
jina-embeddings-v2
Collection
The V2 family of Jina Embeddings supports encoding large documents with 8k sequence length.
•
8 items
•
Updated
•
15
![]()
The text embedding set trained by Jina AI.
The easiest way to starting using jina-embeddings-v2-base-de is to use Jina AI's Embedding API.
jina-embeddings-v2-base-de is a German/English bilingual text embedding model supporting 8192 sequence length.
It is based on a BERT architecture (JinaBERT) that supports the symmetric bidirectional variant of ALiBi to allow longer sequence length.
We have designed it for high performance in mono-lingual & cross-lingual applications and trained it specifically to support mixed German-English input without bias.
Additionally, we provide the following embedding models:
jina-embeddings-v2-base-de ist ein zweisprachiges Text Embedding Modell für Deutsch und Englisch,
welches Texteingaben mit einer Länge von bis zu 8192 Token unterstützt.
Es basiert auf der adaptierten Bert-Modell-Architektur JinaBERT,
welche mithilfe einer symmetrische Variante von ALiBi längere Eingabetexte erlaubt.
Wir haben, das Model für hohe Performance in einsprachigen und cross-lingual Anwendungen entwickelt und speziell darauf trainiert,
gemischte deutsch-englische Eingaben ohne einen Bias zu kodieren.
Des Weiteren stellen wir folgende Embedding-Modelle bereit:
jina-embeddings-v2-small-en: 33 million parameters.jina-embeddings-v2-base-en: 137 million parameters.jina-embeddings-v2-base-zh: 161 million parameters Chinese-English Bilingual embeddings.jina-embeddings-v2-base-de: 161 million parameters German-English Bilingual embeddings (you are here).jina-embeddings-v2-base-es: Spanish-English Bilingual embeddings (soon).jina-embeddings-v2-base-code: 161 million parameters code embeddings.The data and training details are described in this technical report.
mean poooling takes all token embeddings from model output and averaging them at sentence/paragraph level.
It has been proved to be the most effective way to produce high-quality sentence embeddings.
We offer an encode function to deal with this.
However, if you would like to do it without using the default encode function:
import torch
import torch.nn.functional as F
from transformers import AutoTokenizer, AutoModel
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0]
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
sentences = ['How is the weather today?', 'What is the current weather like today?']
tokenizer = AutoTokenizer.from_pretrained('jinaai/jina-embeddings-v2-base-de')
model = AutoModel.from_pretrained('jinaai/jina-embeddings-v2-base-de', trust_remote_code=True, torch_dtype=torch.bfloat16)
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
with torch.no_grad():
model_output = model(**encoded_input)
embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
embeddings = F.normalize(embeddings, p=2, dim=1)
You can use Jina Embedding models directly from transformers package.
!pip install transformers
import torch
from transformers import AutoModel
from numpy.linalg import norm
cos_sim = lambda a,b: (a @ b.T) / (norm(a)*norm(b))
model = AutoModel.from_pretrained('jinaai/jina-embeddings-v2-base-de', trust_remote_code=True, torch_dtype=torch.bfloat16)
embeddings = model.encode(['How is the weather today?', 'Wie ist das Wetter heute?'])
print(cos_sim(embeddings[0], embeddings[1]))
If you only want to handle shorter sequence, such as 2k, pass the max_length parameter to the encode function:
embeddings = model.encode(
['Very long ... document'],
max_length=2048
)
Using the its latest release (v2.3.0) sentence-transformers also supports Jina embeddings (Please make sure that you are logged into huggingface as well):
!pip install -U sentence-transformers
from sentence_transformers import SentenceTransformer
from sentence_transformers.util import cos_sim
model = SentenceTransformer(
"jinaai/jina-embeddings-v2-base-de", # switch to en/zh for English or Chinese
trust_remote_code=True
)
# control your input sequence length up to 8192
model.max_seq_length = 1024
embeddings = model.encode([
'How is the weather today?',
'Wie ist das Wetter heute?'
])
print(cos_sim(embeddings[0], embeddings[1]))
We evaluated our Bilingual model on all German and English evaluation tasks availble on the MTEB benchmark. In addition, we evaluated the models agains a couple of other German, English, and multilingual models on additional German evaluation tasks:

According to the latest blog post from LLamaIndex,
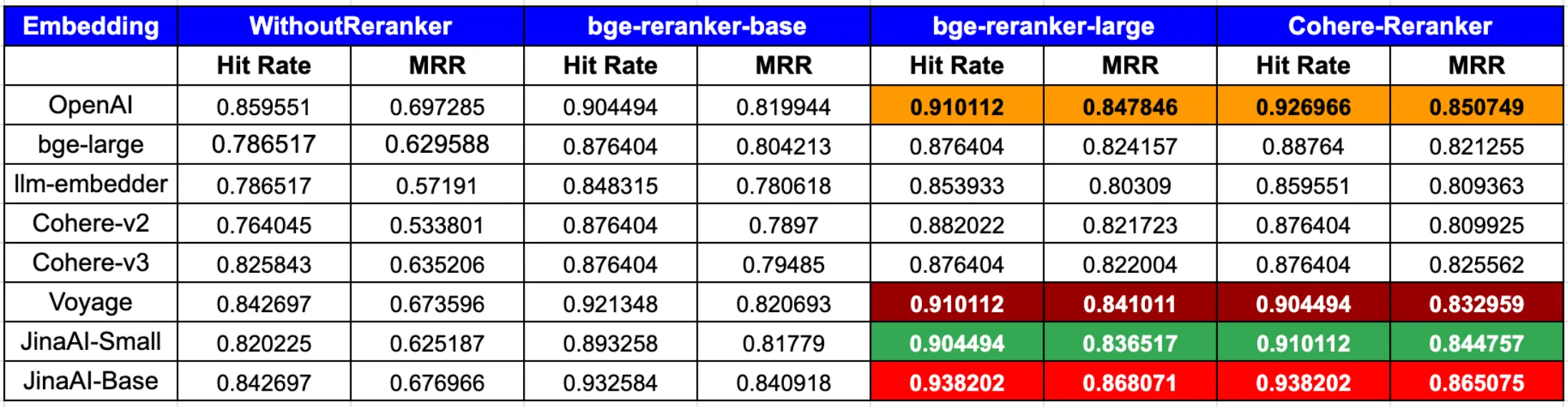
In summary, to achieve the peak performance in both hit rate and MRR, the combination of OpenAI or JinaAI-Base embeddings with the CohereRerank/bge-reranker-large reranker stands out.
Join our Discord community and chat with other community members about ideas.
If you find Jina Embeddings useful in your research, please cite the following paper:
@article{mohr2024multi,
title={Multi-Task Contrastive Learning for 8192-Token Bilingual Text Embeddings},
author={Mohr, Isabelle and Krimmel, Markus and Sturua, Saba and Akram, Mohammad Kalim and Koukounas, Andreas and G{\"u}nther, Michael and Mastrapas, Georgios and Ravishankar, Vinit and Mart{\'\i}nez, Joan Fontanals and Wang, Feng and others},
journal={arXiv preprint arXiv:2402.17016},
year={2024}
}