Introducing 🤗 Optimum: The Optimization Toolkit for Transformers at Scale






This post is the first step of a journey for Hugging Face to democratize state-of-the-art Machine Learning production performance. To get there, we will work hand in hand with our Hardware Partners, as we have with Intel below. Join us in this journey, and follow Optimum, our new open source library!
Why 🤗 Optimum?
🤯 Scaling Transformers is hard
What do Tesla, Google, Microsoft and Facebook all have in common? Well many things, but one of them is they all run billions of Transformer model predictions every day. Transformers for AutoPilot to drive your Tesla (lucky you!), for Gmail to complete your sentences, for Facebook to translate your posts on the fly, for Bing to answer your natural language queries.
Transformers have brought a step change improvement in the accuracy of Machine Learning models, have conquered NLP and are now expanding to other modalities starting with Speech and Vision. But taking these massive models into production, and making them run fast at scale is a huge challenge for any Machine Learning Engineering team.
What if you don’t have hundreds of highly skilled Machine Learning Engineers on payroll like the above companies? Through Optimum, our new open source library, we aim to build the definitive toolkit for Transformers production performance, and enable maximum efficiency to train and run models on specific hardware.
🏭 Optimum puts Transformers to work
To get optimal performance training and serving models, the model acceleration techniques need to be specifically compatible with the targeted hardware. Each hardware platform offers specific software tooling, features and knobs that can have a huge impact on performance. Similarly, to take advantage of advanced model acceleration techniques like sparsity and quantization, optimized kernels need to be compatible with the operators on silicon, and specific to the neural network graph derived from the model architecture. Diving into this 3-dimensional compatibility matrix and how to use model acceleration libraries is daunting work, which few Machine Learning Engineers have experience on.
Optimum aims to make this work easy, providing performance optimization tools targeting efficient AI hardware, built in collaboration with our Hardware Partners, and turn Machine Learning Engineers into ML Optimization wizards.
With the Transformers library, we made it easy for researchers and engineers to use state-of-the-art models, abstracting away the complexity of frameworks, architectures and pipelines.
With the Optimum library, we are making it easy for engineers to leverage all the available hardware features at their disposal, abstracting away the complexity of model acceleration on hardware platforms.
🤗 Optimum in practice: how to quantize a model for Intel Xeon CPU
🤔 Why quantization is important but tricky to get right
Pre-trained language models such as BERT have achieved state-of-the-art results on a wide range of natural language processing tasks, other Transformer based models such as ViT and Speech2Text have achieved state-of-the-art results on computer vision and speech tasks respectively: transformers are everywhere in the Machine Learning world and are here to stay.
However, putting transformer-based models into production can be tricky and expensive as they need a lot of compute power to work. To solve this many techniques exist, the most popular being quantization. Unfortunately, in most cases quantizing a model requires a lot of work, for many reasons:
- The model needs to be edited: some ops need to be replaced by their quantized counterparts, new ops need to be inserted (quantization and dequantization nodes), and others need to be adapted to the fact that weights and activations will be quantized.
This part can be very time-consuming because frameworks such as PyTorch work in eager mode, meaning that the changes mentioned above need to be added to the model implementation itself.
PyTorch now provides a tool called torch.fx that allows you to trace and transform your model without having to actually change the model implementation, but it is tricky to use when tracing is not supported for your model out of the box.
On top of the actual editing, it is also necessary to find which parts of the model need to be edited, which ops have an available quantized kernel counterpart and which ops don't, and so on.
Once the model has been edited, there are many parameters to play with to find the best quantization settings:
- Which kind of observers should I use for range calibration?
- Which quantization scheme should I use?
- Which quantization related data types (int8, uint8, int16) are supported on my target device?
Balance the trade-off between quantization and an acceptable accuracy loss.
Export the quantized model for the target device.
Although PyTorch and TensorFlow made great progress in making things easy for quantization, the complexities of transformer based models makes it hard to use the provided tools out of the box and get something working without putting up a ton of effort.
💡 How Intel is solving quantization and more with Neural Compressor
Intel® Neural Compressor (formerly referred to as Low Precision Optimization Tool or LPOT) is an open-source python library designed to help users deploy low-precision inference solutions. The latter applies low-precision recipes for deep-learning models to achieve optimal product objectives, such as inference performance and memory usage, with expected performance criteria. Neural Compressor supports post-training quantization, quantization-aware training and dynamic quantization. In order to specify the quantization approach, objective and performance criteria, the user must provide a configuration yaml file specifying the tuning parameters. The configuration file can either be hosted on the Hugging Face's Model Hub or can be given through a local directory path.
🔥 How to easily quantize Transformers for Intel Xeon CPUs with Optimum
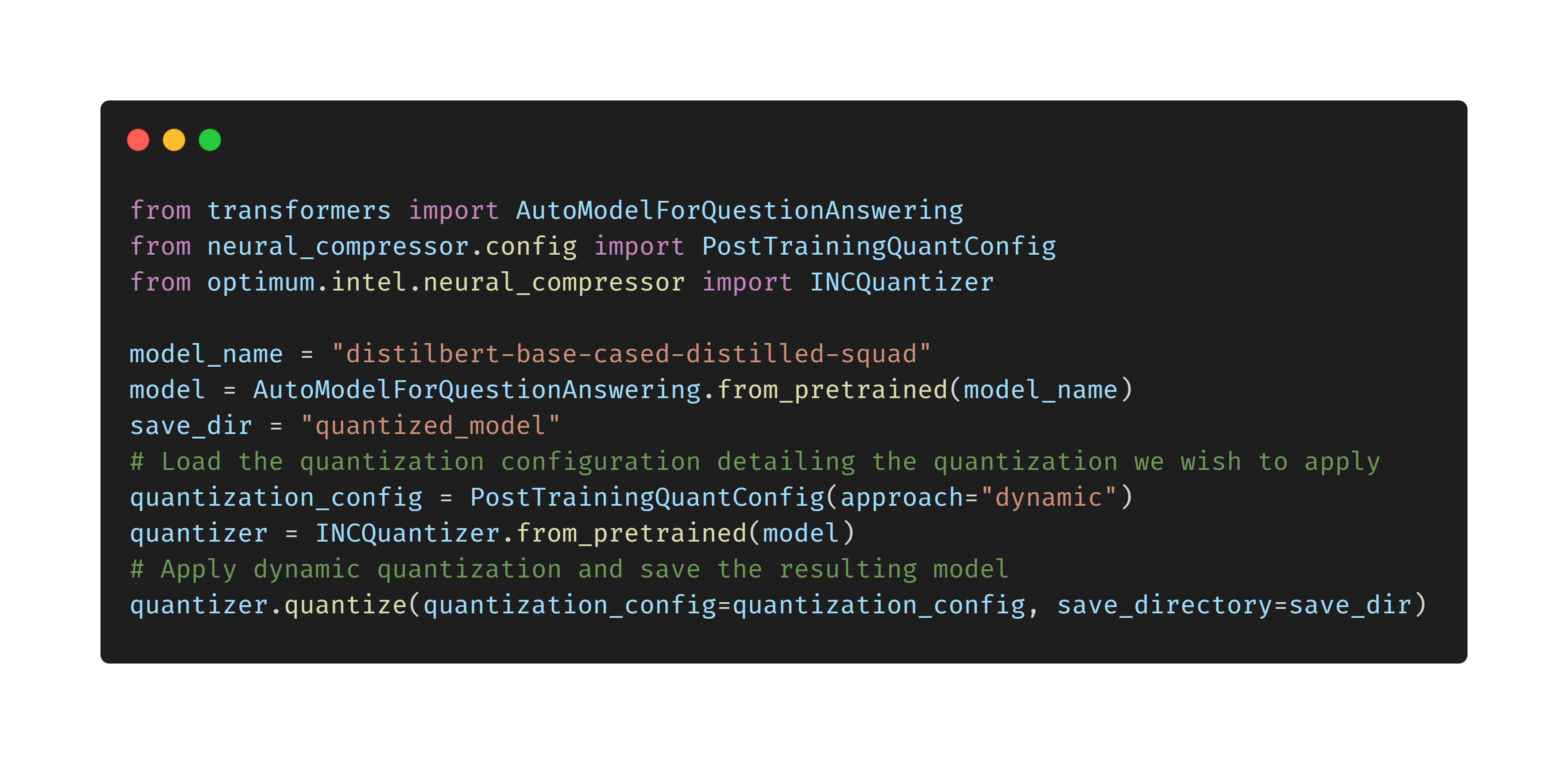
Follow 🤗 Optimum: a journey to democratize ML production performance
⚡️State of the Art Hardware
Optimum will focus on achieving optimal production performance on dedicated hardware, where software and hardware acceleration techniques can be applied for maximum efficiency. We will work hand in hand with our Hardware Partners to enable, test and maintain acceleration, and deliver it in an easy and accessible way through Optimum, as we did with Intel and Neural Compressor. We will soon announce new Hardware Partners who have joined us on our journey toward Machine Learning efficiency.
🔮 State-of-the-Art Models
The collaboration with our Hardware Partners will yield hardware-specific optimized model configurations and artifacts, which we will make available to the AI community via the Hugging Face Model Hub. We hope that Optimum and hardware-optimized models will accelerate the adoption of efficiency in production workloads, which represent most of the aggregate energy spent on Machine Learning. And most of all, we hope that Optimum will accelerate the adoption of Transformers at scale, not just for the biggest tech companies, but for all of us.
🌟 A journey of collaboration: join us, follow our progress
Every journey starts with a first step, and ours was the public release of Optimum. Join us and make your first step by giving the library a Star, so you can follow along as we introduce new supported hardware, acceleration techniques and optimized models.
If you would like to see new hardware and features be supported in Optimum, or you are interested in joining us to work at the intersection of software and hardware, please reach out to us at hardware@huggingface.co







