
[Trimming] ModernBERT
Collection
Collection of trimmed Answer.AI's modernBERT models. The models are sorted alphabetically. • 4 items • Updated
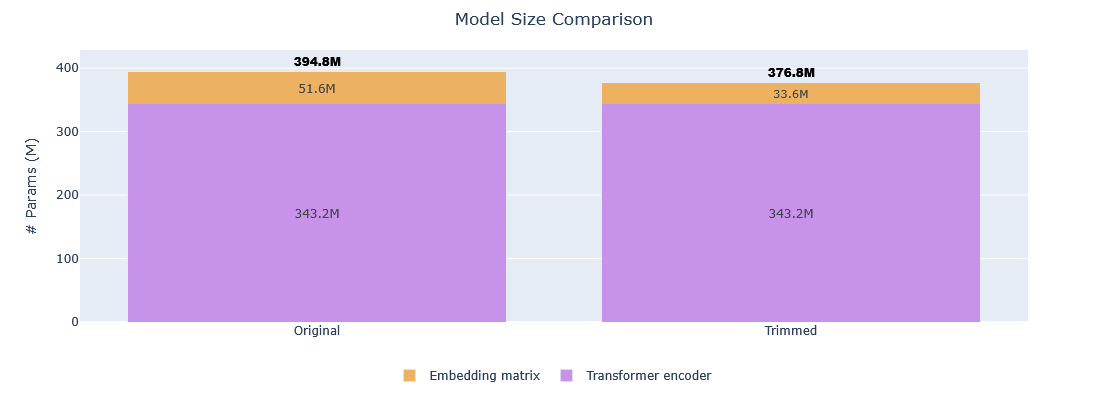
This model is a 4.56% smaller version of answerdotai/ModernBERT-large optimized for English language via vocabulary size reduction using the trimming method.
This trimmed model should perform similarly to the original model with only 32,768 tokens and a much smaller memory footprint.
| Metric | Original | Trimmed | Reduction |
|---|---|---|---|
| Vocabulary size | 50,368 | 32,768 | 34.94% |
| Model size | 395,881,664 params | 377,841,664 params | 4.56% |
from transformers import AutoModel, AutoTokenizer
model_name = "alphaedge-ai/ModernBERT-large-32768"
model = AutoModel.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)
@misc{modernbert,
title={Smarter, Better, Faster, Longer: A Modern Bidirectional Encoder for Fast, Memory Efficient, and Long Context Finetuning and Inference},
author={Benjamin Warner and Antoine Chaffin and Benjamin Clavié and Orion Weller and Oskar Hallström and Said Taghadouini and Alexis Gallagher and Raja Biswas and Faisal Ladhak and Tom Aarsen and Nathan Cooper and Griffin Adams and Jeremy Howard and Iacopo Poli},
year={2024},
eprint={2412.13663},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2412.13663},
}
@misc{hf_blogpost_trimming,
title={Introduction to Trimming},
author={Loïck BOURDOIS and Tom AARSEN and Bram VANROY and Christopher AKIKI and Woojun JUNG and Manuel ROMERO and Prithiv SAKTHI},
year={2026},
url={https://huggingface.co/blog/lbourdois/introduction-to-trimming},
}
Base model
answerdotai/ModernBERT-large