
Ghost 8B Beta
Collection
The large language model developed with goals that include excellent multilingual support, superior knowledge capabilities, and cost-effectiveness.
•
7 items
•
Updated
![]()
A large language model was developed with goals including excellent multilingual support, superior knowledge capabilities and cost efficiency.
Ghost 8B Beta (Llama 3 - Ghost 8B Beta) is a large language model developed with goals that include excellent multilingual support, superior knowledge capabilities, and cost-effectiveness. The model comes in two context length versions, 8k and 128k, along with multilingual function tools support by default.
The Ghost 8B Beta model outperforms prominent models such as Llama 3.1 8B Instruct, GPT 3.5 Turbo in the lc_winrate score. In addition, it also outperforms Claude 3 Opus, Claude 3 Sonnet, GPT-4, and Mistral Large when comparing the winrate score of AlpacaEval 2.0, *.
We believe that it is possible to optimize language models that are not too large to achieve better capabilities in terms of cross-linguistic understanding and solving complex tasks. The potential of these models is often mentioned as being cost-effective when deployed and operated at the production level for both large businesses and startups. By doing this well, we can partly eliminate worries about the cost of GPUs that hinder the development of useful A.I ideas and products for humans.
We create many distributions to give you the best access options that best suit your needs.
| Version | Model card |
|---|---|
| BF16 | 🤗 HuggingFace |
| GGUF | 🤗 HuggingFace |
| AWQ | 🤗 HuggingFace |
| MLX | 🤗 HuggingFace |
The Ghost 8B Beta model is released under the Ghost Open LLMs LICENSE, Llama 3 LICENSE.
Additionally, it would be great if you could mention or credit the model when it benefits your work.
The model is further trained based on meta-llama/Meta-Llama-3-8B.
Ghost 8B Beta has been continual pre-training and fine-tuned with a recipe given the funny name "Teach the little boy how to cook Saigon Pho".
This technique is designed to include model training with 3 main stages:
Note, with this recipe we are able to reproduce this model exactly. More specifically, all training source code (both forks and patches to libraries) is archived and reproducible.
The Ghost 8B Beta model comes with a built-in "chat template" if used via "transformers" so everything is quite simple. Here we will learn what the model supports and how to optimize its use to get the best quality of generated text.
The model supports the following roles:
{{ bos_token }}{% for message in messages %}
{% set role = message['role'] %}
{% if role == 'tools' %}
{% set role = 'tool:schemas' %}
{% elif role == 'execute' %}
{% set role = 'tool:execute' %}
{% elif role == 'response' %}
{% set role = 'tool:results' %}
{% endif %}
{% set content = message['content'] | trim + '<|cos|>' %}
{% if role == 'system' %}
{% set content = '<|role:begin|>system<|role:end|>
' + content %}
{% elif role == 'user' %}
{% set content = '<|role:begin|>user<|role:end|>
' + content %}
{% elif role == 'assistant' %}
{% set content = '<|role:begin|>assistant<|role:end|>
' + content %}
{% elif role == 'refs' %}
{% set content = '<|role:begin|>references<|role:end|>
' + content %}
{% elif role == 'tool:schemas' %}
{% set content = '<|role:begin|>tools<|role:end|>
' + content %}
{% elif role == 'tool:execute' %}
{% set content = '<|role:begin|>assistant<|role:end|>
<|tool:execute|>' + content %}
{% elif role == 'tool:results' %}
{% set content = '<|role:begin|>user<|role:end|>
<|tool:results|>' + content %}
{% endif %}
{{ content }}
{% if loop.last and add_generation_prompt %}
{{ '<|role:begin|>assistant<|role:end|>' }}
{% endif %}
{% endfor %}
To understand better, let's see how to use details.
This content will be updated soon.
To use the model directly, there are many ways to get started, choose one of the following ways to experience it.
For direct use with transformers, you can easily get started with the following steps.
Firstly, you need to install transformers via the command below with pip.
pip install -U transformers
Right now, you can start using the model directly.
import torch
from transformers import (
AutoModelForCausalLM,
AutoTokenizer,
)
base_model = "ghost-x/ghost-8b-beta-1608"
model = AutoModelForCausalLM.from_pretrained(
base_model,
torch_dtype=torch.bfloat16,
device_map="auto",
)
tokenizer = AutoTokenizer.from_pretrained(base_model)
messages = [
{"role": "system", "content": ""},
{"role": "user", "content": "Why is the sky blue ?"},
]
prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
inputs = tokenizer(prompt, return_tensors="pt", add_special_tokens=False)
for k,v in inputs.items():
inputs[k] = v.cuda()
outputs = model.generate(**inputs, max_new_tokens=512, do_sample=True, top_k=50, top_p=0.95, temperature=0.4)
results = tokenizer.batch_decode(outputs)[0]
print(results)
Additionally, you can also use a model with 4bit quantization to reduce the required resources at least. You can start with the code below.
import torch
from transformers import (
AutoModelForCausalLM,
AutoTokenizer,
BitsAndBytesConfig,
)
base_model = "ghost-x/ghost-8b-beta-1608"
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16,
bnb_4bit_use_double_quant=False,
)
model = AutoModelForCausalLM.from_pretrained(
base_model,
quantization_config=bnb_config,
device_map="auto",
)
tokenizer = AutoTokenizer.from_pretrained(base_model)
messages = [
{"role": "system", "content": ""},
{"role": "user", "content": "Why is the sky blue ?"},
]
prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
inputs = tokenizer(prompt, return_tensors="pt", add_special_tokens=False)
for k,v in inputs.items():
inputs[k] = v.cuda()
outputs = model.generate(**inputs, max_new_tokens=512, do_sample=True, top_k=50, top_p=0.95, temperature=0.4)
results = tokenizer.batch_decode(outputs)[0]
print(results)
For direct use with unsloth, you can easily get started with the following steps.
Firstly, you need to install unsloth via the command below with pip.
import torch
major_version, minor_version = torch.cuda.get_device_capability()
# Must install separately since Colab has torch 2.2.1, which breaks packages
!pip install "unsloth[colab-new] @ git+https://github.com/unslothai/unsloth.git"
if major_version >= 8:
# Use this for new GPUs like Ampere, Hopper GPUs (RTX 30xx, RTX 40xx, A100, H100, L40)
!pip install --no-deps packaging ninja einops flash-attn xformers trl peft accelerate bitsandbytes
else:
# Use this for older GPUs (V100, Tesla T4, RTX 20xx)
!pip install --no-deps xformers trl peft accelerate bitsandbytes
pass
Initialize and optimize the model before use.
from unsloth import FastLanguageModel
import os, torch, pprint
base_model = "ghost/ghost-8b-beta"
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = base_model,
max_seq_length = 8192,
dtype = None,
load_in_4bit = False, # Change to `True` if you want to use 4bit quantization.
)
FastLanguageModel.for_inference(model)
Right now, you can start using the model directly.
messages = [
{"role": "system", "content": ""},
{"role": "user", "content": "Why is the sky blue ?"},
]
prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
inputs = tokenizer(prompt, return_tensors="pt", add_special_tokens=False)
for k,v in inputs.items():
inputs[k] = v.cuda()
outputs = model.generate(**inputs, max_new_tokens=512, do_sample=True, top_k=50, top_p=0.95, temperature=0.4)
results = tokenizer.batch_decode(outputs)[0]
print(results)
For direct use with mlx, you can easily get started with the following steps.
Firstly, you need to install unsloth via the command below with pip.
pip install mlx-lm
Right now, you can start using the model directly.
from mlx_lm import load, generate
model, tokenizer = load("ghost-x/ghost-8b-beta-1608-mlx")
messages = [
{"role": "system", "content": ""},
{"role": "user", "content": "Why is the sky blue ?"},
]
prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
response = generate(model, tokenizer, prompt=prompt, verbose=True)
Here are specific instructions and explanations for each use case.
This is an example of a multi-turns conversation between the assistant and the user.
Let's start with "messages" with system and user questions as follows:
messages = [
{"role": "system", "content": ""},
{"role": "user", "content": "What is the significance of the Higgs boson in the Standard Model of particle physics?"},
]
Then adding the assistant's answer generated the same new question from the user.
messages = [
{"role": "system", "content": ""},
{"role": "user", "content": "What is the significance of the Higgs boson in the Standard Model of particle physics?"},
{"role": "assistant", "content": "..."},
{"role": "user", "content": "Identify the author of a novel that features a dystopian society where \"Big Brother\" watches over its citizens and the protagonist works for the Ministry of Truth."},
]
Done, that's how to create ongoing conversations with chat templates.
For "Retrieval-Augmented Generation", the best way to add reference information without having to change the prompt system is to use the "refs" role, see the following example.
refs = json.dumps(
{
"instructions": "These are only general documents used for reference to give the most accurate and honest answers possible. Ignore it if it's irrelevant and don't overuse it.",
"documents": [
# The content of the reference documents is here.
# The model will only rely on reference content to answer if relevant.
"Paracetamol poisoning, also known as acetaminophen poisoning, is caused by excessive use of the medication paracetamol (acetaminophen). Most people have few or non-specific symptoms in the first 24 hours following overdose. These include feeling tired, abdominal pain, or nausea. This is typically followed by a couple of days without any symptoms, after which yellowish skin, blood clotting problems, and confusion occurs as a result of liver failure. Additional complications may include kidney failure, pancreatitis, low blood sugar, and lactic acidosis. If death does not occur, people tend to recover fully over a couple of weeks. Without treatment, death from toxicity occurs 4 to 18 days later.Paracetamol poisoning can occur accidentally or as an attempt to die by suicide. Risk factors for toxicity include alcoholism, malnutrition, and the taking of certain other hepatotoxic medications. Liver damage results not from paracetamol itself, but from one of its metabolites, N-acetyl-p-benzoquinone imine (NAPQI). NAPQI decreases the livers glutathione and directly damages cells in the liver. Diagnosis is based on the blood level of paracetamol at specific times after the medication was taken. These values are often plotted on the Rumack-Matthew nomogram to determine level of concern.Treatment may include activated charcoal if the person seeks medical help soon after the overdose. Attempting to force the person to vomit is not recommended. If there is a potential for toxicity, the antidote acetylcysteine is recommended. The medication is generally given for at least 24 hours. Psychiatric care may be required following recovery. A liver transplant may be required if damage to the liver becomes severe. The need for transplant is often based on low blood pH, high blood lactate, poor blood clotting, or significant hepatic encephalopathy. With early treatment liver failure is rare. Death occurs in about 0.1% of cases.Paracetamol poisoning was first described in the 1960s. Rates of poisoning vary significantly between regions of the world. In the United States more than 100,000 cases occur a year. In the United Kingdom it is the medication responsible for the greatest number of overdoses. Young children are most commonly affected. In the United States and the United Kingdom, paracetamol is the most common cause of acute liver failure. Signs and symptoms The signs and symptoms of paracetamol toxicity occur in three phases. The first phase begins within hours of overdose, and consists of nausea, vomiting, a pale appearance, and sweating. However, patients often have no specific symptoms or only mild symptoms in the first 24 hours of poisoning. Rarely, after massive overdoses, patients may develop symptoms of metabolic acidosis and coma early in the course of poisoning.The second phase occurs between 24 hours and 72 hours following overdose and consists of signs of increasing liver damage. In general, damage occurs in liver cells as they metabolize the paracetamol. The individual may experience right upper quadrant abdominal pain. The increasing liver damage also changes biochemical markers of liver function; International normalized ratio (INR) and the liver transaminases ALT and AST rise to abnormal levels. Acute kidney failure may also occur during this phase, typically caused by either hepatorenal syndrome or multiple organ dysfunction syndrome. In some cases, acute kidney failure may be the primary clinical manifestation of toxicity. In these cases, it has been suggested that the toxic metabolite is produced more in the kidneys than in the liver.The third phase follows at 3 to 5 days, and is marked by complications of massive liver necrosis leading to fulminant liver failure with complications of coagulation defects, low blood sugar, kidney failure, hepatic encephalopathy, brain swelling, sepsis, multiple organ failure, and death. If the third phase is survived, the liver necrosis runs its course, and liver and kidney function typically return to normal in a few weeks. The severity of paracetamol toxicity varies depending on the dose and whether appropriate treatment is received. Cause The toxic dose of paracetamol is highly variable. In general the recommended maximum daily dose for healthy adults is 4 grams. Higher doses lead to increasing risk of toxicity. In adults, single doses above 10 grams or 200 mg/kg of bodyweight, whichever is lower, have a reasonable likelihood of causing toxicity. Toxicity can also occur when multiple smaller doses within 24 hours exceed these levels. Following a dose of 1 gram of paracetamol four times a day for two weeks, patients can expect an increase in alanine transaminase in their liver to typically about three times the normal value. It is unlikely that this dose would lead to liver failure. Studies have shown significant hepatotoxicity is uncommon in patients who have taken greater than normal doses over 3 to 4 days. In adults, a dose of 6 grams a day over the preceding 48 hours could potentially lead to toxicity, while in children acute doses above 200 mg/kg could potentially cause toxicity. Acute paracetamol overdose in children rarely causes illness or death, and it is very uncommon for children to have levels that require treatment, with chronic larger-than-normal doses being the major cause of toxicity in children.Intentional overdosing (self-poisoning, with suicidal intent) is frequently implicated in paracetamol toxicity. In a 2006 review, paracetamol was the most frequently ingested compound in intentional overdosing.In rare individuals, paracetamol toxicity can result from normal use. This may be due to individual ("idiosyncratic") differences in the expression and activity of certain enzymes in one of the metabolic pathways that handle paracetamol (see paracetamols metabolism). Risk factors A number of factors can potentially increase the risk of developing paracetamol toxicity. Chronic excessive alcohol consumption can induce CYP2E1, thus increasing the potential toxicity of paracetamol. In one study of patients with liver injury, 64% reported alcohol intakes of greater than 80 grams a day, while 35% took 60 grams a day or less. Whether chronic alcoholism should be considered a risk factor has been debated by some clinical toxicologists. For chronic alcohol users, acute alcohol ingestion at the time of a paracetamol overdose may have a protective effect. For non-chronic alcohol users, acute alcohol consumption had no protective effect. Fasting is a risk factor, possibly because of depletion of liver glutathione reserves. The concomitant use of the CYP2E1 inducer isoniazid increases the risk of hepatotoxicity, though whether 2E1 induction is related to the hepatotoxicity in this case is unclear. Concomitant use of other drugs that induce CYP enzymes, such as antiepileptics including carbamazepine, phenytoin, and barbiturates, have also been reported as risk factors. Pathophysiology When taken in normal therapeutic doses, paracetamol has been shown to be safe. Following a therapeutic dose, it is mostly converted to nontoxic metabolites via Phase II metabolism by conjugation with sulfate and glucuronide, with a small portion being oxidized via the cytochrome P450 enzyme system. Cytochromes P450 2E1 and 3A4 convert approximately 5% of paracetamol to a highly reactive intermediary metabolite, N-acetyl-p-benzoquinone imine (NAPQI). Under normal conditions, NAPQI is detoxified by conjugation with glutathione to form cysteine and mercapturic acid conjugates.In cases of paracetamol overdose, the sulfate and glucuronide pathways become saturated, and more paracetamol is shunted to the cytochrome P450 system to produce NAPQI. As a result, hepatocellular supplies of glutathione become depleted, as the demand for glutathione is higher than its regeneration. NAPQI therefore remains in its toxic form in the liver and reacts with cellular membrane molecules, resulting in widespread hepatocyte damage and death, leading to acute liver necrosis. In animal studies, the livers stores of glutathione must be depleted to less than 70% of normal levels before liver toxicity occurs. Diagnosis A persons history of taking paracetamol is somewhat accurate for the diagnosis. The most effective way to diagnose poisoning is by obtaining a blood paracetamol level. A drug nomogram developed in 1975, called the Rumack-Matthew nomogram, estimates the risk of toxicity based on the serum concentration of paracetamol at a given number of hours after ingestion. To determine the risk of potential hepatotoxicity, the paracetamol level is traced along the nomogram. Use of a timed serum paracetamol level plotted on the nomogram appears to be the best marker indicating the potential for liver injury. A paracetamol level drawn in the first four hours after ingestion may underestimate the amount in the system because paracetamol may still be in the process of being absorbed from the gastrointestinal tract. Therefore, a serum level taken before 4 hours is not recommended.Clinical or biochemical evidence of liver toxicity may develop in one to four days, although, in severe cases, it may be evident in 12 hours. Right-upper-quadrant tenderness may be present and can aid in diagnosis. Laboratory studies may show evidence of liver necrosis with elevated AST, ALT, bilirubin, and prolonged coagulation times, particularly an elevated prothrombin time. After paracetamol overdose, when AST and ALT exceed 1000 IU/L, paracetamol-induced hepatotoxicity can be diagnosed. In some cases, the AST and ALT levels can exceed 10,000 IU/L. Detection in body fluids Paracetamol may be quantified in blood, plasma, or urine as a diagnostic tool in clinical poisoning situations or to aid in the medicolegal investigation of suspicious deaths. The concentration in serum after a typical dose of paracetamol usually peaks below 30 mg/L, which equals 200 μmol/L. Levels of 30–300 mg/L (200–2000 μmol/L) are often observed in overdose patients. Postmortem blood levels have ranged from 50 to 400 mg/L in persons dying due to acute overdosage. Automated colorimetric techniques, gas chromatography and liquid chromatography are currently in use for the laboratory analysis of the drug in physiological specimens. Prevention Limitation of availability Limiting the availability of paracetamol tablets has been attempted in some countries. In the UK, sales of over-the-counter paracetamol are restricted to packs of 32 x 500 mg tablets in pharmacies, and 16 x 500 mg tablets in non-pharmacy outlets. Pharmacists may provide up to 100 tablets for those with chronic conditions at the pharmacists discretion. In Ireland, the limits are 24 and 12 tablets, respectively. Subsequent study suggests that the reduced availability in large numbers had a significant effect in reducing poisoning deaths from paracetamol overdose.One suggested method of prevention is to make paracetamol a prescription-only medicine, or to remove it entirely from the market. However, overdose is a relatively minor problem; for example, 0.08% of the UK population (over 50 thousand people) present with paracetamol overdose each year. In contrast, paracetamol is a safe and effective medication that is taken without complications by millions of people. In addition, alternative pain relief medications such as aspirin are more toxic in overdose, whereas non-steroidal anti-inflammatory drugs are associated with more adverse effects following normal use. Combination with other agents One strategy for reducing harm done by acetaminophen overdoses is selling paracetamol pre-combined in tablets either with an emetic or an antidote. Paradote was a tablet sold in the UK which combined 500 mg paracetamol with 100 mg methionine, an amino acid formerly used in the treatment of paracetamol overdose. There have been no studies so far on the effectiveness of paracetamol when given in combination with its most commonly used antidote, acetylcysteine.Calcitriol, the active metabolite of vitamin D3, appears to be a catalyst for glutathione production. Calcitriol was found to increase glutathione levels in rat astrocyte primary cultures on average by 42%, increasing glutathione protein concentrations from 29 nmol/mg to 41 nmol/mg, 24 and 48 hours after administration; it continued to have an influence on glutathione levels 96 hours after administration. It has been proposed that co-administration of calcitriol, via injection, may improve treatment outcomes. Paracetamol replacements Paracetamol ester prodrug with L-pyroglutamic acid (PCA), a biosynthetic precursor of glutathione, has been synthesized to reduce paracetamol hepatotoxicity and improve bioavailability. The toxicological studies of different paracetamol esters show that L-5-oxo-pyrrolidine-2-paracetamol carboxylate reduces toxicity after administration of an overdose of paracetamol to mice. The liver glutathione values in mice induced by intraperitoneal injection of the ester are superimposable with the GSH levels recorded in untreated mice control group. The mice group treated with an equivalent dose of paracetamol showed a significative decrease of glutathione of 35% (p<0.01 vs untreated control group). The oral LD50 was found to be greater than 2000 mg kg-1, whereas the intraperitoneal LD50 was 1900 mg kg-1. These results taken together with the good hydrolysis and bioavailability data show that this ester is a potential candidate as a prodrug of paracetamol. Treatment Gastric decontamination In adults, the initial treatment for paracetamol overdose is gastrointestinal decontamination. Paracetamol absorption from the gastrointestinal tract is complete within two hours under normal circumstances, so decontamination is most helpful if performed within this timeframe. Gastric lavage, better known as stomach pumping, may be considered if the amount ingested is potentially life-threatening and the procedure can be performed within 60 minutes of ingestion. Activated charcoal is the most common gastrointestinal decontamination procedure as it adsorbs paracetamol, reducing its gastrointestinal absorption. Administering activated charcoal also poses less risk of aspiration than gastric lavage.It appears that the most benefit from activated charcoal is gained if it is given within 30 minutes to two hours of ingestion. Administering activated charcoal later than 2 hours can be considered in patients that may have delayed gastric emptying due to co-ingested drugs or following ingestion of sustained- or delayed-release paracetamol preparations. Activated charcoal should also be administered if co-ingested drugs warrant decontamination. There was reluctance to give activated charcoal in paracetamol overdose, because of the concern that it may also absorb the oral antidote acetylcysteine. Studies have shown that 39% less acetylcysteine is absorbed into the body when they are administered together. There are conflicting recommendations regarding whether to change the dosing of oral acetylcysteine after the administration of activated charcoal, and even whether the dosing of acetylcysteine needs to be altered at all. Intravenous acetylcysteine has no interaction with activated charcoal. Inducing vomiting with syrup of ipecac has no role in paracetamol overdose because the vomiting it induces delays the effective administration of activated charcoal and oral acetylcysteine. Liver injury is extremely rare after acute accidental ingestion in children under 6 years of age. Children with accidental exposures do not require gastrointestinal decontamination with either gastric lavage, activated charcoal, or syrup of ipecac. Acetylcysteine Acetylcysteine, also called N-acetylcysteine or NAC, works to reduce paracetamol toxicity by replenishing body stores of the antioxidant glutathione. Glutathione reacts with the toxic NAPQI metabolite so that it does not damage cells and can be safely excreted. NAC was usually given following a treatment nomogram (one for patients with risk factors, and one for those without) but the use of the nomogram is no longer recommended as the evidence base to support the use of risk factors was poor and inconsistent and many of the risk factors are imprecise and difficult to determine with sufficient certainty in clinical practice. Cysteamine and methionine have also been used to prevent hepatotoxicity, although studies show that both are associated with more adverse effects than acetylcysteine. Additionally, acetylcysteine has been shown to be a more effective antidote, particularly in patients presenting greater than 8 hours post-ingestion and for those who present with liver failure symptoms.If the person presents less than eight hours after paracetamol overdose, then acetylcysteine significantly reduces the risk of serious hepatotoxicity and guarantees survival. If acetylcysteine is started more than 8 hours after ingestion, there is a sharp decline in its effectiveness because the cascade of toxic events in the liver has already begun, and the risk of acute liver necrosis and death increases dramatically. Although acetylcysteine is most effective if given early, it still has beneficial effects if given as late as 48 hours after ingestion. If the person presents more than eight hours after the paracetamol overdose, then activated charcoal is not useful, and acetylcysteine is started immediately. In earlier presentations, charcoal can be given when the patient arrives and acetylcysteine is initiated while waiting for the paracetamol level results to return from the laboratory.In United States practice, intravenous (IV) and oral administration are considered to be equally effective and safe if given within 8 hours of ingestion. However, IV is the only recommended route in Australasian and British practice. Oral acetylcysteine is given as a 140 mg/kg loading dose followed by 70 mg/kg every four hours for 17 more doses, and if the patient vomits within 1 hour of dose, the dose must be repeated. Oral acetylcysteine may be poorly tolerated due to its unpleasant taste, odor, and its tendency to cause nausea and vomiting. If repeated doses of charcoal are indicated because of another ingested drug, then subsequent doses of charcoal and acetylcysteine should be staggered.Intravenous acetylcysteine is given as a continuous infusion over 20 hours for a total dose 300 mg/kg. Recommended administration involves infusion of a 150 mg/kg loading dose over 15 to 60 minutes, followed by a 50 mg/kg infusion over four hours; the last 100 mg/kg are infused over the remaining 16 hours of the protocol. Intravenous acetylcysteine has the advantage of shortening hospital stay, increasing both doctor and patient convenience, and allowing administration of activated charcoal to reduce absorption of both the paracetamol and any co-ingested drugs without concerns about interference with oral acetylcysteine. Intravenous dosing varies with weight, specifically in children. For patients less than 20 kg, the loading dose is 150 mg/kg in 3 mL/kg diluent, administered over 60 minutes; the second dose is 50 mg/kg in 7 mL/kg diluent over 4 hours; and the third and final dose is 100 mg/kg in 14 mL/kg diluent over 16 hours.The most common adverse effect to acetylcysteine treatment is an anaphylactoid reaction, usually manifested by rash, wheeze, or mild hypotension. May cause infertility or death. Adverse reactions are more common in people treated with IV acetylcysteine, occurring in up to 20% of patients. Anaphylactoid reactions are more likely to occur with the first infusion (the loading dose). Rarely, severe life-threatening reactions may occur in predisposed individuals, such as patients with asthma or atopic dermatitis, and may be characterized by respiratory distress, facial swelling, and even death.If an anaphylactoid reaction occurs the acetylcysteine is temporarily halted or slowed and antihistamines and other supportive care is administered. For example, a nebulised beta-agonist like salbutamol may be indicated in the event of significant bronchospasm (or prophylactically in patients with a history of bronchospasm secondary to acetylcysteine). It is also important to closely monitor fluids and electrolytes. Liver transplant In people who develop acute liver failure or who are otherwise expected to die from liver failure, the mainstay of management is liver transplantation. Liver transplants are performed in specialist centers. The most commonly used criteria for liver transplant were developed by physicians at Kings College Hospital in London. Patients are recommended for transplant if they have an arterial blood pH less than 7.3 after fluid resuscitation or if a patient has Grade III or IV encephalopathy, a prothrombin time greater than 100 seconds, and a serum creatinine greater than 300 mmol/L In a 24-hour period. Other forms of liver support have been used including partial liver transplants. These techniques have the advantage of supporting the patient while their own liver regenerates. Once liver function returns immunosuppressive drugs are commenced and they have to take immunosuppressive medication for the rest of their lives. Prognosis The mortality rate from paracetamol overdose increases two days after the ingestion, reaches a maximum on day four, and then gradually decreases. Acidosis is the most important single indicator of probable mortality and the need for transplantation. A mortality rate of 95% without transplant was reported in patients who had a documented pH less than 7.30. Other indicators of poor prognosis include chronic kidney disease (stage 3 or worse), hepatic encephalopathy, a markedly elevated prothrombin time, or an elevated blood lactic acid level (lactic acidosis). One study has shown that a factor V level less than 10% of normal indicated a poor prognosis (91% mortality), whereas a ratio of factor VIII to factor V of less than 30 indicated a good prognosis (100% survival). Patients with a poor prognosis are usually identified for likely liver transplantation. Patients that do not die are expected to fully recover and have a normal life expectancy and quality of life. Epidemiology Many over-the-counter and prescription-only medications contain paracetamol. Because of its wide availability paired with comparably high toxicity, (compared to ibuprofen and aspirin) there is a much higher potential for overdose. Paracetamol toxicity is one of the most common causes of poisoning worldwide. In the United States, the United Kingdom, Australia, and New Zealand, paracetamol is the most common cause of drug overdoses. Additionally, in both the United States and the United Kingdom it is the most common cause of acute liver failure.In England and Wales an estimated 41,200 cases of paracetamol poisoning occurred in 1989 to 1990, with a mortality of 0.40%. It is estimated that 150 to 200 deaths and 15 to 20 liver transplants occur as a result of poisoning each year in England and Wales. Paracetamol overdose results in more calls to poison control centers in the US than overdose of any other pharmacological substance, accounting for more than 100,000 calls, as well as 56,000 emergency room visits, 2,600 hospitalizations, and 458 deaths due to acute liver failure per year. A study of cases of acute liver failure between November 2000 and October 2004 by the Centers for Disease Control and Prevention in the USA found that paracetamol was the cause of 41% of all cases in adults, and 25% of cases in children. References External links Gerth, Jeff; T. Christian Miller (September 20, 2013). \"Use Only as Directed\". ProPublica. Retrieved October 12, 2013."
],
},
indent=2,
ensure_ascii=False,
)
messages = [
{"role": "system", "content": ""},
{"role": "refs", "content": refs},
{"role": "user", "content": "What are the signs of Paracetamol poisoning?"},
]
To use function tools, first declare the schemas of the tools to Ghost 8B Beta through the role "tool:schemas". Let's look at the example to make it easier to understand.
tools = json.dumps(
[
{
"type": "function",
"function": {
"name": "get_flight_status",
"description": "Get the status of a specific flight",
"parameters": {
"type": "object",
"properties": {
"flight_number": {
"type": "string",
"description": "The flight number"
}
}
}
}
}
],
indent=2,
ensure_ascii=False,
)
messages = [
{"role": "system", "content": ""},
{"role": "tool:schemas", "content": tools},
{"role": "user", "content": "What is the status of flight AZ123?"},
]
In the above example, the model will return the execution information of the tool to use, which is an Object with a structure similar to the content of the "tool:execute" role in the next example. We need to extract and parse it, then call to get the returned results and pass it through the "tool:results" role. Note, "tool:execute" must be passed again. Then, the model's answer will be received back.
messages = [
{"role": "system", "content": ""},
{"role": "tool:schemas", "content": tools},
{"role": "user", "content": "What is the status of flight AZ123?"},
{
"role": "tool:execute",
"content": json.dumps({
"type": "function",
"name": "get_flight_status",
"arguments": { "flight_number": "AZ123" }
}, indent=2, ensure_ascii=False)
},
{
"role": "too:results",
"content": json.dumps({
"type": "function",
"name": "get_flight_status",
"results": {
"flight_number": "AZ123",
"departure_airport": "FCO",
"arrival_airport": "JFK",
"departure_time": "10:00 AM",
"arrival_time": "1:00 PM",
"status": "On time",
"planned_route": [
{ "latitude": 41.8, "longitude": 12.25 },
{ "latitude": 48.8582, "longitude": 2.2945 },
{ "latitude": 40.6413, "longitude": -73.7781 }
]
}
}, indent=2, ensure_ascii=False)
},
]
Done, here is an example that simulates how to use function tools. Note, Ghost 8B Beta has support for calling multiple tools at once.
For deployment, we recommend using vLLM. You can enable the long-context capabilities by following these steps:
You can install vLLM by running the following command.
pip install "vllm>=0.4.3"
Utilize vLLM to deploy your model. For instance, you can set up an openAI-like server using the command:
python -m vllm.entrypoints.openai.api_server --served-model-name ghost-8b-beta --model ghost-x/ghost-8b-beta-1608
Try it now:
curl http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "ghost-8b-beta",
"messages": [
{"role": "system", "content": ""},
{"role": "user", "content": "Why is the sky blue ?"}
]
}'
Done, just enjoy it.
At an overall level, to evaluate whether a model is effective and high quality or not, it must go through rigorous evaluations that are often trusted by the community such as AlpacaEval 2, MT-Bench, MMLU-Pro, GSM8K, etc.
We use the EleutherAI/lm-evaluation-harness library for evaluations to perform benchmarks for common tasks, except for specific tasks such as AlpacaEval 2.0 and MT Bench.
Once again, Ghost 8B Beta is a language model with a fairly modest size with the goal to achieve multilingual capabilities (9+, most popular languages), support for function tools with those languages. Furthermore, it also has the ambition to be equal or superior to other models with a size many times larger than the Ghost 8B Beta.
Note, to run evaluations for the model, set "max_new_tokens" higher to be able to get the answer because the model will explain before drawing conclusions.
Overview based on evaluation results from this AlpacaEval 2.0:
Of course, the AlpacaEval 2.0 review highlights the "Length-controlled (LC) win rates" score, so the "win rates" here are for reference only.
| model | avg length | lc winrate | winrate | std error |
|---|---|---|---|---|
| GPT-4 Preview (11/06) | 2049 | 50.00 | 50.00 | 0.00 |
| Claude 3 Opus (02/29) | 1388 | 40.51 | 29.11 | 1.39 |
| Claude 3 Sonnet (02/29) | 1420 | 34.87 | 25.56 | 1.34 |
| Llama 3 70B Instruct | 1919 | 34.42 | 33.18 | 1.39 |
| Gemini Pro | 1456 | 24.38 | 18.18 | 1.16 |
| Mixtral 8x7B v0.1 | 1465 | 23.69 | 18.26 | 1.19 |
| Ghost 8B Beta (d0x5) | 2430 | 23.12 | 29.14 | 1.32 |
| Llama 3 8B Instruct | 1899 | 22.92 | 22.57 | 1.26 |
| GPT 3.5 Turbo (06/13) | 1331 | 22.35 | 14.09 | 0.00 |
| GPT 3.5 Turbo (11/06) | 796 | 19.30 | 9.17 | 0.00 |
| Mistral 7B Instruct v0.2 | 1676 | 17.11 | 14.72 | 1.08 |
AlpacaEval: An Automatic Evaluator for Instruction-following Language Models
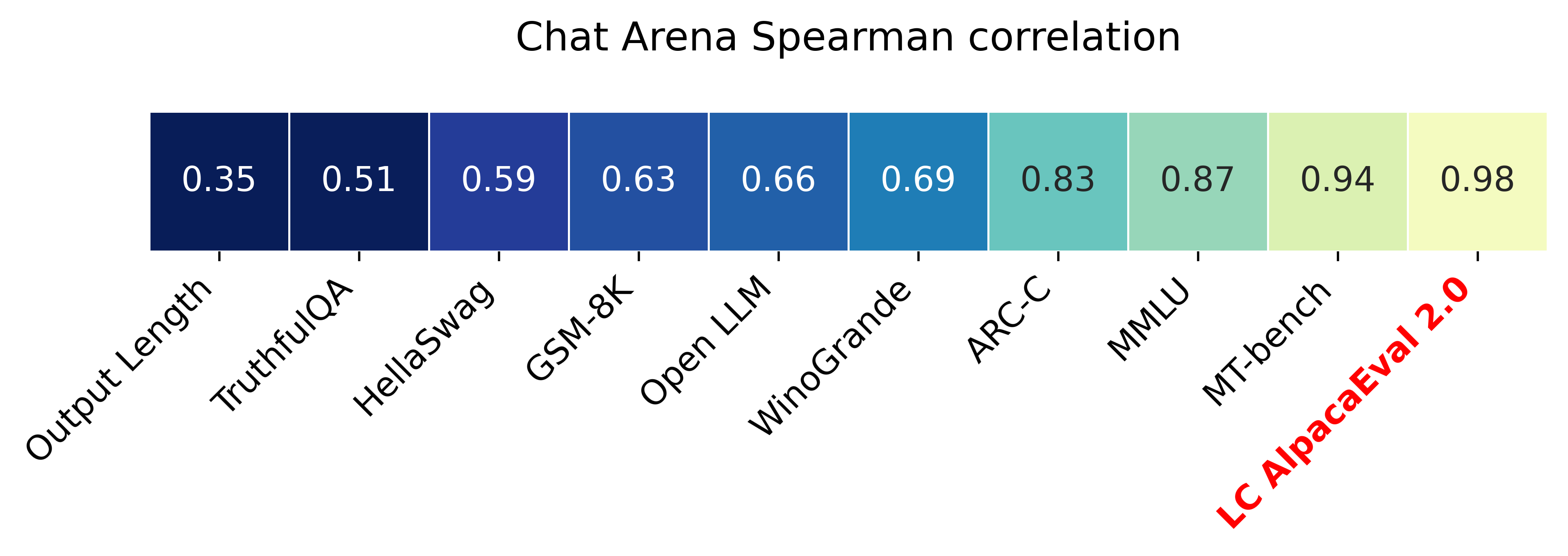
AlpacaEval 2.0 with length-controlled win-rates (paper) has a spearman correlation of 0.98 with ChatBot Arena while costing less than $10 of OpenAI credits run and running in less than 3 minutes. Our goal is to have a benchmark for chat LLMs that is: fast (< 5min), cheap (< $10), and highly correlated with humans (0.98). Here's a comparison with other benchmarks: LC AlpacaEval is the most highly correlated benchmark with Chat Arena.
@article{dubois2024length,
title={Length-Controlled AlpacaEval: A Simple Way to Debias Automatic Evaluators},
author={Dubois, Yann and Galambosi, Bal{\'a}zs and Liang, Percy and Hashimoto, Tatsunori B},
journal={arXiv preprint arXiv:2404.04475},
year={2024}
}
Based on MT Bench average scores, the Ghost 8B Beta scores very close to other much larger models, the GPT 3.5 Turbo and Claude v1. In addition, it outperforms other open models of the same size, Vicuna 33B v1.3, WizardLM 30B and Llama 2 70B chat.
Average Scores
| model | score |
|---|---|
| GPT 4 | 8.990625 |
| GPT 3.5 Turbo | 7.943750 |
| Claude v1 | 7.900000 |
| Ghost 8B Beta (d0x5) | 7.740506 |
| Vicuna 33B v1.3 | 7.121875 |
| WizardLM 30B | 7.009375 |
| Llama 2 70B chat | 6.856250 |
Plots
With MT Bench's plot we will see some other more specific things. In STEM, writing and roleplay scores, the model is at the same level as GPT 4, notably the score in STEM is at an absolute level similar to GPT 4.
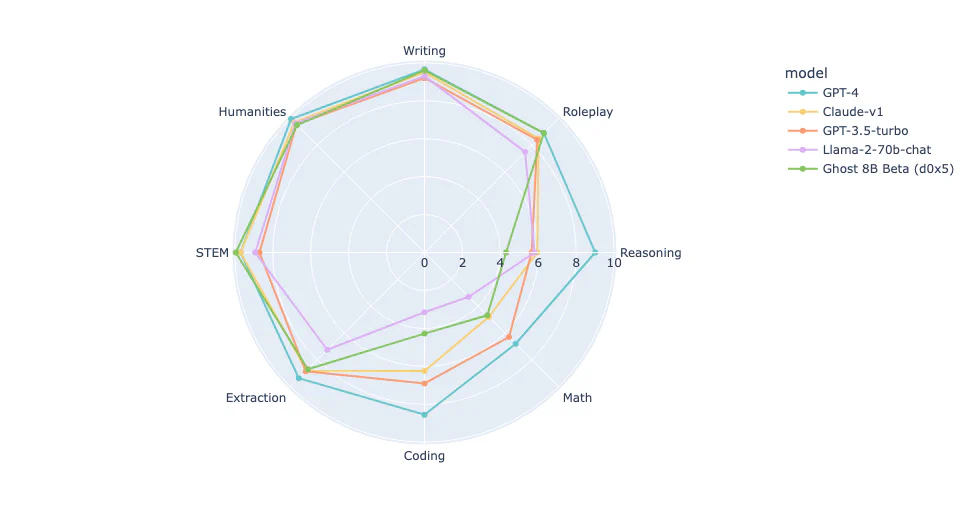
MT Bench is a set of challenging, multi-turn, and open-ended questions for evaluating chat assistants. It uses LLM-as-a-judge to evaluate model responses.
@misc{zheng2023judging,
title={Judging LLM-as-a-judge with MT-Bench and Chatbot Arena},
author={Lianmin Zheng and Wei-Lin Chiang and Ying Sheng and Siyuan Zhuang and Zhanghao Wu and Yonghao Zhuang and Zi Lin and Zhuohan Li and Dacheng Li and Eric. P Xing and Hao Zhang and Joseph E. Gonzalez and Ion Stoica},
year={2023},
eprint={2306.05685},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
GSM8K is an evaluation to test the mathematical capabilities of a widely trusted and accepted language model. In this evaluation, Ghost 8B Beta was run with "gsm8k_cot_zeroshot", which means answering questions without instructions, the score achieved was approximately 67%, it was very impressive.
| tasks | version | filter | n shot | metric | value | std error |
|---|---|---|---|---|---|---|
| gsm8k_cot_zeroshot | 3 | flexible-extract | 0 | exact_match | 0.6641 | 0.0130 |
Leaderboard
The rankings are referenced from this article.
Based on the leaderboard, we can see that Ghost 8B Beta outperforms proprietary models such as xAI Grok 1, OpenAI GPT 3.5 and Mistral Mixtral 8x7b. In addition, Ghost 8B Beta is considered equal to Mistral Medium. Furthermore, only the Ghost 8B Beta, Claude 2 and Claude 3 are rare models that use the zero shot method for evaluation.
| model | accuracy | methodology |
|---|---|---|
| Claude 3 | 95% | Zero shot |
| Gemini Ultra | 94.4% | Majority Vote, 32 Generations |
| GPT 4 | 92% | SFT & 5-shot CoT |
| Claude 2 | 88% | Zero shot |
| Gemini Pro | 86.5% | Majority Vote, 32 Generations |
| Mistral Large | 81% | 5-shot Learning |
| PaLM 2 | 80% | 5-shot Learning |
| Mistral Medium | 66.7% | 5-shot Learning |
| Ghost 8B Beta (d0x5) | 66.4% | Zero shot |
| xAI Grok 1 | 62.9% | 8-shot Learning |
| Mistral Mixtral 8x7B | 58.4% | 5-shot Learning |
| GPT 3.5 | 57.1% | 5-shot Learning |
{
"results": {
"gsm8k_cot_zeroshot": {
"alias": "gsm8k_cot_zeroshot",
"exact_match,strict-match": 0.576194086429113,
"exact_match_stderr,strict-match": 0.013611632008810354,
"exact_match,flexible-extract": 0.6641394996209249,
"exact_match_stderr,flexible-extract": 0.01300922471426737
}
},
"model_source": "hf",
"model_name": "lamhieu/ghost-8b-beta-disl-0x5",
"model_name_sanitized": "lamhieu__ghost-8b-beta-disl-0x5",
"start_time": 1272225.578433881,
"end_time": 1276832.731746671,
"total_evaluation_time_seconds": "4607.153312789975",
...
}
Training Verifiers to Solve Math Word Problems
@misc{cobbe2021training,
title={Training Verifiers to Solve Math Word Problems},
author={Karl Cobbe and Vineet Kosaraju and Mohammad Bavarian and Jacob Hilton and Reiichiro Nakano and Christopher Hesse and John Schulman},
year={2021},
eprint={2110.14168},
archivePrefix={arXiv},
primaryClass={cs.LG}
}
Ghost 8B Beta was evaluated with the task "gpqa_diamond_cot_zeroshot", the model scored approximately 27%. Overall, so you can easily visualize we have compiled a leaderboard so you can understand the model's capabilities in an overview.
| tasks | version | filter | n shot | metric | value | std error |
|---|---|---|---|---|---|---|
| gpqa_diamond_cot_zeroshot | 1 | flexible-extract | 0 | exact_match | 0.2676 | 0.0315 |
Leaderboard
The rankings are referenced from this article.
| model | accuracy | methodology |
|---|---|---|
| Claude 3 Opus | 50.4% | Zero-shot CoT |
| Claude 3 Sonet | 40.4% | Zero-shot CoT |
| GPT-4 | 35.7% | Zero-shot CoT |
| Claude 3 Haiku | 33.3% | Zero-shot CoT |
| GPT-3.5 | 28.1% | Zero-shot CoT |
| Ghost 8B Beta (d0x5) | 26.7% | Zero-shot CoT |
{
"results": {
"gpqa_diamond_cot_zeroshot": {
"alias": "gpqa_diamond_cot_zeroshot",
"exact_match,strict-match": 0.005050505050505051,
"exact_match_stderr,strict-match": 0.005050505050505052,
"exact_match,flexible-extract": 0.2676767676767677,
"exact_match_stderr,flexible-extract": 0.03154449888270285
}
},
"model_source": "hf",
"model_name": "lamhieu/ghost-8b-beta-disl-0x5",
"model_name_sanitized": "lamhieu__ghost-8b-beta-disl-0x5",
"start_time": 1290603.02832825,
"end_time": 1294954.839677157,
"total_evaluation_time_seconds": "4351.811348907184"
...
}
GPQA: A Graduate-Level Google-Proof Q&A Benchmark.
@misc{rein2023gpqa,
title={GPQA: A Graduate-Level Google-Proof Q&A Benchmark},
author={David Rein and Betty Li Hou and Asa Cooper Stickland and Jackson Petty and Richard Yuanzhe Pang and Julien Dirani and Julian Michael and Samuel R. Bowman},
year={2023},
eprint={2311.12022},
archivePrefix={arXiv},
primaryClass={cs.AI}
}
Ghost 8B Beta was evaluated with the task "leaderboard_mmlu_pro", the model scored 30%. Overall, so you can easily visualize we have compiled a leaderboard so you can understand the model's capabilities in an overview.
| tasks | version | filter | n shot | metric | value | std error |
|---|---|---|---|---|---|---|
| leaderboard_mmlu_pro | 0.1 | none | 5 | acc | 0.3042 | 0.0042 |
Leaderboard
The rankings are referenced from this leaderboard.
| model | accuracy | methodology |
|---|---|---|
| Qwen 2 72B Instruct | 48.92% | 5-shot |
| Llama 3 70B Instruct | 46.74% | 5-shot |
| Deepseek LLM 67B Chat | 32.72% | 5-shot |
| Ghost 8B Beta (d0x5) | 30.42% | 5-shot |
| DBRX Instruct 132B | 29.81% | 5-shot |
| Llama 3 8B Instruct | 29.60% | 5-shot |
| SOLAR 10.7B v1.0 | 26.67% | 5-shot |
| C4AI Command-R 35B | 26.33% | 5-shot |
| Aya 23 35B | 26.18% | 5-shot |
| Llama 2 70B Chat | 15.92% | 5-shot |
{
"results": {
"leaderboard_mmlu_pro": {
"alias": "leaderboard_mmlu_pro",
"acc,none": 0.30418882978723405,
"acc_stderr,none": 0.004194367367612373
}
},
"model_source": "hf",
"model_name": "lamhieu/ghost-8b-beta-disl-0x5",
"model_name_sanitized": "lamhieu__ghost-8b-beta-disl-0x5",
"start_time": 1759569.60272917,
"end_time": 1761073.963532963,
"total_evaluation_time_seconds": "1504.3608037931845",
...
}
MMLU-Pro: A More Robust and Challenging Multi-Task Language Understanding Benchmark.
@misc{wang2024mmluprorobustchallengingmultitask,
title={MMLU-Pro: A More Robust and Challenging Multi-Task Language
Understanding Benchmark},
author={Yubo Wang and Xueguang Ma and Ge Zhang and Yuansheng Ni and Abhranil Chandra and Shiguang Guo and Weiming Ren and Aaran Arulraj and Xuan He and Ziyan Jiang and Tianle Li and Max Ku and Kai Wang and Alex Zhuang and Rongqi Fan and Xiang Yue and Wenhu Chen},
year={2024},
eprint={2406.01574},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2406.01574},
}
Other evaluations will be done soon and updated here later.
If the model is interesting or helpful to your work, feel free to buy me a beer and let's raise a glass. It will motivate me to improve the model in the future. 🍻

The project sends sincere thanks to friends, including...

Meta, for providing a great foundational model.

Unsloth, a great tool that helps us easily develop products, at a lower cost than expected.

Kaggle, free GPUs are available to the community for research.
If you want to cooperate, contribute, consult or sponsor, please contact us.
Follow Ghost X to stay updated with the latest information.
If you find our work helpful, feel free to give us a cite.
@misc{ghost-8b-beta,
author = {{Ghost X, Hieu Lam}},
title = {Ghost 8B Beta},
url = {https://ghost-x.org/docs/models/ghost-8b-beta},
year = {2024}
}