
Kámárí Gemma Explanation LoRA (v0)
A QLoRA adapter for google/gemma-4-E4B-it that turns Kámárí's CNN + policy signals into a safe,
multilingual, strict-JSON explanation. Gemma explains a decision; it never estimates age and
never invents a reason code.
- LoRA r=32, alpha 64,
target_modules="all-linear", 4-bit nf4 QLoRA, 3 epochs on H200. - Output schema:
decision, reason_code, user_message, admin_summary, next_step, language, safety_note. Reason codes come from a fixed list.
Intended use
Input: {cnn_result, policy_context:{decision, reason_code, legal_threshold, challenge_threshold}, language}. Output: one strict-JSON object with the message in the requested language. Languages in
the SFT set: en, sw, yo, ha, am, fr, ar (more in the app picker). Non-English strings should get
native-speaker review before release.
Training data
Synthesized from the Kámárí policy engine, not from child faces: sampled signals run through the same
decide() rules, and approved per-reason, per-language templates render the message. The set is
reason-code balanced (so it is not dominated by ALLOW): 8,000 rows, 7,200 train / 800 eval.
Evaluation
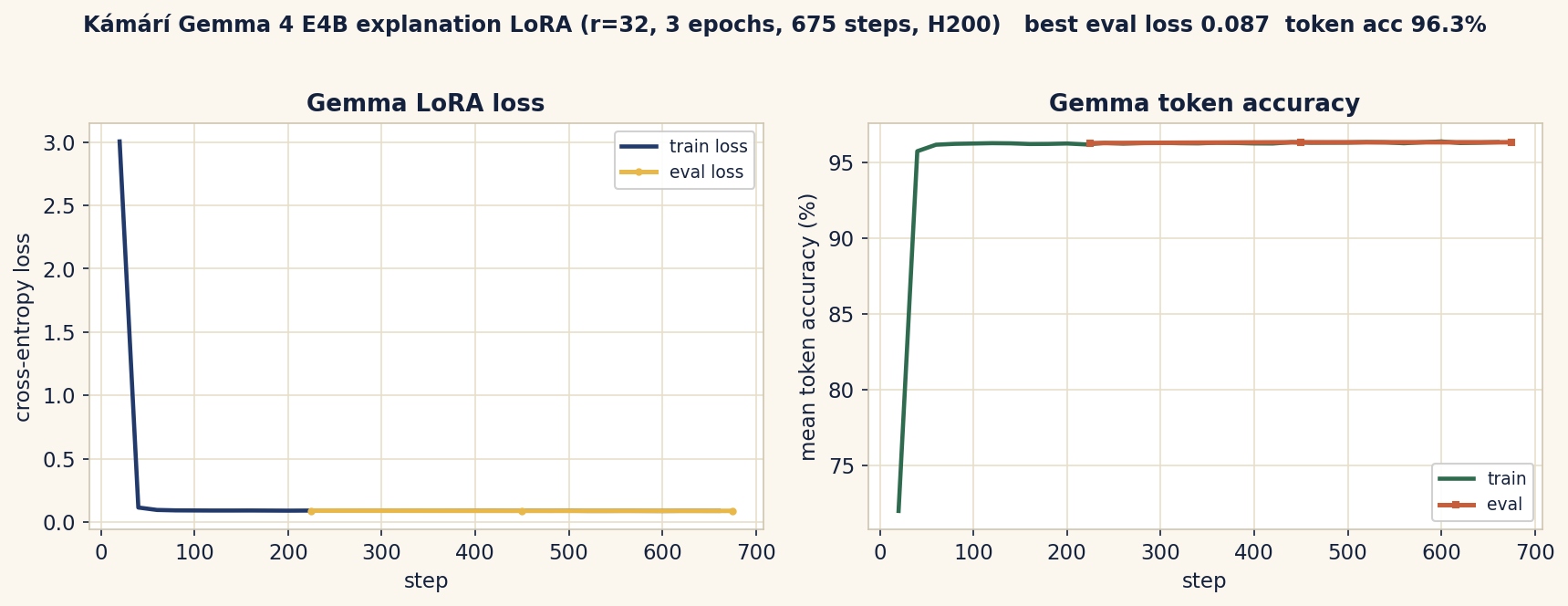
Training loss converged from 3.00 to a best eval loss of 0.087, at 96.3% eval token accuracy
(3 epochs / 675 steps, about 35 minutes on an H200; tracked in Weights & Biases, project kamari).
Evaluated through the served
endpoint (the manual KV-cached greedy decode used in production, not the buggy generate() path),
over n=70 cases across 5 reason codes and 7 languages (en, sw, yo, ha, am, fr, ar):
| Metric | Value |
|---|---|
| JSON validity | 1.00 |
| Schema compliance | 1.00 |
| Decision consistency | 1.00 |
| Policy consistency (reason code) | 1.00 |
| Language correctness | 1.00 |
| Invented-code rate (lower is better) | 0.00 |
The endpoint validates output and falls back to an approved template on any model failure, so the
system always returns valid, schema-correct, policy-consistent JSON; language correctness reflects
in-language generation by the model. (An earlier v0 eval showed 0.0 across the board because it ran
through the buggy generate() path; those numbers are superseded.) Non-English strings still benefit
from a native review.
Training curves
Pulled from the Weights & Biases run (project kamari, run gemma4b-lora-r32). Cross-entropy loss
converges from 3.00 to a best eval loss of 0.087, and mean token accuracy rises to 96.3%, with train
and eval tracking closely across 675 steps (3 epochs).
Serving
Load base Gemma 4 + this adapter, merge_and_unload(), and decode greedily token by token (avoid
generate()). On any validation failure, return a deterministic safe fallback so the caller always
gets valid JSON. Served on a Modal L4 GPU, always-on.
Methodology: https://github.com/Mystique1337/kamari/blob/main/docs/methodology.md
License
Apache-2.0. Every output carries: this is an estimate, not a legal age determination.
Links
- Code (Apache-2.0): https://github.com/Mystique1337/kamari
- Live demo: https://kamari.shinzii.tech
- Methodology: https://github.com/Mystique1337/kamari/blob/main/docs/methodology.md
- Downloads last month
- 25