
Wav2Vec2-Large-XLSR-53-Arabic
Fine-tuned facebook/wav2vec2-large-xlsr-53
on Arabic using the train splits of Common Voice
and Arabic Speech Corpus.
When using this model, make sure that your speech input is sampled at 16kHz.
Usage
The model can be used directly (without a language model) as follows:
import torch
import torchaudio
from datasets import load_dataset
from lang_trans.arabic import buckwalter
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
dataset = load_dataset("common_voice", "ar", split="test[:10]")
resamplers = { # all three sampling rates exist in test split
48000: torchaudio.transforms.Resample(48000, 16000),
44100: torchaudio.transforms.Resample(44100, 16000),
32000: torchaudio.transforms.Resample(32000, 16000),
}
def prepare_example(example):
speech, sampling_rate = torchaudio.load(example["path"])
example["speech"] = resamplers[sampling_rate](speech).squeeze().numpy()
return example
dataset = dataset.map(prepare_example)
processor = Wav2Vec2Processor.from_pretrained("elgeish/wav2vec2-large-xlsr-53-arabic")
model = Wav2Vec2ForCTC.from_pretrained("elgeish/wav2vec2-large-xlsr-53-arabic").eval()
def predict(batch):
inputs = processor(batch["speech"], sampling_rate=16000, return_tensors="pt", padding=True)
with torch.no_grad():
predicted = torch.argmax(model(inputs.input_values).logits, dim=-1)
predicted[predicted == -100] = processor.tokenizer.pad_token_id # see fine-tuning script
batch["predicted"] = processor.tokenizer.batch_decode(predicted)
return batch
dataset = dataset.map(predict, batched=True, batch_size=1, remove_columns=["speech"])
for reference, predicted in zip(dataset["sentence"], dataset["predicted"]):
print("reference:", reference)
print("predicted:", buckwalter.untrans(predicted))
print("--")
Here's the output:
reference: ألديك قلم ؟
predicted: هلديك قالر
--
reference: ليست هناك مسافة على هذه الأرض أبعد من يوم أمس.
predicted: ليست نالك مسافة على هذه الأرض أبعد من يوم أمس
--
reference: إنك تكبر المشكلة.
predicted: إنك تكبر المشكلة
--
reference: يرغب أن يلتقي بك.
predicted: يرغب أن يلتقي بك
--
reference: إنهم لا يعرفون لماذا حتى.
predicted: إنهم لا يعرفون لماذا حتى
--
reference: سيسعدني مساعدتك أي وقت تحب.
predicted: سيسئدني مساعد سكرأي وقت تحب
--
reference: أَحَبُّ نظريّة علمية إليّ هي أن حلقات زحل مكونة بالكامل من الأمتعة المفقودة.
predicted: أحب ناضريةً علمية إلي هي أنحل قتزح المكونا بالكامل من الأمت عن المفقودة
--
reference: سأشتري له قلماً.
predicted: سأشتري له قلما
--
reference: أين المشكلة ؟
predicted: أين المشكل
--
reference: وَلِلَّهِ يَسْجُدُ مَا فِي السَّمَاوَاتِ وَمَا فِي الْأَرْضِ مِنْ دَابَّةٍ وَالْمَلَائِكَةُ وَهُمْ لَا يَسْتَكْبِرُونَ
predicted: ولله يسجد ما في السماوات وما في الأرض من دابة والملائكة وهم لا يستكبرون
--
Evaluation
The model can be evaluated as follows on the Arabic test data of Common Voice:
import jiwer
import torch
import torchaudio
from datasets import load_dataset
from lang_trans.arabic import buckwalter
from transformers import set_seed, Wav2Vec2ForCTC, Wav2Vec2Processor
set_seed(42)
test_split = load_dataset("common_voice", "ar", split="test")
resamplers = { # all three sampling rates exist in test split
48000: torchaudio.transforms.Resample(48000, 16000),
44100: torchaudio.transforms.Resample(44100, 16000),
32000: torchaudio.transforms.Resample(32000, 16000),
}
def prepare_example(example):
speech, sampling_rate = torchaudio.load(example["path"])
example["speech"] = resamplers[sampling_rate](speech).squeeze().numpy()
return example
test_split = test_split.map(prepare_example)
processor = Wav2Vec2Processor.from_pretrained("elgeish/wav2vec2-large-xlsr-53-arabic")
model = Wav2Vec2ForCTC.from_pretrained("elgeish/wav2vec2-large-xlsr-53-arabic").to("cuda").eval()
def predict(batch):
inputs = processor(batch["speech"], sampling_rate=16000, return_tensors="pt", padding=True)
with torch.no_grad():
predicted = torch.argmax(model(inputs.input_values.to("cuda")).logits, dim=-1)
predicted[predicted == -100] = processor.tokenizer.pad_token_id # see fine-tuning script
batch["predicted"] = processor.batch_decode(predicted)
return batch
test_split = test_split.map(predict, batched=True, batch_size=16, remove_columns=["speech"])
transformation = jiwer.Compose([
# normalize some diacritics, remove punctuation, and replace Persian letters with Arabic ones
jiwer.SubstituteRegexes({
r'[auiFNKo\~_،؟»\?;:\-,\.؛«!"]': "", "\u06D6": "",
r"[\|\{]": "A", "p": "h", "ک": "k", "ی": "y"}),
# default transformation below
jiwer.RemoveMultipleSpaces(),
jiwer.Strip(),
jiwer.SentencesToListOfWords(),
jiwer.RemoveEmptyStrings(),
])
metrics = jiwer.compute_measures(
truth=[buckwalter.trans(s) for s in test_split["sentence"]], # Buckwalter transliteration
hypothesis=test_split["predicted"],
truth_transform=transformation,
hypothesis_transform=transformation,
)
print(f"WER: {metrics['wer']:.2%}")
Test Result: 26.55%
Training
For more details, see Fine-Tuning with Arabic Speech Corpus.
This model represents Arabic in a format called Buckwalter transliteration.
The Buckwalter format only includes ASCII characters, some of which are non-alpha (e.g., ">" maps to "أ").
The lang-trans package is used to convert (transliterate) Arabic abjad.
This script
was used to first fine-tune facebook/wav2vec2-large-xlsr-53
on the train split of the Arabic Speech Corpus dataset;
the test split was used for model selection; the resulting model at this point is saved as elgeish/wav2vec2-large-xlsr-53-levantine-arabic.
Training was then resumed using the train split of the Common Voice dataset;
the validation split was used for model selection;
training was stopped to meet the deadline of Fine-Tune-XLSR Week:
this model is the checkpoint at 100k steps and a validation WER of 23.39%.
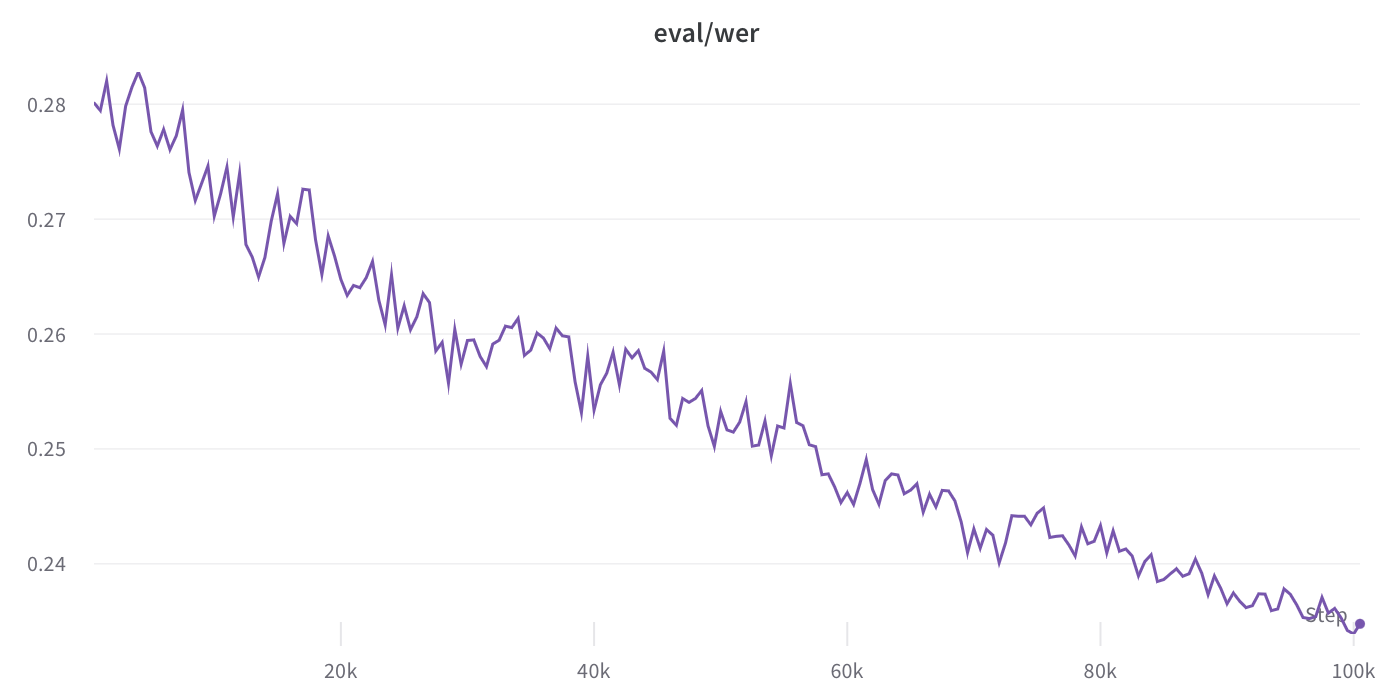
It's worth noting that validation WER is trending down, indicating the potential of further training (resuming the decaying learning rate at 7e-6).
Future Work
One area to explore is using attention_mask in model input, which is recommended here.
Also, exploring data augmentation using datasets used to train models listed here.
- Downloads last month
- 608
Model tree for elgeish/wav2vec2-large-xlsr-53-arabic
Datasets used to train elgeish/wav2vec2-large-xlsr-53-arabic
Spaces using elgeish/wav2vec2-large-xlsr-53-arabic 2
Evaluation results
- Test WER on Common Voice 6.1 (Arabic)test set self-reported26.550
- Validation WER on Common Voice 6.1 (Arabic)test set self-reported23.390