Few-shot learning in practice: GPT-Neo and the 🤗 Accelerated Inference API







In many Machine Learning applications, the amount of available labeled data is a barrier to producing a high-performing model. The latest developments in NLP show that you can overcome this limitation by providing a few examples at inference time with a large language model - a technique known as Few-Shot Learning. In this blog post, we'll explain what Few-Shot Learning is, and explore how a large language model called GPT-Neo, and the 🤗 Accelerated Inference API, can be used to generate your own predictions.
What is Few-Shot Learning?
Few-Shot Learning refers to the practice of feeding a machine learning model with a very small amount of training data to guide its predictions, like a few examples at inference time, as opposed to standard fine-tuning techniques which require a relatively large amount of training data for the pre-trained model to adapt to the desired task with accuracy.
This technique has been mostly used in computer vision, but with some of the latest Language Models, like EleutherAI GPT-Neo and OpenAI GPT-3, we can now use it in Natural Language Processing (NLP).
In NLP, Few-Shot Learning can be used with Large Language Models, which have learned to perform a wide number of tasks implicitly during their pre-training on large text datasets. This enables the model to generalize, that is to understand related but previously unseen tasks, with just a few examples.
Few-Shot NLP examples consist of three main components:
- Task Description: A short description of what the model should do, e.g. "Translate English to French"
- Examples: A few examples showing the model what it is expected to predict, e.g. "sea otter => loutre de mer"
- Prompt: The beginning of a new example, which the model should complete by generating the missing text, e.g. "cheese => "

Image from Language Models are Few-Shot Learners
Creating these few-shot examples can be tricky, since you need to articulate the “task” you want the model to perform through them. A common issue is that models, especially smaller ones, are very sensitive to the way the examples are written.
An approach to optimize Few-Shot Learning in production is to learn a common representation for a task and then train task-specific classifiers on top of this representation.
OpenAI showed in the GPT-3 Paper that the few-shot prompting ability improves with the number of language model parameters.
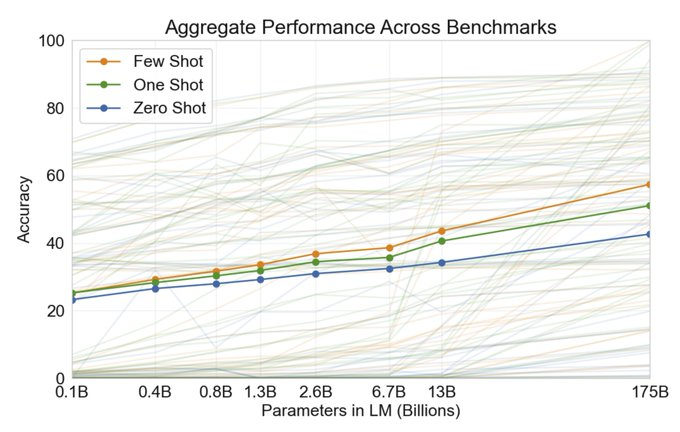
Image from Language Models are Few-Shot Learners
Let's now take a look at how at how GPT-Neo and the 🤗 Accelerated Inference API can be used to generate your own Few-Shot Learning predictions!
What is GPT-Neo?
GPT-Neo is a family of transformer-based language models from EleutherAI based on the GPT architecture. EleutherAI's primary goal is to train a model that is equivalent in size to GPT-3 and make it available to the public under an open license.
All of the currently available GPT-Neo checkpoints are trained with the Pile dataset, a large text corpus that is extensively documented in (Gao et al., 2021). As such, it is expected to function better on the text that matches the distribution of its training text; we recommend keeping this in mind when designing your examples.
🤗 Accelerated Inference API
The Accelerated Inference API is our hosted service to run inference on any of the 10,000+ models publicly available on the 🤗 Model Hub, or your own private models, via simple API calls. The API includes acceleration on CPU and GPU with up to 100x speedup compared to out of the box deployment of Transformers.
To integrate Few-Shot Learning predictions with GPT-Neo in your own apps, you can use the 🤗 Accelerated Inference API with the code snippet below. You can find your API Token here, if you don't have an account you can get started here.
import json
import requests
API_TOKEN = ""
def query(payload='',parameters=None,options={'use_cache': False}):
API_URL = "https://api-inference.huggingface.co/models/EleutherAI/gpt-neo-2.7B"
headers = {"Authorization": f"Bearer {API_TOKEN}"}
body = {"inputs":payload,'parameters':parameters,'options':options}
response = requests.request("POST", API_URL, headers=headers, data= json.dumps(body))
try:
response.raise_for_status()
except requests.exceptions.HTTPError:
return "Error:"+" ".join(response.json()['error'])
else:
return response.json()[0]['generated_text']
parameters = {
'max_new_tokens':25, # number of generated tokens
'temperature': 0.5, # controlling the randomness of generations
'end_sequence': "###" # stopping sequence for generation
}
prompt="...." # few-shot prompt
data = query(prompt,parameters,options)
Practical Insights
Here are some practical insights, which help you get started using GPT-Neo and the 🤗 Accelerated Inference API.
Since GPT-Neo (2.7B) is about 60x smaller than GPT-3 (175B), it does not generalize as well to zero-shot problems and needs 3-4 examples to achieve good results. When you provide more examples GPT-Neo understands the task and takes the end_sequence into account, which allows us to control the generated text pretty well.
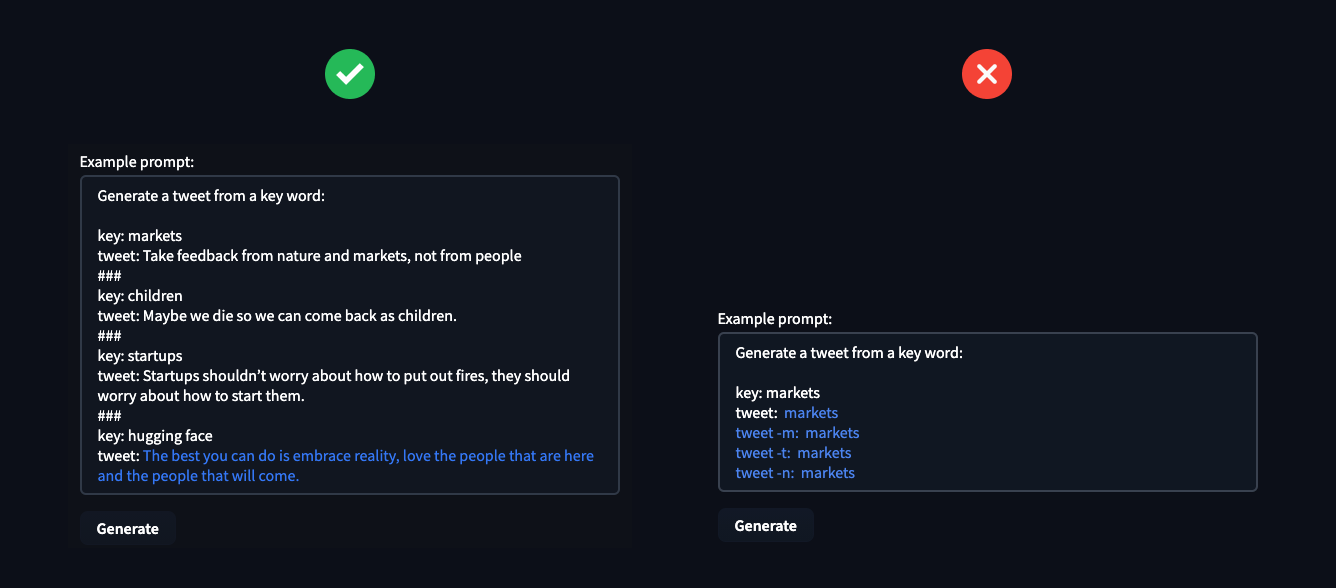
The hyperparameter End Sequence, Token Length & Temperature can be used to control the text-generation of the model and you can use this to your advantage to solve the task you need. The Temperature controlls the randomness of your generations, lower temperature results in less random generations and higher temperature results in more random generations.
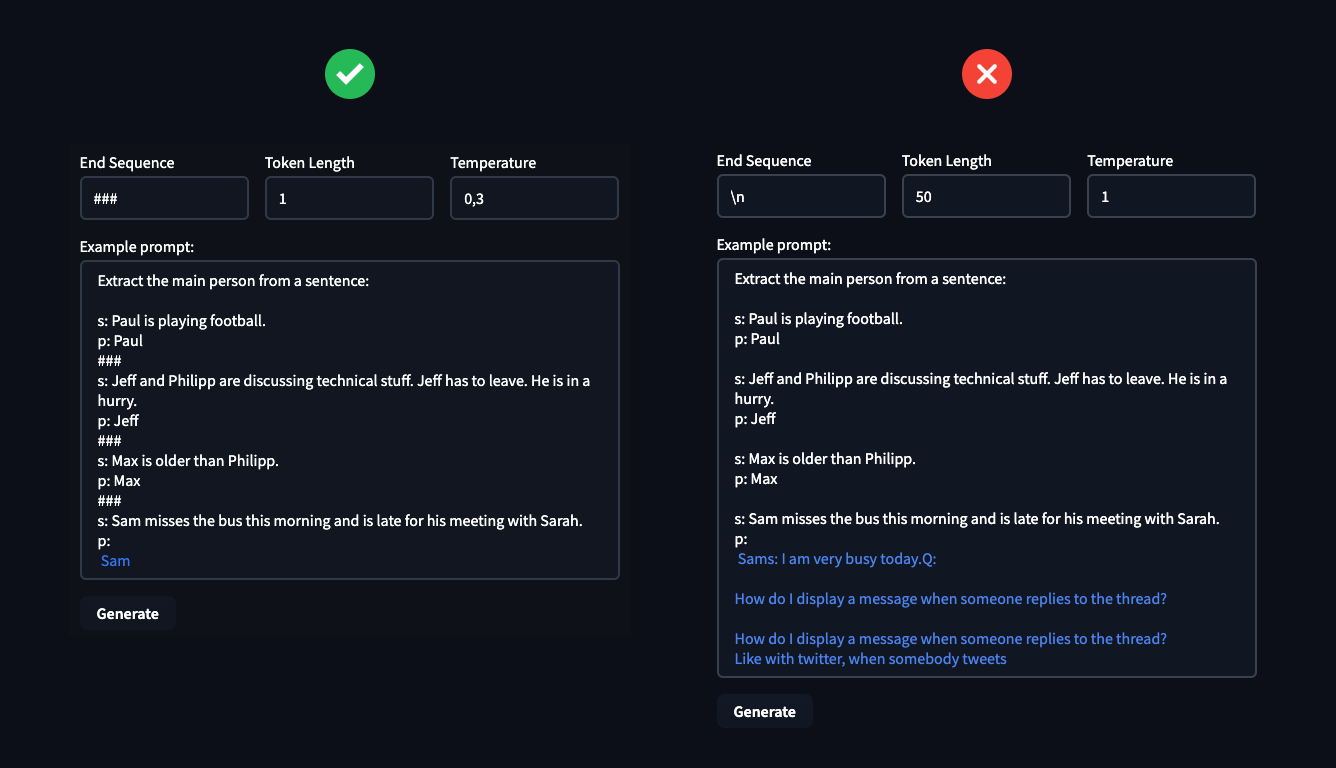
In the example, you can see how important it is to define your hyperparameter. These can make the difference between solving your task or failing miserably.
Responsible Use
Few-Shot Learning is a powerful technique but also presents unique pitfalls that need to be taken into account when designing uses cases.
To illustrate this, let's consider the default Sentiment Analysis setting provided in the widget. After seeing three examples of sentiment classification, the model makes the following predictions 4 times out of 5, with temperature set to 0.1:
Tweet: "I'm a disabled happy person"
Sentiment: Negative
What could go wrong? Imagine that you are using sentiment analysis to aggregate reviews of products on an online shopping website: a possible outcome could be that items useful to people with disabilities would be automatically down-ranked - a form of automated discrimination. For more on this specific issue, we recommend the ACL 2020 paper Social Biases in NLP Models as Barriers for Persons with Disabilities. Because Few-Shot Learning relies more directly on information and associations picked up from pre-training, it makes it more sensitive to this type of failures.
How to minimize the risk of harm? Here are some practical recommendations.
Best practices for responsible use
- Make sure people know which parts of their user experience depend on the outputs of the ML system
- If possible, give users the ability to opt-out
- Provide a mechanism for users to give feedback on the model decision, and to override it
- Monitor feedback, especially model failures, for groups of users that may be disproportionately affected
What needs most to be avoided is to use the model to automatically make decisions for, or about, a user, without opportunity for a human to provide input or correct the output. Several regulations, such as GDPR in Europe, require that users be provided an explanation for automatic decisions made about them.
To use GPT-Neo or any Hugging Face model in your own application, you can start a free trial of the 🤗 Accelerated Inference API. If you need help mitigating bias in models and AI systems, or leveraging Few-Shot Learning, the 🤗 Expert Acceleration Program can offer your team direct premium support from the Hugging Face team.


