Transformers documentation
YOSO
YOSO
Overview
The YOSO model was proposed in You Only Sample (Almost) Once: Linear Cost Self-Attention Via Bernoulli Sampling
by Zhanpeng Zeng, Yunyang Xiong, Sathya N. Ravi, Shailesh Acharya, Glenn Fung, Vikas Singh. YOSO approximates standard softmax self-attention
via a Bernoulli sampling scheme based on Locality Sensitive Hashing (LSH). In principle, all the Bernoulli random variables can be sampled with
a single hash.
The abstract from the paper is the following:
Transformer-based models are widely used in natural language processing (NLP). Central to the transformer model is the self-attention mechanism, which captures the interactions of token pairs in the input sequences and depends quadratically on the sequence length. Training such models on longer sequences is expensive. In this paper, we show that a Bernoulli sampling attention mechanism based on Locality Sensitive Hashing (LSH), decreases the quadratic complexity of such models to linear. We bypass the quadratic cost by considering self-attention as a sum of individual tokens associated with Bernoulli random variables that can, in principle, be sampled at once by a single hash (although in practice, this number may be a small constant). This leads to an efficient sampling scheme to estimate self-attention which relies on specific modifications of LSH (to enable deployment on GPU architectures). We evaluate our algorithm on the GLUE benchmark with standard 512 sequence length where we see favorable performance relative to a standard pretrained Transformer. On the Long Range Arena (LRA) benchmark, for evaluating performance on long sequences, our method achieves results consistent with softmax self-attention but with sizable speed-ups and memory savings and often outperforms other efficient self-attention methods. Our code is available at this https URL
Tips:
- The YOSO attention algorithm is implemented through custom CUDA kernels, functions written in CUDA C++ that can be executed multiple times in parallel on a GPU.
- The kernels provide a
fast_hashfunction, which approximates the random projections of the queries and keys using the Fast Hadamard Transform. Using these hash codes, thelsh_cumulationfunction approximates self-attention via LSH-based Bernoulli sampling. - To use the custom kernels, the user should set
config.use_expectation = False. To ensure that the kernels are compiled successfully, the user must install the correct version of PyTorch and cudatoolkit. By default,config.use_expectation = True, which uses YOSO-E and does not require compiling CUDA kernels.
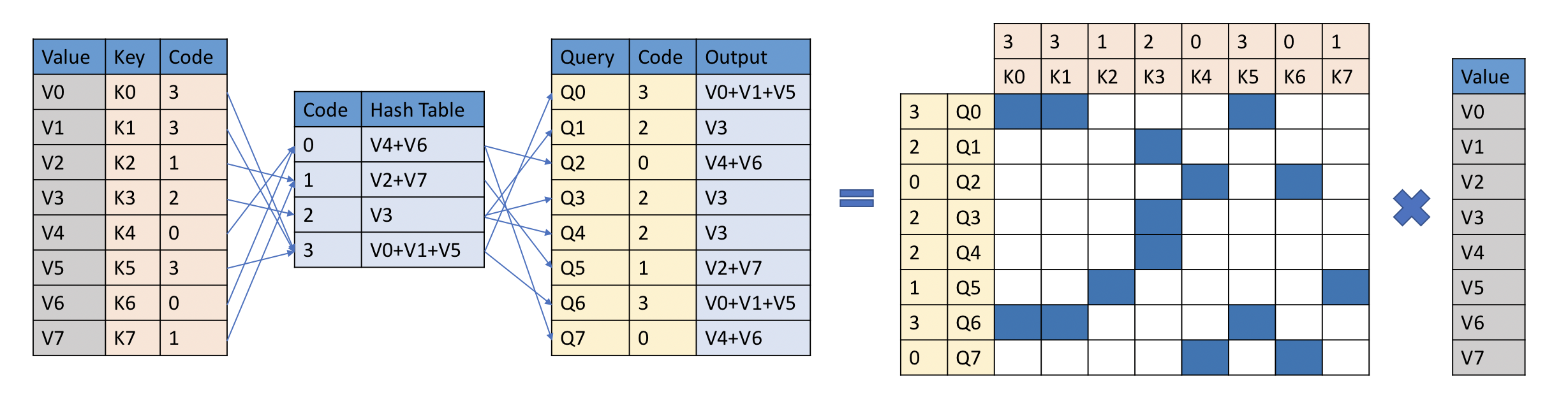 YOSO Attention Algorithm. Taken from the original paper.
YOSO Attention Algorithm. Taken from the original paper.
This model was contributed by novice03. The original code can be found here.
YosoConfig
class transformers.YosoConfig
< source >( vocab_size = 50265 hidden_size = 768 num_hidden_layers = 12 num_attention_heads = 12 intermediate_size = 3072 hidden_act = 'gelu' hidden_dropout_prob = 0.1 attention_probs_dropout_prob = 0.1 max_position_embeddings = 4096 type_vocab_size = 1 initializer_range = 0.02 layer_norm_eps = 1e-12 position_embedding_type = 'absolute' use_expectation = True hash_code_len = 9 num_hash = 64 conv_window = None use_fast_hash = True lsh_backward = True pad_token_id = 1 bos_token_id = 0 eos_token_id = 2 **kwargs )
Parameters
-
vocab_size (
int, optional, defaults to 50265) — Vocabulary size of the YOSO model. Defines the number of different tokens that can be represented by theinputs_idspassed when calling YosoModel. -
hidden_size (
int, optional, defaults to 768) — Dimension of the encoder layers and the pooler layer. -
num_hidden_layers (
int, optional, defaults to 12) — Number of hidden layers in the Transformer encoder. -
num_attention_heads (
int, optional, defaults to 12) — Number of attention heads for each attention layer in the Transformer encoder. -
intermediate_size (
int, optional, defaults to 3072) — Dimension of the “intermediate” (i.e., feed-forward) layer in the Transformer encoder. -
hidden_act (
strorfunction, optional, defaults to"gelu") — The non-linear activation function (function or string) in the encoder and pooler. If string,"gelu","relu","selu"and"gelu_new"are supported. -
hidden_dropout_prob (
float, optional, defaults to 0.1) — The dropout probabilitiy for all fully connected layers in the embeddings, encoder, and pooler. -
attention_probs_dropout_prob (
float, optional, defaults to 0.1) — The dropout ratio for the attention probabilities. -
max_position_embeddings (
int, optional, defaults to 512) — The maximum sequence length that this model might ever be used with. Typically set this to something large just in case (e.g., 512 or 1024 or 2048). -
type_vocab_size (
int, optional, defaults to 2) — The vocabulary size of thetoken_type_idspassed when calling YosoModel. -
initializer_range (
float, optional, defaults to 0.02) — The standard deviation of the truncated_normal_initializer for initializing all weight matrices. -
layer_norm_eps (
float, optional, defaults to 1e-12) — The epsilon used by the layer normalization layers. -
position_embedding_type (
str, optional, defaults to"absolute") — Type of position embedding. Choose one of"absolute","relative_key","relative_key_query". -
use_expectation (
bool, optional, defaults toTrue) — Whether or not to use YOSO Expectation. Overrides any effect of num_hash. -
hash_code_len (
int, optional, defaults to 9) — The length of hashes generated by the hash functions. -
num_hash (
int, optional, defaults to 64) — Number of hash functions used inYosoSelfAttention. -
conv_window (
int, optional) — Kernel size of depth-wise convolution. -
use_fast_hash (
bool, optional, defaults toFalse) — Whether or not to use custom cuda kernels which perform fast random projection via hadamard transform. -
lsh_backward (
bool, optional, defaults toTrue) — Whether or not to perform backpropagation using Locality Sensitive Hashing.
This is the configuration class to store the configuration of a YosoModel. It is used to instantiate an YOSO model according to the specified arguments, defining the model architecture. Instantiating a configuration with the defaults will yield a similar configuration to that of the YOSO uw-madison/yoso-4096 architecture.
Configuration objects inherit from PretrainedConfig and can be used to control the model outputs. Read the documentation from PretrainedConfig for more information.
Example:
>>> from transformers import YosoConfig, YosoModel
>>> # Initializing a YOSO uw-madison/yoso-4096 style configuration
>>> configuration = YosoConfig()
>>> # Initializing a model (with random weights) from the uw-madison/yoso-4096 style configuration
>>> model = YosoModel(configuration)
>>> # Accessing the model configuration
>>> configuration = model.configYosoModel
class transformers.YosoModel
< source >( config )
Parameters
- config (YosoConfig) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the from_pretrained() method to load the model weights.
The bare YOSO Model transformer outputting raw hidden-states without any specific head on top. This model is a PyTorch torch.nn.Module sub-class. Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and behavior.
forward
< source >(
input_ids: typing.Optional[torch.Tensor] = None
attention_mask: typing.Optional[torch.Tensor] = None
token_type_ids: typing.Optional[torch.Tensor] = None
position_ids: typing.Optional[torch.Tensor] = None
head_mask: typing.Optional[torch.Tensor] = None
inputs_embeds: typing.Optional[torch.Tensor] = None
output_attentions: typing.Optional[bool] = None
output_hidden_states: typing.Optional[bool] = None
return_dict: typing.Optional[bool] = None
)
→
transformers.modeling_outputs.BaseModelOutputWithCrossAttentions or tuple(torch.FloatTensor)
Parameters
-
input_ids (
torch.LongTensorof shape(batch_size, sequence_length)) — Indices of input sequence tokens in the vocabulary.Indices can be obtained using AutoTokenizer. See PreTrainedTokenizer.encode() and PreTrainedTokenizer.call() for details.
-
attention_mask (
torch.FloatTensorof shape(batch_size, sequence_length), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
-
token_type_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Segment token indices to indicate first and second portions of the inputs. Indices are selected in[0, 1]:- 0 corresponds to a sentence A token,
- 1 corresponds to a sentence B token.
-
position_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Indices of positions of each input sequence tokens in the position embeddings. Selected in the range[0, config.max_position_embeddings - 1]. -
head_mask (
torch.FloatTensorof shape(num_heads,)or(num_layers, num_heads), optional) — Mask to nullify selected heads of the self-attention modules. Mask values selected in[0, 1]:- 1 indicates the head is not masked,
- 0 indicates the head is masked.
-
inputs_embeds (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size), optional) — Optionally, instead of passinginput_idsyou can choose to directly pass an embedded representation. This is useful if you want more control over how to convert input_ids indices into associated vectors than the model’s internal embedding lookup matrix. -
output_attentions (
bool, optional) — Whether or not to return the attentions tensors of all attention layers. Seeattentionsunder returned tensors for more detail. -
output_hidden_states (
bool, optional) — Whether or not to return the hidden states of all layers. Seehidden_statesunder returned tensors for more detail. -
return_dict (
bool, optional) — Whether or not to return a ModelOutput instead of a plain tuple.
Returns
transformers.modeling_outputs.BaseModelOutputWithCrossAttentions or tuple(torch.FloatTensor)
A transformers.modeling_outputs.BaseModelOutputWithCrossAttentions or a tuple of
torch.FloatTensor (if return_dict=False is passed or when config.return_dict=False) comprising various
elements depending on the configuration (YosoConfig) and inputs.
-
last_hidden_state (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size)) — Sequence of hidden-states at the output of the last layer of the model. -
hidden_states (
tuple(torch.FloatTensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftorch.FloatTensor(one for the output of the embeddings, if the model has an embedding layer, + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size).Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
-
attentions (
tuple(torch.FloatTensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length).Attentions weights after the attention softmax, used to compute the weighted average in the self-attention heads.
-
cross_attentions (
tuple(torch.FloatTensor), optional, returned whenoutput_attentions=Trueandconfig.add_cross_attention=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length).Attentions weights of the decoder’s cross-attention layer, after the attention softmax, used to compute the weighted average in the cross-attention heads.
The YosoModel forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Module
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
Example:
>>> from transformers import AutoTokenizer, YosoModel
>>> import torch
>>> tokenizer = AutoTokenizer.from_pretrained("uw-madison/yoso-4096")
>>> model = YosoModel.from_pretrained("uw-madison/yoso-4096")
>>> inputs = tokenizer("Hello, my dog is cute", return_tensors="pt")
>>> outputs = model(**inputs)
>>> last_hidden_states = outputs.last_hidden_stateYosoForMaskedLM
class transformers.YosoForMaskedLM
< source >( config )
Parameters
- config (YosoConfig) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the from_pretrained() method to load the model weights.
YOSO Model with a language modeling head on top.
This model is a PyTorch torch.nn.Module sub-class. Use
it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and
behavior.
forward
< source >(
input_ids: typing.Optional[torch.Tensor] = None
attention_mask: typing.Optional[torch.Tensor] = None
token_type_ids: typing.Optional[torch.Tensor] = None
position_ids: typing.Optional[torch.Tensor] = None
head_mask: typing.Optional[torch.Tensor] = None
inputs_embeds: typing.Optional[torch.Tensor] = None
labels: typing.Optional[torch.Tensor] = None
output_attentions: typing.Optional[bool] = None
output_hidden_states: typing.Optional[bool] = None
return_dict: typing.Optional[bool] = None
)
→
transformers.modeling_outputs.MaskedLMOutput or tuple(torch.FloatTensor)
Parameters
-
input_ids (
torch.LongTensorof shape(batch_size, sequence_length)) — Indices of input sequence tokens in the vocabulary.Indices can be obtained using AutoTokenizer. See PreTrainedTokenizer.encode() and PreTrainedTokenizer.call() for details.
-
attention_mask (
torch.FloatTensorof shape(batch_size, sequence_length), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
-
token_type_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Segment token indices to indicate first and second portions of the inputs. Indices are selected in[0, 1]:- 0 corresponds to a sentence A token,
- 1 corresponds to a sentence B token.
-
position_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Indices of positions of each input sequence tokens in the position embeddings. Selected in the range[0, config.max_position_embeddings - 1]. -
head_mask (
torch.FloatTensorof shape(num_heads,)or(num_layers, num_heads), optional) — Mask to nullify selected heads of the self-attention modules. Mask values selected in[0, 1]:- 1 indicates the head is not masked,
- 0 indicates the head is masked.
-
inputs_embeds (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size), optional) — Optionally, instead of passinginput_idsyou can choose to directly pass an embedded representation. This is useful if you want more control over how to convert input_ids indices into associated vectors than the model’s internal embedding lookup matrix. -
output_attentions (
bool, optional) — Whether or not to return the attentions tensors of all attention layers. Seeattentionsunder returned tensors for more detail. -
output_hidden_states (
bool, optional) — Whether or not to return the hidden states of all layers. Seehidden_statesunder returned tensors for more detail. -
return_dict (
bool, optional) — Whether or not to return a ModelOutput instead of a plain tuple. -
labels (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Labels for computing the masked language modeling loss. Indices should be in[-100, 0, ..., config.vocab_size](seeinput_idsdocstring) Tokens with indices set to-100are ignored (masked), the loss is only computed for the tokens with labels in[0, ..., config.vocab_size].
Returns
transformers.modeling_outputs.MaskedLMOutput or tuple(torch.FloatTensor)
A transformers.modeling_outputs.MaskedLMOutput or a tuple of
torch.FloatTensor (if return_dict=False is passed or when config.return_dict=False) comprising various
elements depending on the configuration (YosoConfig) and inputs.
-
loss (
torch.FloatTensorof shape(1,), optional, returned whenlabelsis provided) — Masked language modeling (MLM) loss. -
logits (
torch.FloatTensorof shape(batch_size, sequence_length, config.vocab_size)) — Prediction scores of the language modeling head (scores for each vocabulary token before SoftMax). -
hidden_states (
tuple(torch.FloatTensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftorch.FloatTensor(one for the output of the embeddings, if the model has an embedding layer, + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size).Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
-
attentions (
tuple(torch.FloatTensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length).Attentions weights after the attention softmax, used to compute the weighted average in the self-attention heads.
The YosoForMaskedLM forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Module
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
Example:
>>> from transformers import AutoTokenizer, YosoForMaskedLM
>>> import torch
>>> tokenizer = AutoTokenizer.from_pretrained("uw-madison/yoso-4096")
>>> model = YosoForMaskedLM.from_pretrained("uw-madison/yoso-4096")
>>> inputs = tokenizer("The capital of France is [MASK].", return_tensors="pt")
>>> with torch.no_grad():
... logits = model(**inputs).logits
>>> # retrieve index of [MASK]
>>> mask_token_index = (inputs.input_ids == tokenizer.mask_token_id)[0].nonzero(as_tuple=True)[0]
>>> predicted_token_id = logits[0, mask_token_index].argmax(axis=-1)
>>> labels = tokenizer("The capital of France is Paris.", return_tensors="pt")["input_ids"]
>>> # mask labels of non-[MASK] tokens
>>> labels = torch.where(inputs.input_ids == tokenizer.mask_token_id, labels, -100)
>>> outputs = model(**inputs, labels=labels)YosoForSequenceClassification
class transformers.YosoForSequenceClassification
< source >( config )
Parameters
- config (YosoConfig) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the from_pretrained() method to load the model weights.
YOSO Model transformer with a sequence classification/regression head on top (a linear layer on top of the pooled output) e.g. for GLUE tasks. This model is a PyTorch torch.nn.Module sub-class. Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and behavior.
forward
< source >(
input_ids: typing.Optional[torch.Tensor] = None
attention_mask: typing.Optional[torch.Tensor] = None
token_type_ids: typing.Optional[torch.Tensor] = None
position_ids: typing.Optional[torch.Tensor] = None
head_mask: typing.Optional[torch.Tensor] = None
inputs_embeds: typing.Optional[torch.Tensor] = None
labels: typing.Optional[torch.Tensor] = None
output_attentions: typing.Optional[bool] = None
output_hidden_states: typing.Optional[bool] = None
return_dict: typing.Optional[bool] = None
)
→
transformers.modeling_outputs.SequenceClassifierOutput or tuple(torch.FloatTensor)
Parameters
-
input_ids (
torch.LongTensorof shape(batch_size, sequence_length)) — Indices of input sequence tokens in the vocabulary.Indices can be obtained using AutoTokenizer. See PreTrainedTokenizer.encode() and PreTrainedTokenizer.call() for details.
-
attention_mask (
torch.FloatTensorof shape(batch_size, sequence_length), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
-
token_type_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Segment token indices to indicate first and second portions of the inputs. Indices are selected in[0, 1]:- 0 corresponds to a sentence A token,
- 1 corresponds to a sentence B token.
-
position_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Indices of positions of each input sequence tokens in the position embeddings. Selected in the range[0, config.max_position_embeddings - 1]. -
head_mask (
torch.FloatTensorof shape(num_heads,)or(num_layers, num_heads), optional) — Mask to nullify selected heads of the self-attention modules. Mask values selected in[0, 1]:- 1 indicates the head is not masked,
- 0 indicates the head is masked.
-
inputs_embeds (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size), optional) — Optionally, instead of passinginput_idsyou can choose to directly pass an embedded representation. This is useful if you want more control over how to convert input_ids indices into associated vectors than the model’s internal embedding lookup matrix. -
output_attentions (
bool, optional) — Whether or not to return the attentions tensors of all attention layers. Seeattentionsunder returned tensors for more detail. -
output_hidden_states (
bool, optional) — Whether or not to return the hidden states of all layers. Seehidden_statesunder returned tensors for more detail. -
return_dict (
bool, optional) — Whether or not to return a ModelOutput instead of a plain tuple. -
labels (
torch.LongTensorof shape(batch_size,), optional) — Labels for computing the sequence classification/regression loss. Indices should be in[0, ..., config.num_labels - 1]. Ifconfig.num_labels == 1a regression loss is computed (Mean-Square loss), Ifconfig.num_labels > 1a classification loss is computed (Cross-Entropy).
Returns
transformers.modeling_outputs.SequenceClassifierOutput or tuple(torch.FloatTensor)
A transformers.modeling_outputs.SequenceClassifierOutput or a tuple of
torch.FloatTensor (if return_dict=False is passed or when config.return_dict=False) comprising various
elements depending on the configuration (YosoConfig) and inputs.
-
loss (
torch.FloatTensorof shape(1,), optional, returned whenlabelsis provided) — Classification (or regression if config.num_labels==1) loss. -
logits (
torch.FloatTensorof shape(batch_size, config.num_labels)) — Classification (or regression if config.num_labels==1) scores (before SoftMax). -
hidden_states (
tuple(torch.FloatTensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftorch.FloatTensor(one for the output of the embeddings, if the model has an embedding layer, + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size).Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
-
attentions (
tuple(torch.FloatTensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length).Attentions weights after the attention softmax, used to compute the weighted average in the self-attention heads.
The YosoForSequenceClassification forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Module
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
Example of single-label classification:
>>> import torch
>>> from transformers import AutoTokenizer, YosoForSequenceClassification
>>> tokenizer = AutoTokenizer.from_pretrained("uw-madison/yoso-4096")
>>> model = YosoForSequenceClassification.from_pretrained("uw-madison/yoso-4096")
>>> inputs = tokenizer("Hello, my dog is cute", return_tensors="pt")
>>> with torch.no_grad():
... logits = model(**inputs).logits
>>> predicted_class_id = logits.argmax().item()
>>> # To train a model on `num_labels` classes, you can pass `num_labels=num_labels` to `.from_pretrained(...)`
>>> num_labels = len(model.config.id2label)
>>> model = YosoForSequenceClassification.from_pretrained("uw-madison/yoso-4096", num_labels=num_labels)
>>> labels = torch.tensor([1])
>>> loss = model(**inputs, labels=labels).lossExample of multi-label classification:
>>> import torch
>>> from transformers import AutoTokenizer, YosoForSequenceClassification
>>> tokenizer = AutoTokenizer.from_pretrained("uw-madison/yoso-4096")
>>> model = YosoForSequenceClassification.from_pretrained("uw-madison/yoso-4096", problem_type="multi_label_classification")
>>> inputs = tokenizer("Hello, my dog is cute", return_tensors="pt")
>>> with torch.no_grad():
... logits = model(**inputs).logits
>>> predicted_class_ids = torch.arange(0, logits.shape[-1])[torch.sigmoid(logits).squeeze(dim=0) > 0.5]
>>> # To train a model on `num_labels` classes, you can pass `num_labels=num_labels` to `.from_pretrained(...)`
>>> num_labels = len(model.config.id2label)
>>> model = YosoForSequenceClassification.from_pretrained(
... "uw-madison/yoso-4096", num_labels=num_labels, problem_type="multi_label_classification"
... )
>>> labels = torch.sum(
... torch.nn.functional.one_hot(predicted_class_ids[None, :].clone(), num_classes=num_labels), dim=1
... ).to(torch.float)
>>> loss = model(**inputs, labels=labels).lossYosoForMultipleChoice
class transformers.YosoForMultipleChoice
< source >( config )
Parameters
- config (YosoConfig) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the from_pretrained() method to load the model weights.
YOSO Model with a multiple choice classification head on top (a linear layer on top of the pooled output and a softmax) e.g. for RocStories/SWAG tasks. This model is a PyTorch torch.nn.Module sub-class. Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and behavior.
forward
< source >(
input_ids: typing.Optional[torch.Tensor] = None
attention_mask: typing.Optional[torch.Tensor] = None
token_type_ids: typing.Optional[torch.Tensor] = None
position_ids: typing.Optional[torch.Tensor] = None
head_mask: typing.Optional[torch.Tensor] = None
inputs_embeds: typing.Optional[torch.Tensor] = None
labels: typing.Optional[torch.Tensor] = None
output_attentions: typing.Optional[bool] = None
output_hidden_states: typing.Optional[bool] = None
return_dict: typing.Optional[bool] = None
)
→
transformers.modeling_outputs.MultipleChoiceModelOutput or tuple(torch.FloatTensor)
Parameters
-
input_ids (
torch.LongTensorof shape(batch_size, num_choices, sequence_length)) — Indices of input sequence tokens in the vocabulary.Indices can be obtained using AutoTokenizer. See PreTrainedTokenizer.encode() and PreTrainedTokenizer.call() for details.
-
attention_mask (
torch.FloatTensorof shape(batch_size, num_choices, sequence_length), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
-
token_type_ids (
torch.LongTensorof shape(batch_size, num_choices, sequence_length), optional) — Segment token indices to indicate first and second portions of the inputs. Indices are selected in[0, 1]:- 0 corresponds to a sentence A token,
- 1 corresponds to a sentence B token.
-
position_ids (
torch.LongTensorof shape(batch_size, num_choices, sequence_length), optional) — Indices of positions of each input sequence tokens in the position embeddings. Selected in the range[0, config.max_position_embeddings - 1]. -
head_mask (
torch.FloatTensorof shape(num_heads,)or(num_layers, num_heads), optional) — Mask to nullify selected heads of the self-attention modules. Mask values selected in[0, 1]:- 1 indicates the head is not masked,
- 0 indicates the head is masked.
-
inputs_embeds (
torch.FloatTensorof shape(batch_size, num_choices, sequence_length, hidden_size), optional) — Optionally, instead of passinginput_idsyou can choose to directly pass an embedded representation. This is useful if you want more control over how to convert input_ids indices into associated vectors than the model’s internal embedding lookup matrix. -
output_attentions (
bool, optional) — Whether or not to return the attentions tensors of all attention layers. Seeattentionsunder returned tensors for more detail. -
output_hidden_states (
bool, optional) — Whether or not to return the hidden states of all layers. Seehidden_statesunder returned tensors for more detail. -
return_dict (
bool, optional) — Whether or not to return a ModelOutput instead of a plain tuple. -
labels (
torch.LongTensorof shape(batch_size,), optional) — Labels for computing the multiple choice classification loss. Indices should be in[0, ..., num_choices-1]wherenum_choicesis the size of the second dimension of the input tensors. (Seeinput_idsabove)
Returns
transformers.modeling_outputs.MultipleChoiceModelOutput or tuple(torch.FloatTensor)
A transformers.modeling_outputs.MultipleChoiceModelOutput or a tuple of
torch.FloatTensor (if return_dict=False is passed or when config.return_dict=False) comprising various
elements depending on the configuration (YosoConfig) and inputs.
-
loss (
torch.FloatTensorof shape (1,), optional, returned whenlabelsis provided) — Classification loss. -
logits (
torch.FloatTensorof shape(batch_size, num_choices)) — num_choices is the second dimension of the input tensors. (see input_ids above).Classification scores (before SoftMax).
-
hidden_states (
tuple(torch.FloatTensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftorch.FloatTensor(one for the output of the embeddings, if the model has an embedding layer, + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size).Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
-
attentions (
tuple(torch.FloatTensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length).Attentions weights after the attention softmax, used to compute the weighted average in the self-attention heads.
The YosoForMultipleChoice forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Module
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
Example:
>>> from transformers import AutoTokenizer, YosoForMultipleChoice
>>> import torch
>>> tokenizer = AutoTokenizer.from_pretrained("uw-madison/yoso-4096")
>>> model = YosoForMultipleChoice.from_pretrained("uw-madison/yoso-4096")
>>> prompt = "In Italy, pizza served in formal settings, such as at a restaurant, is presented unsliced."
>>> choice0 = "It is eaten with a fork and a knife."
>>> choice1 = "It is eaten while held in the hand."
>>> labels = torch.tensor(0).unsqueeze(0) # choice0 is correct (according to Wikipedia ;)), batch size 1
>>> encoding = tokenizer([prompt, prompt], [choice0, choice1], return_tensors="pt", padding=True)
>>> outputs = model(**{k: v.unsqueeze(0) for k, v in encoding.items()}, labels=labels) # batch size is 1
>>> # the linear classifier still needs to be trained
>>> loss = outputs.loss
>>> logits = outputs.logitsYosoForTokenClassification
class transformers.YosoForTokenClassification
< source >( config )
Parameters
- config (YosoConfig) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the from_pretrained() method to load the model weights.
YOSO Model with a token classification head on top (a linear layer on top of the hidden-states output) e.g. for Named-Entity-Recognition (NER) tasks. This model is a PyTorch torch.nn.Module sub-class. Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and behavior.
forward
< source >(
input_ids: typing.Optional[torch.Tensor] = None
attention_mask: typing.Optional[torch.Tensor] = None
token_type_ids: typing.Optional[torch.Tensor] = None
position_ids: typing.Optional[torch.Tensor] = None
head_mask: typing.Optional[torch.Tensor] = None
inputs_embeds: typing.Optional[torch.Tensor] = None
labels: typing.Optional[torch.Tensor] = None
output_attentions: typing.Optional[bool] = None
output_hidden_states: typing.Optional[bool] = None
return_dict: typing.Optional[bool] = None
)
→
transformers.modeling_outputs.TokenClassifierOutput or tuple(torch.FloatTensor)
Parameters
-
input_ids (
torch.LongTensorof shape(batch_size, sequence_length)) — Indices of input sequence tokens in the vocabulary.Indices can be obtained using AutoTokenizer. See PreTrainedTokenizer.encode() and PreTrainedTokenizer.call() for details.
-
attention_mask (
torch.FloatTensorof shape(batch_size, sequence_length), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
-
token_type_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Segment token indices to indicate first and second portions of the inputs. Indices are selected in[0, 1]:- 0 corresponds to a sentence A token,
- 1 corresponds to a sentence B token.
-
position_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Indices of positions of each input sequence tokens in the position embeddings. Selected in the range[0, config.max_position_embeddings - 1]. -
head_mask (
torch.FloatTensorof shape(num_heads,)or(num_layers, num_heads), optional) — Mask to nullify selected heads of the self-attention modules. Mask values selected in[0, 1]:- 1 indicates the head is not masked,
- 0 indicates the head is masked.
-
inputs_embeds (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size), optional) — Optionally, instead of passinginput_idsyou can choose to directly pass an embedded representation. This is useful if you want more control over how to convert input_ids indices into associated vectors than the model’s internal embedding lookup matrix. -
output_attentions (
bool, optional) — Whether or not to return the attentions tensors of all attention layers. Seeattentionsunder returned tensors for more detail. -
output_hidden_states (
bool, optional) — Whether or not to return the hidden states of all layers. Seehidden_statesunder returned tensors for more detail. -
return_dict (
bool, optional) — Whether or not to return a ModelOutput instead of a plain tuple. -
labels (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Labels for computing the token classification loss. Indices should be in[0, ..., config.num_labels - 1].
Returns
transformers.modeling_outputs.TokenClassifierOutput or tuple(torch.FloatTensor)
A transformers.modeling_outputs.TokenClassifierOutput or a tuple of
torch.FloatTensor (if return_dict=False is passed or when config.return_dict=False) comprising various
elements depending on the configuration (YosoConfig) and inputs.
-
loss (
torch.FloatTensorof shape(1,), optional, returned whenlabelsis provided) — Classification loss. -
logits (
torch.FloatTensorof shape(batch_size, sequence_length, config.num_labels)) — Classification scores (before SoftMax). -
hidden_states (
tuple(torch.FloatTensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftorch.FloatTensor(one for the output of the embeddings, if the model has an embedding layer, + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size).Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
-
attentions (
tuple(torch.FloatTensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length).Attentions weights after the attention softmax, used to compute the weighted average in the self-attention heads.
The YosoForTokenClassification forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Module
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
Example:
>>> from transformers import AutoTokenizer, YosoForTokenClassification
>>> import torch
>>> tokenizer = AutoTokenizer.from_pretrained("uw-madison/yoso-4096")
>>> model = YosoForTokenClassification.from_pretrained("uw-madison/yoso-4096")
>>> inputs = tokenizer(
... "HuggingFace is a company based in Paris and New York", add_special_tokens=False, return_tensors="pt"
... )
>>> with torch.no_grad():
... logits = model(**inputs).logits
>>> predicted_token_class_ids = logits.argmax(-1)
>>> # Note that tokens are classified rather then input words which means that
>>> # there might be more predicted token classes than words.
>>> # Multiple token classes might account for the same word
>>> predicted_tokens_classes = [model.config.id2label[t.item()] for t in predicted_token_class_ids[0]]
>>> labels = predicted_token_class_ids
>>> loss = model(**inputs, labels=labels).lossYosoForQuestionAnswering
class transformers.YosoForQuestionAnswering
< source >( config )
Parameters
- config (YosoConfig) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the from_pretrained() method to load the model weights.
YOSO Model with a span classification head on top for extractive question-answering tasks like SQuAD (a linear
layers on top of the hidden-states output to compute span start logits and span end logits).
This model is a PyTorch torch.nn.Module sub-class. Use
it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and
behavior.
forward
< source >(
input_ids: typing.Optional[torch.Tensor] = None
attention_mask: typing.Optional[torch.Tensor] = None
token_type_ids: typing.Optional[torch.Tensor] = None
position_ids: typing.Optional[torch.Tensor] = None
head_mask: typing.Optional[torch.Tensor] = None
inputs_embeds: typing.Optional[torch.Tensor] = None
start_positions: typing.Optional[torch.Tensor] = None
end_positions: typing.Optional[torch.Tensor] = None
output_attentions: typing.Optional[bool] = None
output_hidden_states: typing.Optional[bool] = None
return_dict: typing.Optional[bool] = None
)
→
transformers.modeling_outputs.QuestionAnsweringModelOutput or tuple(torch.FloatTensor)
Parameters
-
input_ids (
torch.LongTensorof shape(batch_size, sequence_length)) — Indices of input sequence tokens in the vocabulary.Indices can be obtained using AutoTokenizer. See PreTrainedTokenizer.encode() and PreTrainedTokenizer.call() for details.
-
attention_mask (
torch.FloatTensorof shape(batch_size, sequence_length), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
-
token_type_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Segment token indices to indicate first and second portions of the inputs. Indices are selected in[0, 1]:- 0 corresponds to a sentence A token,
- 1 corresponds to a sentence B token.
-
position_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Indices of positions of each input sequence tokens in the position embeddings. Selected in the range[0, config.max_position_embeddings - 1]. -
head_mask (
torch.FloatTensorof shape(num_heads,)or(num_layers, num_heads), optional) — Mask to nullify selected heads of the self-attention modules. Mask values selected in[0, 1]:- 1 indicates the head is not masked,
- 0 indicates the head is masked.
-
inputs_embeds (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size), optional) — Optionally, instead of passinginput_idsyou can choose to directly pass an embedded representation. This is useful if you want more control over how to convert input_ids indices into associated vectors than the model’s internal embedding lookup matrix. -
output_attentions (
bool, optional) — Whether or not to return the attentions tensors of all attention layers. Seeattentionsunder returned tensors for more detail. -
output_hidden_states (
bool, optional) — Whether or not to return the hidden states of all layers. Seehidden_statesunder returned tensors for more detail. -
return_dict (
bool, optional) — Whether or not to return a ModelOutput instead of a plain tuple. -
start_positions (
torch.LongTensorof shape(batch_size,), optional) — Labels for position (index) of the start of the labelled span for computing the token classification loss. Positions are clamped to the length of the sequence (sequence_length). Position outside of the sequence are not taken into account for computing the loss. -
end_positions (
torch.LongTensorof shape(batch_size,), optional) — Labels for position (index) of the end of the labelled span for computing the token classification loss. Positions are clamped to the length of the sequence (sequence_length). Position outside of the sequence are not taken into account for computing the loss.
Returns
transformers.modeling_outputs.QuestionAnsweringModelOutput or tuple(torch.FloatTensor)
A transformers.modeling_outputs.QuestionAnsweringModelOutput or a tuple of
torch.FloatTensor (if return_dict=False is passed or when config.return_dict=False) comprising various
elements depending on the configuration (YosoConfig) and inputs.
-
loss (
torch.FloatTensorof shape(1,), optional, returned whenlabelsis provided) — Total span extraction loss is the sum of a Cross-Entropy for the start and end positions. -
start_logits (
torch.FloatTensorof shape(batch_size, sequence_length)) — Span-start scores (before SoftMax). -
end_logits (
torch.FloatTensorof shape(batch_size, sequence_length)) — Span-end scores (before SoftMax). -
hidden_states (
tuple(torch.FloatTensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftorch.FloatTensor(one for the output of the embeddings, if the model has an embedding layer, + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size).Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
-
attentions (
tuple(torch.FloatTensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length).Attentions weights after the attention softmax, used to compute the weighted average in the self-attention heads.
The YosoForQuestionAnswering forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Module
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
Example:
>>> from transformers import AutoTokenizer, YosoForQuestionAnswering
>>> import torch
>>> tokenizer = AutoTokenizer.from_pretrained("uw-madison/yoso-4096")
>>> model = YosoForQuestionAnswering.from_pretrained("uw-madison/yoso-4096")
>>> question, text = "Who was Jim Henson?", "Jim Henson was a nice puppet"
>>> inputs = tokenizer(question, text, return_tensors="pt")
>>> with torch.no_grad():
... outputs = model(**inputs)
>>> answer_start_index = outputs.start_logits.argmax()
>>> answer_end_index = outputs.end_logits.argmax()
>>> predict_answer_tokens = inputs.input_ids[0, answer_start_index : answer_end_index + 1]
>>> # target is "nice puppet"
>>> target_start_index = torch.tensor([14])
>>> target_end_index = torch.tensor([15])
>>> outputs = model(**inputs, start_positions=target_start_index, end_positions=target_end_index)
>>> loss = outputs.loss