
[Trimming] SigLIP2
Collection
Collection of trimmed Google's SigLIP2 models. The models are sorted alphabetically. • 536 items • Updated
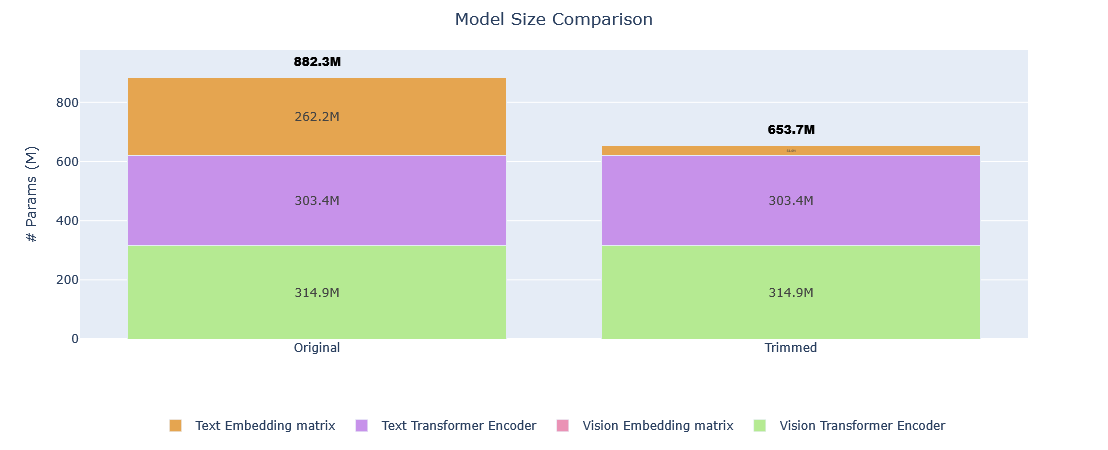
This model is a 25.91% smaller version of google/siglip2-large-patch16-512 optimized for Bengali language via vocabulary size reduction using the trimming method.
This trimmed model should perform similarly to the original model with only 32,768 tokens and a much smaller memory footprint. However, it may not perform well for other languages as tokens not commonly used in the selected languages were removed from the vocabulary.
| Metric | Original | Trimmed | Reduction |
|---|---|---|---|
| Vocabulary size | 256,000 tokens | 32,768 tokens | 87.20% |
| Model size | 882,313,218 params | 653,723,650 params | 25.91% |
from transformers import pipeline
# load pipeline
image_classifier = pipeline(model="alphaedge-ai/siglip2-large-patch16-512-ben-32768", task="zero-shot-image-classification")
# load image and candidate labels
image = "http://images.cocodataset.org/val2017/000000039769.jpg"
candidate_labels = ["Potential label 1 in Bengali", "Potential label 2 in Bengali", "Potential label 3 in Bengali", "Potential label 4 in Bengali"]
# run inference
outputs = image_classifier(image, candidate_labels)
print(outputs)
from sentence_transformers import SentenceTransformer
model = SentenceTransformer("alphaedge-ai/siglip2-large-patch16-512-ben-32768")
images = [
"https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/tasks/car.jpg",
"https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/bee.jpg",
"https://huggingface.co/datasets/huggingface/cats-image/resolve/main/cats_image.jpeg"
]
texts = ["Text 1 in Bengali", "Text 2 in Bengali", "Text 3 in Bengali", "Text 4 in Bengali"]
image_embeddings = model.encode(images)
text_embeddings = model.encode(texts)
print(image_embeddings.shape, text_embeddings.shape)
similarities = model.similarity(image_embeddings, text_embeddings)
print(similarities)
@misc{tschannen2025siglip2multilingualvisionlanguage,
title={SigLIP 2: Multilingual Vision-Language Encoders with Improved Semantic Understanding, Localization, and Dense Features},
author={Michael Tschannen and Alexey Gritsenko and Xiao Wang and Muhammad Ferjad Naeem and Ibrahim Alabdulmohsin and Nikhil Parthasarathy and Talfan Evans and Lucas Beyer and Ye Xia and Basil Mustafa and Olivier Hénaff and Jeremiah Harmsen and Andreas Steiner and Xiaohua Zhai},
year={2025},
eprint={2502.14786},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2502.14786},
}
@misc{hf_blogpost_trimming,
title={Introduction to Trimming},
author={Loïck BOURDOIS and Tom AARSEN and Bram VANROY and Christopher AKIKI and Woojun JUNG and Manuel ROMERO and Prithiv SAKTHI},
year={2026},
url={https://huggingface.co/blog/lbourdois/introduction-to-trimming},
}
Base model
google/siglip2-large-patch16-512