Diffusers documentation
Kandinsky
Kandinsky
Overview
Kandinsky 2.1 inherits best practices from DALL-E 2 and Latent Diffusion, while introducing some new ideas.
It uses CLIP for encoding images and text, and a diffusion image prior (mapping) between latent spaces of CLIP modalities. This approach enhances the visual performance of the model and unveils new horizons in blending images and text-guided image manipulation.
The Kandinsky model is created by Arseniy Shakhmatov, Anton Razzhigaev, Aleksandr Nikolich, Igor Pavlov, Andrey Kuznetsov and Denis Dimitrov and the original codebase can be found here
Available Pipelines:
| Pipeline | Tasks |
|---|---|
| pipeline_kandinsky.py | Text-to-Image Generation |
| pipeline_kandinsky_inpaint.py | Image-Guided Image Generation |
| pipeline_kandinsky_img2img.py | Image-Guided Image Generation |
Usage example
In the following, we will walk you through some examples of how to use the Kandinsky pipelines to create some visually aesthetic artwork.
Text-to-Image Generation
For text-to-image generation, we need to use both KandinskyPriorPipeline and KandinskyPipeline. The first step is to encode text prompts with CLIP and then diffuse the CLIP text embeddings to CLIP image embeddings, as first proposed in DALL-E 2. Let’s throw a fun prompt at Kandinsky to see what it comes up with.
prompt = "A alien cheeseburger creature eating itself, claymation, cinematic, moody lighting"First, let’s instantiate the prior pipeline and the text-to-image pipeline. Both pipelines are diffusion models.
from diffusers import DiffusionPipeline
import torch
pipe_prior = DiffusionPipeline.from_pretrained("kandinsky-community/kandinsky-2-1-prior", torch_dtype=torch.float16)
pipe_prior.to("cuda")
t2i_pipe = DiffusionPipeline.from_pretrained("kandinsky-community/kandinsky-2-1", torch_dtype=torch.float16)
t2i_pipe.to("cuda")Now we pass the prompt through the prior to generate image embeddings. The prior returns both the image embeddings corresponding to the prompt and negative/unconditional image embeddings corresponding to an empty string.
generator = torch.Generator(device="cuda").manual_seed(12)
image_embeds, negative_image_embeds = pipe_prior(prompt, generator=generator).to_tuple()The text-to-image pipeline expects both image_embeds, negative_image_embeds and the original
prompt as the text-to-image pipeline uses another text encoder to better guide the second diffusion
process of t2i_pipe.
By default, the prior returns unconditioned negative image embeddings corresponding to the negative prompt of "".
For better results, you can also pass a negative_prompt to the prior. This will increase the effective batch size
of the prior by a factor of 2.
prompt = "A alien cheeseburger creature eating itself, claymation, cinematic, moody lighting"
negative_prompt = "low quality, bad quality"
image_embeds, negative_image_embeds = pipe_prior(prompt, negative_prompt, generator=generator).to_tuple()Next, we can pass the embeddings as well as the prompt to the text-to-image pipeline. Remember that
in case you are using a customized negative prompt, that you should pass this one also to the text-to-image pipelines
with negative_prompt=negative_prompt:
image = t2i_pipe(prompt, image_embeds=image_embeds, negative_image_embeds=negative_image_embeds).images[0]
image.save("cheeseburger_monster.png")One cheeseburger monster coming up! Enjoy!

The Kandinsky model works extremely well with creative prompts. Here is some of the amazing art that can be created using the exact same process but with different prompts.
prompt = "bird eye view shot of a full body woman with cyan light orange magenta makeup, digital art, long braided hair her face separated by makeup in the style of yin Yang surrealism, symmetrical face, real image, contrasting tone, pastel gradient background"
prompt = "A car exploding into colorful dust"
prompt = "editorial photography of an organic, almost liquid smoke style armchair"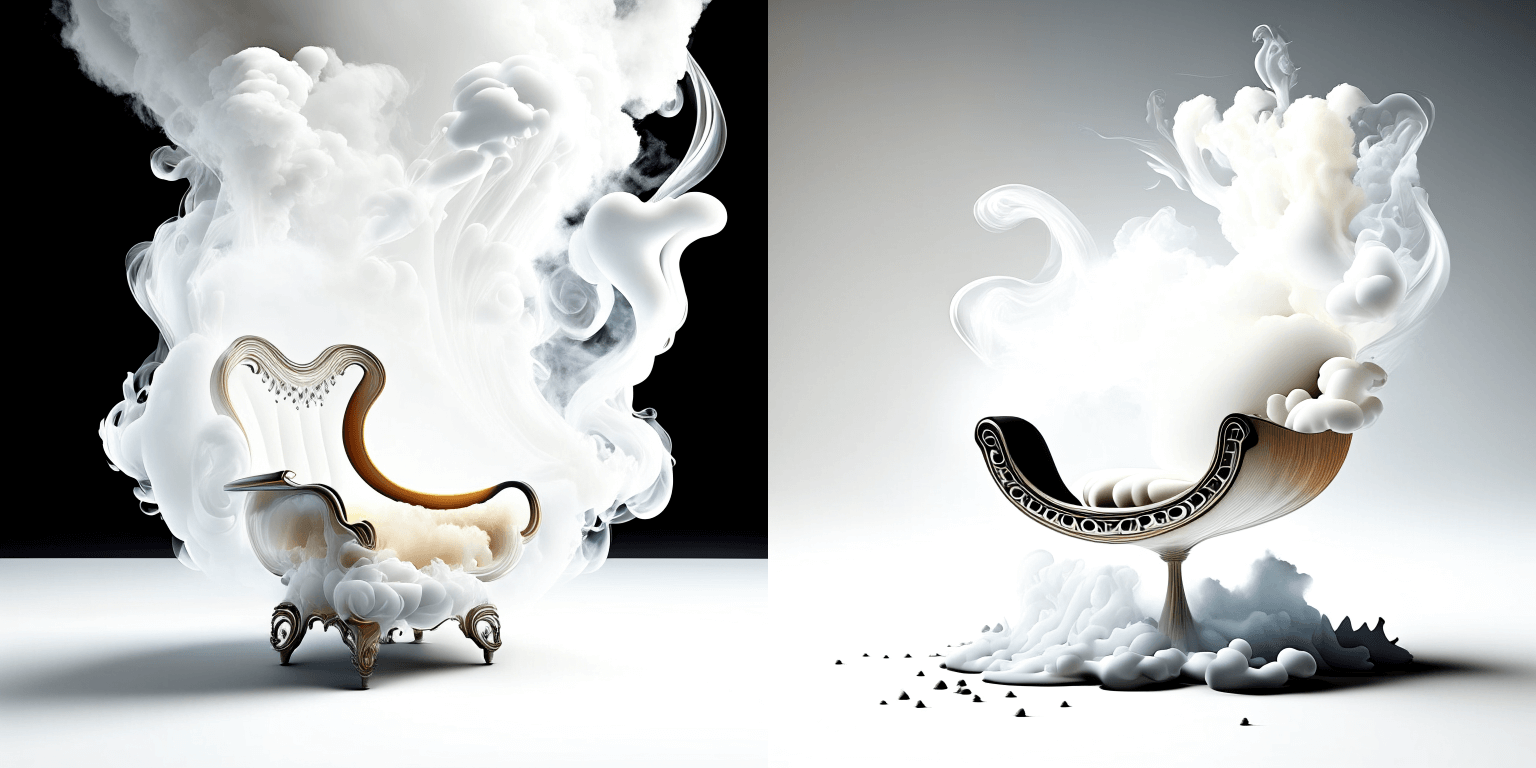
prompt = "birds eye view of a quilted paper style alien planet landscape, vibrant colours, Cinematic lighting"
Text Guided Image-to-Image Generation
The same Kandinsky model weights can be used for text-guided image-to-image translation. In this case, just make sure to load the weights using the KandinskyImg2ImgPipeline pipeline.
Note: You can also directly move the weights of the text-to-image pipelines to the image-to-image pipelines without loading them twice by making use of the components function as explained here.
Let’s download an image.
from PIL import Image
import requests
from io import BytesIO
# download image
url = "https://raw.githubusercontent.com/CompVis/stable-diffusion/main/assets/stable-samples/img2img/sketch-mountains-input.jpg"
response = requests.get(url)
original_image = Image.open(BytesIO(response.content)).convert("RGB")
original_image = original_image.resize((768, 512))
import torch
from diffusers import KandinskyImg2ImgPipeline, KandinskyPriorPipeline
# create prior
pipe_prior = KandinskyPriorPipeline.from_pretrained(
"kandinsky-community/kandinsky-2-1-prior", torch_dtype=torch.float16
)
pipe_prior.to("cuda")
# create img2img pipeline
pipe = KandinskyImg2ImgPipeline.from_pretrained("kandinsky-community/kandinsky-2-1", torch_dtype=torch.float16)
pipe.to("cuda")
prompt = "A fantasy landscape, Cinematic lighting"
negative_prompt = "low quality, bad quality"
generator = torch.Generator(device="cuda").manual_seed(30)
image_embeds, negative_image_embeds = pipe_prior(prompt, negative_prompt, generator=generator).to_tuple()
out = pipe(
prompt,
image=original_image,
image_embeds=image_embeds,
negative_image_embeds=negative_image_embeds,
height=768,
width=768,
strength=0.3,
)
out.images[0].save("fantasy_land.png")
Text Guided Inpainting Generation
You can use KandinskyInpaintPipeline to edit images. In this example, we will add a hat to the portrait of a cat.
from diffusers import KandinskyInpaintPipeline, KandinskyPriorPipeline
from diffusers.utils import load_image
import torch
import numpy as np
pipe_prior = KandinskyPriorPipeline.from_pretrained(
"kandinsky-community/kandinsky-2-1-prior", torch_dtype=torch.float16
)
pipe_prior.to("cuda")
prompt = "a hat"
prior_output = pipe_prior(prompt)
pipe = KandinskyInpaintPipeline.from_pretrained("kandinsky-community/kandinsky-2-1-inpaint", torch_dtype=torch.float16)
pipe.to("cuda")
init_image = load_image(
"https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main" "/kandinsky/cat.png"
)
mask = np.ones((768, 768), dtype=np.float32)
# Let's mask out an area above the cat's head
mask[:250, 250:-250] = 0
out = pipe(
prompt,
image=init_image,
mask_image=mask,
**prior_output,
height=768,
width=768,
num_inference_steps=150,
)
image = out.images[0]
image.save("cat_with_hat.png")
Interpolate
The KandinskyPriorPipeline also comes with a cool utility function that will allow you to interpolate the latent space of different images and texts super easily. Here is an example of how you can create an Impressionist-style portrait for your pet based on “The Starry Night”.
Note that you can interpolate between texts and images - in the below example, we passed a text prompt “a cat” and two images to the interplate function, along with a weights variable containing the corresponding weights for each condition we interplate.
from diffusers import KandinskyPriorPipeline, KandinskyPipeline
from diffusers.utils import load_image
import PIL
import torch
pipe_prior = KandinskyPriorPipeline.from_pretrained(
"kandinsky-community/kandinsky-2-1-prior", torch_dtype=torch.float16
)
pipe_prior.to("cuda")
img1 = load_image(
"https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main" "/kandinsky/cat.png"
)
img2 = load_image(
"https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main" "/kandinsky/starry_night.jpeg"
)
# add all the conditions we want to interpolate, can be either text or image
images_texts = ["a cat", img1, img2]
# specify the weights for each condition in images_texts
weights = [0.3, 0.3, 0.4]
# We can leave the prompt empty
prompt = ""
prior_out = pipe_prior.interpolate(images_texts, weights)
pipe = KandinskyPipeline.from_pretrained("kandinsky-community/kandinsky-2-1", torch_dtype=torch.float16)
pipe.to("cuda")
image = pipe(prompt, **prior_out, height=768, width=768).images[0]
image.save("starry_cat.png")
Optimization
Running Kandinsky in inference requires running both a first prior pipeline: KandinskyPriorPipeline and a second image decoding pipeline which is one of KandinskyPipeline, KandinskyImg2ImgPipeline, or KandinskyInpaintPipeline.
The bulk of the computation time will always be the second image decoding pipeline, so when looking into optimizing the model, one should look into the second image decoding pipeline.
When running with PyTorch < 2.0, we strongly recommend making use of xformers
to speed-up the optimization. This can be done by simply running:
from diffusers import DiffusionPipeline
import torch
t2i_pipe = DiffusionPipeline.from_pretrained("kandinsky-community/kandinsky-2-1", torch_dtype=torch.float16)
t2i_pipe.enable_xformers_memory_efficient_attention()When running on PyTorch >= 2.0, PyTorch’s SDPA attention will automatically be used. For more information on PyTorch’s SDPA, feel free to have a look at this blog post.
To have explicit control , you can also manually set the pipeline to use PyTorch’s 2.0 efficient attention:
from diffusers.models.attention_processor import AttnAddedKVProcessor2_0
t2i_pipe.unet.set_attn_processor(AttnAddedKVProcessor2_0())The slowest and most memory intense attention processor is the default AttnAddedKVProcessor processor.
We do not recommend using it except for testing purposes or cases where very high determistic behaviour is desired.
You can set it with:
from diffusers.models.attention_processor import AttnAddedKVProcessor
t2i_pipe.unet.set_attn_processor(AttnAddedKVProcessor())With PyTorch >= 2.0, you can also use Kandinsky with torch.compile which depending
on your hardware can signficantly speed-up your inference time once the model is compiled.
To use Kandinsksy with torch.compile, you can do:
t2i_pipe.unet.to(memory_format=torch.channels_last)
t2i_pipe.unet = torch.compile(t2i_pipe.unet, mode="reduce-overhead", fullgraph=True)After compilation you should see a very fast inference time. For more information, feel free to have a look at Our PyTorch 2.0 benchmark.
KandinskyPriorPipeline
class diffusers.KandinskyPriorPipeline
< source >( prior: PriorTransformer image_encoder: CLIPVisionModelWithProjection text_encoder: CLIPTextModelWithProjection tokenizer: CLIPTokenizer scheduler: UnCLIPScheduler image_processor: CLIPImageProcessor )
Parameters
- prior (PriorTransformer) — The canonincal unCLIP prior to approximate the image embedding from the text embedding.
-
image_encoder (
CLIPVisionModelWithProjection) — Frozen image-encoder. -
text_encoder (
CLIPTextModelWithProjection) — Frozen text-encoder. -
tokenizer (
CLIPTokenizer) — Tokenizer of class CLIPTokenizer. -
scheduler (
UnCLIPScheduler) — A scheduler to be used in combination withpriorto generate image embedding.
Pipeline for generating image prior for Kandinsky
This model inherits from DiffusionPipeline. Check the superclass documentation for the generic methods the library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
__call__
< source >(
prompt: typing.Union[str, typing.List[str]]
negative_prompt: typing.Union[str, typing.List[str], NoneType] = None
num_images_per_prompt: int = 1
num_inference_steps: int = 25
generator: typing.Union[torch._C.Generator, typing.List[torch._C.Generator], NoneType] = None
latents: typing.Optional[torch.FloatTensor] = None
guidance_scale: float = 4.0
output_type: typing.Optional[str] = 'pt'
return_dict: bool = True
)
→
KandinskyPriorPipelineOutput or tuple
Parameters
-
prompt (
strorList[str]) — The prompt or prompts to guide the image generation. -
negative_prompt (
strorList[str], optional) — The prompt or prompts not to guide the image generation. Ignored when not using guidance (i.e., ignored ifguidance_scaleis less than1). -
num_images_per_prompt (
int, optional, defaults to 1) — The number of images to generate per prompt. -
num_inference_steps (
int, optional, defaults to 100) — The number of denoising steps. More denoising steps usually lead to a higher quality image at the expense of slower inference. -
generator (
torch.GeneratororList[torch.Generator], optional) — One or a list of torch generator(s) to make generation deterministic. -
latents (
torch.FloatTensor, optional) — Pre-generated noisy latents, sampled from a Gaussian distribution, to be used as inputs for image generation. Can be used to tweak the same generation with different prompts. If not provided, a latents tensor will ge generated by sampling using the supplied randomgenerator. -
guidance_scale (
float, optional, defaults to 4.0) — Guidance scale as defined in Classifier-Free Diffusion Guidance.guidance_scaleis defined aswof equation 2. of Imagen Paper. Guidance scale is enabled by settingguidance_scale > 1. Higher guidance scale encourages to generate images that are closely linked to the textprompt, usually at the expense of lower image quality. -
output_type (
str, optional, defaults to"pt") — The output format of the generate image. Choose between:"np"(np.array) or"pt"(torch.Tensor). -
return_dict (
bool, optional, defaults toTrue) — Whether or not to return a ImagePipelineOutput instead of a plain tuple.
Returns
KandinskyPriorPipelineOutput or tuple
Function invoked when calling the pipeline for generation.
Examples:
>>> from diffusers import KandinskyPipeline, KandinskyPriorPipeline
>>> import torch
>>> pipe_prior = KandinskyPriorPipeline.from_pretrained("kandinsky-community/kandinsky-2-1-prior")
>>> pipe_prior.to("cuda")
>>> prompt = "red cat, 4k photo"
>>> out = pipe_prior(prompt)
>>> image_emb = out.image_embeds
>>> negative_image_emb = out.negative_image_embeds
>>> pipe = KandinskyPipeline.from_pretrained("kandinsky-community/kandinsky-2-1")
>>> pipe.to("cuda")
>>> image = pipe(
... prompt,
... image_embeds=image_emb,
... negative_image_embeds=negative_image_emb,
... height=768,
... width=768,
... num_inference_steps=100,
... ).images
>>> image[0].save("cat.png")interpolate
< source >(
images_and_prompts: typing.List[typing.Union[str, PIL.Image.Image, torch.FloatTensor]]
weights: typing.List[float]
num_images_per_prompt: int = 1
num_inference_steps: int = 25
generator: typing.Union[torch._C.Generator, typing.List[torch._C.Generator], NoneType] = None
latents: typing.Optional[torch.FloatTensor] = None
negative_prior_prompt: typing.Optional[str] = None
negative_prompt: str = ''
guidance_scale: float = 4.0
device = None
)
→
KandinskyPriorPipelineOutput or tuple
Parameters
-
images_and_prompts (
List[Union[str, PIL.Image.Image, torch.FloatTensor]]) — list of prompts and images to guide the image generation. weights — (List[float]): list of weights for each condition inimages_and_prompts -
num_images_per_prompt (
int, optional, defaults to 1) — The number of images to generate per prompt. -
num_inference_steps (
int, optional, defaults to 100) — The number of denoising steps. More denoising steps usually lead to a higher quality image at the expense of slower inference. -
generator (
torch.GeneratororList[torch.Generator], optional) — One or a list of torch generator(s) to make generation deterministic. -
latents (
torch.FloatTensor, optional) — Pre-generated noisy latents, sampled from a Gaussian distribution, to be used as inputs for image generation. Can be used to tweak the same generation with different prompts. If not provided, a latents tensor will ge generated by sampling using the supplied randomgenerator. -
negative_prior_prompt (
str, optional) — The prompt not to guide the prior diffusion process. Ignored when not using guidance (i.e., ignored ifguidance_scaleis less than1). -
negative_prompt (
strorList[str], optional) — The prompt not to guide the image generation. Ignored when not using guidance (i.e., ignored ifguidance_scaleis less than1). -
guidance_scale (
float, optional, defaults to 4.0) — Guidance scale as defined in Classifier-Free Diffusion Guidance.guidance_scaleis defined aswof equation 2. of Imagen Paper. Guidance scale is enabled by settingguidance_scale > 1. Higher guidance scale encourages to generate images that are closely linked to the textprompt, usually at the expense of lower image quality.
Returns
KandinskyPriorPipelineOutput or tuple
Function invoked when using the prior pipeline for interpolation.
Examples:
>>> from diffusers import KandinskyPriorPipeline, KandinskyPipeline
>>> from diffusers.utils import load_image
>>> import PIL
>>> import torch
>>> from torchvision import transforms
>>> pipe_prior = KandinskyPriorPipeline.from_pretrained(
... "kandinsky-community/kandinsky-2-1-prior", torch_dtype=torch.float16
... )
>>> pipe_prior.to("cuda")
>>> img1 = load_image(
... "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main"
... "/kandinsky/cat.png"
... )
>>> img2 = load_image(
... "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main"
... "/kandinsky/starry_night.jpeg"
... )
>>> images_texts = ["a cat", img1, img2]
>>> weights = [0.3, 0.3, 0.4]
>>> image_emb, zero_image_emb = pipe_prior.interpolate(images_texts, weights)
>>> pipe = KandinskyPipeline.from_pretrained("kandinsky-community/kandinsky-2-1", torch_dtype=torch.float16)
>>> pipe.to("cuda")
>>> image = pipe(
... "",
... image_embeds=image_emb,
... negative_image_embeds=zero_image_emb,
... height=768,
... width=768,
... num_inference_steps=150,
... ).images[0]
>>> image.save("starry_cat.png")Offloads all models to CPU using accelerate, significantly reducing memory usage. When called, the pipeline’s
models have their state dicts saved to CPU and then are moved to a torch.device('meta') and loaded to GPU only when their specific submodule has its forward` method called.
KandinskyPipeline
class diffusers.KandinskyPipeline
< source >( text_encoder: MultilingualCLIP tokenizer: XLMRobertaTokenizer unet: UNet2DConditionModel scheduler: DDIMScheduler movq: VQModel )
Parameters
-
text_encoder (
MultilingualCLIP) — Frozen text-encoder. -
tokenizer (
XLMRobertaTokenizer) — Tokenizer of class -
scheduler (DDIMScheduler) —
A scheduler to be used in combination with
unetto generate image latents. - unet (UNet2DConditionModel) — Conditional U-Net architecture to denoise the image embedding.
- movq (VQModel) — MoVQ Decoder to generate the image from the latents.
Pipeline for text-to-image generation using Kandinsky
This model inherits from DiffusionPipeline. Check the superclass documentation for the generic methods the library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
__call__
< source >(
prompt: typing.Union[str, typing.List[str]]
image_embeds: typing.Union[torch.FloatTensor, typing.List[torch.FloatTensor]]
negative_image_embeds: typing.Union[torch.FloatTensor, typing.List[torch.FloatTensor]]
negative_prompt: typing.Union[str, typing.List[str], NoneType] = None
height: int = 512
width: int = 512
num_inference_steps: int = 100
guidance_scale: float = 4.0
num_images_per_prompt: int = 1
generator: typing.Union[torch._C.Generator, typing.List[torch._C.Generator], NoneType] = None
latents: typing.Optional[torch.FloatTensor] = None
output_type: typing.Optional[str] = 'pil'
return_dict: bool = True
)
→
ImagePipelineOutput or tuple
Parameters
-
prompt (
strorList[str]) — The prompt or prompts to guide the image generation. -
image_embeds (
torch.FloatTensororList[torch.FloatTensor]) — The clip image embeddings for text prompt, that will be used to condition the image generation. -
negative_image_embeds (
torch.FloatTensororList[torch.FloatTensor]) — The clip image embeddings for negative text prompt, will be used to condition the image generation. -
negative_prompt (
strorList[str], optional) — The prompt or prompts not to guide the image generation. Ignored when not using guidance (i.e., ignored ifguidance_scaleis less than1). -
height (
int, optional, defaults to 512) — The height in pixels of the generated image. -
width (
int, optional, defaults to 512) — The width in pixels of the generated image. -
num_inference_steps (
int, optional, defaults to 100) — The number of denoising steps. More denoising steps usually lead to a higher quality image at the expense of slower inference. -
guidance_scale (
float, optional, defaults to 4.0) — Guidance scale as defined in Classifier-Free Diffusion Guidance.guidance_scaleis defined aswof equation 2. of Imagen Paper. Guidance scale is enabled by settingguidance_scale > 1. Higher guidance scale encourages to generate images that are closely linked to the textprompt, usually at the expense of lower image quality. -
num_images_per_prompt (
int, optional, defaults to 1) — The number of images to generate per prompt. -
generator (
torch.GeneratororList[torch.Generator], optional) — One or a list of torch generator(s) to make generation deterministic. -
latents (
torch.FloatTensor, optional) — Pre-generated noisy latents, sampled from a Gaussian distribution, to be used as inputs for image generation. Can be used to tweak the same generation with different prompts. If not provided, a latents tensor will ge generated by sampling using the supplied randomgenerator. -
output_type (
str, optional, defaults to"pil") — The output format of the generate image. Choose between:"pil"(PIL.Image.Image),"np"(np.array) or"pt"(torch.Tensor). -
return_dict (
bool, optional, defaults toTrue) — Whether or not to return a ImagePipelineOutput instead of a plain tuple.
Returns
ImagePipelineOutput or tuple
Function invoked when calling the pipeline for generation.
Examples:
>>> from diffusers import KandinskyPipeline, KandinskyPriorPipeline
>>> import torch
>>> pipe_prior = KandinskyPriorPipeline.from_pretrained("kandinsky-community/Kandinsky-2-1-prior")
>>> pipe_prior.to("cuda")
>>> prompt = "red cat, 4k photo"
>>> out = pipe_prior(prompt)
>>> image_emb = out.image_embeds
>>> negative_image_emb = out.negative_image_embeds
>>> pipe = KandinskyPipeline.from_pretrained("kandinsky-community/kandinsky-2-1")
>>> pipe.to("cuda")
>>> image = pipe(
... prompt,
... image_embeds=image_emb,
... negative_image_embeds=negative_image_emb,
... height=768,
... width=768,
... num_inference_steps=100,
... ).images
>>> image[0].save("cat.png")Offloads all models to CPU using accelerate, reducing memory usage with a low impact on performance. Compared
to enable_sequential_cpu_offload, this method moves one whole model at a time to the GPU when its forward
method is called, and the model remains in GPU until the next model runs. Memory savings are lower than with
enable_sequential_cpu_offload, but performance is much better due to the iterative execution of the unet.
Offloads all models to CPU using accelerate, significantly reducing memory usage. When called, the pipeline’s
models have their state dicts saved to CPU and then are moved to a torch.device('meta') and loaded to GPU only when their specific submodule has its forward` method called.
KandinskyImg2ImgPipeline
class diffusers.KandinskyImg2ImgPipeline
< source >( text_encoder: MultilingualCLIP movq: VQModel tokenizer: XLMRobertaTokenizer unet: UNet2DConditionModel scheduler: DDIMScheduler )
Parameters
-
text_encoder (
MultilingualCLIP) — Frozen text-encoder. -
tokenizer (
XLMRobertaTokenizer) — Tokenizer of class -
scheduler (DDIMScheduler) —
A scheduler to be used in combination with
unetto generate image latents. - unet (UNet2DConditionModel) — Conditional U-Net architecture to denoise the image embedding.
- movq (VQModel) — MoVQ image encoder and decoder
Pipeline for image-to-image generation using Kandinsky
This model inherits from DiffusionPipeline. Check the superclass documentation for the generic methods the library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
__call__
< source >(
prompt: typing.Union[str, typing.List[str]]
image: typing.Union[torch.FloatTensor, PIL.Image.Image, typing.List[torch.FloatTensor], typing.List[PIL.Image.Image]]
image_embeds: FloatTensor
negative_image_embeds: FloatTensor
negative_prompt: typing.Union[str, typing.List[str], NoneType] = None
height: int = 512
width: int = 512
num_inference_steps: int = 100
strength: float = 0.3
guidance_scale: float = 7.0
num_images_per_prompt: int = 1
generator: typing.Union[torch._C.Generator, typing.List[torch._C.Generator], NoneType] = None
output_type: typing.Optional[str] = 'pil'
return_dict: bool = True
)
→
ImagePipelineOutput or tuple
Parameters
-
prompt (
strorList[str]) — The prompt or prompts to guide the image generation. -
image (
torch.FloatTensor,PIL.Image.Image) —Image, or tensor representing an image batch, that will be used as the starting point for the process. -
image_embeds (
torch.FloatTensororList[torch.FloatTensor]) — The clip image embeddings for text prompt, that will be used to condition the image generation. -
negative_image_embeds (
torch.FloatTensororList[torch.FloatTensor]) — The clip image embeddings for negative text prompt, will be used to condition the image generation. -
negative_prompt (
strorList[str], optional) — The prompt or prompts not to guide the image generation. Ignored when not using guidance (i.e., ignored ifguidance_scaleis less than1). -
height (
int, optional, defaults to 512) — The height in pixels of the generated image. -
width (
int, optional, defaults to 512) — The width in pixels of the generated image. -
num_inference_steps (
int, optional, defaults to 100) — The number of denoising steps. More denoising steps usually lead to a higher quality image at the expense of slower inference. -
strength (
float, optional, defaults to 0.3) — Conceptually, indicates how much to transform the referenceimage. Must be between 0 and 1.imagewill be used as a starting point, adding more noise to it the larger thestrength. The number of denoising steps depends on the amount of noise initially added. Whenstrengthis 1, added noise will be maximum and the denoising process will run for the full number of iterations specified innum_inference_steps. A value of 1, therefore, essentially ignoresimage. -
guidance_scale (
float, optional, defaults to 4.0) — Guidance scale as defined in Classifier-Free Diffusion Guidance.guidance_scaleis defined aswof equation 2. of Imagen Paper. Guidance scale is enabled by settingguidance_scale > 1. Higher guidance scale encourages to generate images that are closely linked to the textprompt, usually at the expense of lower image quality. -
num_images_per_prompt (
int, optional, defaults to 1) — The number of images to generate per prompt. -
generator (
torch.GeneratororList[torch.Generator], optional) — One or a list of torch generator(s) to make generation deterministic. -
output_type (
str, optional, defaults to"pil") — The output format of the generate image. Choose between:"pil"(PIL.Image.Image),"np"(np.array) or"pt"(torch.Tensor). -
return_dict (
bool, optional, defaults toTrue) — Whether or not to return a ImagePipelineOutput instead of a plain tuple.
Returns
ImagePipelineOutput or tuple
Function invoked when calling the pipeline for generation.
Examples:
>>> from diffusers import KandinskyImg2ImgPipeline, KandinskyPriorPipeline
>>> from diffusers.utils import load_image
>>> import torch
>>> pipe_prior = KandinskyPriorPipeline.from_pretrained(
... "kandinsky-community/kandinsky-2-1-prior", torch_dtype=torch.float16
... )
>>> pipe_prior.to("cuda")
>>> prompt = "A red cartoon frog, 4k"
>>> image_emb, zero_image_emb = pipe_prior(prompt, return_dict=False)
>>> pipe = KandinskyImg2ImgPipeline.from_pretrained(
... "kandinsky-community/kandinsky-2-1", torch_dtype=torch.float16
... )
>>> pipe.to("cuda")
>>> init_image = load_image(
... "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main"
... "/kandinsky/frog.png"
... )
>>> image = pipe(
... prompt,
... image=init_image,
... image_embeds=image_emb,
... negative_image_embeds=zero_image_emb,
... height=768,
... width=768,
... num_inference_steps=100,
... strength=0.2,
... ).images
>>> image[0].save("red_frog.png")Offloads all models to CPU using accelerate, reducing memory usage with a low impact on performance. Compared
to enable_sequential_cpu_offload, this method moves one whole model at a time to the GPU when its forward
method is called, and the model remains in GPU until the next model runs. Memory savings are lower than with
enable_sequential_cpu_offload, but performance is much better due to the iterative execution of the unet.
Offloads all models to CPU using accelerate, significantly reducing memory usage. When called, the pipeline’s
models have their state dicts saved to CPU and then are moved to a torch.device('meta') and loaded to GPU only when their specific submodule has its forward` method called.
KandinskyInpaintPipeline
class diffusers.KandinskyInpaintPipeline
< source >( text_encoder: MultilingualCLIP movq: VQModel tokenizer: XLMRobertaTokenizer unet: UNet2DConditionModel scheduler: DDIMScheduler )
Parameters
-
text_encoder (
MultilingualCLIP) — Frozen text-encoder. -
tokenizer (
XLMRobertaTokenizer) — Tokenizer of class -
scheduler (DDIMScheduler) —
A scheduler to be used in combination with
unetto generate image latents. - unet (UNet2DConditionModel) — Conditional U-Net architecture to denoise the image embedding.
- movq (VQModel) — MoVQ image encoder and decoder
Pipeline for text-guided image inpainting using Kandinsky2.1
This model inherits from DiffusionPipeline. Check the superclass documentation for the generic methods the library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
__call__
< source >(
prompt: typing.Union[str, typing.List[str]]
image: typing.Union[torch.FloatTensor, PIL.Image.Image]
mask_image: typing.Union[torch.FloatTensor, PIL.Image.Image, numpy.ndarray]
image_embeds: FloatTensor
negative_image_embeds: FloatTensor
negative_prompt: typing.Union[str, typing.List[str], NoneType] = None
height: int = 512
width: int = 512
num_inference_steps: int = 100
guidance_scale: float = 4.0
num_images_per_prompt: int = 1
generator: typing.Union[torch._C.Generator, typing.List[torch._C.Generator], NoneType] = None
latents: typing.Optional[torch.FloatTensor] = None
output_type: typing.Optional[str] = 'pil'
return_dict: bool = True
)
→
ImagePipelineOutput or tuple
Parameters
-
prompt (
strorList[str]) — The prompt or prompts to guide the image generation. -
image (
torch.FloatTensor,PIL.Image.Imageornp.ndarray) —Image, or tensor representing an image batch, that will be used as the starting point for the process. -
mask_image (
PIL.Image.Image,torch.FloatTensorornp.ndarray) —Image, or a tensor representing an image batch, to maskimage. White pixels in the mask will be repainted, while black pixels will be preserved. You can pass a pytorch tensor as mask only if the image you passed is a pytorch tensor, and it should contain one color channel (L) instead of 3, so the expected shape would be either(B, 1, H, W,),(B, H, W),(1, H, W)or(H, W)If image is an PIL image or numpy array, mask should also be a either PIL image or numpy array. If it is a PIL image, it will be converted to a single channel (luminance) before use. If it is a nummpy array, the expected shape is(H, W). -
image_embeds (
torch.FloatTensororList[torch.FloatTensor]) — The clip image embeddings for text prompt, that will be used to condition the image generation. -
negative_image_embeds (
torch.FloatTensororList[torch.FloatTensor]) — The clip image embeddings for negative text prompt, will be used to condition the image generation. -
negative_prompt (
strorList[str], optional) — The prompt or prompts not to guide the image generation. Ignored when not using guidance (i.e., ignored ifguidance_scaleis less than1). -
height (
int, optional, defaults to 512) — The height in pixels of the generated image. -
width (
int, optional, defaults to 512) — The width in pixels of the generated image. -
num_inference_steps (
int, optional, defaults to 100) — The number of denoising steps. More denoising steps usually lead to a higher quality image at the expense of slower inference. -
guidance_scale (
float, optional, defaults to 4.0) — Guidance scale as defined in Classifier-Free Diffusion Guidance.guidance_scaleis defined aswof equation 2. of Imagen Paper. Guidance scale is enabled by settingguidance_scale > 1. Higher guidance scale encourages to generate images that are closely linked to the textprompt, usually at the expense of lower image quality. -
num_images_per_prompt (
int, optional, defaults to 1) — The number of images to generate per prompt. -
generator (
torch.GeneratororList[torch.Generator], optional) — One or a list of torch generator(s) to make generation deterministic. -
latents (
torch.FloatTensor, optional) — Pre-generated noisy latents, sampled from a Gaussian distribution, to be used as inputs for image generation. Can be used to tweak the same generation with different prompts. If not provided, a latents tensor will ge generated by sampling using the supplied randomgenerator. -
output_type (
str, optional, defaults to"pil") — The output format of the generate image. Choose between:"pil"(PIL.Image.Image),"np"(np.array) or"pt"(torch.Tensor). -
return_dict (
bool, optional, defaults toTrue) — Whether or not to return a ImagePipelineOutput instead of a plain tuple.
Returns
ImagePipelineOutput or tuple
Function invoked when calling the pipeline for generation.
Examples:
>>> from diffusers import KandinskyInpaintPipeline, KandinskyPriorPipeline
>>> from diffusers.utils import load_image
>>> import torch
>>> import numpy as np
>>> pipe_prior = KandinskyPriorPipeline.from_pretrained(
... "kandinsky-community/kandinsky-2-1-prior", torch_dtype=torch.float16
... )
>>> pipe_prior.to("cuda")
>>> prompt = "a hat"
>>> image_emb, zero_image_emb = pipe_prior(prompt, return_dict=False)
>>> pipe = KandinskyInpaintPipeline.from_pretrained(
... "kandinsky-community/kandinsky-2-1-inpaint", torch_dtype=torch.float16
... )
>>> pipe.to("cuda")
>>> init_image = load_image(
... "https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main"
... "/kandinsky/cat.png"
... )
>>> mask = np.ones((768, 768), dtype=np.float32)
>>> mask[:250, 250:-250] = 0
>>> out = pipe(
... prompt,
... image=init_image,
... mask_image=mask,
... image_embeds=image_emb,
... negative_image_embeds=zero_image_emb,
... height=768,
... width=768,
... num_inference_steps=50,
... )
>>> image = out.images[0]
>>> image.save("cat_with_hat.png")Offloads all models to CPU using accelerate, reducing memory usage with a low impact on performance. Compared
to enable_sequential_cpu_offload, this method moves one whole model at a time to the GPU when its forward
method is called, and the model remains in GPU until the next model runs. Memory savings are lower than with
enable_sequential_cpu_offload, but performance is much better due to the iterative execution of the unet.
Offloads all models to CPU using accelerate, significantly reducing memory usage. When called, the pipeline’s
models have their state dicts saved to CPU and then are moved to a torch.device('meta') and loaded to GPU only when their specific submodule has its forward` method called.