
Stream3D-VLM: Online 3D Spatial Understanding with Incremental Geometry Priors
Paper • 2606.06891 • Published • 4
![]()
Stream3D-VLM is an online 3D vision-language model that supports real-time spatial understanding and interaction directly from streaming video. Unlike existing 3D Large Multimodal Models that operate in offline settings and require complete scene observations or predefined video clips, Stream3D-VLM enables efficient and continuous 3D scene comprehension without offline processing.
To address the scarcity of streaming 3D–language data, we develop a scalable data generation pipeline that curates over 1M online spatio-temporal 3D QA pairs (Stream3D-1M) and establish a comprehensive benchmark with 10,000 QA samples, spanning 29 subtasks across 5 cognitive competencies and 3 temporal interaction modes (Stream3D-Bench).
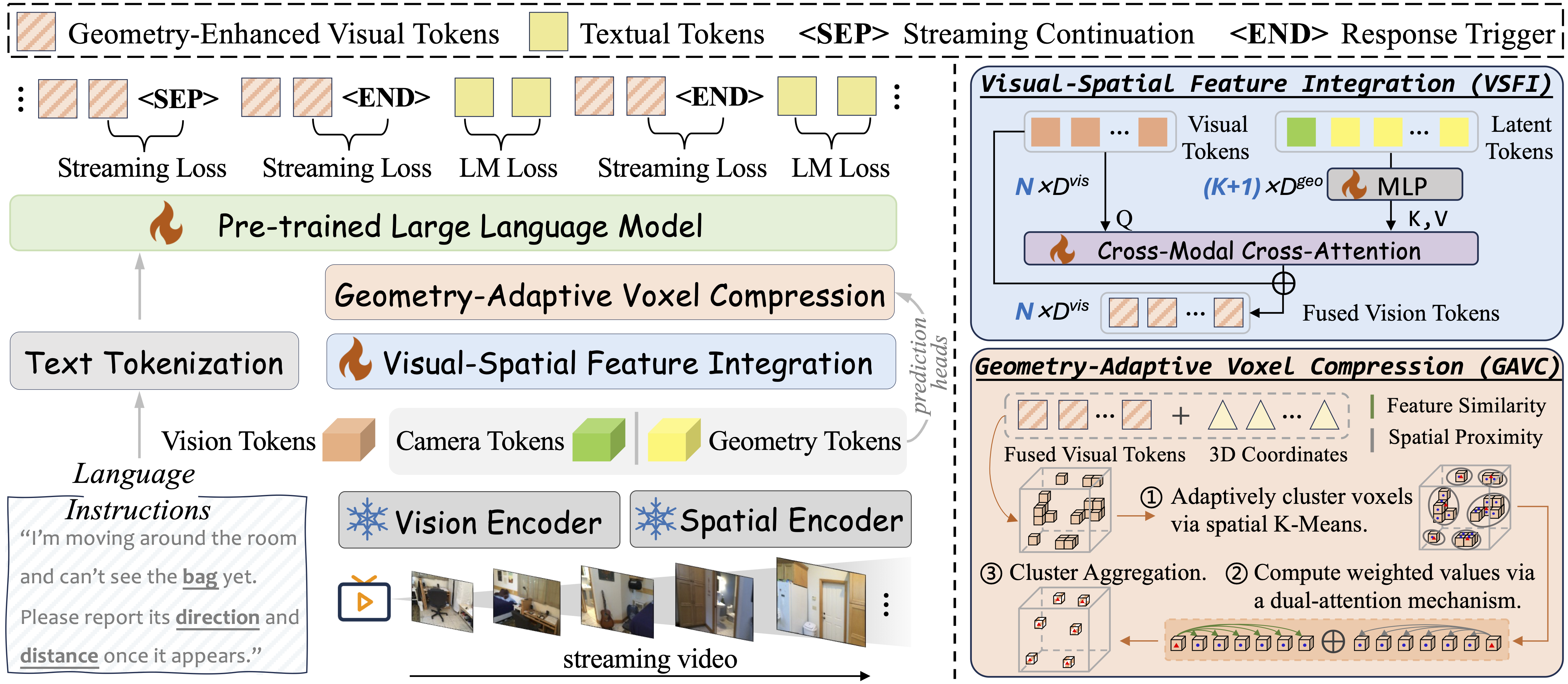
Online 3D Spatial Understanding: Real-time spatial reasoning from streaming video without requiring full scene reconstruction upfront.
Incremental Geometry Priors: The VSFI module injects temporally aligned geometric features from a 3D reconstruction model into the visual stream as video unfolds.
Streaming Control Modeling: Learns when to respond or remain silent via joint optimization of streaming control loss and standard language modeling loss.
Efficient Long-Context Inference: The plug-and-play GAVC module dynamically compresses visual tokens guided by 3D structure, reducing decoding overhead for real-time deployment.
Comprehensive Benchmark: Stream3D-Bench covers Forward Response (monitoring), Realtime Perception (observation), and Backward Tracing (memory) across diverse spatio-temporal 3D tasks.
Stream3D-VLM consistently outperforms competing proprietary and open-source models on Stream3D-Bench, delivering the most accurate response timing and the lowest inference latency. Results are reported under a 1 fps streaming video setting. NA / MCA / OEA denote numerical, multiple-choice, and open-ended answers, respectively.
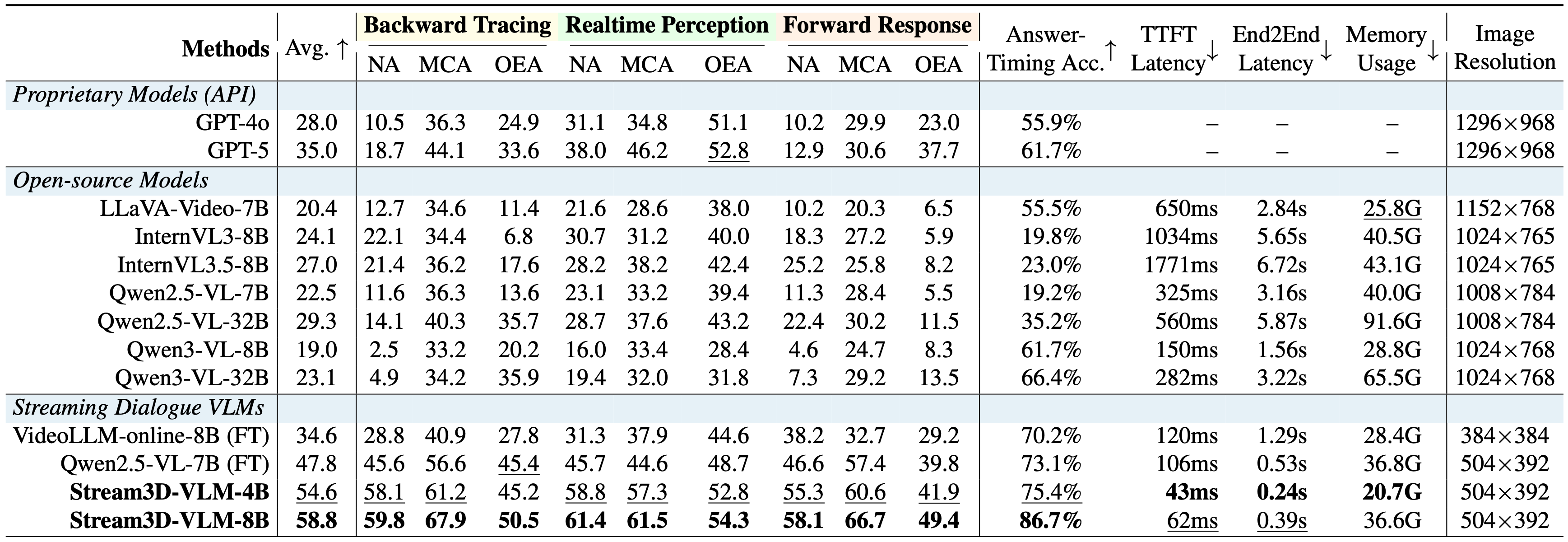
Bold and underlined values indicate the best and second-best results, respectively. More details can be found on our paper.
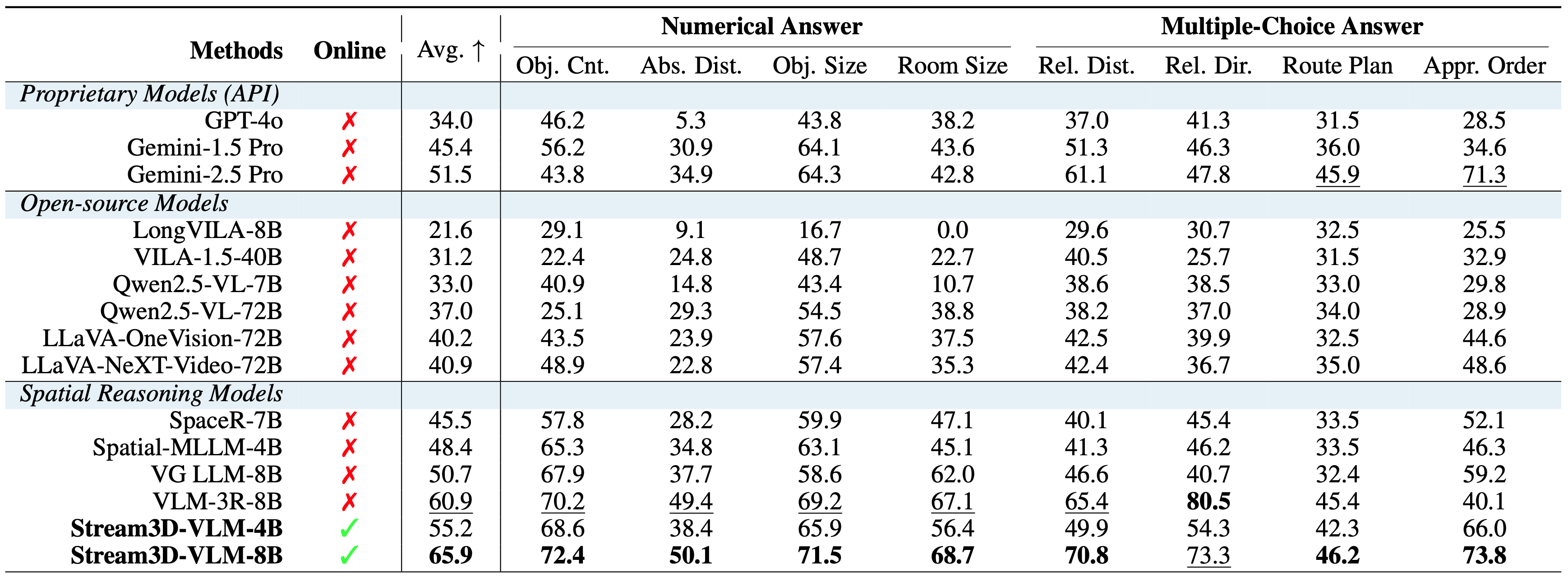
Despite being designed for streaming scenarios, Stream3D-VLM also performs well across all subtasks of the offline spatial perception and reasoning benchmark, significantly surpassing both commercial and open-source models.
| Resource | Link |
|---|---|
| Training Dataset | JonnyYu828/Stream3D-1M-Dataset |
| Benchmark | JonnyYu828/Stream3D-Bench |
| Code | hanxunyu/Stream3D-VLM |
| Project Page | stream3d-vlm.github.io |
If you find Stream3D-VLM useful for your research or applications, please consider citing our work using the following BibTeX:
@article{yu2026stream3d,
title={Stream3D-VLM: Online 3D Spatial Understanding with Incremental Geometry Priors},
author={Hanxun Yu and Xuan Qu and Lei Ke and Boqiang Zhang and Yuxin Wang and Jianke Zhu and Dong Yu},
journal={arXiv preprint arXiv:2606.06891},
year={2026}
}
Base model
Qwen/Qwen2.5-VL-3B-Instruct