
[Trimming] Qwen3 Embedding 0.6B
Collection
Collection of trimmed Qwen's Qwen3-Embedding-0.6B models. The models are sorted alphabetically. • 166 items • Updated • 1
This model is a 23.25% smaller version of Qwen/Qwen3-Embedding-0.6B optimized for Assamese language via vocabulary size reduction using the trimming method.
This trimmed model should perform similarly to the original model with only 16,384 tokens and a much smaller memory footprint. However, it may not perform well for other languages as tokens not commonly used in the selected languages were removed from the vocabulary.
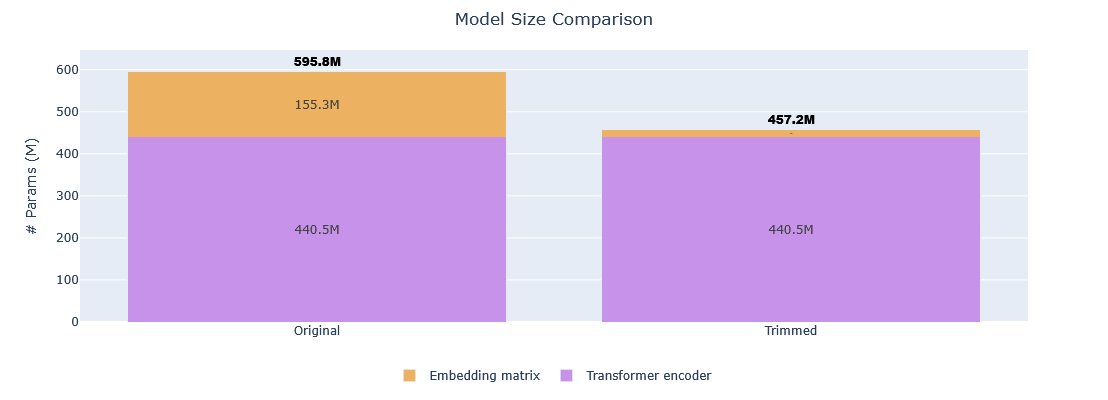
| Metric | Original | Trimmed | Reduction |
|---|---|---|---|
| Vocabulary size | 151,669 tokens | 16,384 tokens | 89.20% |
| Model size | 595,776,512 params | 457,244,672 params | 23.25% |
from sentence_transformers import SentenceTransformer
# Download from the 🤗 Hub
model = SentenceTransformer("alphaedge-ai/Qwen3-Embedding-asm-16384")
# Run inference with queries and documents
query = "My query in Assamese"
documents = [
"Chunk in Assamese",
"Chunk in Assamese",
"Chunk in Assamese",
]
query_embeddings = model.encode_query(query)
document_embeddings = model.encode_document(documents)
print(query_embeddings.shape, document_embeddings.shape)
# Compute similarities to determine a ranking
similarities = model.similarity(query_embeddings, document_embeddings)
print(similarities)
@article{qwen3embedding,
title={Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models},
author={Zhang, Yanzhao and Li, Mingxin and Long, Dingkun and Zhang, Xin and Lin, Huan and Yang, Baosong and Xie, Pengjun and Yang, An and Liu, Dayiheng and Lin, Junyang and Huang, Fei and Zhou, Jingren},
journal={arXiv preprint arXiv:2506.05176},
year={2025}
}
@misc{hf_blogpost_trimming,
title={Introduction to Trimming},
author={Loïck BOURDOIS and Tom AARSEN and Bram VANROY and Christopher AKIKI and Woojun JUNG and Manuel ROMERO and Prithiv SAKTHI},
year={2026},
url={https://huggingface.co/blog/lbourdois/introduction-to-trimming},
}