Diffusers documentation
Text-to-Image Generation with ControlNet Conditioning
Text-to-Image Generation with ControlNet Conditioning
Overview
Adding Conditional Control to Text-to-Image Diffusion Models by Lvmin Zhang and Maneesh Agrawala.
Using the pretrained models we can provide control images (for example, a depth map) to control Stable Diffusion text-to-image generation so that it follows the structure of the depth image and fills in the details.
The abstract of the paper is the following:
We present a neural network structure, ControlNet, to control pretrained large diffusion models to support additional input conditions. The ControlNet learns task-specific conditions in an end-to-end way, and the learning is robust even when the training dataset is small (< 50k). Moreover, training a ControlNet is as fast as fine-tuning a diffusion model, and the model can be trained on a personal devices. Alternatively, if powerful computation clusters are available, the model can scale to large amounts (millions to billions) of data. We report that large diffusion models like Stable Diffusion can be augmented with ControlNets to enable conditional inputs like edge maps, segmentation maps, keypoints, etc. This may enrich the methods to control large diffusion models and further facilitate related applications.
This model was contributed by the community contributor takuma104 ❤️ .
Resources:
Available Pipelines:
| Pipeline | Tasks | Demo |
|---|---|---|
| StableDiffusionControlNetPipeline | Text-to-Image Generation with ControlNet Conditioning | Colab Example |
| StableDiffusionControlNetImg2ImgPipeline | Image-to-Image Generation with ControlNet Conditioning | |
| StableDiffusionControlNetInpaintPipeline | Inpainting Generation with ControlNet Conditioning |
Usage example
In the following we give a simple example of how to use a ControlNet checkpoint with Diffusers for inference. The inference pipeline is the same for all pipelines:
- Take an image and run it through a pre-conditioning processor.
- Run the pre-processed image through the StableDiffusionControlNetPipeline.
Let’s have a look at a simple example using the Canny Edge ControlNet.
from diffusers import StableDiffusionControlNetPipeline
from diffusers.utils import load_image
# Let's load the popular vermeer image
image = load_image(
"https://hf.co/datasets/huggingface/documentation-images/resolve/main/diffusers/input_image_vermeer.png"
)
Next, we process the image to get the canny image. This is step 1. - running the pre-conditioning processor. The pre-conditioning processor is different for every ControlNet. Please see the model cards of the official checkpoints for more information about other models.
First, we need to install opencv:
pip install opencv-contrib-pythonNext, let’s also install all required Hugging Face libraries:
pip install diffusers transformers git+https://github.com/huggingface/accelerate.gitThen we can retrieve the canny edges of the image.
import cv2
from PIL import Image
import numpy as np
image = np.array(image)
low_threshold = 100
high_threshold = 200
image = cv2.Canny(image, low_threshold, high_threshold)
image = image[:, :, None]
image = np.concatenate([image, image, image], axis=2)
canny_image = Image.fromarray(image)Let’s take a look at the processed image.

Now, we load the official Stable Diffusion 1.5 Model as well as the ControlNet for canny edges.
from diffusers import StableDiffusionControlNetPipeline, ControlNetModel
import torch
controlnet = ControlNetModel.from_pretrained("lllyasviel/sd-controlnet-canny", torch_dtype=torch.float16)
pipe = StableDiffusionControlNetPipeline.from_pretrained(
"runwayml/stable-diffusion-v1-5", controlnet=controlnet, torch_dtype=torch.float16
)To speed-up things and reduce memory, let’s enable model offloading and use the fast UniPCMultistepScheduler.
from diffusers import UniPCMultistepScheduler
pipe.scheduler = UniPCMultistepScheduler.from_config(pipe.scheduler.config)
# this command loads the individual model components on GPU on-demand.
pipe.enable_model_cpu_offload()Finally, we can run the pipeline:
generator = torch.manual_seed(0)
out_image = pipe(
"disco dancer with colorful lights", num_inference_steps=20, generator=generator, image=canny_image
).images[0]This should take only around 3-4 seconds on GPU (depending on hardware). The output image then looks as follows:

Note: To see how to run all other ControlNet checkpoints, please have a look at ControlNet with Stable Diffusion 1.5.
Combining multiple conditionings
Multiple ControlNet conditionings can be combined for a single image generation. Pass a list of ControlNets to the pipeline’s constructor and a corresponding list of conditionings to __call__.
When combining conditionings, it is helpful to mask conditionings such that they do not overlap. In the example, we mask the middle of the canny map where the pose conditioning is located.
It can also be helpful to vary the controlnet_conditioning_scales to emphasize one conditioning over the other.
Canny conditioning
The original image:

Prepare the conditioning:
from diffusers.utils import load_image
from PIL import Image
import cv2
import numpy as np
from diffusers.utils import load_image
canny_image = load_image(
"https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/landscape.png"
)
canny_image = np.array(canny_image)
low_threshold = 100
high_threshold = 200
canny_image = cv2.Canny(canny_image, low_threshold, high_threshold)
# zero out middle columns of image where pose will be overlayed
zero_start = canny_image.shape[1] // 4
zero_end = zero_start + canny_image.shape[1] // 2
canny_image[:, zero_start:zero_end] = 0
canny_image = canny_image[:, :, None]
canny_image = np.concatenate([canny_image, canny_image, canny_image], axis=2)
canny_image = Image.fromarray(canny_image)
Openpose conditioning
The original image:

Prepare the conditioning:
from controlnet_aux import OpenposeDetector
from diffusers.utils import load_image
openpose = OpenposeDetector.from_pretrained("lllyasviel/ControlNet")
openpose_image = load_image(
"https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/person.png"
)
openpose_image = openpose(openpose_image)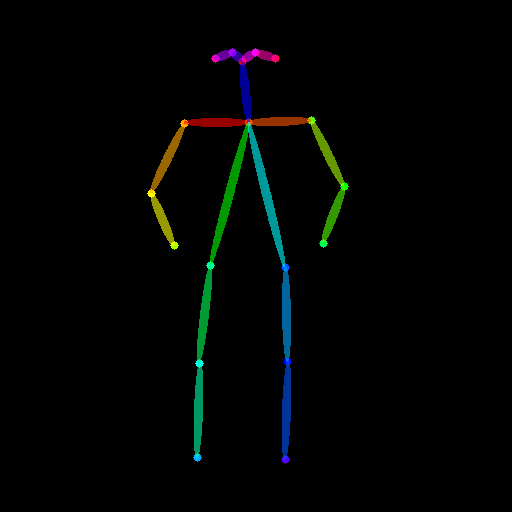
Running ControlNet with multiple conditionings
from diffusers import StableDiffusionControlNetPipeline, ControlNetModel, UniPCMultistepScheduler
import torch
controlnet = [
ControlNetModel.from_pretrained("lllyasviel/sd-controlnet-openpose", torch_dtype=torch.float16),
ControlNetModel.from_pretrained("lllyasviel/sd-controlnet-canny", torch_dtype=torch.float16),
]
pipe = StableDiffusionControlNetPipeline.from_pretrained(
"runwayml/stable-diffusion-v1-5", controlnet=controlnet, torch_dtype=torch.float16
)
pipe.scheduler = UniPCMultistepScheduler.from_config(pipe.scheduler.config)
pipe.enable_xformers_memory_efficient_attention()
pipe.enable_model_cpu_offload()
prompt = "a giant standing in a fantasy landscape, best quality"
negative_prompt = "monochrome, lowres, bad anatomy, worst quality, low quality"
generator = torch.Generator(device="cpu").manual_seed(1)
images = [openpose_image, canny_image]
image = pipe(
prompt,
images,
num_inference_steps=20,
generator=generator,
negative_prompt=negative_prompt,
controlnet_conditioning_scale=[1.0, 0.8],
).images[0]
image.save("./multi_controlnet_output.png")
Guess Mode
Guess Mode is a ControlNet feature that was implemented after the publication of the paper. The description states:
In this mode, the ControlNet encoder will try best to recognize the content of the input control map, like depth map, edge map, scribbles, etc, even if you remove all prompts.
The core implementation:
It adjusts the scale of the output residuals from ControlNet by a fixed ratio depending on the block depth. The shallowest DownBlock corresponds to 0.1. As the blocks get deeper, the scale increases exponentially, and the scale for the output of the MidBlock becomes 1.0.
Since the core implementation is just this, it does not have any impact on prompt conditioning. While it is common to use it without specifying any prompts, it is also possible to provide prompts if desired.
Usage:
Just specify guess_mode=True in the pipe() function. A guidance_scale between 3.0 and 5.0 is recommended.
from diffusers import StableDiffusionControlNetPipeline, ControlNetModel
import torch
controlnet = ControlNetModel.from_pretrained("lllyasviel/sd-controlnet-canny")
pipe = StableDiffusionControlNetPipeline.from_pretrained("runwayml/stable-diffusion-v1-5", controlnet=controlnet).to(
"cuda"
)
image = pipe("", image=canny_image, guess_mode=True, guidance_scale=3.0).images[0]
image.save("guess_mode_generated.png")Output image comparison:
Canny Control Example| no guess_mode with prompt | guess_mode without prompt |
|---|---|
 |
 |
Available checkpoints
ControlNet requires a control image in addition to the text-to-image prompt. Each pretrained model is trained using a different conditioning method that requires different images for conditioning the generated outputs. For example, Canny edge conditioning requires the control image to be the output of a Canny filter, while depth conditioning requires the control image to be a depth map. See the overview and image examples below to know more.
All checkpoints can be found under the authors’ namespace lllyasviel.
13.04.2024 Update: The author has released improved controlnet checkpoints v1.1 - see here.
ControlNet v1.0
| Model Name | Control Image Overview | Control Image Example | Generated Image Example |
|---|---|---|---|
| lllyasviel/sd-controlnet-canny Trained with canny edge detection |
A monochrome image with white edges on a black background. |  |
 |
| lllyasviel/sd-controlnet-depth Trained with Midas depth estimation |
A grayscale image with black representing deep areas and white representing shallow areas. |  |
 |
| lllyasviel/sd-controlnet-hed Trained with HED edge detection (soft edge) |
A monochrome image with white soft edges on a black background. |  |
 |
| lllyasviel/sd-controlnet-mlsd Trained with M-LSD line detection |
A monochrome image composed only of white straight lines on a black background. |  |
 |
| lllyasviel/sd-controlnet-normal Trained with normal map |
A normal mapped image. |  |
 |
| lllyasviel/sd-controlnet-openpose Trained with OpenPose bone image |
A OpenPose bone image. |  |
 |
| lllyasviel/sd-controlnet-scribble Trained with human scribbles |
A hand-drawn monochrome image with white outlines on a black background. |  |
 |
| lllyasviel/sd-controlnet-seg Trained with semantic segmentation |
An ADE20K’s segmentation protocol image. |  |
 |
ControlNet v1.1
| Model Name | Control Image Overview | Condition Image | Control Image Example | Generated Image Example |
|---|---|---|---|---|
| lllyasviel/control_v11p_sd15_canny |
Trained with canny edge detection | A monochrome image with white edges on a black background. |  |
 |
| lllyasviel/control_v11e_sd15_ip2p |
Trained with pixel to pixel instruction | No condition . |  |
 |
| lllyasviel/control_v11p_sd15_inpaint |
Trained with image inpainting | No condition. |  |
 |
| lllyasviel/control_v11p_sd15_mlsd |
Trained with multi-level line segment detection | An image with annotated line segments. |  |
 |
| lllyasviel/control_v11f1p_sd15_depth |
Trained with depth estimation | An image with depth information, usually represented as a grayscale image. |  |
 |
| lllyasviel/control_v11p_sd15_normalbae |
Trained with surface normal estimation | An image with surface normal information, usually represented as a color-coded image. |  |
 |
| lllyasviel/control_v11p_sd15_seg |
Trained with image segmentation | An image with segmented regions, usually represented as a color-coded image. |  |
 |
| lllyasviel/control_v11p_sd15_lineart |
Trained with line art generation | An image with line art, usually black lines on a white background. |  |
 |
| lllyasviel/control_v11p_sd15s2_lineart_anime |
Trained with anime line art generation | An image with anime-style line art. |  |
 |
| lllyasviel/control_v11p_sd15_openpose |
Trained with human pose estimation | An image with human poses, usually represented as a set of keypoints or skeletons. |  |
 |
| lllyasviel/control_v11p_sd15_scribble |
Trained with scribble-based image generation | An image with scribbles, usually random or user-drawn strokes. |  |
 |
| lllyasviel/control_v11p_sd15_softedge |
Trained with soft edge image generation | An image with soft edges, usually to create a more painterly or artistic effect. |  |
 |
| lllyasviel/control_v11e_sd15_shuffle |
Trained with image shuffling | An image with shuffled patches or regions. |  |
 |
| lllyasviel/control_v11f1e_sd15_tile |
Trained with image tiling | A blurry image or part of an image . |  |
 |
StableDiffusionControlNetPipeline
class diffusers.StableDiffusionControlNetPipeline
< source >( vae: AutoencoderKL text_encoder: CLIPTextModel tokenizer: CLIPTokenizer unet: UNet2DConditionModel controlnet: typing.Union[diffusers.models.controlnet.ControlNetModel, typing.List[diffusers.models.controlnet.ControlNetModel], typing.Tuple[diffusers.models.controlnet.ControlNetModel], diffusers.pipelines.controlnet.multicontrolnet.MultiControlNetModel] scheduler: KarrasDiffusionSchedulers safety_checker: StableDiffusionSafetyChecker feature_extractor: CLIPImageProcessor requires_safety_checker: bool = True )
Parameters
- vae (AutoencoderKL) — Variational Auto-Encoder (VAE) Model to encode and decode images to and from latent representations.
-
text_encoder (
CLIPTextModel) — Frozen text-encoder. Stable Diffusion uses the text portion of CLIP, specifically the clip-vit-large-patch14 variant. -
tokenizer (
CLIPTokenizer) — Tokenizer of class CLIPTokenizer. - unet (UNet2DConditionModel) — Conditional U-Net architecture to denoise the encoded image latents.
-
controlnet (ControlNetModel or
List[ControlNetModel]) — Provides additional conditioning to the unet during the denoising process. If you set multiple ControlNets as a list, the outputs from each ControlNet are added together to create one combined additional conditioning. -
scheduler (SchedulerMixin) —
A scheduler to be used in combination with
unetto denoise the encoded image latents. Can be one of DDIMScheduler, LMSDiscreteScheduler, or PNDMScheduler. -
safety_checker (
StableDiffusionSafetyChecker) — Classification module that estimates whether generated images could be considered offensive or harmful. Please, refer to the model card for details. -
feature_extractor (
CLIPImageProcessor) — Model that extracts features from generated images to be used as inputs for thesafety_checker.
Pipeline for text-to-image generation using Stable Diffusion with ControlNet guidance.
This model inherits from DiffusionPipeline. Check the superclass documentation for the generic methods the library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
In addition the pipeline inherits the following loading methods:
- Textual-Inversion: loaders.TextualInversionLoaderMixin.load_textual_inversion()
__call__
< source >(
prompt: typing.Union[str, typing.List[str]] = None
image: typing.Union[torch.FloatTensor, PIL.Image.Image, numpy.ndarray, typing.List[torch.FloatTensor], typing.List[PIL.Image.Image], typing.List[numpy.ndarray]] = None
height: typing.Optional[int] = None
width: typing.Optional[int] = None
num_inference_steps: int = 50
guidance_scale: float = 7.5
negative_prompt: typing.Union[str, typing.List[str], NoneType] = None
num_images_per_prompt: typing.Optional[int] = 1
eta: float = 0.0
generator: typing.Union[torch._C.Generator, typing.List[torch._C.Generator], NoneType] = None
latents: typing.Optional[torch.FloatTensor] = None
prompt_embeds: typing.Optional[torch.FloatTensor] = None
negative_prompt_embeds: typing.Optional[torch.FloatTensor] = None
output_type: typing.Optional[str] = 'pil'
return_dict: bool = True
callback: typing.Union[typing.Callable[[int, int, torch.FloatTensor], NoneType], NoneType] = None
callback_steps: int = 1
cross_attention_kwargs: typing.Union[typing.Dict[str, typing.Any], NoneType] = None
controlnet_conditioning_scale: typing.Union[float, typing.List[float]] = 1.0
guess_mode: bool = False
)
→
StableDiffusionPipelineOutput or tuple
Parameters
-
prompt (
strorList[str], optional) — The prompt or prompts to guide the image generation. If not defined, one has to passprompt_embeds. instead. -
image (
torch.FloatTensor,PIL.Image.Image,np.ndarray,List[torch.FloatTensor],List[PIL.Image.Image],List[np.ndarray], —List[List[torch.FloatTensor]],List[List[np.ndarray]]orList[List[PIL.Image.Image]]): The ControlNet input condition. ControlNet uses this input condition to generate guidance to Unet. If the type is specified asTorch.FloatTensor, it is passed to ControlNet as is.PIL.Image.Imagecan also be accepted as an image. The dimensions of the output image defaults toimage’s dimensions. If height and/or width are passed,imageis resized according to them. If multiple ControlNets are specified in init, images must be passed as a list such that each element of the list can be correctly batched for input to a single controlnet. -
height (
int, optional, defaults to self.unet.config.sample_size * self.vae_scale_factor) — The height in pixels of the generated image. -
width (
int, optional, defaults to self.unet.config.sample_size * self.vae_scale_factor) — The width in pixels of the generated image. -
num_inference_steps (
int, optional, defaults to 50) — The number of denoising steps. More denoising steps usually lead to a higher quality image at the expense of slower inference. -
guidance_scale (
float, optional, defaults to 7.5) — Guidance scale as defined in Classifier-Free Diffusion Guidance.guidance_scaleis defined aswof equation 2. of Imagen Paper. Guidance scale is enabled by settingguidance_scale > 1. Higher guidance scale encourages to generate images that are closely linked to the textprompt, usually at the expense of lower image quality. -
negative_prompt (
strorList[str], optional) — The prompt or prompts not to guide the image generation. If not defined, one has to passnegative_prompt_embedsinstead. Ignored when not using guidance (i.e., ignored ifguidance_scaleis less than1). -
num_images_per_prompt (
int, optional, defaults to 1) — The number of images to generate per prompt. -
eta (
float, optional, defaults to 0.0) — Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to schedulers.DDIMScheduler, will be ignored for others. -
generator (
torch.GeneratororList[torch.Generator], optional) — One or a list of torch generator(s) to make generation deterministic. -
latents (
torch.FloatTensor, optional) — Pre-generated noisy latents, sampled from a Gaussian distribution, to be used as inputs for image generation. Can be used to tweak the same generation with different prompts. If not provided, a latents tensor will ge generated by sampling using the supplied randomgenerator. -
prompt_embeds (
torch.FloatTensor, optional) — Pre-generated text embeddings. Can be used to easily tweak text inputs, e.g. prompt weighting. If not provided, text embeddings will be generated frompromptinput argument. -
negative_prompt_embeds (
torch.FloatTensor, optional) — Pre-generated negative text embeddings. Can be used to easily tweak text inputs, e.g. prompt weighting. If not provided, negative_prompt_embeds will be generated fromnegative_promptinput argument. -
output_type (
str, optional, defaults to"pil") — The output format of the generate image. Choose between PIL:PIL.Image.Imageornp.array. -
return_dict (
bool, optional, defaults toTrue) — Whether or not to return a StableDiffusionPipelineOutput instead of a plain tuple. -
callback (
Callable, optional) — A function that will be called everycallback_stepssteps during inference. The function will be called with the following arguments:callback(step: int, timestep: int, latents: torch.FloatTensor). -
callback_steps (
int, optional, defaults to 1) — The frequency at which thecallbackfunction will be called. If not specified, the callback will be called at every step. -
cross_attention_kwargs (
dict, optional) — A kwargs dictionary that if specified is passed along to theAttentionProcessoras defined underself.processorin diffusers.cross_attention. -
controlnet_conditioning_scale (
floatorList[float], optional, defaults to 1.0) — The outputs of the controlnet are multiplied bycontrolnet_conditioning_scalebefore they are added to the residual in the original unet. If multiple ControlNets are specified in init, you can set the corresponding scale as a list. -
guess_mode (
bool, optional, defaults toFalse) — In this mode, the ControlNet encoder will try best to recognize the content of the input image even if you remove all prompts. Theguidance_scalebetween 3.0 and 5.0 is recommended.
Returns
StableDiffusionPipelineOutput or tuple
StableDiffusionPipelineOutput if return_dict is True, otherwise a tuple. When returning a tuple, the first element is a list with the generated images, and the second element is a list of bools denoting whether the corresponding generated image likely represents "not-safe-for-work" (nsfw) content, according to the safety_checker`.
Function invoked when calling the pipeline for generation.
Examples:
>>> # !pip install opencv-python transformers accelerate
>>> from diffusers import StableDiffusionControlNetPipeline, ControlNetModel, UniPCMultistepScheduler
>>> from diffusers.utils import load_image
>>> import numpy as np
>>> import torch
>>> import cv2
>>> from PIL import Image
>>> # download an image
>>> image = load_image(
... "https://hf.co/datasets/huggingface/documentation-images/resolve/main/diffusers/input_image_vermeer.png"
... )
>>> image = np.array(image)
>>> # get canny image
>>> image = cv2.Canny(image, 100, 200)
>>> image = image[:, :, None]
>>> image = np.concatenate([image, image, image], axis=2)
>>> canny_image = Image.fromarray(image)
>>> # load control net and stable diffusion v1-5
>>> controlnet = ControlNetModel.from_pretrained("lllyasviel/sd-controlnet-canny", torch_dtype=torch.float16)
>>> pipe = StableDiffusionControlNetPipeline.from_pretrained(
... "runwayml/stable-diffusion-v1-5", controlnet=controlnet, torch_dtype=torch.float16
... )
>>> # speed up diffusion process with faster scheduler and memory optimization
>>> pipe.scheduler = UniPCMultistepScheduler.from_config(pipe.scheduler.config)
>>> # remove following line if xformers is not installed
>>> pipe.enable_xformers_memory_efficient_attention()
>>> pipe.enable_model_cpu_offload()
>>> # generate image
>>> generator = torch.manual_seed(0)
>>> image = pipe(
... "futuristic-looking woman", num_inference_steps=20, generator=generator, image=canny_image
... ).images[0]enable_attention_slicing
< source >( slice_size: typing.Union[str, int, NoneType] = 'auto' )
Parameters
-
slice_size (
strorint, optional, defaults to"auto") — When"auto", halves the input to the attention heads, so attention will be computed in two steps. If"max", maximum amount of memory will be saved by running only one slice at a time. If a number is provided, uses as many slices asattention_head_dim // slice_size. In this case,attention_head_dimmust be a multiple ofslice_size.
Enable sliced attention computation.
When this option is enabled, the attention module will split the input tensor in slices, to compute attention in several steps. This is useful to save some memory in exchange for a small speed decrease.
Disable sliced attention computation. If enable_attention_slicing was previously invoked, this method will go
back to computing attention in one step.
Enable sliced VAE decoding.
When this option is enabled, the VAE will split the input tensor in slices to compute decoding in several steps. This is useful to save some memory and allow larger batch sizes.
Disable sliced VAE decoding. If enable_vae_slicing was previously invoked, this method will go back to
computing decoding in one step.
enable_xformers_memory_efficient_attention
< source >( attention_op: typing.Optional[typing.Callable] = None )
Parameters
-
attention_op (
Callable, optional) — Override the defaultNoneoperator for use asopargument to thememory_efficient_attention()function of xFormers.
Enable memory efficient attention as implemented in xformers.
When this option is enabled, you should observe lower GPU memory usage and a potential speed up at inference time. Speed up at training time is not guaranteed.
Warning: When Memory Efficient Attention and Sliced attention are both enabled, the Memory Efficient Attention is used.
Examples:
>>> import torch
>>> from diffusers import DiffusionPipeline
>>> from xformers.ops import MemoryEfficientAttentionFlashAttentionOp
>>> pipe = DiffusionPipeline.from_pretrained("stabilityai/stable-diffusion-2-1", torch_dtype=torch.float16)
>>> pipe = pipe.to("cuda")
>>> pipe.enable_xformers_memory_efficient_attention(attention_op=MemoryEfficientAttentionFlashAttentionOp)
>>> # Workaround for not accepting attention shape using VAE for Flash Attention
>>> pipe.vae.enable_xformers_memory_efficient_attention(attention_op=None)Disable memory efficient attention as implemented in xformers.
load_textual_inversion
< source >( pretrained_model_name_or_path: typing.Union[str, typing.List[str], typing.Dict[str, torch.Tensor], typing.List[typing.Dict[str, torch.Tensor]]] token: typing.Union[str, typing.List[str], NoneType] = None **kwargs )
Parameters
-
pretrained_model_name_or_path (
stroros.PathLikeorList[str or os.PathLike]orDictorList[Dict]) — Can be either:- A string, the model id of a pretrained model hosted inside a model repo on huggingface.co.
Valid model ids should have an organization name, like
"sd-concepts-library/low-poly-hd-logos-icons". - A path to a directory containing textual inversion weights, e.g.
./my_text_inversion_directory/. - A path to a file containing textual inversion weights, e.g.
./my_text_inversions.pt. - A torch state dict.
Or a list of those elements.
- A string, the model id of a pretrained model hosted inside a model repo on huggingface.co.
Valid model ids should have an organization name, like
-
token (
strorList[str], optional) — Override the token to use for the textual inversion weights. Ifpretrained_model_name_or_pathis a list, thentokenmust also be a list of equal length. -
weight_name (
str, optional) — Name of a custom weight file. This should be used in two cases:- The saved textual inversion file is in
diffusersformat, but was saved under a specific weight name, such astext_inv.bin. - The saved textual inversion file is in the “Automatic1111” form.
- The saved textual inversion file is in
-
cache_dir (
Union[str, os.PathLike], optional) — Path to a directory in which a downloaded pretrained model configuration should be cached if the standard cache should not be used. -
force_download (
bool, optional, defaults toFalse) — Whether or not to force the (re-)download of the model weights and configuration files, overriding the cached versions if they exist. -
resume_download (
bool, optional, defaults toFalse) — Whether or not to delete incompletely received files. Will attempt to resume the download if such a file exists. -
proxies (
Dict[str, str], optional) — A dictionary of proxy servers to use by protocol or endpoint, e.g.,{'http': 'foo.bar:3128', 'http://hostname': 'foo.bar:4012'}. The proxies are used on each request. -
local_files_only(
bool, optional, defaults toFalse) — Whether or not to only look at local files (i.e., do not try to download the model). -
use_auth_token (
stror bool, optional) — The token to use as HTTP bearer authorization for remote files. IfTrue, will use the token generated when runningdiffusers-cli login(stored in~/.huggingface). -
revision (
str, optional, defaults to"main") — The specific model version to use. It can be a branch name, a tag name, or a commit id, since we use a git-based system for storing models and other artifacts on huggingface.co, sorevisioncan be any identifier allowed by git. -
subfolder (
str, optional, defaults to"") — In case the relevant files are located inside a subfolder of the model repo (either remote in huggingface.co or downloaded locally), you can specify the folder name here. -
mirror (
str, optional) — Mirror source to accelerate downloads in China. If you are from China and have an accessibility problem, you can set this option to resolve it. Note that we do not guarantee the timeliness or safety. Please refer to the mirror site for more information.
Load textual inversion embeddings into the text encoder of stable diffusion pipelines. Both diffusers and
Automatic1111 formats are supported (see example below).
This function is experimental and might change in the future.
It is required to be logged in (huggingface-cli login) when you want to use private or gated
models.
Example:
To load a textual inversion embedding vector in diffusers format:
from diffusers import StableDiffusionPipeline
import torch
model_id = "runwayml/stable-diffusion-v1-5"
pipe = StableDiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16).to("cuda")
pipe.load_textual_inversion("sd-concepts-library/cat-toy")
prompt = "A <cat-toy> backpack"
image = pipe(prompt, num_inference_steps=50).images[0]
image.save("cat-backpack.png")To load a textual inversion embedding vector in Automatic1111 format, make sure to first download the vector,
e.g. from civitAI and then load the vector locally:
from diffusers import StableDiffusionPipeline
import torch
model_id = "runwayml/stable-diffusion-v1-5"
pipe = StableDiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16).to("cuda")
pipe.load_textual_inversion("./charturnerv2.pt", token="charturnerv2")
prompt = "charturnerv2, multiple views of the same character in the same outfit, a character turnaround of a woman wearing a black jacket and red shirt, best quality, intricate details."
image = pipe(prompt, num_inference_steps=50).images[0]
image.save("character.png")Disable tiled VAE decoding. If enable_vae_tiling was previously invoked, this method will go back to
computing decoding in one step.
Offloads all models to CPU using accelerate, reducing memory usage with a low impact on performance. Compared
to enable_sequential_cpu_offload, this method moves one whole model at a time to the GPU when its forward
method is called, and the model remains in GPU until the next model runs. Memory savings are lower than with
enable_sequential_cpu_offload, but performance is much better due to the iterative execution of the unet.
Offloads all models to CPU using accelerate, significantly reducing memory usage. When called, unet,
text_encoder, vae, controlnet, and safety checker have their state dicts saved to CPU and then are moved to a
torch.device('meta') and loaded to GPU only when their specific submodule has its forwardmethod called. Note that offloading happens on a submodule basis. Memory savings are higher than withenable_model_cpu_offload`, but performance is lower.
Enable tiled VAE decoding.
When this option is enabled, the VAE will split the input tensor into tiles to compute decoding and encoding in several steps. This is useful to save a large amount of memory and to allow the processing of larger images.
StableDiffusionControlNetImg2ImgPipeline
class diffusers.StableDiffusionControlNetImg2ImgPipeline
< source >( vae: AutoencoderKL text_encoder: CLIPTextModel tokenizer: CLIPTokenizer unet: UNet2DConditionModel controlnet: typing.Union[diffusers.models.controlnet.ControlNetModel, typing.List[diffusers.models.controlnet.ControlNetModel], typing.Tuple[diffusers.models.controlnet.ControlNetModel], diffusers.pipelines.controlnet.multicontrolnet.MultiControlNetModel] scheduler: KarrasDiffusionSchedulers safety_checker: StableDiffusionSafetyChecker feature_extractor: CLIPImageProcessor requires_safety_checker: bool = True )
Parameters
- vae (AutoencoderKL) — Variational Auto-Encoder (VAE) Model to encode and decode images to and from latent representations.
-
text_encoder (
CLIPTextModel) — Frozen text-encoder. Stable Diffusion uses the text portion of CLIP, specifically the clip-vit-large-patch14 variant. -
tokenizer (
CLIPTokenizer) — Tokenizer of class CLIPTokenizer. - unet (UNet2DConditionModel) — Conditional U-Net architecture to denoise the encoded image latents.
-
controlnet (ControlNetModel or
List[ControlNetModel]) — Provides additional conditioning to the unet during the denoising process. If you set multiple ControlNets as a list, the outputs from each ControlNet are added together to create one combined additional conditioning. -
scheduler (SchedulerMixin) —
A scheduler to be used in combination with
unetto denoise the encoded image latents. Can be one of DDIMScheduler, LMSDiscreteScheduler, or PNDMScheduler. -
safety_checker (
StableDiffusionSafetyChecker) — Classification module that estimates whether generated images could be considered offensive or harmful. Please, refer to the model card for details. -
feature_extractor (
CLIPImageProcessor) — Model that extracts features from generated images to be used as inputs for thesafety_checker.
Pipeline for text-to-image generation using Stable Diffusion with ControlNet guidance.
This model inherits from DiffusionPipeline. Check the superclass documentation for the generic methods the library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
In addition the pipeline inherits the following loading methods:
- Textual-Inversion: loaders.TextualInversionLoaderMixin.load_textual_inversion()
__call__
< source >(
prompt: typing.Union[str, typing.List[str]] = None
image: typing.Union[torch.FloatTensor, PIL.Image.Image, numpy.ndarray, typing.List[torch.FloatTensor], typing.List[PIL.Image.Image], typing.List[numpy.ndarray]] = None
control_image: typing.Union[torch.FloatTensor, PIL.Image.Image, numpy.ndarray, typing.List[torch.FloatTensor], typing.List[PIL.Image.Image], typing.List[numpy.ndarray]] = None
height: typing.Optional[int] = None
width: typing.Optional[int] = None
strength: float = 0.8
num_inference_steps: int = 50
guidance_scale: float = 7.5
negative_prompt: typing.Union[str, typing.List[str], NoneType] = None
num_images_per_prompt: typing.Optional[int] = 1
eta: float = 0.0
generator: typing.Union[torch._C.Generator, typing.List[torch._C.Generator], NoneType] = None
latents: typing.Optional[torch.FloatTensor] = None
prompt_embeds: typing.Optional[torch.FloatTensor] = None
negative_prompt_embeds: typing.Optional[torch.FloatTensor] = None
output_type: typing.Optional[str] = 'pil'
return_dict: bool = True
callback: typing.Union[typing.Callable[[int, int, torch.FloatTensor], NoneType], NoneType] = None
callback_steps: int = 1
cross_attention_kwargs: typing.Union[typing.Dict[str, typing.Any], NoneType] = None
controlnet_conditioning_scale: typing.Union[float, typing.List[float]] = 0.8
guess_mode: bool = False
)
→
StableDiffusionPipelineOutput or tuple
Parameters
-
prompt (
strorList[str], optional) — The prompt or prompts to guide the image generation. If not defined, one has to passprompt_embeds. instead. -
image (
torch.FloatTensor,PIL.Image.Image,np.ndarray,List[torch.FloatTensor],List[PIL.Image.Image],List[np.ndarray], —List[List[torch.FloatTensor]],List[List[np.ndarray]]orList[List[PIL.Image.Image]]): The initial image will be used as the starting point for the image generation process. Can also accpet image latents asimage, if passing latents directly, it will not be encoded again. -
control_image (
torch.FloatTensor,PIL.Image.Image,np.ndarray,List[torch.FloatTensor],List[PIL.Image.Image],List[np.ndarray], —List[List[torch.FloatTensor]],List[List[np.ndarray]]orList[List[PIL.Image.Image]]): The ControlNet input condition. ControlNet uses this input condition to generate guidance to Unet. If the type is specified asTorch.FloatTensor, it is passed to ControlNet as is.PIL.Image.Imagecan also be accepted as an image. The dimensions of the output image defaults toimage’s dimensions. If height and/or width are passed,imageis resized according to them. If multiple ControlNets are specified in init, images must be passed as a list such that each element of the list can be correctly batched for input to a single controlnet. -
height (
int, optional, defaults to self.unet.config.sample_size * self.vae_scale_factor) — The height in pixels of the generated image. -
width (
int, optional, defaults to self.unet.config.sample_size * self.vae_scale_factor) — The width in pixels of the generated image. -
num_inference_steps (
int, optional, defaults to 50) — The number of denoising steps. More denoising steps usually lead to a higher quality image at the expense of slower inference. -
guidance_scale (
float, optional, defaults to 7.5) — Guidance scale as defined in Classifier-Free Diffusion Guidance.guidance_scaleis defined aswof equation 2. of Imagen Paper. Guidance scale is enabled by settingguidance_scale > 1. Higher guidance scale encourages to generate images that are closely linked to the textprompt, usually at the expense of lower image quality. -
negative_prompt (
strorList[str], optional) — The prompt or prompts not to guide the image generation. If not defined, one has to passnegative_prompt_embedsinstead. Ignored when not using guidance (i.e., ignored ifguidance_scaleis less than1). -
num_images_per_prompt (
int, optional, defaults to 1) — The number of images to generate per prompt. -
eta (
float, optional, defaults to 0.0) — Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to schedulers.DDIMScheduler, will be ignored for others. -
generator (
torch.GeneratororList[torch.Generator], optional) — One or a list of torch generator(s) to make generation deterministic. -
latents (
torch.FloatTensor, optional) — Pre-generated noisy latents, sampled from a Gaussian distribution, to be used as inputs for image generation. Can be used to tweak the same generation with different prompts. If not provided, a latents tensor will ge generated by sampling using the supplied randomgenerator. -
prompt_embeds (
torch.FloatTensor, optional) — Pre-generated text embeddings. Can be used to easily tweak text inputs, e.g. prompt weighting. If not provided, text embeddings will be generated frompromptinput argument. -
negative_prompt_embeds (
torch.FloatTensor, optional) — Pre-generated negative text embeddings. Can be used to easily tweak text inputs, e.g. prompt weighting. If not provided, negative_prompt_embeds will be generated fromnegative_promptinput argument. -
output_type (
str, optional, defaults to"pil") — The output format of the generate image. Choose between PIL:PIL.Image.Imageornp.array. -
return_dict (
bool, optional, defaults toTrue) — Whether or not to return a StableDiffusionPipelineOutput instead of a plain tuple. -
callback (
Callable, optional) — A function that will be called everycallback_stepssteps during inference. The function will be called with the following arguments:callback(step: int, timestep: int, latents: torch.FloatTensor). -
callback_steps (
int, optional, defaults to 1) — The frequency at which thecallbackfunction will be called. If not specified, the callback will be called at every step. -
cross_attention_kwargs (
dict, optional) — A kwargs dictionary that if specified is passed along to theAttentionProcessoras defined underself.processorin diffusers.cross_attention. -
controlnet_conditioning_scale (
floatorList[float], optional, defaults to 1.0) — The outputs of the controlnet are multiplied bycontrolnet_conditioning_scalebefore they are added to the residual in the original unet. If multiple ControlNets are specified in init, you can set the corresponding scale as a list. Note that by default, we use a smaller conditioning scale for inpainting than for call(). -
guess_mode (
bool, optional, defaults toFalse) — In this mode, the ControlNet encoder will try best to recognize the content of the input image even if you remove all prompts. Theguidance_scalebetween 3.0 and 5.0 is recommended.
Returns
StableDiffusionPipelineOutput or tuple
StableDiffusionPipelineOutput if return_dict is True, otherwise a tuple. When returning a tuple, the first element is a list with the generated images, and the second element is a list of bools denoting whether the corresponding generated image likely represents "not-safe-for-work" (nsfw) content, according to the safety_checker`.
Function invoked when calling the pipeline for generation.
Examples:
>>> # !pip install opencv-python transformers accelerate
>>> from diffusers import StableDiffusionControlNetImg2ImgPipeline, ControlNetModel, UniPCMultistepScheduler
>>> from diffusers.utils import load_image
>>> import numpy as np
>>> import torch
>>> import cv2
>>> from PIL import Image
>>> # download an image
>>> image = load_image(
... "https://hf.co/datasets/huggingface/documentation-images/resolve/main/diffusers/input_image_vermeer.png"
... )
>>> np_image = np.array(image)
>>> # get canny image
>>> np_image = cv2.Canny(np_image, 100, 200)
>>> np_image = np_image[:, :, None]
>>> np_image = np.concatenate([np_image, np_image, np_image], axis=2)
>>> canny_image = Image.fromarray(np_image)
>>> # load control net and stable diffusion v1-5
>>> controlnet = ControlNetModel.from_pretrained("lllyasviel/sd-controlnet-canny", torch_dtype=torch.float16)
>>> pipe = StableDiffusionControlNetImg2ImgPipeline.from_pretrained(
... "runwayml/stable-diffusion-v1-5", controlnet=controlnet, torch_dtype=torch.float16
... )
>>> # speed up diffusion process with faster scheduler and memory optimization
>>> pipe.scheduler = UniPCMultistepScheduler.from_config(pipe.scheduler.config)
>>> pipe.enable_model_cpu_offload()
>>> # generate image
>>> generator = torch.manual_seed(0)
>>> image = pipe(
... "futuristic-looking woman",
... num_inference_steps=20,
... generator=generator,
... image=image,
... control_image=canny_image,
... ).images[0]enable_attention_slicing
< source >( slice_size: typing.Union[str, int, NoneType] = 'auto' )
Parameters
-
slice_size (
strorint, optional, defaults to"auto") — When"auto", halves the input to the attention heads, so attention will be computed in two steps. If"max", maximum amount of memory will be saved by running only one slice at a time. If a number is provided, uses as many slices asattention_head_dim // slice_size. In this case,attention_head_dimmust be a multiple ofslice_size.
Enable sliced attention computation.
When this option is enabled, the attention module will split the input tensor in slices, to compute attention in several steps. This is useful to save some memory in exchange for a small speed decrease.
Disable sliced attention computation. If enable_attention_slicing was previously invoked, this method will go
back to computing attention in one step.
Enable sliced VAE decoding.
When this option is enabled, the VAE will split the input tensor in slices to compute decoding in several steps. This is useful to save some memory and allow larger batch sizes.
Disable sliced VAE decoding. If enable_vae_slicing was previously invoked, this method will go back to
computing decoding in one step.
enable_xformers_memory_efficient_attention
< source >( attention_op: typing.Optional[typing.Callable] = None )
Parameters
-
attention_op (
Callable, optional) — Override the defaultNoneoperator for use asopargument to thememory_efficient_attention()function of xFormers.
Enable memory efficient attention as implemented in xformers.
When this option is enabled, you should observe lower GPU memory usage and a potential speed up at inference time. Speed up at training time is not guaranteed.
Warning: When Memory Efficient Attention and Sliced attention are both enabled, the Memory Efficient Attention is used.
Examples:
>>> import torch
>>> from diffusers import DiffusionPipeline
>>> from xformers.ops import MemoryEfficientAttentionFlashAttentionOp
>>> pipe = DiffusionPipeline.from_pretrained("stabilityai/stable-diffusion-2-1", torch_dtype=torch.float16)
>>> pipe = pipe.to("cuda")
>>> pipe.enable_xformers_memory_efficient_attention(attention_op=MemoryEfficientAttentionFlashAttentionOp)
>>> # Workaround for not accepting attention shape using VAE for Flash Attention
>>> pipe.vae.enable_xformers_memory_efficient_attention(attention_op=None)Disable memory efficient attention as implemented in xformers.
load_textual_inversion
< source >( pretrained_model_name_or_path: typing.Union[str, typing.List[str], typing.Dict[str, torch.Tensor], typing.List[typing.Dict[str, torch.Tensor]]] token: typing.Union[str, typing.List[str], NoneType] = None **kwargs )
Parameters
-
pretrained_model_name_or_path (
stroros.PathLikeorList[str or os.PathLike]orDictorList[Dict]) — Can be either:- A string, the model id of a pretrained model hosted inside a model repo on huggingface.co.
Valid model ids should have an organization name, like
"sd-concepts-library/low-poly-hd-logos-icons". - A path to a directory containing textual inversion weights, e.g.
./my_text_inversion_directory/. - A path to a file containing textual inversion weights, e.g.
./my_text_inversions.pt. - A torch state dict.
Or a list of those elements.
- A string, the model id of a pretrained model hosted inside a model repo on huggingface.co.
Valid model ids should have an organization name, like
-
token (
strorList[str], optional) — Override the token to use for the textual inversion weights. Ifpretrained_model_name_or_pathis a list, thentokenmust also be a list of equal length. -
weight_name (
str, optional) — Name of a custom weight file. This should be used in two cases:- The saved textual inversion file is in
diffusersformat, but was saved under a specific weight name, such astext_inv.bin. - The saved textual inversion file is in the “Automatic1111” form.
- The saved textual inversion file is in
-
cache_dir (
Union[str, os.PathLike], optional) — Path to a directory in which a downloaded pretrained model configuration should be cached if the standard cache should not be used. -
force_download (
bool, optional, defaults toFalse) — Whether or not to force the (re-)download of the model weights and configuration files, overriding the cached versions if they exist. -
resume_download (
bool, optional, defaults toFalse) — Whether or not to delete incompletely received files. Will attempt to resume the download if such a file exists. -
proxies (
Dict[str, str], optional) — A dictionary of proxy servers to use by protocol or endpoint, e.g.,{'http': 'foo.bar:3128', 'http://hostname': 'foo.bar:4012'}. The proxies are used on each request. -
local_files_only(
bool, optional, defaults toFalse) — Whether or not to only look at local files (i.e., do not try to download the model). -
use_auth_token (
stror bool, optional) — The token to use as HTTP bearer authorization for remote files. IfTrue, will use the token generated when runningdiffusers-cli login(stored in~/.huggingface). -
revision (
str, optional, defaults to"main") — The specific model version to use. It can be a branch name, a tag name, or a commit id, since we use a git-based system for storing models and other artifacts on huggingface.co, sorevisioncan be any identifier allowed by git. -
subfolder (
str, optional, defaults to"") — In case the relevant files are located inside a subfolder of the model repo (either remote in huggingface.co or downloaded locally), you can specify the folder name here. -
mirror (
str, optional) — Mirror source to accelerate downloads in China. If you are from China and have an accessibility problem, you can set this option to resolve it. Note that we do not guarantee the timeliness or safety. Please refer to the mirror site for more information.
Load textual inversion embeddings into the text encoder of stable diffusion pipelines. Both diffusers and
Automatic1111 formats are supported (see example below).
This function is experimental and might change in the future.
It is required to be logged in (huggingface-cli login) when you want to use private or gated
models.
Example:
To load a textual inversion embedding vector in diffusers format:
from diffusers import StableDiffusionPipeline
import torch
model_id = "runwayml/stable-diffusion-v1-5"
pipe = StableDiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16).to("cuda")
pipe.load_textual_inversion("sd-concepts-library/cat-toy")
prompt = "A <cat-toy> backpack"
image = pipe(prompt, num_inference_steps=50).images[0]
image.save("cat-backpack.png")To load a textual inversion embedding vector in Automatic1111 format, make sure to first download the vector,
e.g. from civitAI and then load the vector locally:
from diffusers import StableDiffusionPipeline
import torch
model_id = "runwayml/stable-diffusion-v1-5"
pipe = StableDiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16).to("cuda")
pipe.load_textual_inversion("./charturnerv2.pt", token="charturnerv2")
prompt = "charturnerv2, multiple views of the same character in the same outfit, a character turnaround of a woman wearing a black jacket and red shirt, best quality, intricate details."
image = pipe(prompt, num_inference_steps=50).images[0]
image.save("character.png")Disable tiled VAE decoding. If enable_vae_tiling was previously invoked, this method will go back to
computing decoding in one step.
Offloads all models to CPU using accelerate, reducing memory usage with a low impact on performance. Compared
to enable_sequential_cpu_offload, this method moves one whole model at a time to the GPU when its forward
method is called, and the model remains in GPU until the next model runs. Memory savings are lower than with
enable_sequential_cpu_offload, but performance is much better due to the iterative execution of the unet.
Offloads all models to CPU using accelerate, significantly reducing memory usage. When called, unet,
text_encoder, vae, controlnet, and safety checker have their state dicts saved to CPU and then are moved to a
torch.device('meta') and loaded to GPU only when their specific submodule has its forwardmethod called. Note that offloading happens on a submodule basis. Memory savings are higher than withenable_model_cpu_offload`, but performance is lower.
Enable tiled VAE decoding.
When this option is enabled, the VAE will split the input tensor into tiles to compute decoding and encoding in several steps. This is useful to save a large amount of memory and to allow the processing of larger images.
StableDiffusionControlNetInpaintPipeline
class diffusers.StableDiffusionControlNetInpaintPipeline
< source >( vae: AutoencoderKL text_encoder: CLIPTextModel tokenizer: CLIPTokenizer unet: UNet2DConditionModel controlnet: typing.Union[diffusers.models.controlnet.ControlNetModel, typing.List[diffusers.models.controlnet.ControlNetModel], typing.Tuple[diffusers.models.controlnet.ControlNetModel], diffusers.pipelines.controlnet.multicontrolnet.MultiControlNetModel] scheduler: KarrasDiffusionSchedulers safety_checker: StableDiffusionSafetyChecker feature_extractor: CLIPImageProcessor requires_safety_checker: bool = True )
Parameters
- vae (AutoencoderKL) — Variational Auto-Encoder (VAE) Model to encode and decode images to and from latent representations.
-
text_encoder (
CLIPTextModel) — Frozen text-encoder. Stable Diffusion uses the text portion of CLIP, specifically the clip-vit-large-patch14 variant. -
tokenizer (
CLIPTokenizer) — Tokenizer of class CLIPTokenizer. - unet (UNet2DConditionModel) — Conditional U-Net architecture to denoise the encoded image latents.
-
controlnet (ControlNetModel or
List[ControlNetModel]) — Provides additional conditioning to the unet during the denoising process. If you set multiple ControlNets as a list, the outputs from each ControlNet are added together to create one combined additional conditioning. -
scheduler (SchedulerMixin) —
A scheduler to be used in combination with
unetto denoise the encoded image latents. Can be one of DDIMScheduler, LMSDiscreteScheduler, or PNDMScheduler. -
safety_checker (
StableDiffusionSafetyChecker) — Classification module that estimates whether generated images could be considered offensive or harmful. Please, refer to the model card for details. -
feature_extractor (
CLIPImageProcessor) — Model that extracts features from generated images to be used as inputs for thesafety_checker.
Pipeline for text-to-image generation using Stable Diffusion with ControlNet guidance.
This model inherits from DiffusionPipeline. Check the superclass documentation for the generic methods the library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
In addition the pipeline inherits the following loading methods:
- Textual-Inversion: loaders.TextualInversionLoaderMixin.load_textual_inversion()
This pipeline can be used both with checkpoints that have been specifically fine-tuned for inpainting, such as runwayml/stable-diffusion-inpainting as well as default text-to-image stable diffusion checkpoints, such as runwayml/stable-diffusion-v1-5. Default text-to-image stable diffusion checkpoints might be preferable for controlnets that have been fine-tuned on those, such as lllyasviel/control_v11p_sd15_inpaint.
__call__
< source >(
prompt: typing.Union[str, typing.List[str]] = None
image: typing.Union[torch.Tensor, PIL.Image.Image] = None
mask_image: typing.Union[torch.Tensor, PIL.Image.Image] = None
control_image: typing.Union[torch.FloatTensor, PIL.Image.Image, numpy.ndarray, typing.List[torch.FloatTensor], typing.List[PIL.Image.Image], typing.List[numpy.ndarray]] = None
height: typing.Optional[int] = None
width: typing.Optional[int] = None
strength: float = 1.0
num_inference_steps: int = 50
guidance_scale: float = 7.5
negative_prompt: typing.Union[str, typing.List[str], NoneType] = None
num_images_per_prompt: typing.Optional[int] = 1
eta: float = 0.0
generator: typing.Union[torch._C.Generator, typing.List[torch._C.Generator], NoneType] = None
latents: typing.Optional[torch.FloatTensor] = None
prompt_embeds: typing.Optional[torch.FloatTensor] = None
negative_prompt_embeds: typing.Optional[torch.FloatTensor] = None
output_type: typing.Optional[str] = 'pil'
return_dict: bool = True
callback: typing.Union[typing.Callable[[int, int, torch.FloatTensor], NoneType], NoneType] = None
callback_steps: int = 1
cross_attention_kwargs: typing.Union[typing.Dict[str, typing.Any], NoneType] = None
controlnet_conditioning_scale: typing.Union[float, typing.List[float]] = 0.5
guess_mode: bool = False
)
→
StableDiffusionPipelineOutput or tuple
Parameters
-
prompt (
strorList[str], optional) — The prompt or prompts to guide the image generation. If not defined, one has to passprompt_embeds. instead. -
image (
torch.FloatTensor,PIL.Image.Image,List[torch.FloatTensor],List[PIL.Image.Image], —List[List[torch.FloatTensor]], orList[List[PIL.Image.Image]]): The ControlNet input condition. ControlNet uses this input condition to generate guidance to Unet. If the type is specified asTorch.FloatTensor, it is passed to ControlNet as is.PIL.Image.Imagecan also be accepted as an image. The dimensions of the output image defaults toimage’s dimensions. If height and/or width are passed,imageis resized according to them. If multiple ControlNets are specified in init, images must be passed as a list such that each element of the list can be correctly batched for input to a single controlnet. -
height (
int, optional, defaults to self.unet.config.sample_size * self.vae_scale_factor) — The height in pixels of the generated image. -
width (
int, optional, defaults to self.unet.config.sample_size * self.vae_scale_factor) — The width in pixels of the generated image. -
strength (
float, optional, defaults to 1.) — Conceptually, indicates how much to transform the masked portion of the referenceimage. Must be between 0 and 1.imagewill be used as a starting point, adding more noise to it the larger thestrength. The number of denoising steps depends on the amount of noise initially added. Whenstrengthis 1, added noise will be maximum and the denoising process will run for the full number of iterations specified innum_inference_steps. A value of 1, therefore, essentially ignores the masked portion of the referenceimage. -
num_inference_steps (
int, optional, defaults to 50) — The number of denoising steps. More denoising steps usually lead to a higher quality image at the expense of slower inference. -
guidance_scale (
float, optional, defaults to 7.5) — Guidance scale as defined in Classifier-Free Diffusion Guidance.guidance_scaleis defined aswof equation 2. of Imagen Paper. Guidance scale is enabled by settingguidance_scale > 1. Higher guidance scale encourages to generate images that are closely linked to the textprompt, usually at the expense of lower image quality. -
negative_prompt (
strorList[str], optional) — The prompt or prompts not to guide the image generation. If not defined, one has to passnegative_prompt_embedsinstead. Ignored when not using guidance (i.e., ignored ifguidance_scaleis less than1). -
num_images_per_prompt (
int, optional, defaults to 1) — The number of images to generate per prompt. -
eta (
float, optional, defaults to 0.0) — Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to schedulers.DDIMScheduler, will be ignored for others. -
generator (
torch.GeneratororList[torch.Generator], optional) — One or a list of torch generator(s) to make generation deterministic. -
latents (
torch.FloatTensor, optional) — Pre-generated noisy latents, sampled from a Gaussian distribution, to be used as inputs for image generation. Can be used to tweak the same generation with different prompts. If not provided, a latents tensor will ge generated by sampling using the supplied randomgenerator. -
prompt_embeds (
torch.FloatTensor, optional) — Pre-generated text embeddings. Can be used to easily tweak text inputs, e.g. prompt weighting. If not provided, text embeddings will be generated frompromptinput argument. -
negative_prompt_embeds (
torch.FloatTensor, optional) — Pre-generated negative text embeddings. Can be used to easily tweak text inputs, e.g. prompt weighting. If not provided, negative_prompt_embeds will be generated fromnegative_promptinput argument. -
output_type (
str, optional, defaults to"pil") — The output format of the generate image. Choose between PIL:PIL.Image.Imageornp.array. -
return_dict (
bool, optional, defaults toTrue) — Whether or not to return a StableDiffusionPipelineOutput instead of a plain tuple. -
callback (
Callable, optional) — A function that will be called everycallback_stepssteps during inference. The function will be called with the following arguments:callback(step: int, timestep: int, latents: torch.FloatTensor). -
callback_steps (
int, optional, defaults to 1) — The frequency at which thecallbackfunction will be called. If not specified, the callback will be called at every step. -
cross_attention_kwargs (
dict, optional) — A kwargs dictionary that if specified is passed along to theAttentionProcessoras defined underself.processorin diffusers.cross_attention. -
controlnet_conditioning_scale (
floatorList[float], optional, defaults to 0.5) — The outputs of the controlnet are multiplied bycontrolnet_conditioning_scalebefore they are added to the residual in the original unet. If multiple ControlNets are specified in init, you can set the corresponding scale as a list. Note that by default, we use a smaller conditioning scale for inpainting than for call(). -
guess_mode (
bool, optional, defaults toFalse) — In this mode, the ControlNet encoder will try best to recognize the content of the input image even if you remove all prompts. Theguidance_scalebetween 3.0 and 5.0 is recommended.
Returns
StableDiffusionPipelineOutput or tuple
StableDiffusionPipelineOutput if return_dict is True, otherwise a tuple. When returning a tuple, the first element is a list with the generated images, and the second element is a list of bools denoting whether the corresponding generated image likely represents "not-safe-for-work" (nsfw) content, according to the safety_checker`.
Function invoked when calling the pipeline for generation.
Examples:
>>> # !pip install transformers accelerate
>>> from diffusers import StableDiffusionControlNetInpaintPipeline, ControlNetModel, DDIMScheduler
>>> from diffusers.utils import load_image
>>> import numpy as np
>>> import torch
>>> init_image = load_image(
... "https://huggingface.co/datasets/diffusers/test-arrays/resolve/main/stable_diffusion_inpaint/boy.png"
... )
>>> init_image = init_image.resize((512, 512))
>>> generator = torch.Generator(device="cpu").manual_seed(1)
>>> mask_image = load_image(
... "https://huggingface.co/datasets/diffusers/test-arrays/resolve/main/stable_diffusion_inpaint/boy_mask.png"
... )
>>> mask_image = mask_image.resize((512, 512))
>>> def make_inpaint_condition(image, image_mask):
... image = np.array(image.convert("RGB")).astype(np.float32) / 255.0
... image_mask = np.array(image_mask.convert("L")).astype(np.float32) / 255.0
... assert image.shape[0:1] == image_mask.shape[0:1], "image and image_mask must have the same image size"
... image[image_mask > 0.5] = -1.0 # set as masked pixel
... image = np.expand_dims(image, 0).transpose(0, 3, 1, 2)
... image = torch.from_numpy(image)
... return image
>>> control_image = make_inpaint_condition(init_image, mask_image)
>>> controlnet = ControlNetModel.from_pretrained(
... "lllyasviel/control_v11p_sd15_inpaint", torch_dtype=torch.float16
... )
>>> pipe = StableDiffusionControlNetInpaintPipeline.from_pretrained(
... "runwayml/stable-diffusion-v1-5", controlnet=controlnet, torch_dtype=torch.float16
... )
>>> pipe.scheduler = DDIMScheduler.from_config(pipe.scheduler.config)
>>> pipe.enable_model_cpu_offload()
>>> # generate image
>>> image = pipe(
... "a handsome man with ray-ban sunglasses",
... num_inference_steps=20,
... generator=generator,
... eta=1.0,
... image=init_image,
... mask_image=mask_image,
... control_image=control_image,
... ).images[0]enable_attention_slicing
< source >( slice_size: typing.Union[str, int, NoneType] = 'auto' )
Parameters
-
slice_size (
strorint, optional, defaults to"auto") — When"auto", halves the input to the attention heads, so attention will be computed in two steps. If"max", maximum amount of memory will be saved by running only one slice at a time. If a number is provided, uses as many slices asattention_head_dim // slice_size. In this case,attention_head_dimmust be a multiple ofslice_size.
Enable sliced attention computation.
When this option is enabled, the attention module will split the input tensor in slices, to compute attention in several steps. This is useful to save some memory in exchange for a small speed decrease.
Disable sliced attention computation. If enable_attention_slicing was previously invoked, this method will go
back to computing attention in one step.
Enable sliced VAE decoding.
When this option is enabled, the VAE will split the input tensor in slices to compute decoding in several steps. This is useful to save some memory and allow larger batch sizes.
Disable sliced VAE decoding. If enable_vae_slicing was previously invoked, this method will go back to
computing decoding in one step.
enable_xformers_memory_efficient_attention
< source >( attention_op: typing.Optional[typing.Callable] = None )
Parameters
-
attention_op (
Callable, optional) — Override the defaultNoneoperator for use asopargument to thememory_efficient_attention()function of xFormers.
Enable memory efficient attention as implemented in xformers.
When this option is enabled, you should observe lower GPU memory usage and a potential speed up at inference time. Speed up at training time is not guaranteed.
Warning: When Memory Efficient Attention and Sliced attention are both enabled, the Memory Efficient Attention is used.
Examples:
>>> import torch
>>> from diffusers import DiffusionPipeline
>>> from xformers.ops import MemoryEfficientAttentionFlashAttentionOp
>>> pipe = DiffusionPipeline.from_pretrained("stabilityai/stable-diffusion-2-1", torch_dtype=torch.float16)
>>> pipe = pipe.to("cuda")
>>> pipe.enable_xformers_memory_efficient_attention(attention_op=MemoryEfficientAttentionFlashAttentionOp)
>>> # Workaround for not accepting attention shape using VAE for Flash Attention
>>> pipe.vae.enable_xformers_memory_efficient_attention(attention_op=None)Disable memory efficient attention as implemented in xformers.
load_textual_inversion
< source >( pretrained_model_name_or_path: typing.Union[str, typing.List[str], typing.Dict[str, torch.Tensor], typing.List[typing.Dict[str, torch.Tensor]]] token: typing.Union[str, typing.List[str], NoneType] = None **kwargs )
Parameters
-
pretrained_model_name_or_path (
stroros.PathLikeorList[str or os.PathLike]orDictorList[Dict]) — Can be either:- A string, the model id of a pretrained model hosted inside a model repo on huggingface.co.
Valid model ids should have an organization name, like
"sd-concepts-library/low-poly-hd-logos-icons". - A path to a directory containing textual inversion weights, e.g.
./my_text_inversion_directory/. - A path to a file containing textual inversion weights, e.g.
./my_text_inversions.pt. - A torch state dict.
Or a list of those elements.
- A string, the model id of a pretrained model hosted inside a model repo on huggingface.co.
Valid model ids should have an organization name, like
-
token (
strorList[str], optional) — Override the token to use for the textual inversion weights. Ifpretrained_model_name_or_pathis a list, thentokenmust also be a list of equal length. -
weight_name (
str, optional) — Name of a custom weight file. This should be used in two cases:- The saved textual inversion file is in
diffusersformat, but was saved under a specific weight name, such astext_inv.bin. - The saved textual inversion file is in the “Automatic1111” form.
- The saved textual inversion file is in
-
cache_dir (
Union[str, os.PathLike], optional) — Path to a directory in which a downloaded pretrained model configuration should be cached if the standard cache should not be used. -
force_download (
bool, optional, defaults toFalse) — Whether or not to force the (re-)download of the model weights and configuration files, overriding the cached versions if they exist. -
resume_download (
bool, optional, defaults toFalse) — Whether or not to delete incompletely received files. Will attempt to resume the download if such a file exists. -
proxies (
Dict[str, str], optional) — A dictionary of proxy servers to use by protocol or endpoint, e.g.,{'http': 'foo.bar:3128', 'http://hostname': 'foo.bar:4012'}. The proxies are used on each request. -
local_files_only(
bool, optional, defaults toFalse) — Whether or not to only look at local files (i.e., do not try to download the model). -
use_auth_token (
stror bool, optional) — The token to use as HTTP bearer authorization for remote files. IfTrue, will use the token generated when runningdiffusers-cli login(stored in~/.huggingface). -
revision (
str, optional, defaults to"main") — The specific model version to use. It can be a branch name, a tag name, or a commit id, since we use a git-based system for storing models and other artifacts on huggingface.co, sorevisioncan be any identifier allowed by git. -
subfolder (
str, optional, defaults to"") — In case the relevant files are located inside a subfolder of the model repo (either remote in huggingface.co or downloaded locally), you can specify the folder name here. -
mirror (
str, optional) — Mirror source to accelerate downloads in China. If you are from China and have an accessibility problem, you can set this option to resolve it. Note that we do not guarantee the timeliness or safety. Please refer to the mirror site for more information.
Load textual inversion embeddings into the text encoder of stable diffusion pipelines. Both diffusers and
Automatic1111 formats are supported (see example below).
This function is experimental and might change in the future.
It is required to be logged in (huggingface-cli login) when you want to use private or gated
models.
Example:
To load a textual inversion embedding vector in diffusers format:
from diffusers import StableDiffusionPipeline
import torch
model_id = "runwayml/stable-diffusion-v1-5"
pipe = StableDiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16).to("cuda")
pipe.load_textual_inversion("sd-concepts-library/cat-toy")
prompt = "A <cat-toy> backpack"
image = pipe(prompt, num_inference_steps=50).images[0]
image.save("cat-backpack.png")To load a textual inversion embedding vector in Automatic1111 format, make sure to first download the vector,
e.g. from civitAI and then load the vector locally:
from diffusers import StableDiffusionPipeline
import torch
model_id = "runwayml/stable-diffusion-v1-5"
pipe = StableDiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16).to("cuda")
pipe.load_textual_inversion("./charturnerv2.pt", token="charturnerv2")
prompt = "charturnerv2, multiple views of the same character in the same outfit, a character turnaround of a woman wearing a black jacket and red shirt, best quality, intricate details."
image = pipe(prompt, num_inference_steps=50).images[0]
image.save("character.png")Disable tiled VAE decoding. If enable_vae_tiling was previously invoked, this method will go back to
computing decoding in one step.
Offloads all models to CPU using accelerate, reducing memory usage with a low impact on performance. Compared
to enable_sequential_cpu_offload, this method moves one whole model at a time to the GPU when its forward
method is called, and the model remains in GPU until the next model runs. Memory savings are lower than with
enable_sequential_cpu_offload, but performance is much better due to the iterative execution of the unet.
Offloads all models to CPU using accelerate, significantly reducing memory usage. When called, unet,
text_encoder, vae, controlnet, and safety checker have their state dicts saved to CPU and then are moved to a
torch.device('meta') and loaded to GPU only when their specific submodule has its forwardmethod called. Note that offloading happens on a submodule basis. Memory savings are higher than withenable_model_cpu_offload`, but performance is lower.
Enable tiled VAE decoding.
When this option is enabled, the VAE will split the input tensor into tiles to compute decoding and encoding in several steps. This is useful to save a large amount of memory and to allow the processing of larger images.
FlaxStableDiffusionControlNetPipeline
class diffusers.FlaxStableDiffusionControlNetPipeline
< source >( vae: FlaxAutoencoderKL text_encoder: FlaxCLIPTextModel tokenizer: CLIPTokenizer unet: FlaxUNet2DConditionModel controlnet: FlaxControlNetModel scheduler: typing.Union[diffusers.schedulers.scheduling_ddim_flax.FlaxDDIMScheduler, diffusers.schedulers.scheduling_pndm_flax.FlaxPNDMScheduler, diffusers.schedulers.scheduling_lms_discrete_flax.FlaxLMSDiscreteScheduler, diffusers.schedulers.scheduling_dpmsolver_multistep_flax.FlaxDPMSolverMultistepScheduler] safety_checker: FlaxStableDiffusionSafetyChecker feature_extractor: CLIPFeatureExtractor dtype: dtype = <class 'jax.numpy.float32'> )
Parameters
- vae (FlaxAutoencoderKL) — Variational Auto-Encoder (VAE) Model to encode and decode images to and from latent representations.
-
text_encoder (
FlaxCLIPTextModel) — Frozen text-encoder. Stable Diffusion uses the text portion of CLIP, specifically the clip-vit-large-patch14 variant. -
tokenizer (
CLIPTokenizer) — Tokenizer of class CLIPTokenizer. - unet (FlaxUNet2DConditionModel) — Conditional U-Net architecture to denoise the encoded image latents.
- controlnet (FlaxControlNetModel — Provides additional conditioning to the unet during the denoising process.
-
scheduler (SchedulerMixin) —
A scheduler to be used in combination with
unetto denoise the encoded image latents. Can be one ofFlaxDDIMScheduler,FlaxLMSDiscreteScheduler,FlaxPNDMScheduler, orFlaxDPMSolverMultistepScheduler. -
safety_checker (
FlaxStableDiffusionSafetyChecker) — Classification module that estimates whether generated images could be considered offensive or harmful. Please, refer to the model card for details. -
feature_extractor (
CLIPFeatureExtractor) — Model that extracts features from generated images to be used as inputs for thesafety_checker.
Pipeline for text-to-image generation using Stable Diffusion with ControlNet Guidance.
This model inherits from FlaxDiffusionPipeline. Check the superclass documentation for the generic methods the
library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
__call__
< source >(
prompt_ids: array
image: array
params: typing.Union[typing.Dict, flax.core.frozen_dict.FrozenDict]
prng_seed: PRNGKeyArray
num_inference_steps: int = 50
guidance_scale: typing.Union[float, array] = 7.5
latents: array = None
neg_prompt_ids: array = None
controlnet_conditioning_scale: typing.Union[float, array] = 1.0
return_dict: bool = True
jit: bool = False
)
→
FlaxStableDiffusionPipelineOutput or tuple
Parameters
-
prompt_ids (
jnp.array) — The prompt or prompts to guide the image generation. -
image (
jnp.array) — Array representing the ControlNet input condition. ControlNet use this input condition to generate guidance to Unet. -
params (
DictorFrozenDict) — Dictionary containing the model parameters/weights -
prng_seed (
jax.random.KeyArrayorjax.Array) — Array containing random number generator key -
num_inference_steps (
int, optional, defaults to 50) — The number of denoising steps. More denoising steps usually lead to a higher quality image at the expense of slower inference. -
guidance_scale (
float, optional, defaults to 7.5) — Guidance scale as defined in Classifier-Free Diffusion Guidance.guidance_scaleis defined aswof equation 2. of Imagen Paper. Guidance scale is enabled by settingguidance_scale > 1. Higher guidance scale encourages to generate images that are closely linked to the textprompt, usually at the expense of lower image quality. -
latents (
jnp.array, optional) — Pre-generated noisy latents, sampled from a Gaussian distribution, to be used as inputs for image generation. Can be used to tweak the same generation with different prompts. If not provided, a latents tensor will ge generated by sampling using the supplied randomgenerator. -
controlnet_conditioning_scale (
floatorjnp.array, optional, defaults to 1.0) — The outputs of the controlnet are multiplied bycontrolnet_conditioning_scalebefore they are added to the residual in the original unet. -
return_dict (
bool, optional, defaults toTrue) — Whether or not to return aFlaxStableDiffusionPipelineOutputinstead of a plain tuple. -
jit (
bool, defaults toFalse) — Whether to runpmapversions of the generation and safety scoring functions. NOTE: This argument exists because__call__is not yet end-to-end pmap-able. It will be removed in a future release.
Returns
FlaxStableDiffusionPipelineOutput or tuple
FlaxStableDiffusionPipelineOutput if return_dict is True, otherwise a
tuple. When returning a tuple, the first element is a list with the generated images, and the second element is a list of bools denoting whether the corresponding generated image likely represents "not-safe-for-work" (nsfw) content, according to the safety_checker`.
Function invoked when calling the pipeline for generation.
Examples:
>>> import jax
>>> import numpy as np
>>> import jax.numpy as jnp
>>> from flax.jax_utils import replicate
>>> from flax.training.common_utils import shard
>>> from diffusers.utils import load_image
>>> from PIL import Image
>>> from diffusers import FlaxStableDiffusionControlNetPipeline, FlaxControlNetModel
>>> def image_grid(imgs, rows, cols):
... w, h = imgs[0].size
... grid = Image.new("RGB", size=(cols * w, rows * h))
... for i, img in enumerate(imgs):
... grid.paste(img, box=(i % cols * w, i // cols * h))
... return grid
>>> def create_key(seed=0):
... return jax.random.PRNGKey(seed)
>>> rng = create_key(0)
>>> # get canny image
>>> canny_image = load_image(
... "https://huggingface.co/datasets/YiYiXu/test-doc-assets/resolve/main/blog_post_cell_10_output_0.jpeg"
... )
>>> prompts = "best quality, extremely detailed"
>>> negative_prompts = "monochrome, lowres, bad anatomy, worst quality, low quality"
>>> # load control net and stable diffusion v1-5
>>> controlnet, controlnet_params = FlaxControlNetModel.from_pretrained(
... "lllyasviel/sd-controlnet-canny", from_pt=True, dtype=jnp.float32
... )
>>> pipe, params = FlaxStableDiffusionControlNetPipeline.from_pretrained(
... "runwayml/stable-diffusion-v1-5", controlnet=controlnet, revision="flax", dtype=jnp.float32
... )
>>> params["controlnet"] = controlnet_params
>>> num_samples = jax.device_count()
>>> rng = jax.random.split(rng, jax.device_count())
>>> prompt_ids = pipe.prepare_text_inputs([prompts] * num_samples)
>>> negative_prompt_ids = pipe.prepare_text_inputs([negative_prompts] * num_samples)
>>> processed_image = pipe.prepare_image_inputs([canny_image] * num_samples)
>>> p_params = replicate(params)
>>> prompt_ids = shard(prompt_ids)
>>> negative_prompt_ids = shard(negative_prompt_ids)
>>> processed_image = shard(processed_image)
>>> output = pipe(
... prompt_ids=prompt_ids,
... image=processed_image,
... params=p_params,
... prng_seed=rng,
... num_inference_steps=50,
... neg_prompt_ids=negative_prompt_ids,
... jit=True,
... ).images
>>> output_images = pipe.numpy_to_pil(np.asarray(output.reshape((num_samples,) + output.shape[-3:])))
>>> output_images = image_grid(output_images, num_samples // 4, 4)
>>> output_images.save("generated_image.png")