
Bielik-7B-v0.1
Collection
A collection of models based on Bielik-7B-v0.1 - base model, instructional and quantized versions, and MLX (Apple).
•
8 items
•
Updated

The Bielik-7B-v0.1 is a generative text model featuring 7 billion parameters, meticulously evolved from its predecessor, the Mistral-7B-v0.1, through processing of over 70 billion tokens. Forementioned model stands as a testament to the unique collaboration between the open-science/open-souce project SpeakLeash and the High Performance Computing (HPC) center: ACK Cyfronet AGH. Developed and trained on Polish text corpora, which has been cherry-picked and processed by the SpeakLeash team, this endeavor leverages Polish large-scale computing infrastructure, specifically within the PLGrid environment, and more precisely, the HPC centers: ACK Cyfronet AGH. The creation and training of the Bielik-7B-v0.1 was propelled by the support of computational grant number PLG/2024/016951, conducted on the Helios supercomputer, enabling the use of cutting-edge technology and computational resources essential for large-scale machine learning processes. As a result, the model exhibits an exceptional ability to understand and process the Polish language, providing accurate responses and performing a variety of linguistic tasks with high precision.
Bielik-7B-v0.1 has been trained with the use of an original open source framework called ALLaMo implemented by Krzysztof Ociepa. This framework allows users to train language models with architecture similar to LLaMA and Mistral in fast and efficient way.
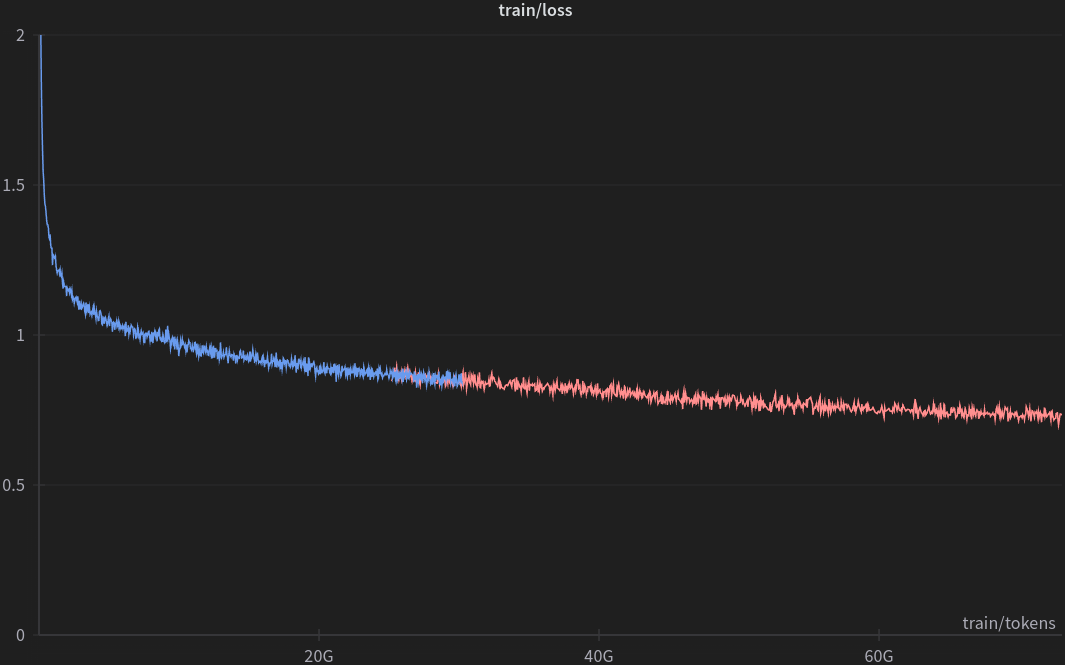
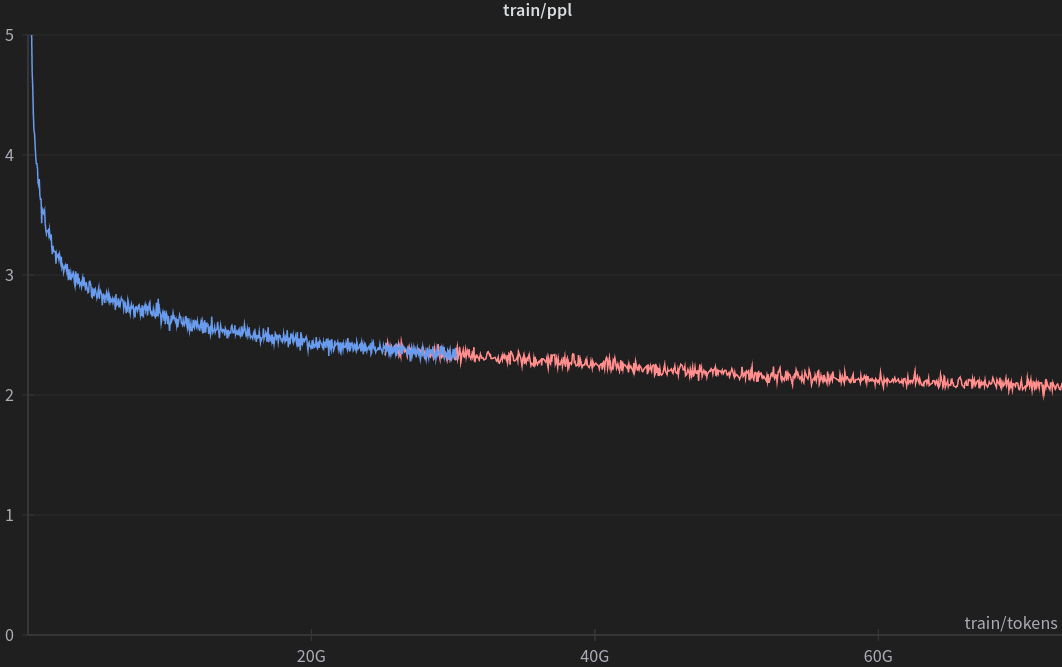
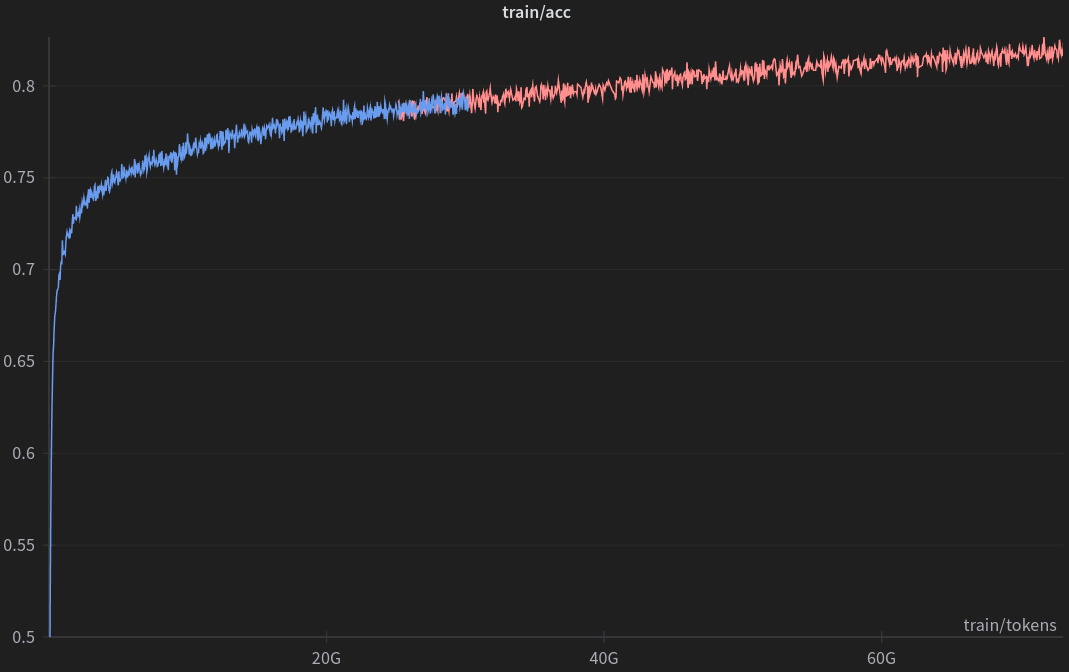
The model training was conducted on the Helios Supercomputer at the ACK Cyfronet AGH, utilizing 256 NVidia GH200 cards while achieving a throughput exceeding 9200 tokens/gpu/second.
The training dataset was composed of Polish texts collected and made available through the SpeakLeash project. We used over 36 billion tokens for two epochs of training.
A XGBoost classification model was prepared and created to evaluate the quality of texts in native Polish language. It is based on 93 features, such as the ratio of out-of-vocabulary words to all words (OOVs), the number of nouns, verbs, average sentence length etc. The model outputs the category of a given document (either HIGH, MEDIUM or LOW) along with the probability. This approach allows implementation of dedicated pipeline to choose documents, from which we've used entries with HIGH quality index and probability exceeding 90%.
This filtration and appropriate selection of texts enable the provision of a condensed and high-quality database of texts in Polish for training purposes.
| Hyperparameter | Value |
|---|---|
| Context length | 4096 |
| Micro Batch Size | 4 |
| Batch Size | 4194304 |
| Learning Rate (cosine) | 3e-05 -> 2e-05 |
| Warmup Iterations | 2000 |
| All Iterations | 17350 |
| Optimizer | AdamW |
| β1, β2 | 0.9, 0.95 |
| Adam_eps | 1e−8 |
| Weight Decay | 0.1 |
| Grad Clip | 1.0 |
| Precision | bfloat16 (mixed) |
This model can be easily loaded using the AutoModelForCausalLM functionality.
from transformers import AutoTokenizer, AutoModelForCausalLM
model_name = "speakleash/Bielik-7B-v0.1"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
In order to reduce the memory usage, you can use smaller precision (bfloat16).
import torch
model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype=torch.bfloat16)
And then you can use Hugging Face Pipelines to generate text:
import transformers
text = "Najważniejszym celem człowieka na ziemi jest"
pipeline = transformers.pipeline("text-generation", model=model, tokenizer=tokenizer)
sequences = pipeline(max_new_tokens=100, do_sample=True, top_k=50, eos_token_id=tokenizer.eos_token_id, text_inputs=text)
for seq in sequences:
print(f"Result: {seq['generated_text']}")
Generated output:
Najważniejszym celem człowieka na ziemi jest życie w pokoju, harmonii i miłości. Dla każdego z nas bardzo ważne jest, aby otaczać się kochanymi osobami.
Models have been evaluated on Open PL LLM Leaderboard 5-shot. The benchmark evaluates models in NLP tasks like sentiment analysis, categorization, text classification but does not test chatting skills. Here are presented:
As of April 3, 2024, the following table showcases the current scores of pretrained and continuously pretrained models according to the Open PL LLM Leaderboard, evaluated in a 5-shot setting:
| Average | RAG Reranking | RAG Reader | Perplexity | |
|---|---|---|---|---|
| 7B parameters models: | ||||
| Baseline (majority class) | 0.00 | 53.36 | - | - |
| OPI-PG/Qra-7b | 11.13 | 54.40 | 75.25 | 203.36 |
| meta-llama/Llama-2-7b-hf | 12.73 | 54.02 | 77.92 | 850.45 |
| internlm/internlm2-base-7b | 20.68 | 52.39 | 69.85 | 3110.92 |
| Bielik-7B-v0.1 | 29.38 | 62.13 | 88.39 | 123.31 |
| mistralai/Mistral-7B-v0.1 | 30.67 | 60.35 | 85.39 | 857.32 |
| internlm/internlm2-7b | 33.03 | 69.39 | 73.63 | 5498.23 |
| alpindale/Mistral-7B-v0.2-hf | 33.05 | 60.23 | 85.21 | 932.60 |
| speakleash/mistral-apt3-7B/spi-e0_hf (experimental) | 35.50 | 62.14 | 87.48 | 132.78 |
| Models with different sizes: | ||||
| sdadas/polish-gpt2-xl (1.7B) | -23.22 | 48.07 | 3.04 | 160.95 |
| Azurro/APT3-1B-Base (1B) | -8.23 | 51.49 | 18.94 | 249.90 |
| OPI-PG/Qra-1b (1B) | -5.44 | 47.65 | 38.51 | 398.96 |
| internlm/internlm2-1_8b (1.8B) | -2.78 | 49.37 | 31.88 | 60296.30 |
| OPI-PG/Qra-13b (13B) | 29.03 | 53.28 | 83.03 | 168.66 |
| upstage/SOLAR-10.7B-v1.0 (10.7B) | 38.12 | 75.81 | 86.39 | 641.05 |
| Polish instruction fine-tuned models: | ||||
| szymonrucinski/Curie-7B-v1 | 26.72 | 55.58 | 85.19 | 389.17 |
| Voicelab/trurl-2-7b | 18.85 | 60.67 | 77.19 | 1098.88 |
| Bielik-7B-Instruct-v0.1 | 39.28 | 61.89 | 86.00 | 277.92 |
As you can see, Bielik-7B-v0.1 does not have the best Average score, but it has some clear advantages, e.g. the best score in the RAG Reader task.
The results in the above table were obtained without utilizing instruction templates for instructional models, instead treating them like base models. This approach could skew the results, as instructional models are optimized with specific instructions in mind.
Bielik-7B-v0.1 is not intended for deployment without fine-tuning. It should not be used for human-facing interactions without further guardrails and user consent.
Bielik-7B-v0.1 can produce factually incorrect output, and should not be relied on to produce factually accurate data. Bielik-7B-v0.1 was trained on various public datasets. While great efforts have been taken to clear the training data, it is possible that this model can generate lewd, false, biased or otherwise offensive outputs.
The model is licensed under Apache 2.0, which allows for commercial use.
Please cite this model using the following format:
@misc{Bielik7Bv01,
title = {Introducing Bielik-7B-v0.1: Polish Language Model},
author = {Ociepa, Krzysztof and Flis, Łukasz and Wróbel, Krzysztof and Gwoździej, Adrian and {SpeakLeash Team} and {Cyfronet Team}},
year = {2024},
url = {https://huggingface.co/speakleash/Bielik-7B-v0.1},
note = {Accessed: 2024-04-01}, % change this date
urldate = {2024-04-01} % change this date
}
The model could not have been created without the commitment and work of the entire SpeakLeash team, whose contribution is invaluable. Thanks to the hard work of many individuals, it was possible to gather a large amount of content in Polish and establish collaboration between the open-science SpeakLeash project and the HPC center: ACK Cyfronet AGH. Individuals who contributed to the creation of the model through their commitment to the open-science SpeakLeash project: Sebastian Kondracki, Maria Filipkowska, Grzegorz Urbanowicz, Szymon Baczyński, Paweł Kiszczak, Igor Ciuciura, Paweł Cyrta, Jacek Chwiła, Jan Maria Kowalski, Karol Jezierski, Kamil Nonckiewicz, Izabela Babis, Nina Babis, Waldemar Boszko, Remigiusz Kinas, Piotr Rybak and many other wonderful researchers and enthusiasts of the AI world.
Members of the ACK Cyfronet AGH team providing valuable support and expertise: Szymon Mazurek.
If you have any questions or suggestions, please use the discussion tab. If you want to contact us directly, join our Discord SpeakLeash.