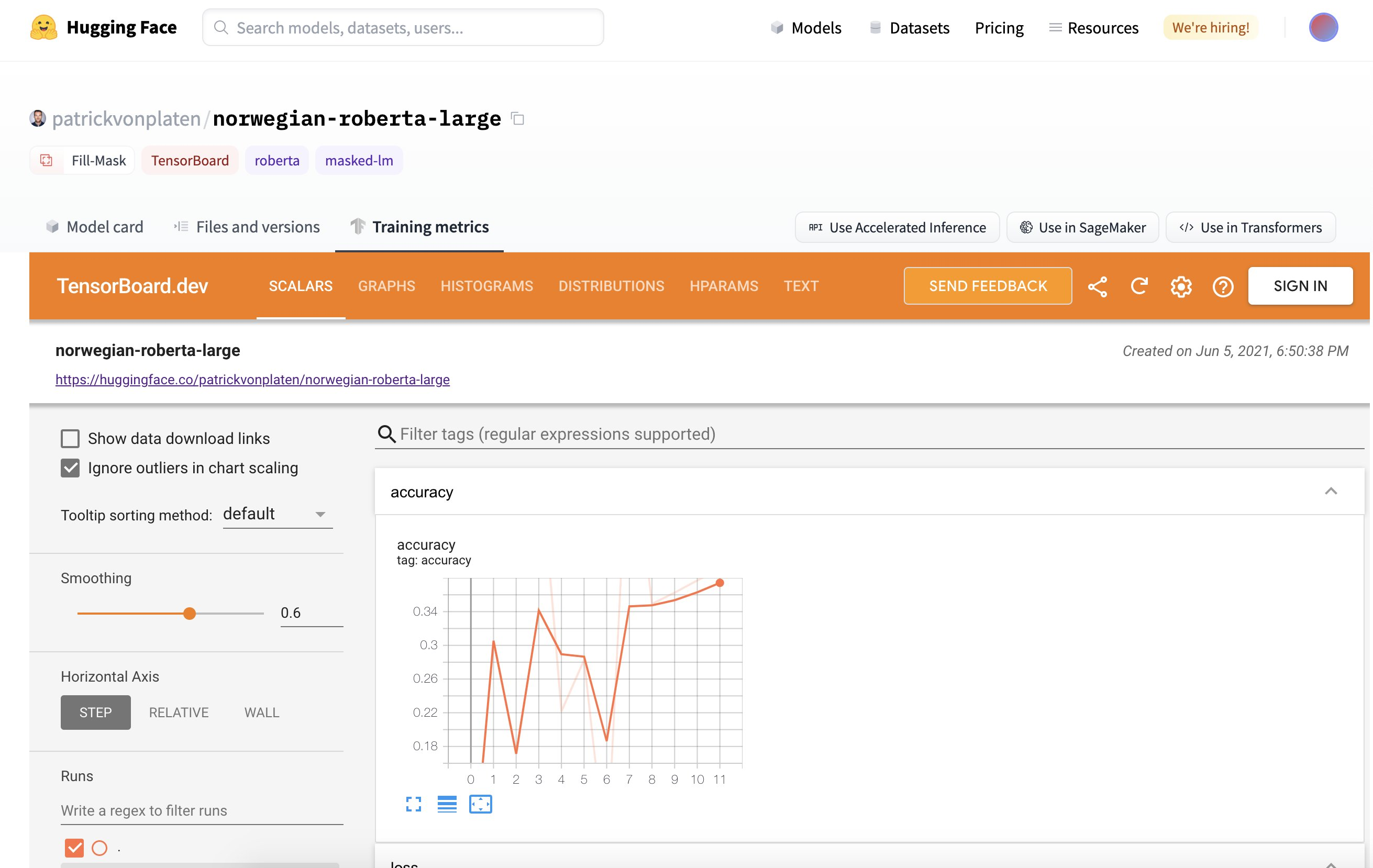
In late June, we launched a TensorBoard integration for all our models. If there are TensorBoard traces in the repo, an automatic, free TensorBoard instance is launched for you. This works with both public and private repositories and for any library that has TensorBoard traces!
Metrics
In July, we added the ability to list evaluation metrics in model repos by adding them to their model card📈. If you add an evaluation metric under the model-index section of your model card, it will be displayed proudly in your model repo.
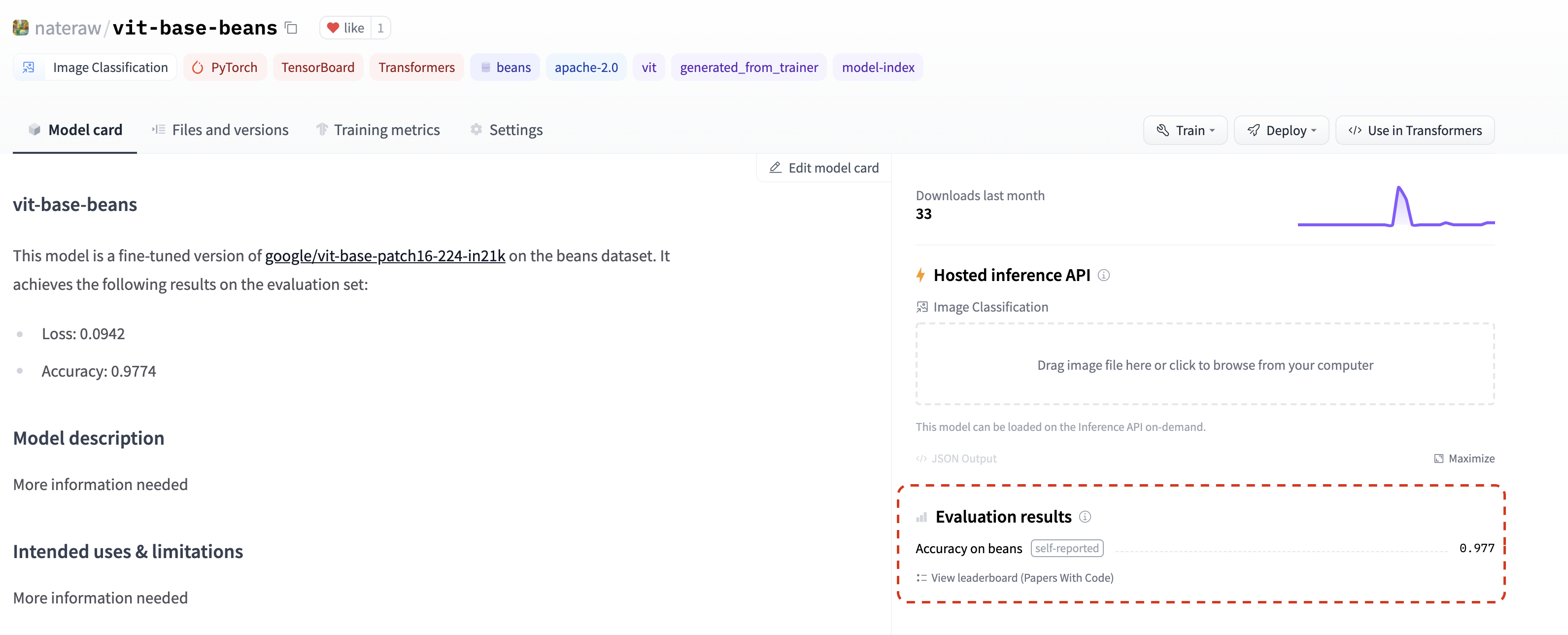
If that wasn't enough, these metrics will be automatically linked to the corresponding Papers With Code leaderboard. That means as soon as you share your model on the Hub, you can compare your results side-by-side with others in the community. 💪
Check out this repo as an example, paying close attention to model-index section of its model card to see how you can do this yourself and find the metrics in Papers with Code automatically.
New Widgets
The Hub has 18 widgets that allow users to try out models directly in the browser.
With our latest integrations to Sentence Transformers, we also introduced two new widgets: feature extraction and sentence similarity.
The latest audio classification widget enables many cool use cases: language identification, street sound detection 🚨, command recognition, speaker identification, and more! You can try this out with transformers and speechbrain models today! 🔊 (Beware, when you try some of the models, you might need to bark out loud)
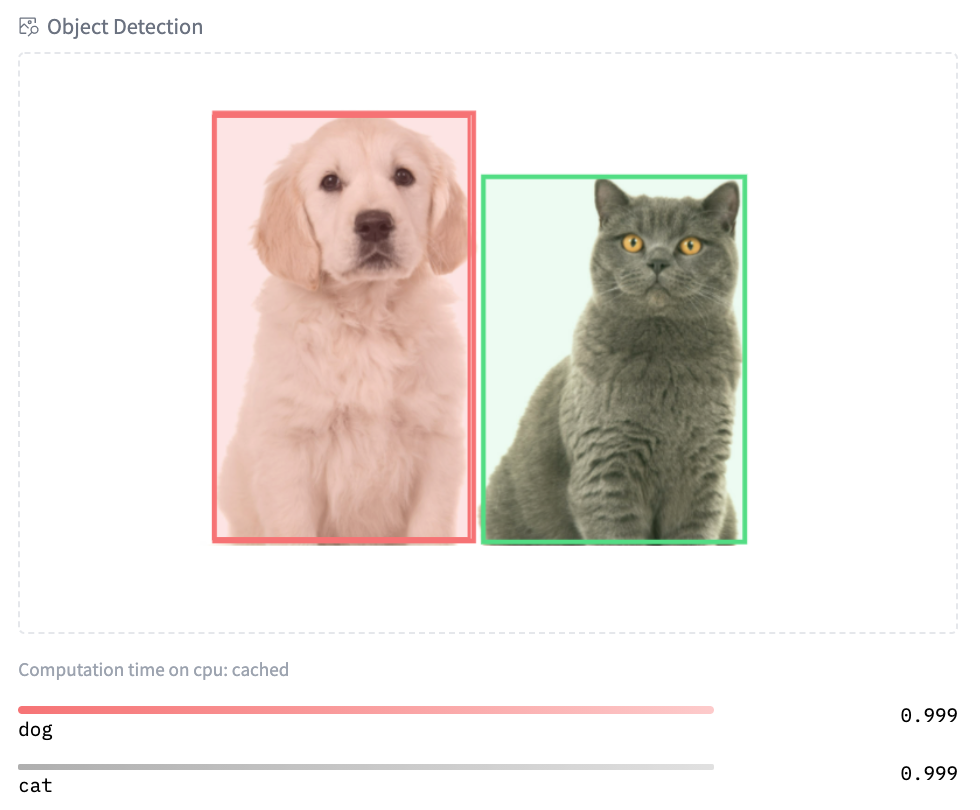
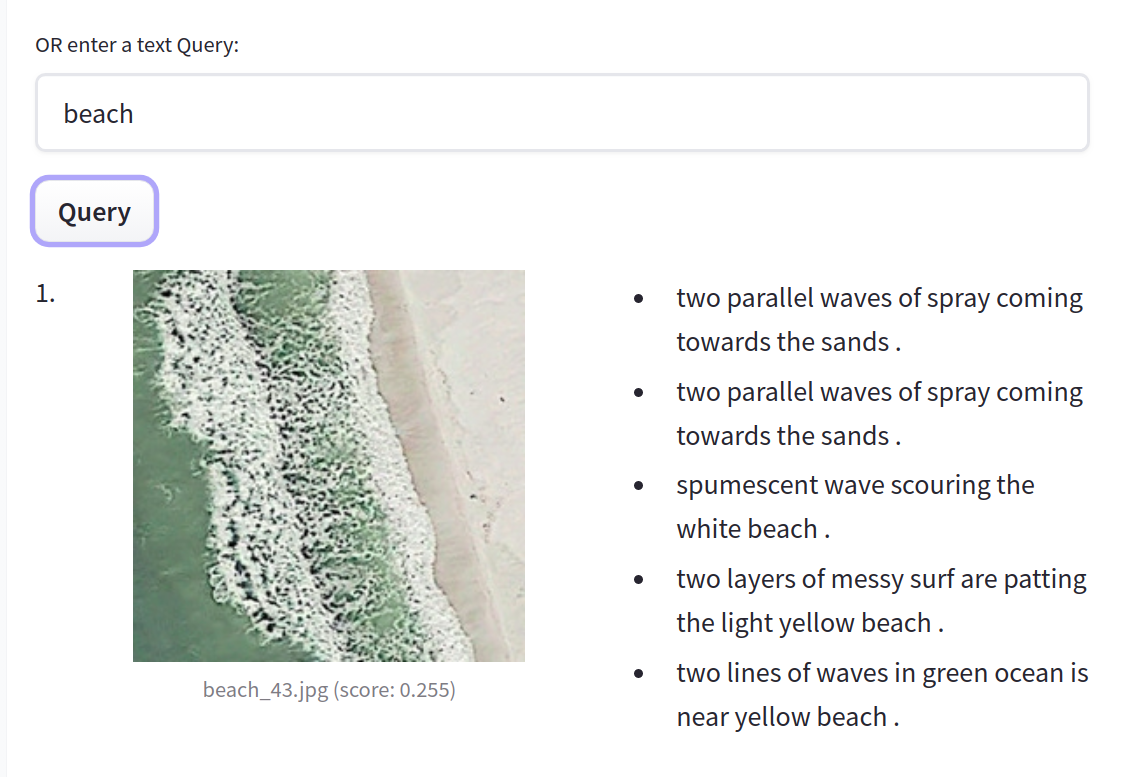
You can try our early demo of structured data classification with Scikit-learn. And finally, we also introduced new widgets for image-related models: text to image, image classification, and object detection. Try image classification with Google's ViT model here and object detection with Facebook AI's DETR model here!
More Features
That's not everything that has happened in the Hub. We've introduced new and improved documentation of the Hub. We also introduced two widely requested features: users can now transfer/rename repositories and directly upload new files to the Hub.
Community
Hugging Face Course
In June, we launched the first part of our free online course! The course teaches you everything about the 🤗 Ecosystem: Transformers, Tokenizers, Datasets, Accelerate, and the Hub. You can also find links to the course lessons in the official documentation of our libraries. The live sessions for all chapters can be found on our YouTube channel. Stay tuned for the next part of the course which we'll be launching later this year!
JAX/FLAX Sprint
In July we hosted our biggest community event ever with almost 800 participants! In this event co-organized with the JAX/Flax and Google Cloud teams, compute-intensive NLP, Computer Vision, and Speech projects were made accessible to a wider audience of engineers and researchers by providing free TPUv3s. The participants created over 170 models, 22 datasets, and 38 Spaces demos 🤯. You can explore all the amazing demos and projects here.
There were talks around JAX/Flax, Transformers, large-scale language modeling, and more! You can find all recordings here.
We're really excited to share the work of the 3 winning teams!
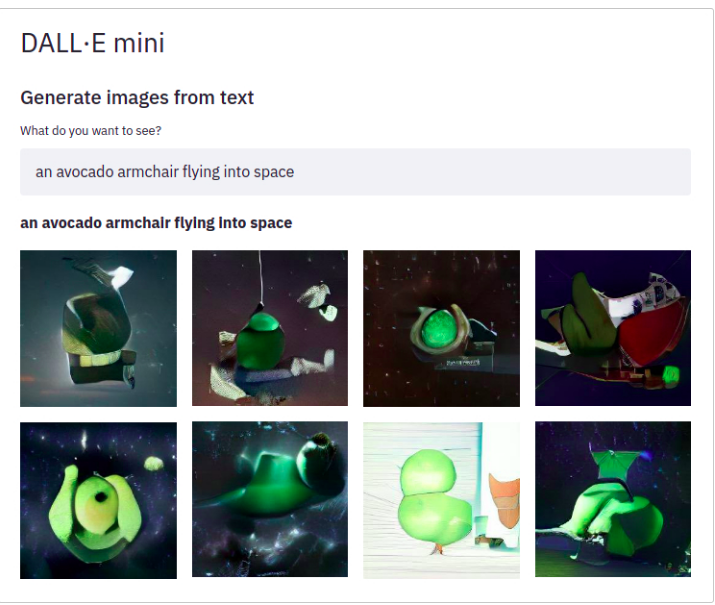
Dall-e mini. DALL·E mini is a model that generates images from any prompt you give! DALL·E mini is 27 times smaller than the original DALL·E and still has impressive results.
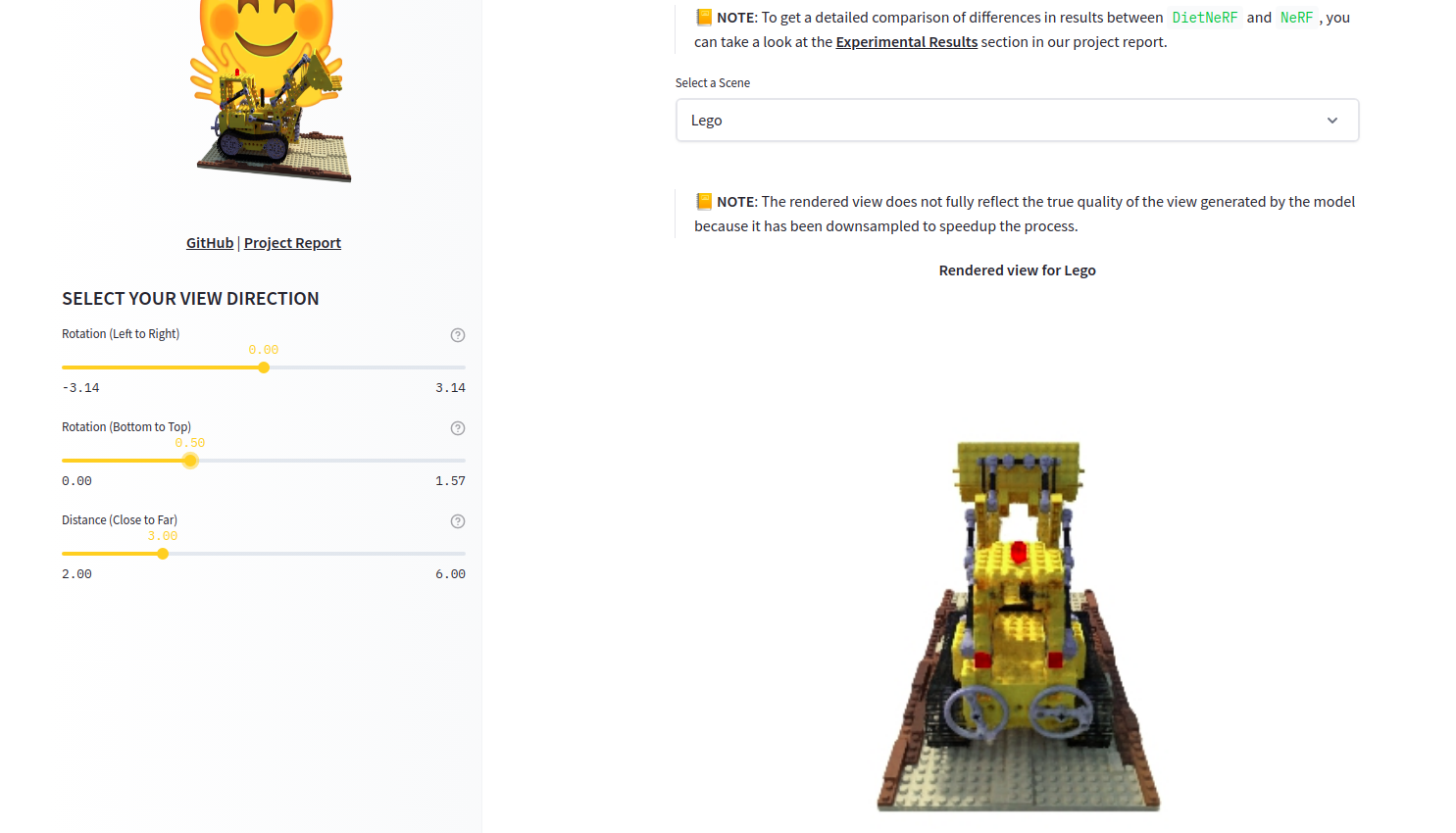
DietNerf. DietNerf is a 3D neural view synthesis model designed for few-shot learning of 3D scene reconstruction using 2D views. This is the first Open Source implementation of the "Putting Nerf on a Diet" paper.
CLIP RSIC. CLIP RSIC is a CLIP model fine-tuned on remote sensing image data to enable zero-shot satellite image classification and captioning. This project demonstrates how effective fine-tuned CLIP models can be for specialized domains.
Apart from these very cool projects, we're excited about how these community events enable training large and multi-modal models for multiple languages. For example, we saw the first ever Open Source big LMs for some low-resource languages like Swahili, Polish and Marathi.
Bonus
On top of everything we just shared, our team has been doing lots of other things. Here are just some of them:
- 📖 This 3-part video series shows the theory on how to train state-of-the-art sentence embedding models.
- We presented at PyTorch Community Voices and participated in a QA (video).
- Hugging Face has collaborated with NLP in Spanish and SpainAI in a Spanish course that teaches concepts and state-of-the art architectures as well as their applications through use cases.
- We presented at MLOps World Demo Days.
Open Source
New in Transformers
Summer has been an exciting time for 🤗 Transformers! The library reached 50,000 stars, 30 million total downloads, and almost 1000 contributors! 🤩
So what's new? JAX/Flax is now the 3rd supported framework with over 5000 models in the Hub! You can find actively maintained examples for different tasks such as text classification. We're also working hard on improving our TensorFlow support: all our examples have been reworked to be more robust, TensorFlow idiomatic, and clearer. This includes examples such as summarization, translation, and named entity recognition.
You can now easily publish your model to the Hub, including automatically authored model cards, evaluation metrics, and TensorBoard instances. There is also increased support for exporting models to ONNX with the new transformers.onnx module.
python -m transformers.onnx --model=bert-base-cased onnx/bert-base-cased/
The last 4 releases introduced many new cool models!
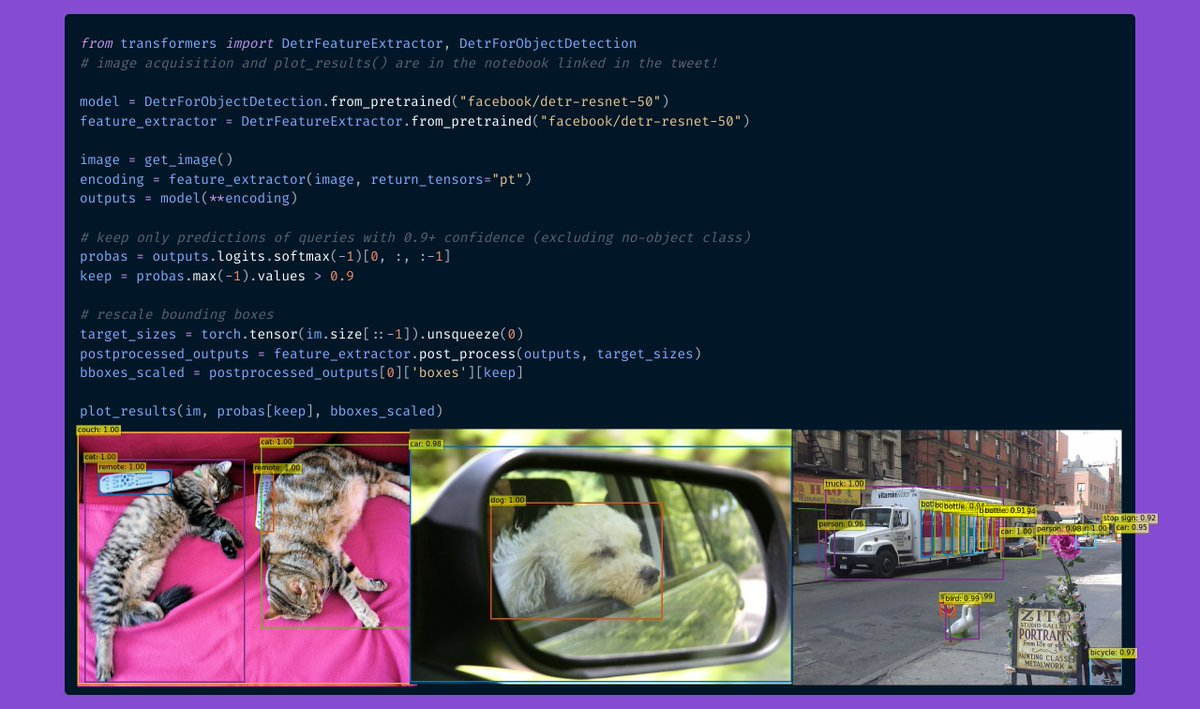
- DETR can do fast end-to-end object detection and image segmentation. Check out some of our community tutorials!
- ByT5 is the first tokenizer-free model in the Hub! You can find all available checkpoints here.
- CANINE is another tokenizer-free encoder-only model by Google AI, operating directly at the character level. You can find all (multilingual) checkpoints here.
- HuBERT shows exciting results for downstream audio tasks such as command classification and emotion recognition. Check the models here.
- LayoutLMv2 and LayoutXLM are two incredible models capable of parsing document images (like PDFs) by incorporating text, layout, and visual information. We built a Space demo so you can directly try it out! Demo notebooks can be found here.

- BEiT by Microsoft Research makes self-supervised Vision Transformers outperform supervised ones, using a clever pre-training objective inspired by BERT.
- RemBERT, a large multilingual Transformer that outperforms XLM-R (and mT5 with a similar number of parameters) in zero-shot transfer.
- Splinter which can be used for few-shot question answering. Given only 128 examples, Splinter is able to reach ~73% F1 on SQuAD, outperforming MLM-based models by 24 points!
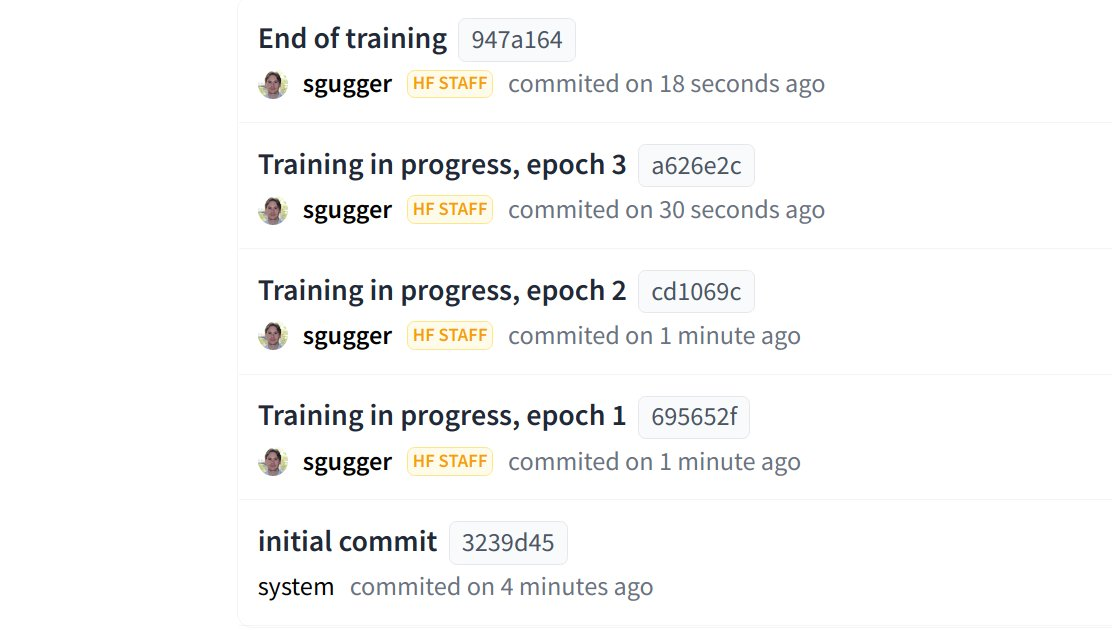
The Hub is now integrated into transformers, with the ability to push to the Hub configuration, model, and tokenizer files without leaving the Python runtime! The Trainer can now push directly to the Hub every time a checkpoint is saved:
New in Datasets
You can find 1400 public datasets in https://huggingface.co/datasets thanks to the awesome contributions from all our community. 💯
The support for datasets keeps growing: it can be used in JAX, process parquet files, use remote files, and has wider support for other domains such as Automatic Speech Recognition and Image Classification.
Users can also directly host and share their datasets to the community simply by uploading their data files in a repository on the Dataset Hub.
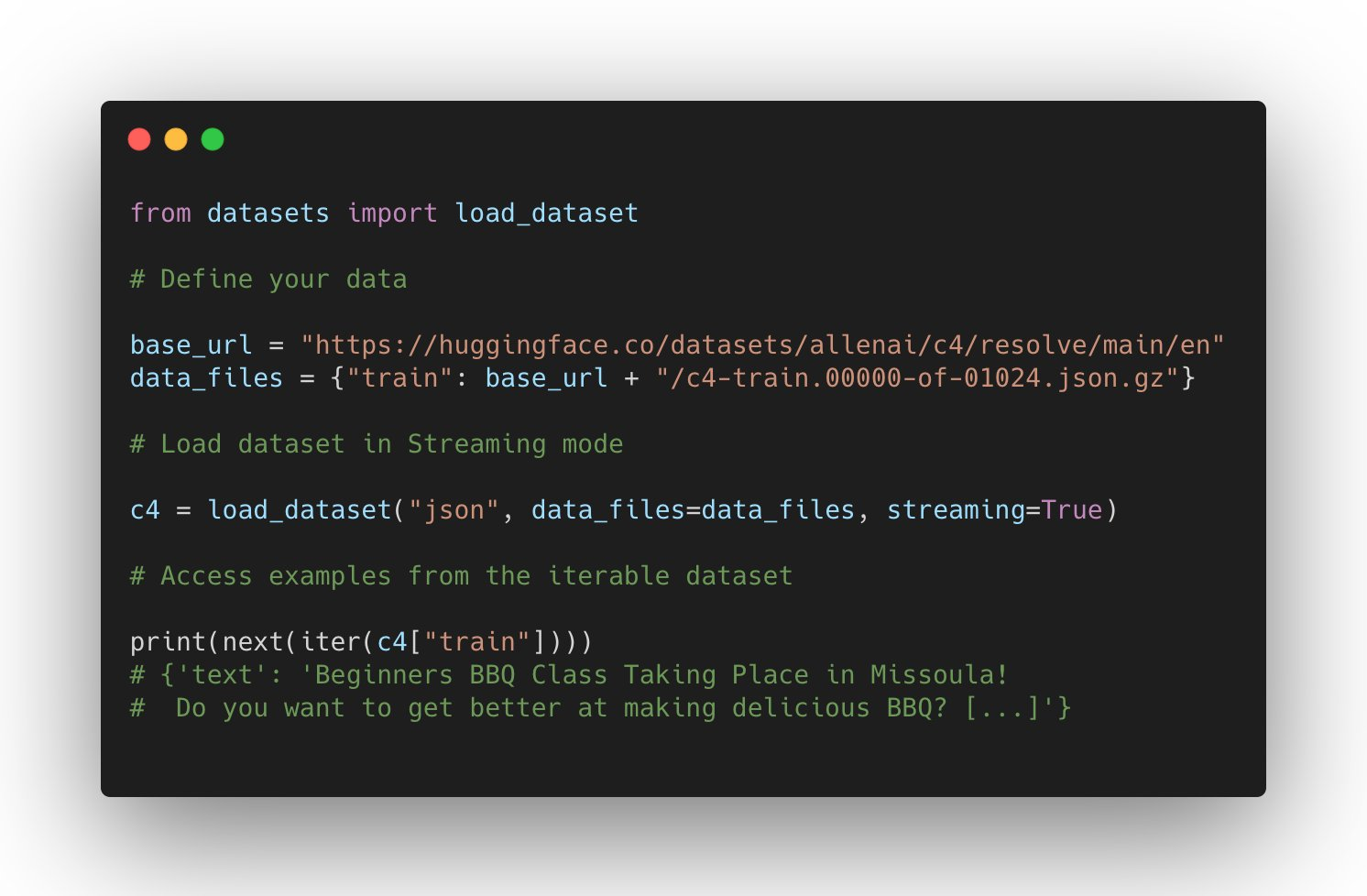
What are the new datasets highlights? Microsoft CodeXGlue datasets for multiple coding tasks (code completion, generation, search, etc), huge datasets such as C4 and MC4, and many more such as RussianSuperGLUE and DISFL-QA.
Welcoming new Libraries to the Hub
Apart from having deep integration with transformers-based models, the Hub is also building great partnerships with Open Source ML libraries to provide free model hosting and versioning. We've been achieving this with our huggingface_hub Open-Source library as well as new Hub documentation.
All spaCy canonical pipelines can now be found in the official spaCy organization, and any user can share their pipelines with a single command python -m spacy huggingface-hub. To read more about it, head to https://huggingface.co/blog/spacy. You can try all canonical spaCy models directly in the Hub in the demo Space!
Another exciting integration is Sentence Transformers. You can read more about it in the blog announcement: you can find over 200 models in the Hub, easily share your models with the rest of the community and reuse models from the community.
But that's not all! You can now find over 100 Adapter Transformers in the Hub and try out Speechbrain models with widgets directly in the browser for different tasks such as audio classification. If you're interested in our collaborations to integrate new ML libraries to the Hub, you can read more about them here.

Solutions
Coming soon: Infinity
Transformers latency down to 1ms? 🤯🤯🤯
We have been working on a really sleek solution to achieve unmatched efficiency for state-of-the-art Transformer models, for companies to deploy in their own infrastructure.
- Infinity comes as a single-container and can be deployed in any production environment.
- It can achieve 1ms latency for BERT-like models on GPU and 4-10ms on CPU 🤯🤯🤯
- Infinity meets the highest security requirements and can be integrated into your system without the need for internet access. You have control over all incoming and outgoing traffic.
⚠️ Join us for a live announcement and demo on Sep 28, where we will be showcasing Infinity for the first time in public!
NEW: Hardware Acceleration
Hugging Face is partnering with leading AI hardware accelerators such as Intel, Qualcomm and GraphCore to make state-of-the-art production performance accessible and extend training capabilities on SOTA hardware. As the first step in this journey, we introduced a new Open Source library: 🤗 Optimum - the ML optimization toolkit for production performance 🏎. Learn more in this blog post.
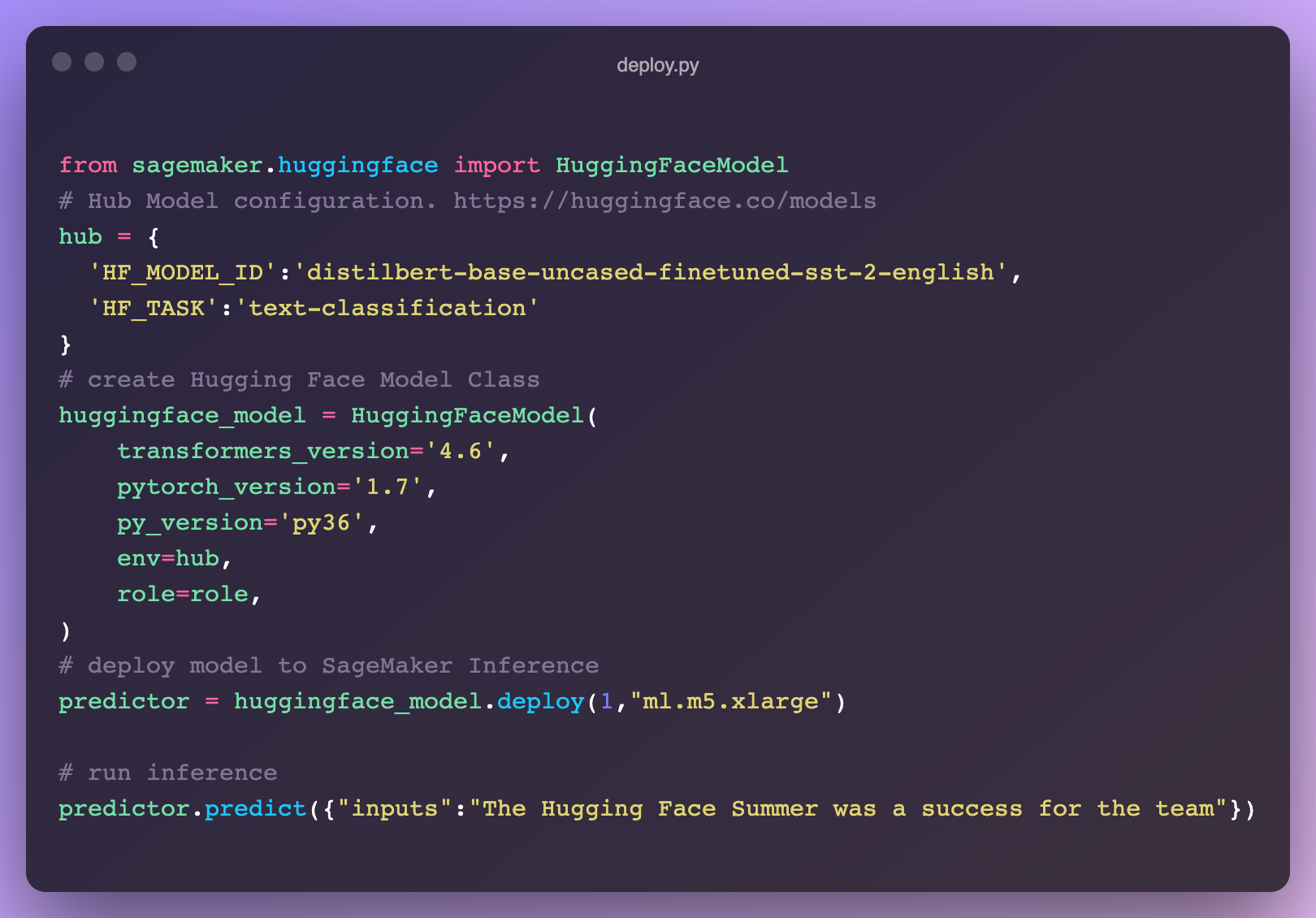
NEW: Inference on SageMaker
We launched a new integration with AWS to make it easier than ever to deploy 🤗 Transformers in SageMaker 🔥. Pick up the code snippet right from the 🤗 Hub model page! Learn more about how to leverage transformers in SageMaker in our docs or check out these video tutorials.
For questions reach out to us on the forum: https://discuss.huggingface.co/c/sagemaker/17
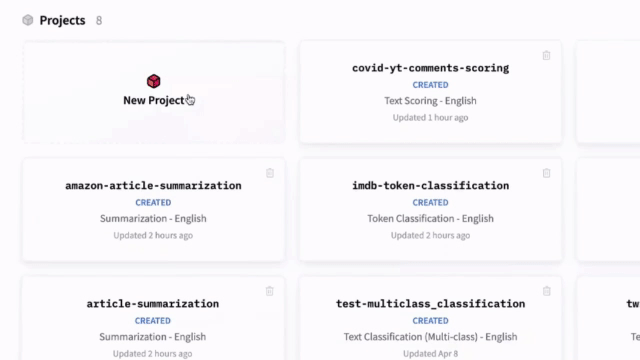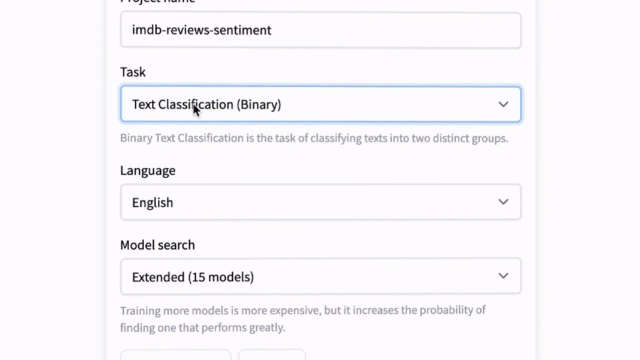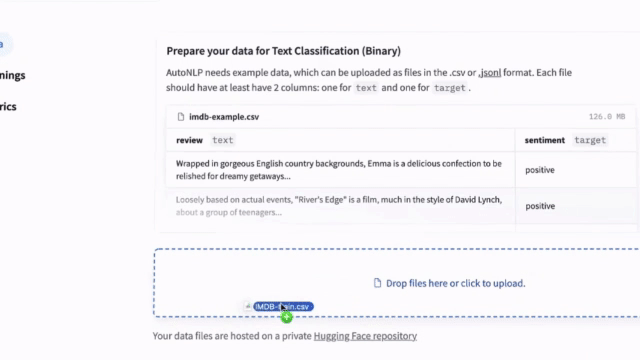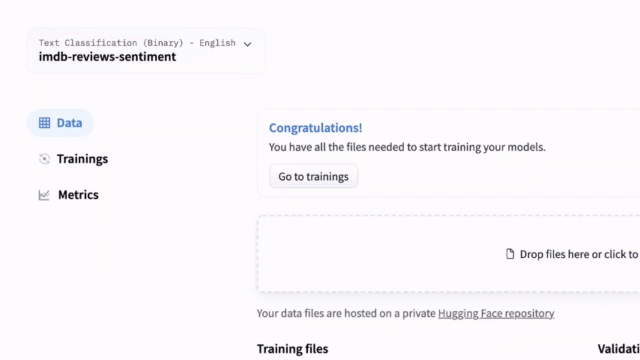
NEW: AutoNLP In Your Browser
We released a new AutoNLP experience: a web interface to train models straight from your browser! Now all it takes is a few clicks to train, evaluate and deploy 🤗 Transformers models on your own data. Try it out - NO CODE needed!
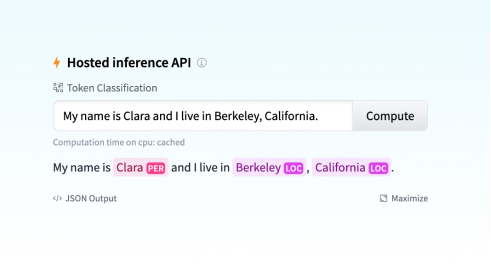
Inference API
Webinar:
We hosted a live webinar to show how to add Machine Learning capabilities with just a few lines of code. We also built a VSCode extension that leverages the Hugging Face Inference API to generate comments describing Python code.
Hugging Face + Zapier Demo
20,000+ Machine Learning models connected to 3,000+ apps? 🤯 By leveraging the Inference API, you can now easily connect models right into apps like Gmail, Slack, Twitter, and more. In this demo video, we created a zap that uses this code snippet to analyze your Twitter mentions and alerts you on Slack about the negative ones.
Hugging Face + Google Sheets Demo
With the Inference API, you can easily use zero-shot classification right into your spreadsheets in Google Sheets. Just add this script in Tools -> Script Editor:
Few-shot learning in practice
We wrote a blog post about what Few-Shot Learning is and explores how GPT-Neo and 🤗 Accelerated Inference API are used to generate your own predictions.
Expert Acceleration Program
Check out out the brand new home for the Expert Acceleration Program; you can now get direct, premium support from our Machine Learning experts and build better ML solutions, faster.
Research
At BigScience we held our first live event (since the kick off) in July BigScience Episode #1. Our second event BigScience Episode #2 was held on September 20th, 2021 with technical talks and updates by the BigScience working groups and invited talks by Jade Abbott (Masakhane), Percy Liang (Stanford CRFM), Stella Biderman (EleutherAI) and more. We have completed the first large-scale training on Jean Zay, a 13B English only decoder model (you can find the details here), and we're currently deciding on the architecture of the second model. The organization working group has filed the application for the second half of the compute budget: Jean Zay V100 : 2,500,000 GPU hours. 🚀
In June, we shared the result of our collaboration with the Yandex research team: DeDLOC, a method to collaboratively train your large neural networks, i.e. without using an HPC cluster, but with various accessible resources such as Google Colaboratory or Kaggle notebooks, personal computers or preemptible VMs. Thanks to this method, we were able to train sahajBERT, a Bengali language model, with 40 volunteers! And our model competes with the state of the art, and even is the best for the downstream task of classification on Soham News Article Classification dataset. You can read more about it in this blog post. This is a fascinating line of research because it would make model pre-training much more accessible (financially speaking)!
In June our paper, How Many Data Points is a Prompt Worth?, got a Best Paper award at NAACL! In it, we reconcile and compare traditional and prompting approaches to adapt pre-trained models, finding that human-written prompts are worth up to thousands of supervised data points on new tasks. You can also read its blog post.
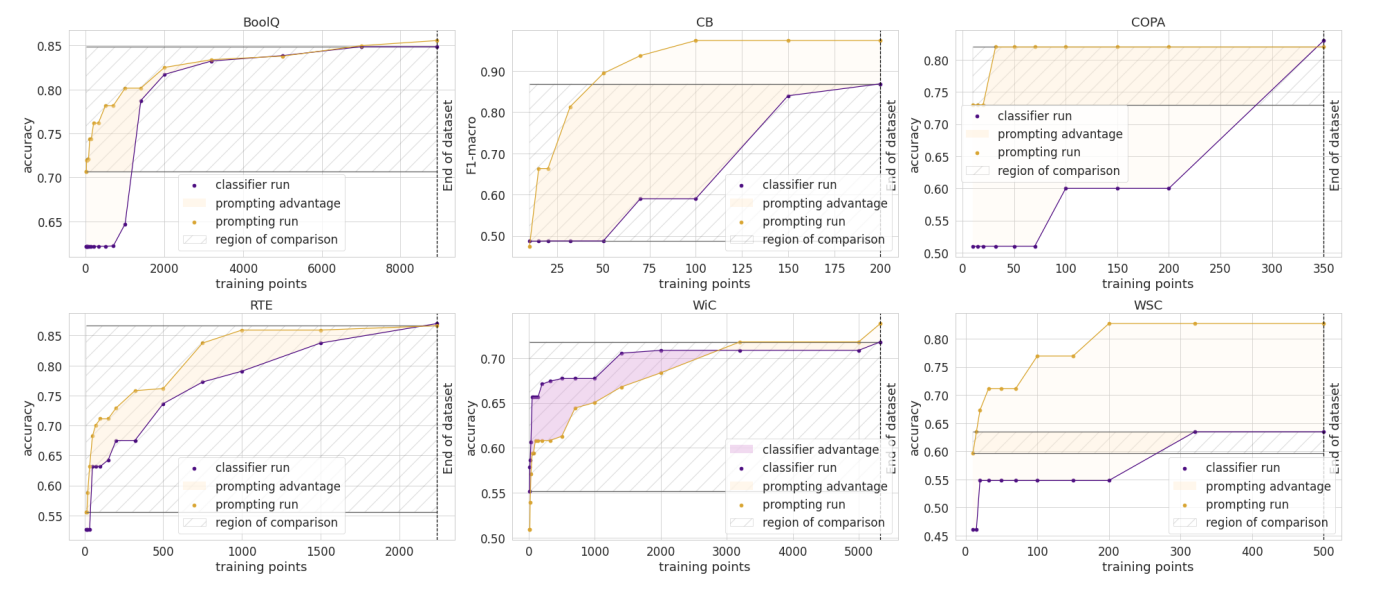
We're looking forward to EMNLP this year where we have four accepted papers!
- Our paper "Datasets: A Community Library for Natural Language Processing" documents the Hugging Face Datasets project that has over 300 contributors. This community project gives easy access to hundreds of datasets to researchers. It has facilitated new use cases of cross-dataset NLP, and has advanced features for tasks like indexing and streaming large datasets.
- Our collaboration with researchers from TU Darmstadt lead to another paper accepted at the conference ("Avoiding Inference Heuristics in Few-shot Prompt-based Finetuning"). In this paper, we show that prompt-based fine-tuned language models (which achieve strong performance in few-shot setups) still suffer from learning surface heuristics (sometimes called dataset biases), a pitfall that zero-shot models don't exhibit.
- Our submission "Block Pruning For Faster Transformers" has also been accepted as a long paper. In this paper, we show how to use block sparsity to obtain both fast and small Transformer models. Our experiments yield models which are 2.4x faster and 74% smaller than BERT on SQuAD.
Last words
😎 🔥 Summer was fun! So many things have happened! We hope you enjoyed reading this blog post and looking forward to share the new projects we're working on. See you in the winter! ❄️

