BridgeTower
Overview
The BridgeTower model was proposed in BridgeTower: Building Bridges Between Encoders in Vision-Language Representative Learning by Xiao Xu, Chenfei Wu, Shachar Rosenman, Vasudev Lal, Wanxiang Che, Nan Duan. The goal of this model is to build a bridge between each uni-modal encoder and the cross-modal encoder to enable comprehensive and detailed interaction at each layer of the cross-modal encoder thus achieving remarkable performance on various downstream tasks with almost negligible additional performance and computational costs.
This paper has been accepted to the AAAI’23 conference.
The abstract from the paper is the following:
Vision-Language (VL) models with the TWO-TOWER architecture have dominated visual-language representation learning in recent years. Current VL models either use lightweight uni-modal encoders and learn to extract, align and fuse both modalities simultaneously in a deep cross-modal encoder, or feed the last-layer uni-modal representations from the deep pre-trained uni-modal encoders into the top cross-modal encoder. Both approaches potentially restrict vision-language representation learning and limit model performance. In this paper, we propose BRIDGETOWER, which introduces multiple bridge layers that build a connection between the top layers of uni-modal encoders and each layer of the crossmodal encoder. This enables effective bottom-up cross-modal alignment and fusion between visual and textual representations of different semantic levels of pre-trained uni-modal encoders in the cross-modal encoder. Pre-trained with only 4M images, BRIDGETOWER achieves state-of-the-art performance on various downstream vision-language tasks. In particular, on the VQAv2 test-std set, BRIDGETOWER achieves an accuracy of 78.73%, outperforming the previous state-of-the-art model METER by 1.09% with the same pre-training data and almost negligible additional parameters and computational costs. Notably, when further scaling the model, BRIDGETOWER achieves an accuracy of 81.15%, surpassing models that are pre-trained on orders-of-magnitude larger datasets.
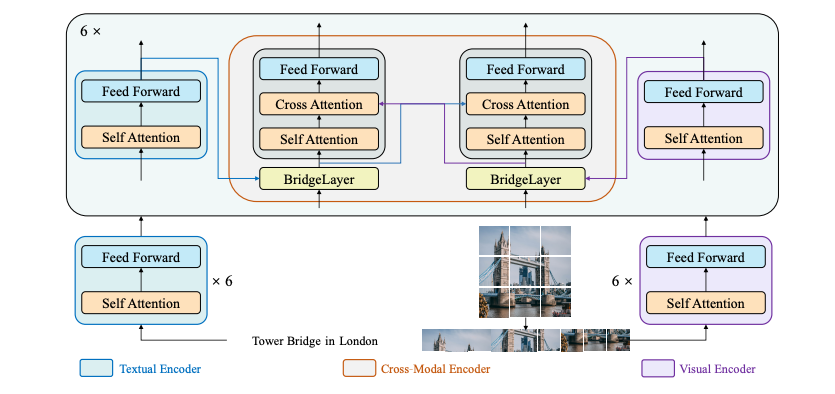 BridgeTower architecture. Taken from the original paper.
BridgeTower architecture. Taken from the original paper. Usage
BridgeTower consists of a visual encoder, a textual encoder and cross-modal encoder with multiple lightweight bridge layers. The goal of this approach was to build a bridge between each uni-modal encoder and the cross-modal encoder to enable comprehensive and detailed interaction at each layer of the cross-modal encoder. In principle, one can apply any visual, textual or cross-modal encoder in the proposed architecture.
The BridgeTowerProcessor wraps RobertaTokenizer and BridgeTowerImageProcessor into a single instance to both encode the text and prepare the images respectively.
The following example shows how to run contrastive learning using BridgeTowerProcessor and BridgeTowerForContrastiveLearning.
>>> from transformers import BridgeTowerProcessor, BridgeTowerForContrastiveLearning
>>> import requests
>>> from PIL import Image
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> texts = ["An image of two cats chilling on a couch", "A football player scoring a goal"]
>>> processor = BridgeTowerProcessor.from_pretrained("BridgeTower/bridgetower-large-itm-mlm-itc")
>>> model = BridgeTowerForContrastiveLearning.from_pretrained("BridgeTower/bridgetower-large-itm-mlm-itc")
>>> # forward pass
>>> scores = dict()
>>> for text in texts:
... # prepare inputs
... encoding = processor(image, text, return_tensors="pt")
... outputs = model(**encoding)
... scores[text] = outputsThe following example shows how to run image-text retrieval using BridgeTowerProcessor and BridgeTowerForImageAndTextRetrieval.
>>> from transformers import BridgeTowerProcessor, BridgeTowerForImageAndTextRetrieval
>>> import requests
>>> from PIL import Image
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> texts = ["An image of two cats chilling on a couch", "A football player scoring a goal"]
>>> processor = BridgeTowerProcessor.from_pretrained("BridgeTower/bridgetower-base-itm-mlm")
>>> model = BridgeTowerForImageAndTextRetrieval.from_pretrained("BridgeTower/bridgetower-base-itm-mlm")
>>> # forward pass
>>> scores = dict()
>>> for text in texts:
... # prepare inputs
... encoding = processor(image, text, return_tensors="pt")
... outputs = model(**encoding)
... scores[text] = outputs.logits[0, 1].item()The following example shows how to run masked language modeling using BridgeTowerProcessor and BridgeTowerForMaskedLM.
>>> from transformers import BridgeTowerProcessor, BridgeTowerForMaskedLM
>>> from PIL import Image
>>> import requests
>>> url = "http://images.cocodataset.org/val2017/000000360943.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw).convert("RGB")
>>> text = "a <mask> looking out of the window"
>>> processor = BridgeTowerProcessor.from_pretrained("BridgeTower/bridgetower-base-itm-mlm")
>>> model = BridgeTowerForMaskedLM.from_pretrained("BridgeTower/bridgetower-base-itm-mlm")
>>> # prepare inputs
>>> encoding = processor(image, text, return_tensors="pt")
>>> # forward pass
>>> outputs = model(**encoding)
>>> results = processor.decode(outputs.logits.argmax(dim=-1).squeeze(0).tolist())
>>> print(results)
.a cat looking out of the window.This model was contributed by Anahita Bhiwandiwalla, Tiep Le and Shaoyen Tseng. The original code can be found here.
Tips:
- This implementation of BridgeTower uses RobertaTokenizer to generate text embeddings and OpenAI’s CLIP/ViT model to compute visual embeddings.
- Checkpoints for pre-trained bridgeTower-base and bridgetower masked language modeling and image text matching are released.
- Please refer to Table 5 for BridgeTower’s performance on Image Retrieval and other down stream tasks.
- The PyTorch version of this model is only available in torch 1.10 and higher.
BridgeTowerConfig
class transformers.BridgeTowerConfig
< source >( share_cross_modal_transformer_layers = True hidden_act = 'gelu' hidden_size = 768 initializer_factor = 1 layer_norm_eps = 1e-05 share_link_tower_layers = False link_tower_type = 'add' num_attention_heads = 12 num_hidden_layers = 6 tie_word_embeddings = False init_layernorm_from_vision_encoder = False text_config = None vision_config = None **kwargs )
Parameters
- share_cross_modal_transformer_layers (
bool, optional, defaults toTrue) — Whether cross modal transformer layers are shared. - hidden_act (
strorfunction, optional, defaults to"gelu") — The non-linear activation function (function or string) in the encoder and pooler. - hidden_size (
int, optional, defaults to 768) — Dimensionality of the encoder layers and the pooler layer. - initializer_factor (`float“, optional, defaults to 1) — A factor for initializing all weight matrices (should be kept to 1, used internally for initialization testing).
- layer_norm_eps (
float, optional, defaults to 1e-05) — The epsilon used by the layer normalization layers. - share_link_tower_layers (
bool, optional, defaults toFalse) — Whether the bride/link tower layers are shared. - link_tower_type (
str, optional, defaults to"add") — Type of the bridge/link layer. - num_attention_heads (
int, optional, defaults to 12) — Number of attention heads for each attention layer in the Transformer encoder. - num_hidden_layers (
int, optional, defaults to 6) — Number of hidden layers in the Transformer encoder. - tie_word_embeddings (
bool, optional, defaults toFalse) — Whether to tie input and output embeddings. - init_layernorm_from_vision_encoder (
bool, optional, defaults toFalse) — Whether to init LayerNorm from the vision encoder. - text_config (
dict, optional) — Dictionary of configuration options used to initialize BridgeTowerTextConfig. - vision_config (
dict, optional) — Dictionary of configuration options used to initialize BridgeTowerVisionConfig.
This is the configuration class to store the configuration of a BridgeTowerModel. It is used to instantiate a BridgeTower model according to the specified arguments, defining the model architecture. Instantiating a configuration with the defaults will yield a similar configuration to that of the bridgetower-base BridgeTower/bridgetower-base architecture.
Configuration objects inherit from PretrainedConfig and can be used to control the model outputs. Read the documentation from PretrainedConfig for more information.
Example:
>>> from transformers import BridgeTowerModel, BridgeTowerConfig
>>> # Initializing a BridgeTower BridgeTower/bridgetower-base style configuration
>>> configuration = BridgeTowerConfig()
>>> # Initializing a model from the BridgeTower/bridgetower-base style configuration
>>> model = BridgeTowerModel(configuration)
>>> # Accessing the model configuration
>>> configuration = model.configfrom_text_vision_configs
< source >( text_config: BridgeTowerTextConfig vision_config: BridgeTowerVisionConfig **kwargs )
Instantiate a BridgeTowerConfig (or a derived class) from BridgeTower text model configuration. Returns: BridgeTowerConfig: An instance of a configuration object
BridgeTowerTextConfig
class transformers.BridgeTowerTextConfig
< source >( vocab_size = 50265 hidden_size = 768 num_hidden_layers = 12 num_attention_heads = 12 initializer_factor = 1 intermediate_size = 3072 hidden_act = 'gelu' hidden_dropout_prob = 0.1 attention_probs_dropout_prob = 0.1 max_position_embeddings = 514 type_vocab_size = 1 layer_norm_eps = 1e-05 pad_token_id = 1 bos_token_id = 0 eos_token_id = 2 position_embedding_type = 'absolute' use_cache = True **kwargs )
Parameters
- vocab_size (
int, optional, defaults to 50265) — Vocabulary size of the text part of the model. Defines the number of different tokens that can be represented by theinputs_idspassed when calling BridgeTowerModel. - hidden_size (
int, optional, defaults to 768) — Dimensionality of the encoder layers and the pooler layer. - num_hidden_layers (
int, optional, defaults to 12) — Number of hidden layers in the Transformer encoder. - num_attention_heads (
int, optional, defaults to 12) — Number of attention heads for each attention layer in the Transformer encoder. - intermediate_size (
int, optional, defaults to 3072) — Dimensionality of the “intermediate” (often named feed-forward) layer in the Transformer encoder. - hidden_act (
strorCallable, optional, defaults to"gelu") — The non-linear activation function (function or string) in the encoder and pooler. If string,"gelu","relu","silu"and"gelu_new"are supported. - hidden_dropout_prob (
float, optional, defaults to 0.1) — The dropout probability for all fully connected layers in the embeddings, encoder, and pooler. - attention_probs_dropout_prob (
float, optional, defaults to 0.1) — The dropout ratio for the attention probabilities. - max_position_embeddings (
int, optional, defaults to 514) — The maximum sequence length that this model might ever be used with. Typically set this to something large just in case (e.g., 512 or 1024 or 2048). - type_vocab_size (
int, optional, defaults to 2) — The vocabulary size of thetoken_type_ids. - initializer_factor (`float“, optional, defaults to 1) — A factor for initializing all weight matrices (should be kept to 1, used internally for initialization testing).
- layer_norm_eps (
float, optional, defaults to 1e-05) — The epsilon used by the layer normalization layers. - position_embedding_type (
str, optional, defaults to"absolute") — Type of position embedding. Choose one of"absolute","relative_key","relative_key_query". For positional embeddings use"absolute". For more information on"relative_key", please refer to Self-Attention with Relative Position Representations (Shaw et al.). For more information on"relative_key_query", please refer to Method 4 in Improve Transformer Models with Better Relative Position Embeddings (Huang et al.). - is_decoder (
bool, optional, defaults toFalse) — Whether the model is used as a decoder or not. IfFalse, the model is used as an encoder. - use_cache (
bool, optional, defaults toTrue) — Whether or not the model should return the last key/values attentions (not used by all models). Only relevant ifconfig.is_decoder=True.
This is the configuration class to store the text configuration of a BridgeTowerModel. The default values here are copied from RoBERTa. Instantiating a configuration with the defaults will yield a similar configuration to that of the bridgetower-base BridegTower/bridgetower-base architecture.
Configuration objects inherit from PretrainedConfig and can be used to control the model outputs. Read the documentation from PretrainedConfig for more information.
BridgeTowerVisionConfig
class transformers.BridgeTowerVisionConfig
< source >( hidden_size = 768 num_hidden_layers = 12 num_channels = 3 patch_size = 16 image_size = 288 initializer_factor = 1 layer_norm_eps = 1e-05 stop_gradient = False share_layernorm = True remove_last_layer = False **kwargs )
Parameters
- hidden_size (
int, optional, defaults to 768) — Dimensionality of the encoder layers and the pooler layer. - num_hidden_layers (
int, optional, defaults to 12) — Number of hidden layers in visual encoder model. - patch_size (
int, optional, defaults to 16) — The size (resolution) of each patch. - image_size (
int, optional, defaults to 288) — The size (resolution) of each image. - initializer_factor (`float“, optional, defaults to 1) — A factor for initializing all weight matrices (should be kept to 1, used internally for initialization testing).
- layer_norm_eps (
float, optional, defaults to 1e-05) — The epsilon used by the layer normalization layers. - stop_gradient (
bool, optional, defaults toFalse) — Whether to stop gradient for training. - share_layernorm (
bool, optional, defaults toTrue) — Whether LayerNorm layers are shared. - remove_last_layer (
bool, optional, defaults toFalse) — Whether to remove the last layer from the vision encoder.
This is the configuration class to store the vision configuration of a BridgeTowerModel. Instantiating a configuration with the defaults will yield a similar configuration to that of the bridgetower-base BridgeTower/bridgetower-base architecture.
Configuration objects inherit from PretrainedConfig and can be used to control the model outputs. Read the documentation from PretrainedConfig for more information.
BridgeTowerImageProcessor
class transformers.BridgeTowerImageProcessor
< source >( do_resize: bool = True size: typing.Dict[str, int] = 288 size_divisor: int = 32 resample: Resampling = <Resampling.BICUBIC: 3> do_rescale: bool = True rescale_factor: typing.Union[int, float] = 0.00392156862745098 do_normalize: bool = True image_mean: typing.Union[float, typing.List[float], NoneType] = None image_std: typing.Union[float, typing.List[float], NoneType] = None do_center_crop: bool = True do_pad: bool = True **kwargs )
Parameters
- do_resize (
bool, optional, defaults toTrue) — Whether to resize the image’s (height, width) dimensions to the specifiedsize. Can be overridden by thedo_resizeparameter in thepreprocessmethod. - size (
Dict[str, int]optional, defaults to288) — Resize the shorter side of the input tosize["shortest_edge"]. The longer side will be limited to underint((1333 / 800) * size["shortest_edge"])while preserving the aspect ratio. Only has an effect ifdo_resizeis set toTrue. Can be overridden by thesizeparameter in thepreprocessmethod. - size_divisor (
int, optional, defaults to 32) — The size by which to make sure both the height and width can be divided. Only has an effect ifdo_resizeis set toTrue. Can be overridden by thesize_divisorparameter in thepreprocessmethod. - resample (
PILImageResampling, optional, defaults toPILImageResampling.BICUBIC) — Resampling filter to use if resizing the image. Only has an effect ifdo_resizeis set toTrue. Can be overridden by theresampleparameter in thepreprocessmethod. - do_rescale (
bool, optional, defaults toTrue) — Whether to rescale the image by the specified scalerescale_factor. Can be overridden by thedo_rescaleparameter in thepreprocessmethod. - rescale_factor (
intorfloat, optional, defaults to1/255) — Scale factor to use if rescaling the image. Only has an effect ifdo_rescaleis set toTrue. Can be overridden by therescale_factorparameter in thepreprocessmethod. - do_normalize (
bool, optional, defaults toTrue) — Whether to normalize the image. Can be overridden by thedo_normalizeparameter in thepreprocessmethod. Can be overridden by thedo_normalizeparameter in thepreprocessmethod. - image_mean (
floatorList[float], optional, defaults toIMAGENET_STANDARD_MEAN) — Mean to use if normalizing the image. This is a float or list of floats the length of the number of channels in the image. Can be overridden by theimage_meanparameter in thepreprocessmethod. Can be overridden by theimage_meanparameter in thepreprocessmethod. - image_std (
floatorList[float], optional, defaults toIMAGENET_STANDARD_STD) — Standard deviation to use if normalizing the image. This is a float or list of floats the length of the number of channels in the image. Can be overridden by theimage_stdparameter in thepreprocessmethod. Can be overridden by theimage_stdparameter in thepreprocessmethod. - do_center_crop (
bool, optional, defaults toTrue) — Whether to center crop the image. Can be overridden by thedo_center_cropparameter in thepreprocessmethod. - do_pad (
bool, optional, defaults toTrue) — Whether to pad the image to the(max_height, max_width)of the images in the batch. Can be overridden by thedo_padparameter in thepreprocessmethod.
Constructs a BridgeTower image processor.
preprocess
< source >( images: typing.Union[ForwardRef('PIL.Image.Image'), numpy.ndarray, ForwardRef('torch.Tensor'), typing.List[ForwardRef('PIL.Image.Image')], typing.List[numpy.ndarray], typing.List[ForwardRef('torch.Tensor')]] do_resize: typing.Optional[bool] = None size: typing.Union[typing.Dict[str, int], NoneType] = None size_divisor: typing.Optional[int] = None resample: Resampling = None do_rescale: typing.Optional[bool] = None rescale_factor: typing.Optional[float] = None do_normalize: typing.Optional[bool] = None image_mean: typing.Union[float, typing.List[float], NoneType] = None image_std: typing.Union[float, typing.List[float], NoneType] = None do_pad: typing.Optional[bool] = None do_center_crop: typing.Optional[bool] = None return_tensors: typing.Union[str, transformers.utils.generic.TensorType, NoneType] = None data_format: ChannelDimension = <ChannelDimension.FIRST: 'channels_first'> input_data_format: typing.Union[str, transformers.image_utils.ChannelDimension, NoneType] = None **kwargs )
Parameters
- images (
ImageInput) — Image to preprocess. Expects a single or batch of images with pixel values ranging from 0 to 255. If passing in images with pixel values between 0 and 1, setdo_rescale=False. - do_resize (
bool, optional, defaults toself.do_resize) — Whether to resize the image. - size (
Dict[str, int], optional, defaults toself.size) — Controls the size of the image afterresize. The shortest edge of the image is resized tosize["shortest_edge"]whilst preserving the aspect ratio. If the longest edge of this resized image is >int(size["shortest_edge"] * (1333 / 800)), then the image is resized again to make the longest edge equal toint(size["shortest_edge"] * (1333 / 800)). - size_divisor (
int, optional, defaults toself.size_divisor) — The image is resized to a size that is a multiple of this value. - resample (
PILImageResampling, optional, defaults toself.resample) — Resampling filter to use if resizing the image. Only has an effect ifdo_resizeis set toTrue. - do_rescale (
bool, optional, defaults toself.do_rescale) — Whether to rescale the image values between [0 - 1]. - rescale_factor (
float, optional, defaults toself.rescale_factor) — Rescale factor to rescale the image by ifdo_rescaleis set toTrue. - do_normalize (
bool, optional, defaults toself.do_normalize) — Whether to normalize the image. - image_mean (
floatorList[float], optional, defaults toself.image_mean) — Image mean to normalize the image by ifdo_normalizeis set toTrue. - image_std (
floatorList[float], optional, defaults toself.image_std) — Image standard deviation to normalize the image by ifdo_normalizeis set toTrue. - do_pad (
bool, optional, defaults toself.do_pad) — Whether to pad the image to the (max_height, max_width) in the batch. IfTrue, a pixel mask is also created and returned. - do_center_crop (
bool, optional, defaults toself.do_center_crop) — Whether to center crop the image. If the input size is smaller thancrop_sizealong any edge, the image is padded with 0’s and then center cropped. - return_tensors (
strorTensorType, optional) — The type of tensors to return. Can be one of:- Unset: Return a list of
np.ndarray. TensorType.TENSORFLOWor'tf': Return a batch of typetf.Tensor.TensorType.PYTORCHor'pt': Return a batch of typetorch.Tensor.TensorType.NUMPYor'np': Return a batch of typenp.ndarray.TensorType.JAXor'jax': Return a batch of typejax.numpy.ndarray.
- Unset: Return a list of
- data_format (
ChannelDimensionorstr, optional, defaults toChannelDimension.FIRST) — The channel dimension format for the output image. Can be one of:"channels_first"orChannelDimension.FIRST: image in (num_channels, height, width) format."channels_last"orChannelDimension.LAST: image in (height, width, num_channels) format.- Unset: Use the channel dimension format of the input image.
- input_data_format (
ChannelDimensionorstr, optional) — The channel dimension format for the input image. If unset, the channel dimension format is inferred from the input image. Can be one of:"channels_first"orChannelDimension.FIRST: image in (num_channels, height, width) format."channels_last"orChannelDimension.LAST: image in (height, width, num_channels) format."none"orChannelDimension.NONE: image in (height, width) format.
Preprocess an image or batch of images.
BridgeTowerProcessor
class transformers.BridgeTowerProcessor
< source >( image_processor tokenizer )
Parameters
- image_processor (
BridgeTowerImageProcessor) — An instance of BridgeTowerImageProcessor. The image processor is a required input. - tokenizer (
RobertaTokenizerFast) — An instance of [‘RobertaTokenizerFast`]. The tokenizer is a required input.
Constructs a BridgeTower processor which wraps a Roberta tokenizer and BridgeTower image processor into a single processor.
BridgeTowerProcessor offers all the functionalities of BridgeTowerImageProcessor and
RobertaTokenizerFast. See the docstring of call() and
decode() for more information.
__call__
< source >( images text: typing.Union[str, typing.List[str], typing.List[typing.List[str]]] = None add_special_tokens: bool = True padding: typing.Union[bool, str, transformers.utils.generic.PaddingStrategy] = False truncation: typing.Union[bool, str, transformers.tokenization_utils_base.TruncationStrategy] = None max_length: typing.Optional[int] = None stride: int = 0 pad_to_multiple_of: typing.Optional[int] = None return_token_type_ids: typing.Optional[bool] = None return_attention_mask: typing.Optional[bool] = None return_overflowing_tokens: bool = False return_special_tokens_mask: bool = False return_offsets_mapping: bool = False return_length: bool = False verbose: bool = True return_tensors: typing.Union[str, transformers.utils.generic.TensorType, NoneType] = None **kwargs )
This method uses BridgeTowerImageProcessor.call() method to prepare image(s) for the model, and RobertaTokenizerFast.call() to prepare text for the model.
Please refer to the docstring of the above two methods for more information.
BridgeTowerModel
class transformers.BridgeTowerModel
< source >( config )
Parameters
- config (BridgeTowerConfig) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the from_pretrained() method to load the model weights.
The bare BridgeTower Model transformer outputting BridgeTowerModelOutput object without any specific head on top.
This model is a PyTorch torch.nn.Module <https://pytorch.org/docs/stable/nn.html#torch.nn.Module>_ subclass. Use
it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and
behavior.
forward
< source >( input_ids: typing.Optional[torch.LongTensor] = None attention_mask: typing.Optional[torch.FloatTensor] = None token_type_ids: typing.Optional[torch.LongTensor] = None pixel_values: typing.Optional[torch.FloatTensor] = None pixel_mask: typing.Optional[torch.LongTensor] = None head_mask: typing.Optional[torch.FloatTensor] = None inputs_embeds: typing.Optional[torch.FloatTensor] = None image_embeds: typing.Optional[torch.FloatTensor] = None image_token_type_idx: typing.Optional[int] = None output_attentions: typing.Optional[bool] = None output_hidden_states: typing.Optional[bool] = None return_dict: typing.Optional[bool] = None labels: typing.Optional[torch.LongTensor] = None ) → transformers.models.bridgetower.modeling_bridgetower.BridgeTowerModelOutput or tuple(torch.FloatTensor)
Parameters
- input_ids (
torch.LongTensorof shape({0})) — Indices of input sequence tokens in the vocabulary. Indices can be obtained using AutoTokenizer. See PreTrainedTokenizer.encode() and PreTrainedTokenizer.call() for details. What are input IDs? - attention_mask (
torch.FloatTensorof shape({0}), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked. What are attention masks?
- token_type_ids (
torch.LongTensorof shape({0}), optional) — Segment token indices to indicate first and second portions of the inputs. Indices are selected in[0, 1]:- 0 corresponds to a sentence A token,
- 1 corresponds to a sentence B token. What are token type IDs?
- pixel_values (
torch.FloatTensorof shape(batch_size, num_channels, height, width)) — Pixel values. Pixel values can be obtained using BridgeTowerImageProcessor. See BridgeTowerImageProcessor.call() for details. - pixel_mask (
torch.LongTensorof shape(batch_size, height, width), optional) — Mask to avoid performing attention on padding pixel values. Mask values selected in[0, 1]:- 1 for pixels that are real (i.e. not masked),
- 0 for pixels that are padding (i.e. masked).
What are attention masks? <../glossary.html#attention-mask>__
- head_mask (
torch.FloatTensorof shape(num_heads,)or(num_layers, num_heads), optional) — Mask to nullify selected heads of the self-attention modules. Mask values selected in[0, 1]:- 1 indicates the head is not masked,
- 0 indicates the head is masked.
- inputs_embeds (
torch.FloatTensorof shape({0}, hidden_size), optional) — Optionally, instead of passinginput_idsyou can choose to directly pass an embedded representation. This is useful if you want more control over how to convertinput_idsindices into associated vectors than the model’s internal embedding lookup matrix. - image_embeds (
torch.FloatTensorof shape(batch_size, num_patches, hidden_size), optional) — Optionally, instead of passingpixel_values, you can choose to directly pass an embedded representation. This is useful if you want more control over how to convertpixel_valuesinto patch embeddings. - image_token_type_idx (
int, optional) —- The token type ids for images.
- output_attentions (
bool, optional) — Whether or not to return the attentions tensors of all attention layers. Seeattentionsunder returned tensors for more detail. - output_hidden_states (
bool, optional) — Whether or not to return the hidden states of all layers. Seehidden_statesunder returned tensors for more detail. - return_dict (
bool, optional) — Whether or not to return a ModelOutput instead of a plain tuple. - output_hidden_states (
bool, optional) — If set toTrue, hidden states are returned as a list containing the hidden states of text, image, and cross-modal components respectively. i.e.(hidden_states_text, hidden_states_image, hidden_states_cross_modal)where each element is a list of the hidden states of the corresponding modality.hidden_states_txt/imgare a list of tensors corresponding to unimodal hidden states andhidden_states_cross_modalis a list of tuples containingcross_modal_text_hidden_statesandcross_modal_image_hidden_statesof each brdige layer. - labels (
torch.LongTensorof shape(batch_size,), optional) — Labels are currently not supported.
Returns
transformers.models.bridgetower.modeling_bridgetower.BridgeTowerModelOutput or tuple(torch.FloatTensor)
A transformers.models.bridgetower.modeling_bridgetower.BridgeTowerModelOutput or a tuple of
torch.FloatTensor (if return_dict=False is passed or when config.return_dict=False) comprising various
elements depending on the configuration (BridgeTowerConfig) and inputs.
-
text_features (
torch.FloatTensorof shape(batch_size, text_sequence_length, hidden_size)) — Sequence of hidden-states at the text output of the last layer of the model. -
image_features (
torch.FloatTensorof shape(batch_size, image_sequence_length, hidden_size)) — Sequence of hidden-states at the image output of the last layer of the model. -
pooler_output (
torch.FloatTensorof shape(batch_size, hidden_size x 2)) — Concatenation of last layer hidden-state of the first token of the text and image sequence (classification token), respectively, after further processing through layers used for auxiliary pretraining tasks. -
hidden_states (
tuple(torch.FloatTensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftorch.FloatTensor(one for the output of the embeddings, if the model has an embedding layer, + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size). Hidden-states of the model at the output of each layer plus the optional initial embedding outputs. -
attentions (
tuple(torch.FloatTensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length).Attentions weights after the attention softmax, used to compute the weighted average in the self-attention heads.
The BridgeTowerModel forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Module
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
Examples:
>>> from transformers import BridgeTowerProcessor, BridgeTowerModel
>>> from PIL import Image
>>> import requests
>>> # prepare image and text
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> text = "hello world"
>>> processor = BridgeTowerProcessor.from_pretrained("BridgeTower/bridgetower-base")
>>> model = BridgeTowerModel.from_pretrained("BridgeTower/bridgetower-base")
>>> inputs = processor(image, text, return_tensors="pt")
>>> outputs = model(**inputs)
>>> outputs.keys()
odict_keys(['text_features', 'image_features', 'pooler_output'])BridgeTowerForContrastiveLearning
class transformers.BridgeTowerForContrastiveLearning
< source >( config )
Parameters
- config (BridgeTowerConfig) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the from_pretrained() method to load the model weights.
BridgeTower Model with a image-text contrastive head on top computing image-text contrastive loss.
This model is a PyTorch torch.nn.Module <https://pytorch.org/docs/stable/nn.html#torch.nn.Module>_ subclass. Use
it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and
behavior.
forward
< source >( input_ids: typing.Optional[torch.LongTensor] = None attention_mask: typing.Optional[torch.FloatTensor] = None token_type_ids: typing.Optional[torch.LongTensor] = None pixel_values: typing.Optional[torch.FloatTensor] = None pixel_mask: typing.Optional[torch.LongTensor] = None head_mask: typing.Optional[torch.FloatTensor] = None inputs_embeds: typing.Optional[torch.FloatTensor] = None image_embeds: typing.Optional[torch.FloatTensor] = None output_attentions: typing.Optional[bool] = None output_hidden_states: typing.Optional[bool] = True return_dict: typing.Optional[bool] = None return_loss: typing.Optional[bool] = None ) → transformers.models.bridgetower.modeling_bridgetower.BridgeTowerContrastiveOutput or tuple(torch.FloatTensor)
Parameters
- input_ids (
torch.LongTensorof shape({0})) — Indices of input sequence tokens in the vocabulary. Indices can be obtained using AutoTokenizer. See PreTrainedTokenizer.encode() and PreTrainedTokenizer.call() for details. What are input IDs? - attention_mask (
torch.FloatTensorof shape({0}), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked. What are attention masks?
- token_type_ids (
torch.LongTensorof shape({0}), optional) — Segment token indices to indicate first and second portions of the inputs. Indices are selected in[0, 1]:- 0 corresponds to a sentence A token,
- 1 corresponds to a sentence B token. What are token type IDs?
- pixel_values (
torch.FloatTensorof shape(batch_size, num_channels, height, width)) — Pixel values. Pixel values can be obtained using BridgeTowerImageProcessor. See BridgeTowerImageProcessor.call() for details. - pixel_mask (
torch.LongTensorof shape(batch_size, height, width), optional) — Mask to avoid performing attention on padding pixel values. Mask values selected in[0, 1]:- 1 for pixels that are real (i.e. not masked),
- 0 for pixels that are padding (i.e. masked).
What are attention masks? <../glossary.html#attention-mask>__
- head_mask (
torch.FloatTensorof shape(num_heads,)or(num_layers, num_heads), optional) — Mask to nullify selected heads of the self-attention modules. Mask values selected in[0, 1]:- 1 indicates the head is not masked,
- 0 indicates the head is masked.
- inputs_embeds (
torch.FloatTensorof shape({0}, hidden_size), optional) — Optionally, instead of passinginput_idsyou can choose to directly pass an embedded representation. This is useful if you want more control over how to convertinput_idsindices into associated vectors than the model’s internal embedding lookup matrix. - image_embeds (
torch.FloatTensorof shape(batch_size, num_patches, hidden_size), optional) — Optionally, instead of passingpixel_values, you can choose to directly pass an embedded representation. This is useful if you want more control over how to convertpixel_valuesinto patch embeddings. - image_token_type_idx (
int, optional) —- The token type ids for images.
- output_attentions (
bool, optional) — Whether or not to return the attentions tensors of all attention layers. Seeattentionsunder returned tensors for more detail. - output_hidden_states (
bool, optional) — Whether or not to return the hidden states of all layers. Seehidden_statesunder returned tensors for more detail. - return_dict (
bool, optional) — Whether or not to return a ModelOutput instead of a plain tuple. - return_loss (
bool, optional) — Whether or not to return the contrastive loss.
Returns
transformers.models.bridgetower.modeling_bridgetower.BridgeTowerContrastiveOutput or tuple(torch.FloatTensor)
A transformers.models.bridgetower.modeling_bridgetower.BridgeTowerContrastiveOutput or a tuple of
torch.FloatTensor (if return_dict=False is passed or when config.return_dict=False) comprising various
elements depending on the configuration (BridgeTowerConfig) and inputs.
- loss (
torch.FloatTensorof shape(1,), optional, returned whenreturn_lossisTrue— Image-text contrastive loss. - logits (
torch.FloatTensorof shape(batch_size, sequence_length, config.vocab_size)) — Prediction scores of the language modeling head (scores for each vocabulary token before SoftMax). - text_embeds (
torch.FloatTensor), optional, returned when model is initialized withwith_projection=True) — The text embeddings obtained by applying the projection layer to the pooler_output. - image_embeds (
torch.FloatTensor), optional, returned when model is initialized withwith_projection=True) — The image embeddings obtained by applying the projection layer to the pooler_output. - cross_embeds (
torch.FloatTensor), optional, returned when model is initialized withwith_projection=True) — The text-image cross-modal embeddings obtained by applying the projection layer to the pooler_output. - hidden_states (
tuple(torch.FloatTensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftorch.FloatTensor(one for the output of the embeddings, if the model has an embedding layer, + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size). Hidden-states of the model at the output of each layer plus the optional initial embedding outputs. - attentions (
tuple(torch.FloatTensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length).
The BridgeTowerForContrastiveLearning forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Module
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
Examples:
>>> from transformers import BridgeTowerProcessor, BridgeTowerForContrastiveLearning
>>> import requests
>>> from PIL import Image
>>> import torch
>>> image_urls = [
... "https://farm4.staticflickr.com/3395/3428278415_81c3e27f15_z.jpg",
... "http://images.cocodataset.org/val2017/000000039769.jpg",
... ]
>>> texts = ["two dogs in a car", "two cats sleeping on a couch"]
>>> images = [Image.open(requests.get(url, stream=True).raw) for url in image_urls]
>>> processor = BridgeTowerProcessor.from_pretrained("BridgeTower/bridgetower-large-itm-mlm-itc")
>>> model = BridgeTowerForContrastiveLearning.from_pretrained("BridgeTower/bridgetower-large-itm-mlm-itc")
>>> inputs = processor(images, texts, padding=True, return_tensors="pt")
>>> loss = model(**inputs, return_loss=True).loss
>>> inputs = processor(images, texts[::-1], padding=True, return_tensors="pt")
>>> loss_swapped = model(**inputs, return_loss=True).loss
>>> print("Loss", round(loss.item(), 4))
Loss 0.0019
>>> print("Loss with swapped images", round(loss_swapped.item(), 4))
Loss with swapped images 2.126BridgeTowerForMaskedLM
class transformers.BridgeTowerForMaskedLM
< source >( config )
Parameters
- config (BridgeTowerConfig) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the from_pretrained() method to load the model weights.
BridgeTower Model with a language modeling head on top as done during pretraining.
This model is a PyTorch torch.nn.Module <https://pytorch.org/docs/stable/nn.html#torch.nn.Module>_ subclass. Use
it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and
behavior.
forward
< source >( input_ids: typing.Optional[torch.LongTensor] = None attention_mask: typing.Optional[torch.FloatTensor] = None token_type_ids: typing.Optional[torch.LongTensor] = None pixel_values: typing.Optional[torch.FloatTensor] = None pixel_mask: typing.Optional[torch.LongTensor] = None head_mask: typing.Optional[torch.FloatTensor] = None inputs_embeds: typing.Optional[torch.FloatTensor] = None image_embeds: typing.Optional[torch.FloatTensor] = None output_attentions: typing.Optional[bool] = None output_hidden_states: typing.Optional[bool] = None return_dict: typing.Optional[bool] = None labels: typing.Optional[torch.LongTensor] = None ) → transformers.modeling_outputs.MaskedLMOutput or tuple(torch.FloatTensor)
Parameters
- input_ids (
torch.LongTensorof shape(batch_size, sequence_length)) — Indices of input sequence tokens in the vocabulary. Indices can be obtained using AutoTokenizer. See PreTrainedTokenizer.encode() and PreTrainedTokenizer.call() for details. What are input IDs? - attention_mask (
torch.FloatTensorof shape(batch_size, sequence_length), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked. What are attention masks?
- token_type_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Segment token indices to indicate first and second portions of the inputs. Indices are selected in[0, 1]:- 0 corresponds to a sentence A token,
- 1 corresponds to a sentence B token. What are token type IDs?
- pixel_values (
torch.FloatTensorof shape(batch_size, num_channels, height, width)) — Pixel values. Pixel values can be obtained using BridgeTowerImageProcessor. See BridgeTowerImageProcessor.call() for details. - pixel_mask (
torch.LongTensorof shape(batch_size, height, width), optional) — Mask to avoid performing attention on padding pixel values. Mask values selected in[0, 1]:- 1 for pixels that are real (i.e. not masked),
- 0 for pixels that are padding (i.e. masked).
What are attention masks? <../glossary.html#attention-mask>__
- head_mask (
torch.FloatTensorof shape(num_heads,)or(num_layers, num_heads), optional) — Mask to nullify selected heads of the self-attention modules. Mask values selected in[0, 1]:- 1 indicates the head is not masked,
- 0 indicates the head is masked.
- inputs_embeds (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size), optional) — Optionally, instead of passinginput_idsyou can choose to directly pass an embedded representation. This is useful if you want more control over how to convertinput_idsindices into associated vectors than the model’s internal embedding lookup matrix. - image_embeds (
torch.FloatTensorof shape(batch_size, num_patches, hidden_size), optional) — Optionally, instead of passingpixel_values, you can choose to directly pass an embedded representation. This is useful if you want more control over how to convertpixel_valuesinto patch embeddings. - image_token_type_idx (
int, optional) —- The token type ids for images.
- output_attentions (
bool, optional) — Whether or not to return the attentions tensors of all attention layers. Seeattentionsunder returned tensors for more detail. - output_hidden_states (
bool, optional) — Whether or not to return the hidden states of all layers. Seehidden_statesunder returned tensors for more detail. - return_dict (
bool, optional) — Whether or not to return a ModelOutput instead of a plain tuple. - labels (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Labels for computing the masked language modeling loss. Indices should be in[-100, 0, ..., config.vocab_size](seeinput_idsdocstring) Tokens with indices set to-100are ignored (masked), the loss is only computed for the tokens with labels in[0, ..., config.vocab_size]
Returns
transformers.modeling_outputs.MaskedLMOutput or tuple(torch.FloatTensor)
A transformers.modeling_outputs.MaskedLMOutput or a tuple of
torch.FloatTensor (if return_dict=False is passed or when config.return_dict=False) comprising various
elements depending on the configuration (BridgeTowerConfig) and inputs.
-
loss (
torch.FloatTensorof shape(1,), optional, returned whenlabelsis provided) — Masked language modeling (MLM) loss. -
logits (
torch.FloatTensorof shape(batch_size, sequence_length, config.vocab_size)) — Prediction scores of the language modeling head (scores for each vocabulary token before SoftMax). -
hidden_states (
tuple(torch.FloatTensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftorch.FloatTensor(one for the output of the embeddings, if the model has an embedding layer, + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size).Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
-
attentions (
tuple(torch.FloatTensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length).Attentions weights after the attention softmax, used to compute the weighted average in the self-attention heads.
The BridgeTowerForMaskedLM forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Module
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
Examples:
>>> from transformers import BridgeTowerProcessor, BridgeTowerForMaskedLM
>>> from PIL import Image
>>> import requests
>>> url = "http://images.cocodataset.org/val2017/000000360943.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw).convert("RGB")
>>> text = "a <mask> looking out of the window"
>>> processor = BridgeTowerProcessor.from_pretrained("BridgeTower/bridgetower-base-itm-mlm")
>>> model = BridgeTowerForMaskedLM.from_pretrained("BridgeTower/bridgetower-base-itm-mlm")
>>> # prepare inputs
>>> encoding = processor(image, text, return_tensors="pt")
>>> # forward pass
>>> outputs = model(**encoding)
>>> results = processor.decode(outputs.logits.argmax(dim=-1).squeeze(0).tolist())
>>> print(results)
.a cat looking out of the window.BridgeTowerForImageAndTextRetrieval
class transformers.BridgeTowerForImageAndTextRetrieval
< source >( config )
Parameters
- config (BridgeTowerConfig) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the from_pretrained() method to load the model weights.
BridgeTower Model transformer with a classifier head on top (a linear layer on top of the final hidden state of the [CLS] token) for image-to-text matching.
This model is a PyTorch torch.nn.Module <https://pytorch.org/docs/stable/nn.html#torch.nn.Module>_ subclass. Use
it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and
behavior.
forward
< source >( input_ids: typing.Optional[torch.LongTensor] = None attention_mask: typing.Optional[torch.FloatTensor] = None token_type_ids: typing.Optional[torch.LongTensor] = None pixel_values: typing.Optional[torch.FloatTensor] = None pixel_mask: typing.Optional[torch.LongTensor] = None head_mask: typing.Optional[torch.FloatTensor] = None inputs_embeds: typing.Optional[torch.FloatTensor] = None image_embeds: typing.Optional[torch.FloatTensor] = None output_attentions: typing.Optional[bool] = None output_hidden_states: typing.Optional[bool] = None return_dict: typing.Optional[bool] = None labels: typing.Optional[torch.LongTensor] = None ) → transformers.modeling_outputs.SequenceClassifierOutput or tuple(torch.FloatTensor)
Parameters
- input_ids (
torch.LongTensorof shape({0})) — Indices of input sequence tokens in the vocabulary. Indices can be obtained using AutoTokenizer. See PreTrainedTokenizer.encode() and PreTrainedTokenizer.call() for details. What are input IDs? - attention_mask (
torch.FloatTensorof shape({0}), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked. What are attention masks?
- token_type_ids (
torch.LongTensorof shape({0}), optional) — Segment token indices to indicate first and second portions of the inputs. Indices are selected in[0, 1]:- 0 corresponds to a sentence A token,
- 1 corresponds to a sentence B token. What are token type IDs?
- pixel_values (
torch.FloatTensorof shape(batch_size, num_channels, height, width)) — Pixel values. Pixel values can be obtained using BridgeTowerImageProcessor. See BridgeTowerImageProcessor.call() for details. - pixel_mask (
torch.LongTensorof shape(batch_size, height, width), optional) — Mask to avoid performing attention on padding pixel values. Mask values selected in[0, 1]:- 1 for pixels that are real (i.e. not masked),
- 0 for pixels that are padding (i.e. masked).
What are attention masks? <../glossary.html#attention-mask>__
- head_mask (
torch.FloatTensorof shape(num_heads,)or(num_layers, num_heads), optional) — Mask to nullify selected heads of the self-attention modules. Mask values selected in[0, 1]:- 1 indicates the head is not masked,
- 0 indicates the head is masked.
- inputs_embeds (
torch.FloatTensorof shape({0}, hidden_size), optional) — Optionally, instead of passinginput_idsyou can choose to directly pass an embedded representation. This is useful if you want more control over how to convertinput_idsindices into associated vectors than the model’s internal embedding lookup matrix. - image_embeds (
torch.FloatTensorof shape(batch_size, num_patches, hidden_size), optional) — Optionally, instead of passingpixel_values, you can choose to directly pass an embedded representation. This is useful if you want more control over how to convertpixel_valuesinto patch embeddings. - image_token_type_idx (
int, optional) —- The token type ids for images.
- output_attentions (
bool, optional) — Whether or not to return the attentions tensors of all attention layers. Seeattentionsunder returned tensors for more detail. - output_hidden_states (
bool, optional) — Whether or not to return the hidden states of all layers. Seehidden_statesunder returned tensors for more detail. - return_dict (
bool, optional) — Whether or not to return a ModelOutput instead of a plain tuple. - labels (
torch.LongTensorof shape(batch_size, 1), optional) — Labels for computing the image-text matching loss. 0 means the pairs don’t match and 1 means they match. The pairs with 0 will be skipped for calculation.
Returns
transformers.modeling_outputs.SequenceClassifierOutput or tuple(torch.FloatTensor)
A transformers.modeling_outputs.SequenceClassifierOutput or a tuple of
torch.FloatTensor (if return_dict=False is passed or when config.return_dict=False) comprising various
elements depending on the configuration (BridgeTowerConfig) and inputs.
-
loss (
torch.FloatTensorof shape(1,), optional, returned whenlabelsis provided) — Classification (or regression if config.num_labels==1) loss. -
logits (
torch.FloatTensorof shape(batch_size, config.num_labels)) — Classification (or regression if config.num_labels==1) scores (before SoftMax). -
hidden_states (
tuple(torch.FloatTensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftorch.FloatTensor(one for the output of the embeddings, if the model has an embedding layer, + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size).Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
-
attentions (
tuple(torch.FloatTensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length).Attentions weights after the attention softmax, used to compute the weighted average in the self-attention heads.
The BridgeTowerForImageAndTextRetrieval forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Module
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
Examples:
>>> from transformers import BridgeTowerProcessor, BridgeTowerForImageAndTextRetrieval
>>> import requests
>>> from PIL import Image
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> texts = ["An image of two cats chilling on a couch", "A football player scoring a goal"]
>>> processor = BridgeTowerProcessor.from_pretrained("BridgeTower/bridgetower-base-itm-mlm")
>>> model = BridgeTowerForImageAndTextRetrieval.from_pretrained("BridgeTower/bridgetower-base-itm-mlm")
>>> # forward pass
>>> scores = dict()
>>> for text in texts:
... # prepare inputs
... encoding = processor(image, text, return_tensors="pt")
... outputs = model(**encoding)
... scores[text] = outputs.logits[0, 1].item()