
PaddleOCR-VL-1.5: Towards a Multi-Task 0.9B VLM for Robust In-the-Wild Document Parsing
Paper • 2601.21957 • Published • 23
PP-DocLayoutV3 · OpenVINO IR
Layout Analysis Module of PaddleOCR-VL-1.5 — converted to OpenVINO™ IR for local inference on Intel CPU / GPU / NPU

This repository hosts the OpenVINO™ IR build of PP-DocLayoutV3, the layout-analysis module of
PaddleOCR-VL-1.5. The original PaddlePaddle weights have been converted to OpenVINO Intermediate
Representation (inference.xml + inference.bin) so the model runs fully locally on Intel CPU,
integrated/discrete GPU, and NPU via the OpenVINO runtime — no cloud service and no PaddlePaddle
runtime required.
本仓库提供 PP-DocLayoutV3 的 OpenVINO™ IR 版本,它是 PaddleOCR-VL-1.5 的版面分析(layout)模块。 模型已从 PaddlePaddle 权重转换为 OpenVINO 中间表示(
inference.xml+inference.bin),可在 Intel CPU / 集显 / 独显 / NPU 上完全本地运行,无需联网、无需安装 PaddlePaddle。
PP-DocLayoutV3 is specifically engineered to handle non-planar document images. It directly predicts multi-point bounding boxes for layout elements (rather than standard two-point boxes) and determines the logical reading order for skewed and curved surfaces within a single forward pass, significantly reducing cascading errors. It is an essential component of PaddleOCR-VL-1.5, providing the layout analysis that drives high-precision parsing of real-world documents.
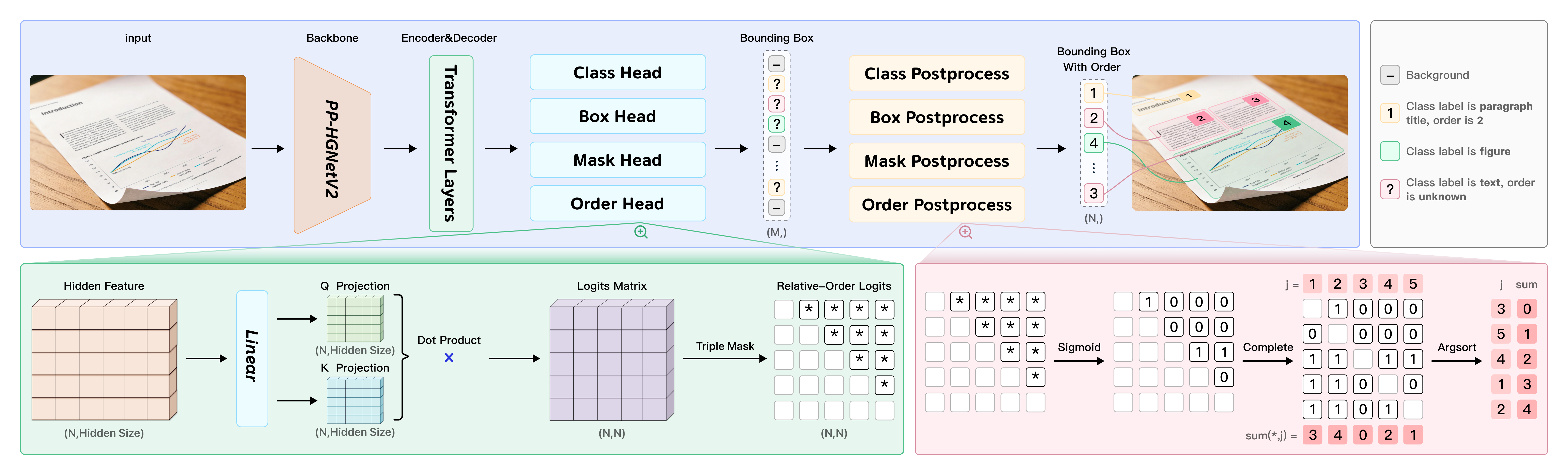
| File | Description |
|---|---|
inference.xml |
OpenVINO IR network topology |
inference.bin |
OpenVINO IR weights |
inference.yml |
Preprocessing config (resize 800×800, normalization) + 25-class label list + draw_threshold |
config.json |
Model config |
preprocessor_config.json |
Image-processor config |
image [1, 3, 800, 800] (BGR, resized to 800×800, no keep-ratio) + scale_factor [1, 2]0.5 (draw_threshold in inference.yml)This model is the layout stage of an end-to-end document-parsing pipeline. Pair it with
FionaGu1019/PaddleOCR-VL-1.5-ov
(the recognition VLM) to get layout detection → reading order → text/table/formula recognition.
from modelscope import snapshot_download
# Download both stages of the pipeline
layout_dir = snapshot_download("FionaGu1019/PP-DocLayoutV3-ov")
vl_dir = snapshot_download("FionaGu1019/PaddleOCR-VL-1.5-ov")
import cv2
import numpy as np
import openvino as ov
model_dir = "PP-DocLayoutV3-ov" # local path or snapshot_download(...) result
core = ov.Core()
compiled = core.compile_model(f"{model_dir}/inference.xml", "GPU") # "CPU" / "GPU" / "NPU"
# Preprocess: resize to 800x800 (no keep-ratio), CHW, float32
img = cv2.imread("document.jpg")
h, w = img.shape[:2]
resized = cv2.resize(img, (800, 800), interpolation=cv2.INTER_LINEAR)
blob = resized.astype(np.float32).transpose(2, 0, 1)[None] # [1,3,800,800]
scale_factor = np.array([[800 / h, 800 / w]], dtype=np.float32) # [1,2]
results = compiled({"image": blob, "scale_factor": scale_factor})
# Outputs are DETR detections (class id, score, box); filter by draw_threshold=0.5
# and map class ids via the label_list in inference.yml.
Tip: enable on-disk kernel caching with
core.set_property({"CACHE_DIR": ".ov_cache"})to avoid re-compiling kernels on every run (a large speedup on GPU).




If you find PP-DocLayoutV3 helpful, feel free to give the original project a star and citation.
@misc{cui2026paddleocrvl15multitask09bvlm,
title={PaddleOCR-VL-1.5: Towards a Multi-Task 0.9B VLM for Robust In-the-Wild Document Parsing},
author={Cheng Cui and Ting Sun and Suyin Liang and Tingquan Gao and Zelun Zhang and Jiaxuan Liu and Xueqing Wang and Changda Zhou and Hongen Liu and Manhui Lin and Yue Zhang and Yubo Zhang and Yi Liu and Dianhai Yu and Yanjun Ma},
year={2026},
eprint={2601.21957},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2601.21957},
}
Base model
PaddlePaddle/PP-DocLayoutV3