
Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models
Paper • 2506.05176 • Published • 83
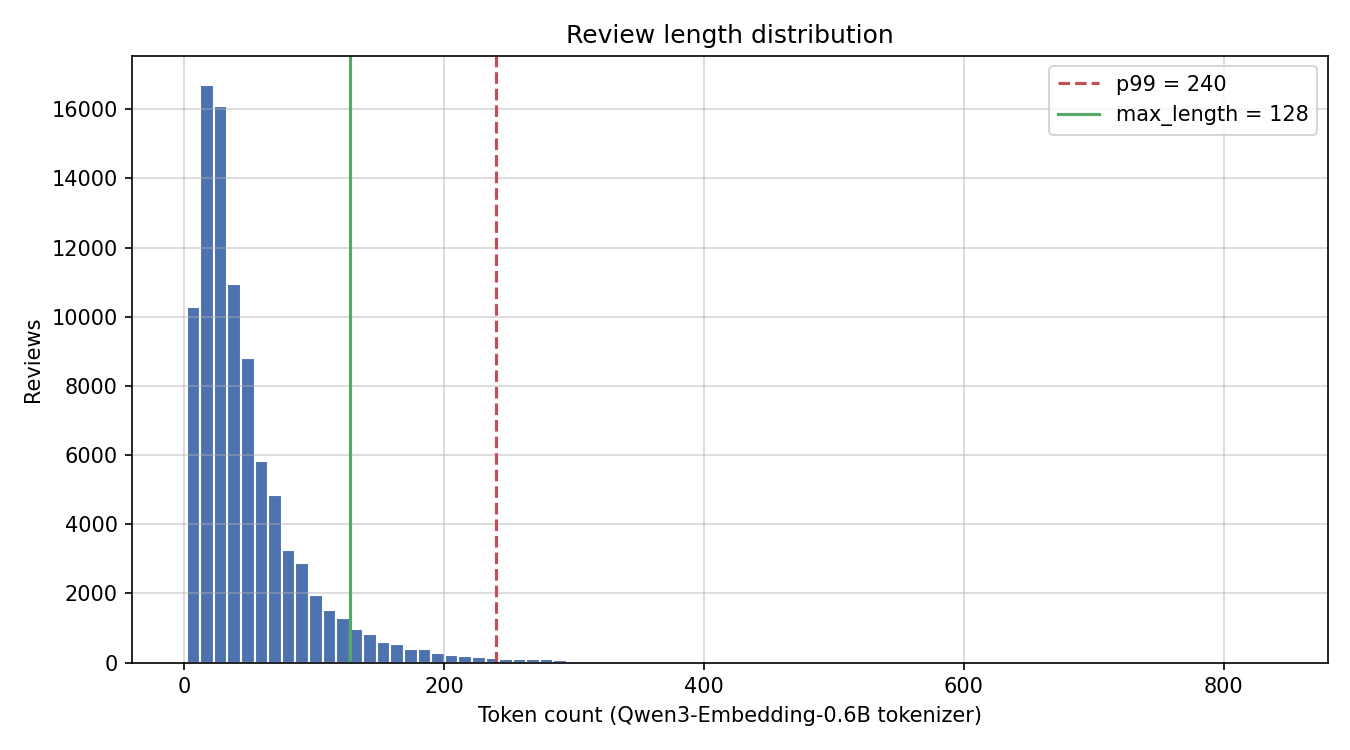
Fine-tuned and unlearned variants of Qwen/Qwen3-Embedding-0.6B for three-class Russian sentiment classification on women's clothing reviews. Full training code, dataset splits, metric tables, figures, and reproduction commands:
https://github.com/pymlex/qwen3-embedding-0.6b-unlearning
We forget class neutral in a three-class sentiment model over Russian product reviews. Original is trained on negative, neutral, and positive. Gold is trained on retain data only with a two-logit head over negative and positive. Gold stays frozen as the reference for KL divergence and prediction agreement during unlearning.
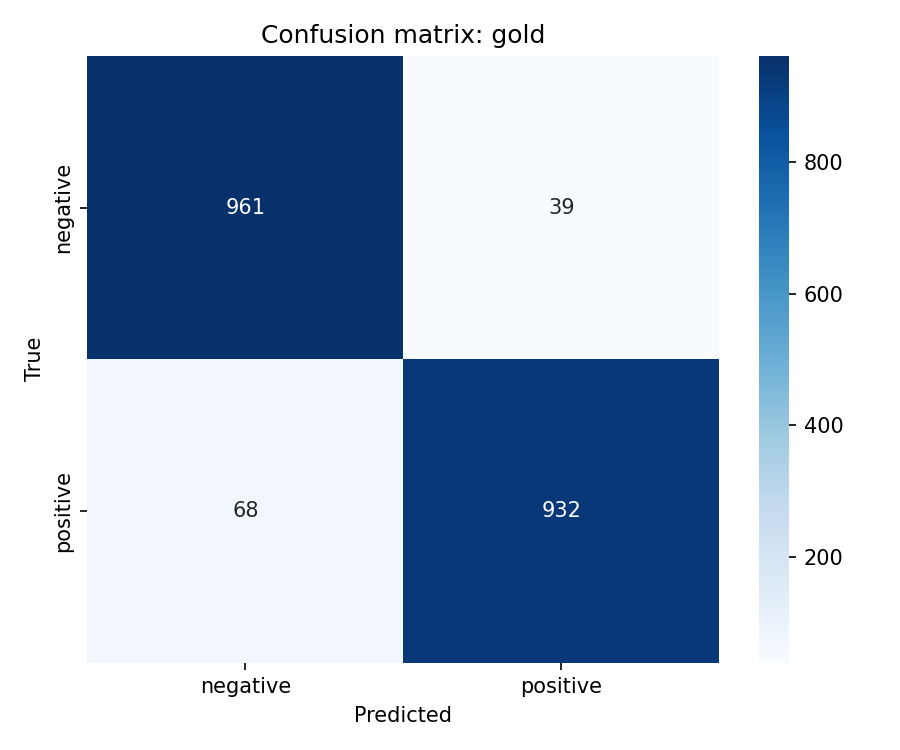
Gold reaches test MCC 0.893 on the two-class retain task. Original reaches test MCC 0.633 on the full three-class split. These values measure different tasks and should not be compared directly.
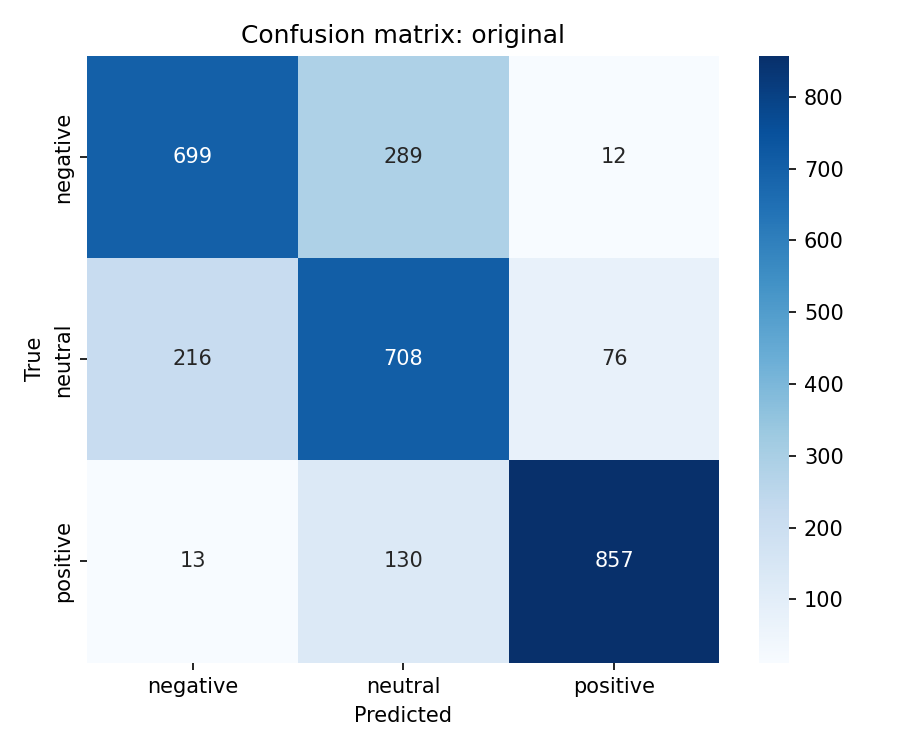
Class neutral is difficult in this corpus. Many neutral reviews lie near the boundary between weak negative and weak positive polarity, and automatic labelling noise concentrates on this class. On a balanced three-class test split, a predictor that classifies negative and positive at gold quality but fails on neutral yields multiclass MCC near 0.65. Original validation MCC 0.656 exceeds this reference. Saved test predictions assign neutral to 37.6% of examples, so original learned neutral to a limited extent. Training and evaluation on two polar classes only removes the third decision region, and MCC rises to about 0.90.
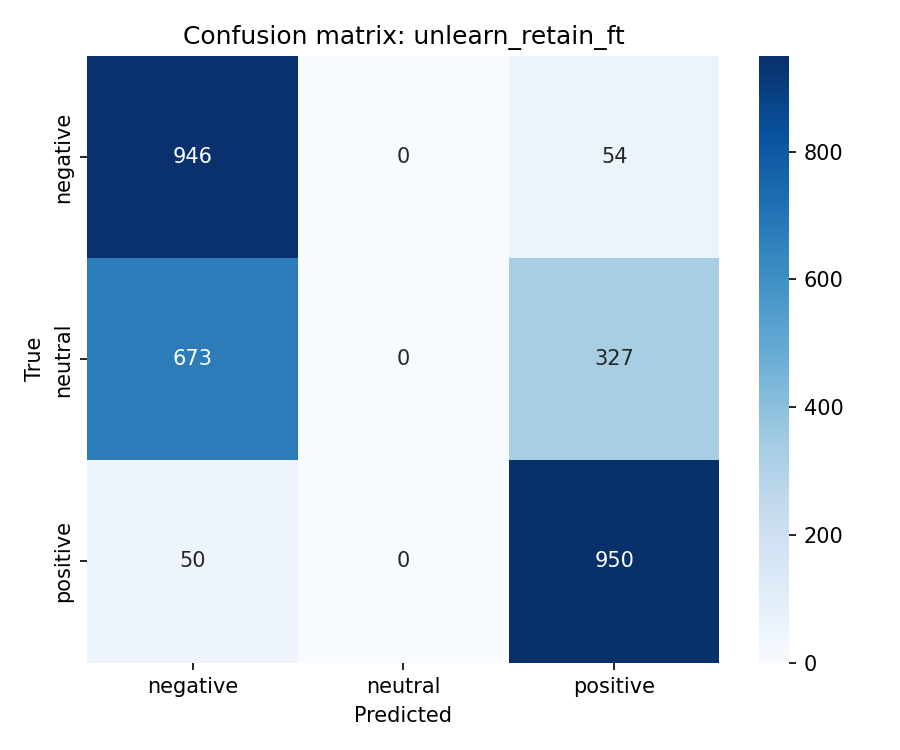
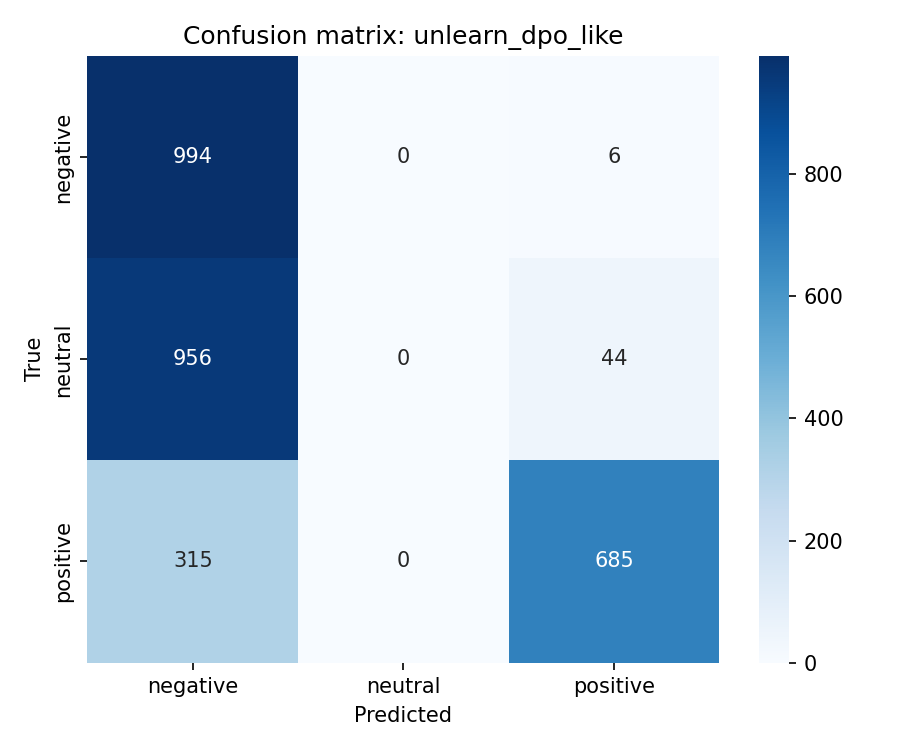
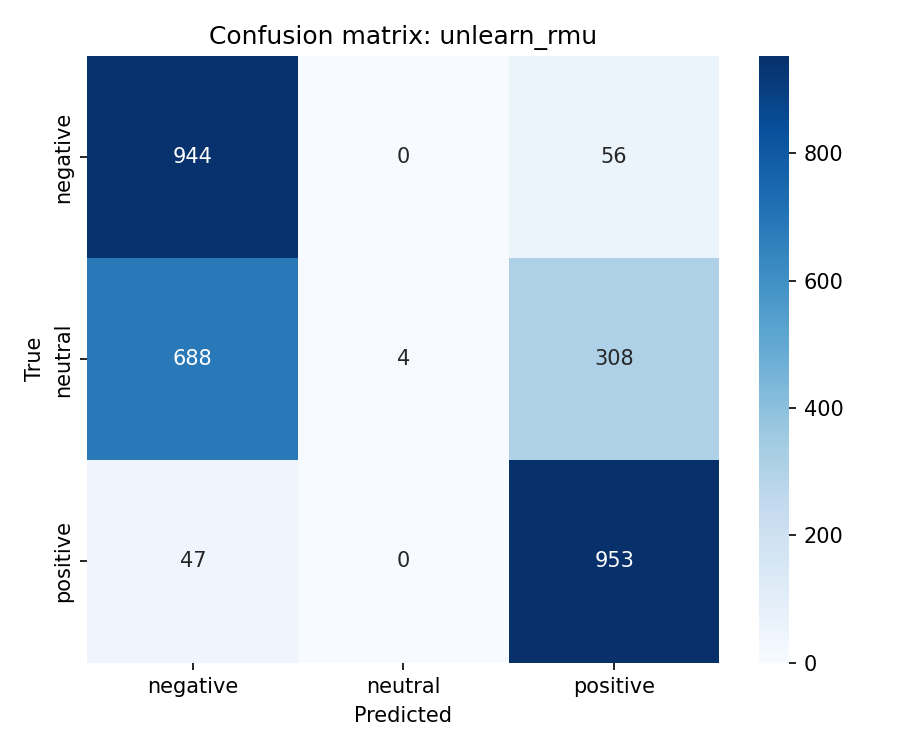
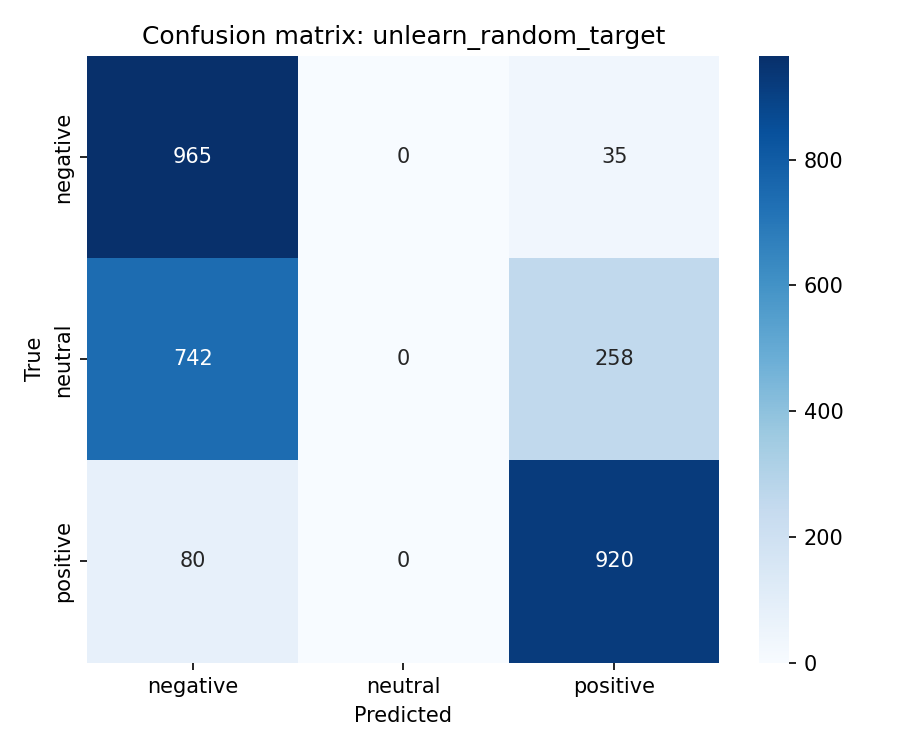
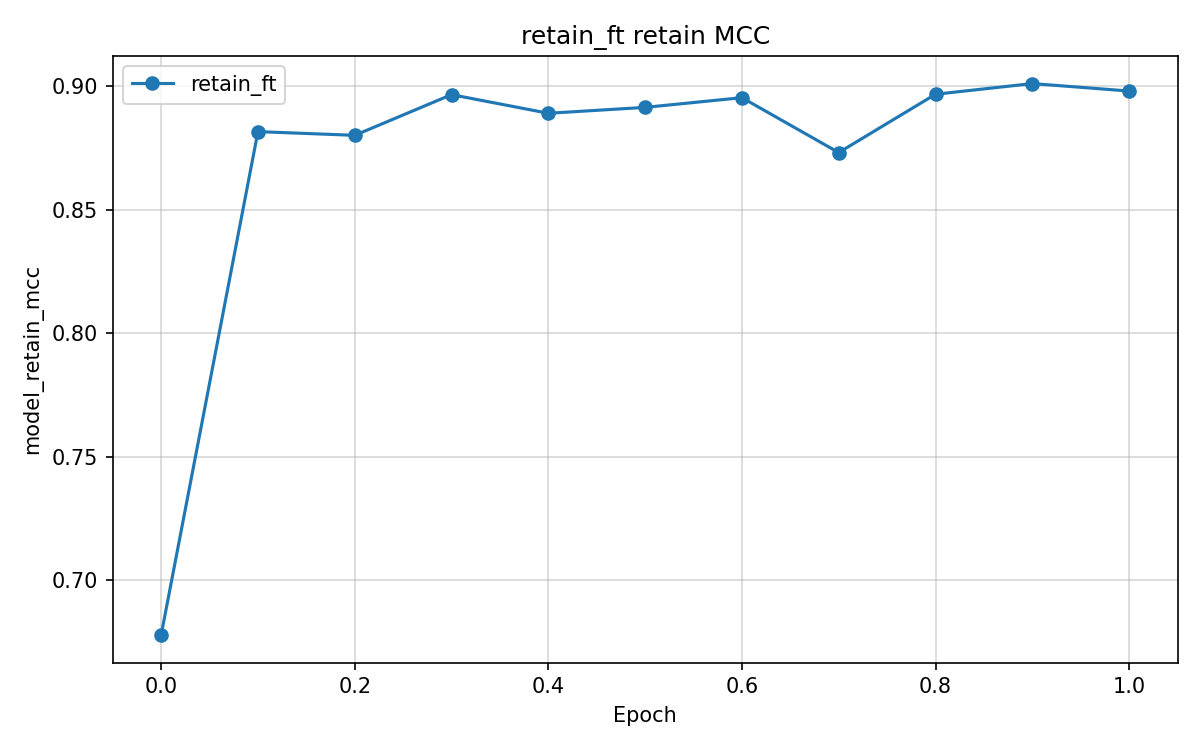
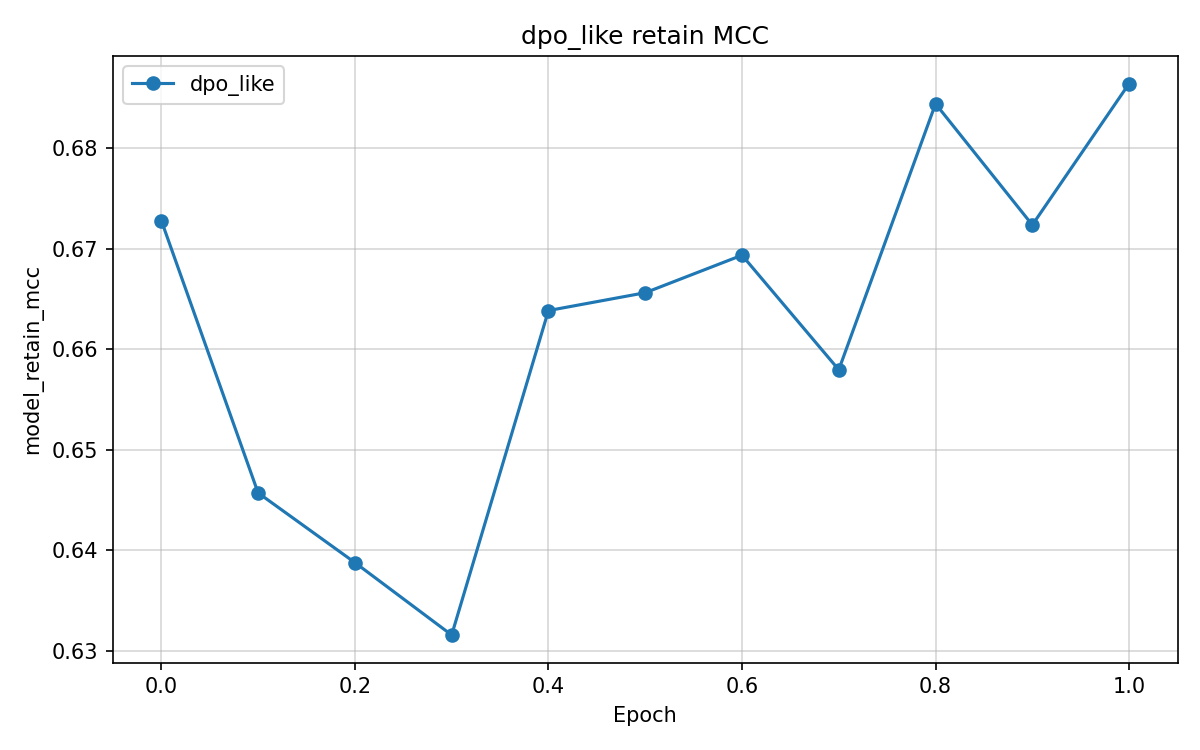
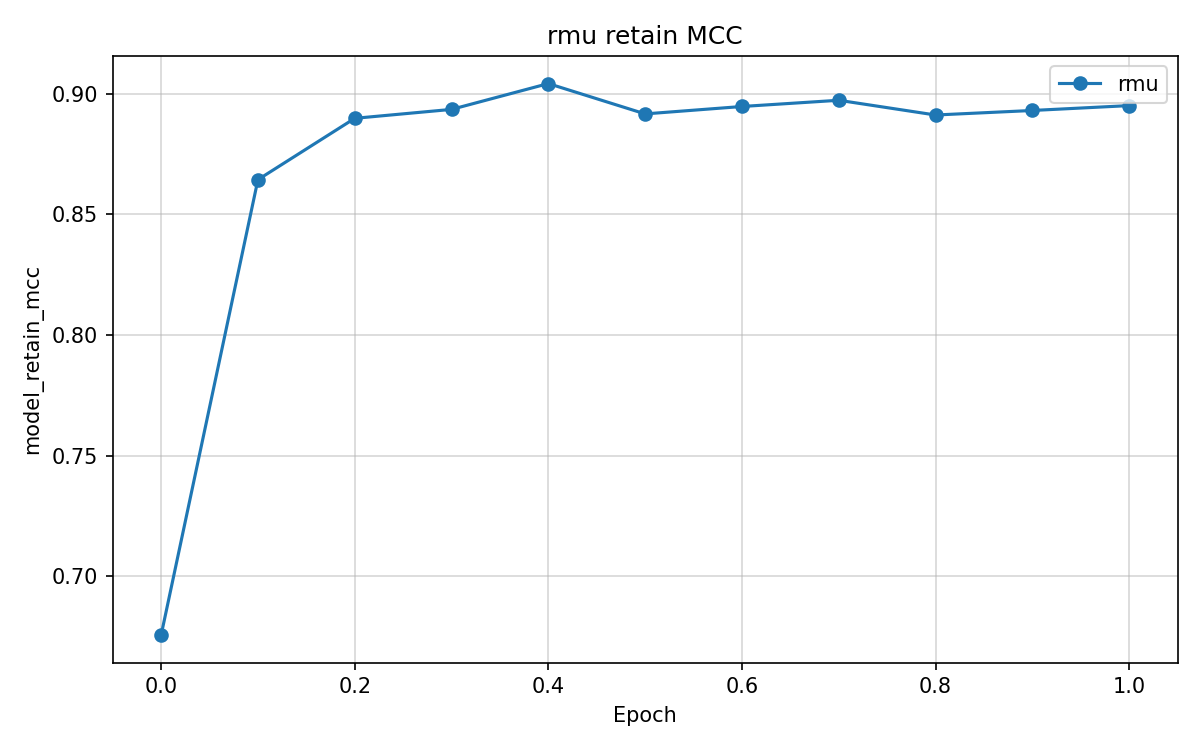
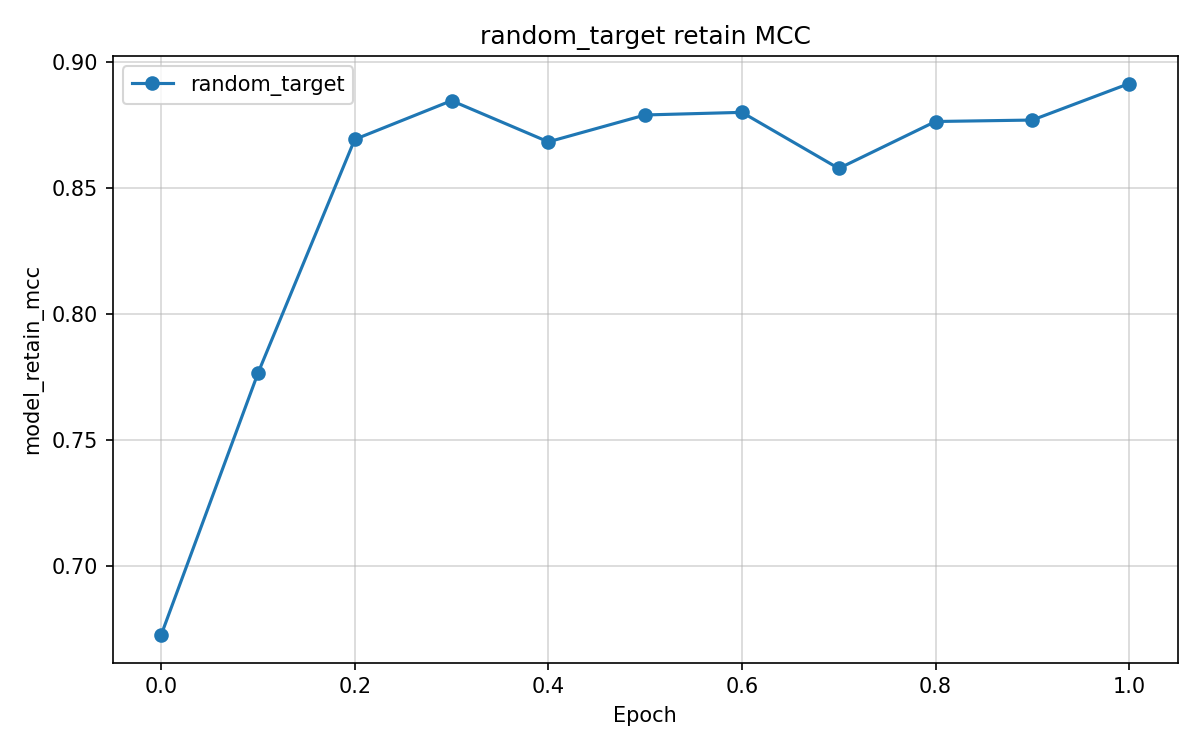
We compare four unlearning objectives starting from original. Checkpoints cover gold, original, and unlearn/{method}/ for retain_ft, dpo_like, rmu, and random_target. Experiments used Google Colab Pro with an NVIDIA L4 GPU, one baseline epoch, and one unlearning epoch per method.
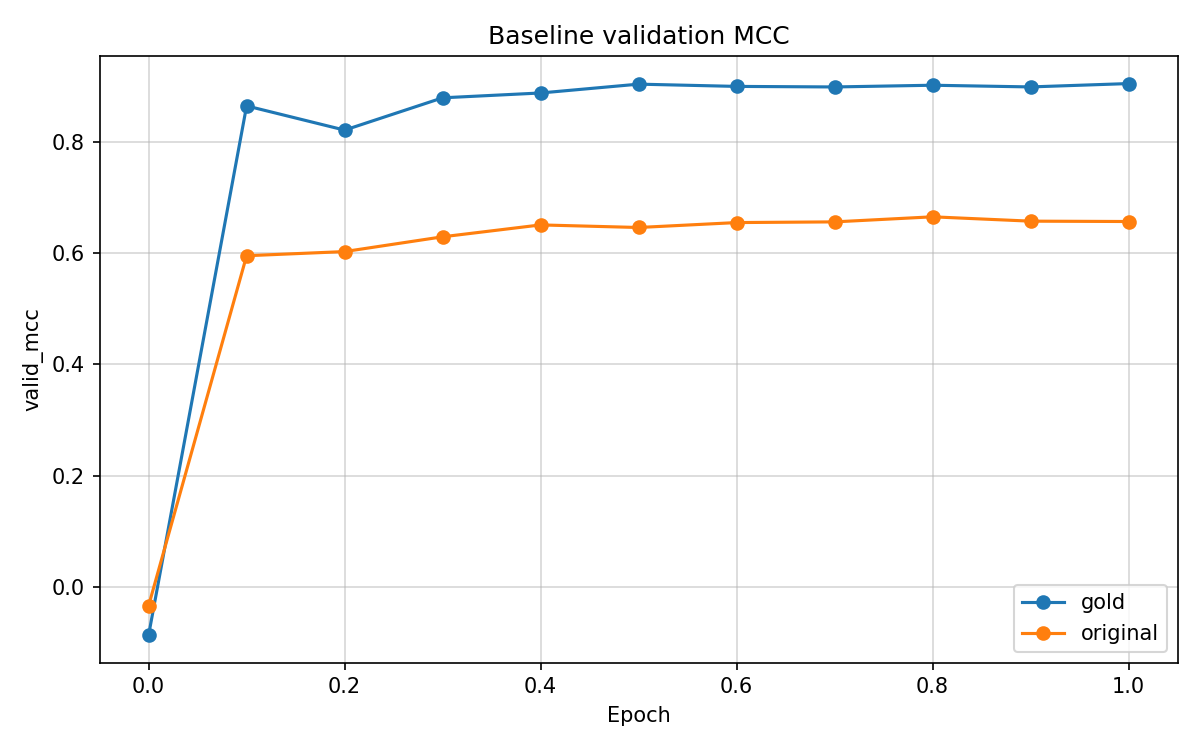
Gold converges quickly on retain validation. Original plateaus near 0.65–0.66 from epoch 0.4 onward.
Multiclass MCC columns test_mcc and model_retain_mcc lie in [-1,1]. Column model_forget_mcc maps neutral argmax rate on the forget test split to [-1,1] only at exact 0% or 100%. Values 1.761 for original and -11.068 for rmu fall outside that range and are numerical artefacts. retain_ft, random_target, and rmu pass the retain gate at model_retain_mcc \geq 0.804 and suppress neutral on the test split. retain_ft leads on gold_kl_retain and gold_agree_forget. dpo_like fails the retain gate.
| Model | test MCC | model_retain_mcc | model_forget_mcc | gold_kl_retain | gold_kl_forget | gold_agree_retain | gold_agree_forget |
|---|---|---|---|---|---|---|---|
| gold | 0.893 | 0.893 | -1.000 | 0.000 | 0.000 | 1.000 | 1.000 |
| original | 0.633 | 0.676 | 1.761 | 0.021 | 0.047 | 0.787 | 0.290 |
| retain_ft | 0.521 | 0.896 | -1.000 | 0.065 | 0.162 | 0.966 | 0.905 |
| random_target | 0.521 | 0.888 | -1.000 | 0.088 | 0.185 | 0.966 | 0.876 |
| rmu | 0.523 | 0.898 | -11.068 | 0.090 | 0.198 | 0.962 | 0.880 |
| dpo_like | 0.456 | 0.715 | -1.000 | 0.232 | 0.228 | 0.859 | 0.764 |
Best unlearning method: retain_ft (unlearn/retain_ft/).
| Folder | Description |
|---|---|
gold/ |
Two-class reference model trained on retain data only |
original/ |
Three-class baseline trained on the full train split |
unlearn/retain_ft/ |
Retain fine-tuning, selected as best |
unlearn/dpo_like/ |
DPO-like unlearning |
unlearn/rmu/ |
RMU with uniform refusal target |
unlearn/random_target/ |
Random target mislabelling on forget set |
Each checkpoint stores a fine-tuned encoder directory and classifier.pt MLP head weights.
from huggingface_hub import snapshot_download
import torch
from models.classifier import QwenEmbeddingClassifier
repo_dir = snapshot_download("pymlex/qwen3-embedding-0.6b-unlearning")
model = QwenEmbeddingClassifier.load_pretrained(
f"{repo_dir}/unlearn/retain_ft",
model_id="Qwen/Qwen3-Embedding-0.6B",
num_classes=3,
hidden_dim=512,
max_length=128,
)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device).eval()
label_names = ["negative", "neutral", "positive"]
reviews = [
"Платье пришло с браком, очень разочарована.",
"Отличное качество, ношу каждый день.",
"Нормальная вещь, ничего особенного.",
]
probs = model.predict_probs(reviews, device)
for review, prob_vector in zip(reviews, probs.cpu().numpy()):
prediction = label_names[int(prob_vector.argmax())]
print(review)
print(f" prediction: {prediction}")
print(f" probabilities: {dict(zip(label_names, prob_vector.round(3)))}")
Clone https://github.com/pymlex/qwen3-embedding-0.6b-unlearning for QwenEmbeddingClassifier. Replace unlearn/retain_ft with another checkpoint folder. Gold uses num_classes=2.
@software{zyukov2026qwen3unlearning,
author = {Zyukov, Alex},
title = {{Qwen3-Embedding-0.6B Unlearning}: Machine Unlearning for Russian Sentiment Classification},
year = {2026},
url = {https://github.com/pymlex/qwen3-embedding-0.6b-unlearning},
version = {1.0},
note = {Hugging Face model pymlex/qwen3-embedding-0.6b-unlearning}
}
@article{qwen3embedding,
title={Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models},
author={Zhang, Yanzhao and Li, Mingxin and Long, Dingkun and Zhang, Xin and Lin, Huan and Yang, Baosong and Xie, Pengjun and Yang, An and Liu, Dayiheng and Lin, Junyang and Huang, Fei and Zhou, Jingren},
journal={arXiv preprint arXiv:2506.05176},
year={2025}
}
@INPROCEEDINGS{Smetanin-SA-2019,
author={Sergey Smetanin and Michail Komarov},
booktitle={2019 IEEE 21st Conference on Business Informatics (CBI)},
title={Sentiment Analysis of Product Reviews in Russian using Convolutional Neural Networks},
year={2019},
volume={01},
pages={482-486},
doi={10.1109/CBI.2019.00062}
}
The project is under GPL-3.0 license.