

HuggingFaceM4/idefics2-8b
Image-Text-to-Text
•
Updated
•
16.6k
•
•
602
__key__
stringlengths 7
7
| __url__
stringclasses 6
values | json
dict | pdf
unknown |
|---|---|---|---|
6368667 | "hf://datasets/pixparse/pdfa-eng-wds@78af41b722c098baef2a87fab70a15dcf8d77ab7/pdfa-eng-train-0000.ta(...TRUNCATED) | {"pages":[{"images_bbox":[[0.37353,0.090907,0.253736,0.100189]],"images_bbox_no_text_overlap":[[0.37(...TRUNCATED) | "JVBERi0xLjYNJeLjz9MNCjM2MiAwIG9iago8PC9MaW5lYXJpemVkIDEvTCAzNDI4NDkvTyAzNjQvRSAxMjEwMzQvTiA1L1QgMzQ(...TRUNCATED) |
4102114 | "hf://datasets/pixparse/pdfa-eng-wds@78af41b722c098baef2a87fab70a15dcf8d77ab7/pdfa-eng-train-0000.ta(...TRUNCATED) | {"pages":[{"images_bbox":[],"images_bbox_no_text_overlap":[],"lines":{"bbox":[[0.375768,0.043485,0.2(...TRUNCATED) | "JVBERi0xLjcNCiW1tbW1DQoxIDAgb2JqDQo8PC9UeXBlL0NhdGFsb2cvUGFnZXMgMiAwIFIvTGFuZyhlbi1VUykgL1N0cnVjdFR(...TRUNCATED) |
7912120 | "hf://datasets/pixparse/pdfa-eng-wds@78af41b722c098baef2a87fab70a15dcf8d77ab7/pdfa-eng-train-0000.ta(...TRUNCATED) | {"pages":[{"images_bbox":[],"images_bbox_no_text_overlap":[],"lines":{"bbox":[[0.374199,0.045981,0.2(...TRUNCATED) | "JVBERi0xLjcNCiW1tbW1DQoxIDAgb2JqDQo8PC9UeXBlL0NhdGFsb2cvUGFnZXMgMiAwIFIvTGFuZyhlbi1VUykgL1N0cnVjdFR(...TRUNCATED) |
7292019 | "hf://datasets/pixparse/pdfa-eng-wds@78af41b722c098baef2a87fab70a15dcf8d77ab7/pdfa-eng-train-0000.ta(...TRUNCATED) | {"pages":[{"images_bbox":[[0.068182,0.117647,0.85322,0.751225]],"images_bbox_no_text_overlap":[],"li(...TRUNCATED) | "JVBERi0xLjUNCiW1tbW1DQoxIDAgb2JqDQo8PC9UeXBlL0NhdGFsb2cvUGFnZXMgMiAwIFIvTGFuZyhlbi1VUykgL1N0cnVjdFR(...TRUNCATED) |
3180753 | "hf://datasets/pixparse/pdfa-eng-wds@78af41b722c098baef2a87fab70a15dcf8d77ab7/pdfa-eng-train-0000.ta(...TRUNCATED) | {"pages":[{"images_bbox":[[0.028399,0.034058,0.107573,0.036488],[0.04475,0.201294,0.494836,0.212847](...TRUNCATED) | "JVBERi0xLjQNJeLjz9MNCjEyIDAgb2JqDTw8L0xpbmVhcml6ZWQgMS9MIDkzMjMzNS9PIDE1L0UgOTI2ODgyL04gNS9UIDkzMTk(...TRUNCATED) |
5384718 | "hf://datasets/pixparse/pdfa-eng-wds@78af41b722c098baef2a87fab70a15dcf8d77ab7/pdfa-eng-train-0000.ta(...TRUNCATED) | {"pages":[{"images_bbox":[],"images_bbox_no_text_overlap":[],"lines":{"bbox":[[0.365314,0.072559,0.2(...TRUNCATED) | "JVBERi0xLjMKJcTl8uXrp/Og0MTGCjQgMCBvYmoKPDwgL0xlbmd0aCA1IDAgUiAvRmlsdGVyIC9GbGF0ZURlY29kZSA+PgpzdHJ(...TRUNCATED) |
7106895 | "hf://datasets/pixparse/pdfa-eng-wds@78af41b722c098baef2a87fab70a15dcf8d77ab7/pdfa-eng-train-0000.ta(...TRUNCATED) | {"pages":[{"images_bbox":[],"images_bbox_no_text_overlap":[],"lines":{"bbox":[[0.082353,0.16709,0.27(...TRUNCATED) | "JVBERi0xLjcNJeLjz9MNCjM4IDAgb2JqDTw8L0xpbmVhcml6ZWQgMS9MIDE4NTUwOC9PIDQwL0UgMTI4NDcyL04gNC9UIDE4NDY(...TRUNCATED) |
2998218 | "hf://datasets/pixparse/pdfa-eng-wds@78af41b722c098baef2a87fab70a15dcf8d77ab7/pdfa-eng-train-0000.ta(...TRUNCATED) | {"pages":[{"images_bbox":[],"images_bbox_no_text_overlap":[],"lines":{"bbox":[[0.142857,0.061618,0.6(...TRUNCATED) | "JVBERi0xLjcKJeLjz9MKMTAgMCBvYmoKPDwgL1R5cGUgL1BhZ2UgL1BhcmVudCAxIDAgUiAvTGFzdE1vZGlmaWVkIChEOjIwMjE(...TRUNCATED) |
2167084 | "hf://datasets/pixparse/pdfa-eng-wds@78af41b722c098baef2a87fab70a15dcf8d77ab7/pdfa-eng-train-0000.ta(...TRUNCATED) | {"pages":[{"images_bbox":[[0.68325,-0.000348,0.318743,0.054031],[0.562239,0.326056,0.301978,0.083467(...TRUNCATED) | "JVBERi0xLjcNJeLjz9MNCjggMCBvYmoNPDwvTGluZWFyaXplZCAxL0wgNDk4ODA2L08gMTAvRSA0OTQzNDYvTiAxL1QgNDk4NTM(...TRUNCATED) |
5204531 | "hf://datasets/pixparse/pdfa-eng-wds@78af41b722c098baef2a87fab70a15dcf8d77ab7/pdfa-eng-train-0000.ta(...TRUNCATED) | {"pages":[{"images_bbox":[],"images_bbox_no_text_overlap":[],"lines":{"bbox":[[0.017836,0.007769,0.1(...TRUNCATED) | "JVBERi0xLjcKJeLjz9MKMTAgMCBvYmoKPDwgL1R5cGUgL1BhZ2UgL1BhcmVudCAxIDAgUiAvTGFzdE1vZGlmaWVkIChEOjIwMjE(...TRUNCATED) |
PDFA dataset is a document dataset filtered from the SafeDocs corpus, aka CC-MAIN-2021-31-PDF-UNTRUNCATED. The original purpose of that corpus is for comprehensive pdf documents analysis. The purpose of that subset differs in that regard, as focus has been done on making the dataset machine learning-ready for vision-language models.
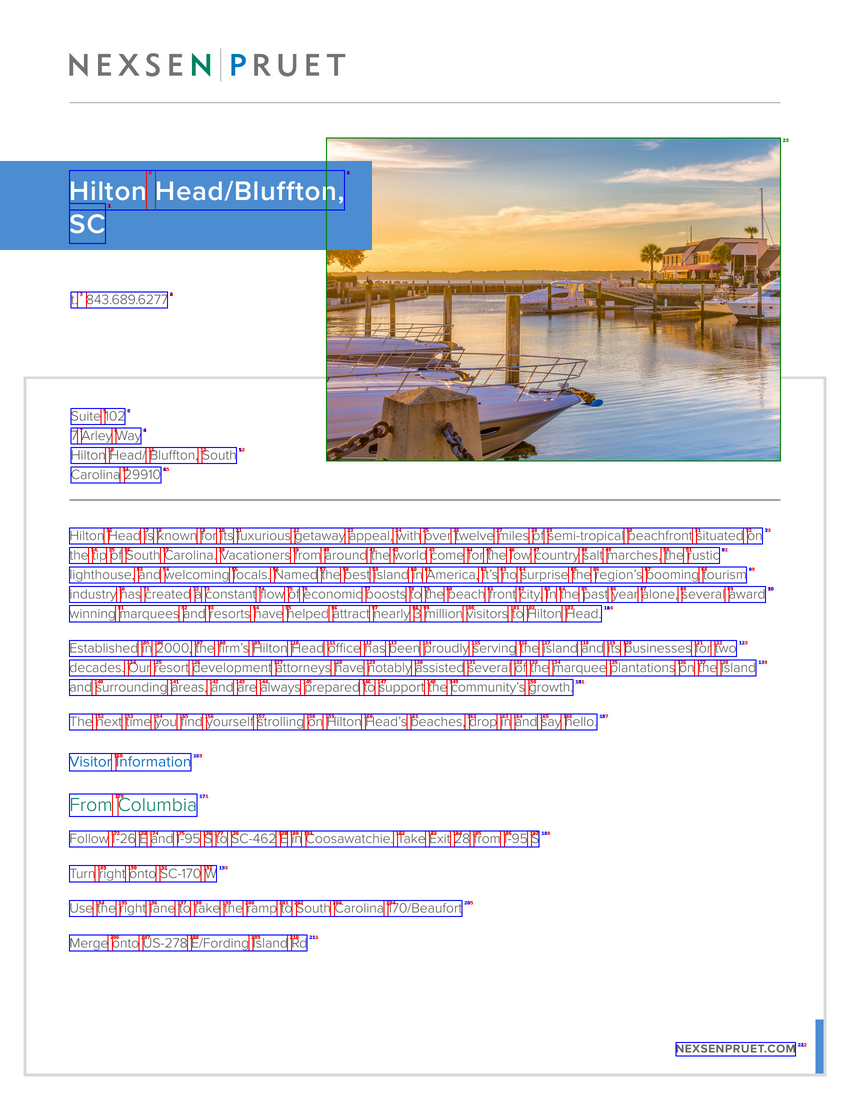
An example page of one pdf document, with added bounding boxes around words (red), lines (blue) and embedded images (green).
chug
Check out chug, our optimized library for sharded dataset loading!
import chug
task_cfg = chug.DataTaskDocReadCfg(
page_sampling='all',
)
data_cfg = chug.DataCfg(
source='pixparse/pdfa-eng-wds',
split='train',
batch_size=None,
format='hfids',
num_workers=0,
)
data_loader = chug.create_loader(
data_cfg,
task_cfg,
)
sample = next(iter(data_loader))
datasets
This dataset can also be used with webdataset library or current releases of Hugging Face datasets. Here is an example using the "streaming" parameter. We do recommend downloading the dataset to save bandwidth.
dataset = load_dataset('pixparse/pdfa-eng-wds', streaming=True)
print(next(iter(dataset['train'])).keys())
>> dict_keys(['__key__', '__url__', 'json', 'ocr', 'pdf', 'tif'])
For faster download, you can use directly the huggingface_hub library. Make sure hf_transfer is installed prior to downloading and mind that you have enough space locally.
import os
os.environ["HF_HUB_ENABLE_HF_TRANSFER"] = "1"
from huggingface_hub import HfApi, logging
#logging.set_verbosity_debug()
hf = HfApi()
hf.snapshot_download("pixparse/pdfa-eng-wds", repo_type="dataset", local_dir_use_symlinks=False)
On a normal setting, the 1.5TB can be downloaded in approximately 4 hours.
Further, a metadata file _pdfa-english-train-info-minimal.json contains the list of samples per shard, with same basename and .json or .pdf extension,
as well as the count of files per shard.
Initially, we started from the readily available ~11TB zip files from PDFA in their initial data release.
From the pdf digital files, we extracted words, bounding boxes and image bounding boxes that are available in the pdf file. This information is then reshaped into lines organized in reading order, under the key lines. We keep non-reshaped word and bounding box information under the word key, should users want to use their own heuristic.
The way we obtain an approximate reading order is simply by looking at the frequency peaks of the leftmost word x-coordinate. A frequency peak means that a high number of lines are starting from the same point. Then, we keep track of the x-coordinate of each such identified column. If no peaks are found, the document is assumed to be readable in plain format. The code to detect columns can be found here.
def get_columnar_separators(page, min_prominence=0.3, num_bins=10, kernel_width=1):
"""
Identifies the x-coordinates that best separate columns by analyzing the derivative of a histogram
of the 'left' values (xmin) of bounding boxes.
Args:
page (dict): Page data with 'bbox' containing bounding boxes of words.
min_prominence (float): The required prominence of peaks in the histogram.
num_bins (int): Number of bins to use for the histogram.
kernel_width (int): The width of the Gaussian kernel used for smoothing the histogram.
Returns:
separators (list): The x-coordinates that separate the columns, if any.
"""
try:
left_values = [b[0] for b in page['bbox']]
hist, bin_edges = np.histogram(left_values, bins=num_bins)
hist = scipy.ndimage.gaussian_filter1d(hist, kernel_width)
min_val = min(hist)
hist = np.insert(hist, [0, len(hist)], min_val)
bin_width = bin_edges[1] - bin_edges[0]
bin_edges = np.insert(bin_edges, [0, len(bin_edges)], [bin_edges[0] - bin_width, bin_edges[-1] + bin_width])
peaks, _ = scipy.signal.find_peaks(hist, prominence=min_prominence * np.max(hist))
derivatives = np.diff(hist)
separators = []
if len(peaks) > 1:
# This finds the index of the maximum derivative value between peaks
# which indicates peaks after trough --> column
for i in range(len(peaks)-1):
peak_left = peaks[i]
peak_right = peaks[i+1]
max_deriv_index = np.argmax(derivatives[peak_left:peak_right]) + peak_left
separator_x = bin_edges[max_deriv_index + 1]
separators.append(separator_x)
except Exception as e:
separators = []
return separators
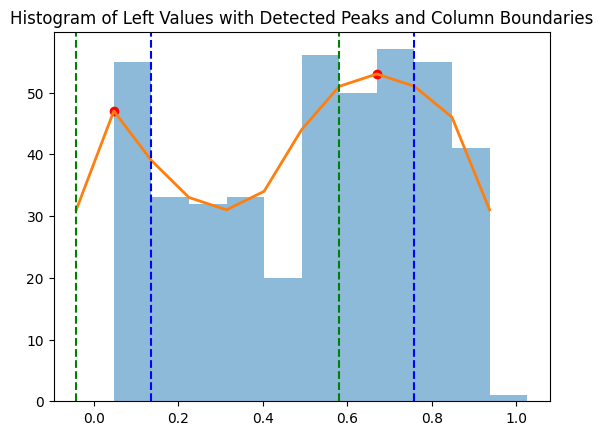
A graph of leftmost x-positions of bounding boxes on a 2-column (arxiv) document. Peaks are visibly detected.
For each pdf document, we store statistics on the file size, number of words (as characters separated by spaces), number of pages, as well as the rendering times of each page for a given dpi.
File size and page rendering time are used to set thresholds in the final dataset: the goal is to remove files that are larger than 100 MB, or that take more than 500ms to render on a modern machine, to optimize dataloading at scale. Having "too large" or "too slow" files would add a burden to large-scale training pipelines and we choose to alleviate this in the current release. Finally, a full pass over the dataset is done, trying to open and decode a bytestream from each raw object and discarding any object (pair pdf/json) that fails to be opened, to remove corrupted data.
As a last step, we use XLM-Roberta to restrict the dataset to an english subset, specifically papluca/xlm-roberta-base-language-detection , on the first 512 words of the first page of each document.
Be aware that some documents may have several languages embedded in them, or that some predictions might be inaccurate. A majority of documents from the original corpus are in English language.
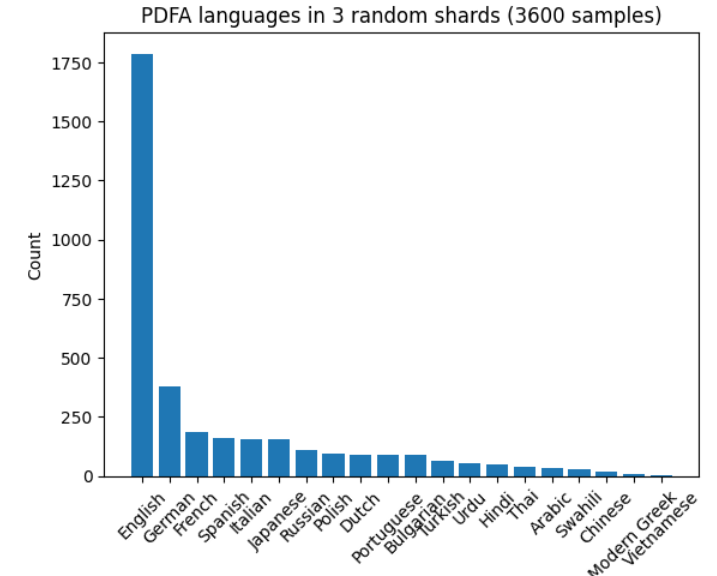
A histogram of language distribution taken on a fraction of the original -non-filtered on language- PDFA dataset.
At the end, each document exists as a pairing of a pdf and a json file containing extensive OCR annotation as well as metadata information about rendering times. The filterings and packaging in webdataset format are tailored towards multimodal machine learning at scale, specifically image-to-text tasks.
Pdf files are coming from various sources. They are in RGB format, and contain multiple pages, and they can be rendered using the engine of your choice, here pdf2image .
from pdf2image import convert_from_bytes
pdf_first_page = convert_from_bytes(sample['pdf'], dpi=300, first_page=1, last_page=1)[0]

The metadata for each document has been formatted in this way. Each pdf is paired with a json file with the following structure. Entries have been shortened for readability.
{
"pages": [
{
"words": [
{
"text": [
"Health", "Smart", "Virginia", "Sample", "Lesson", "Plan", "Grade", "8", "-", "HP-7"
],
"bbox": [
[0.117647, 0.045563, 0.051981, 0.015573],
[0.174694, 0.045563, 0.047954, 0.015573],
[0.227643, 0.045563, 0.05983, 0.015573],
[0.292539, 0.045563, 0.061002, 0.015573],
[0.357839, 0.045563, 0.058053, 0.015573],
[0.420399, 0.045563, 0.035908, 0.015573],
[0.716544, 0.04577, 0.054624, 0.016927],
[0.776681, 0.04577, 0.010905, 0.016927],
[0.793087, 0.04577, 0.00653, 0.016927],
[0.805078, 0.04577, 0.044768, 0.016927]
],
"score": [
1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0
],
"line_pos": [
[0, 0], [0, 8], [0, 16], [0, 24], [0, 32], [0, 40], [0, 48], [1, 0], [2, 0], [3, 0]
]
}
],
"lines": [
{
"text": [
"Health Smart Virginia Sample Lesson Plan Grade", "Physical", "Disease", "Health", "2020", "Grade 8 Sample Lesson Plan:"
],
"bbox": [
[0.117647, 0.045563, 0.653521, 0.016927],
[0.716546, 0.063952, 0.07323199999999996, 0.016927],
[0.716546, 0.082134, 0.07102200000000003, 0.016927],
[0.716546, 0.100315, 0.05683300000000002, 0.016927],
[0.716546, 0.118497, 0.043709, 0.016927],
[0.27, 0.201185, 0.459554, 0.028268]
],
"score": [
1.0, 1.0, 1.0, 1.0, 1.0, 1.0
],
"word_slice": [
[0, 7], [7, 8], [8, 9], [9, 10], [10, 11], [11, 16]
]
}
],
"images_bbox": [
[0.37353, 0.090907, 0.253736, 0.100189]
],
"images_bbox_no_text_overlap": [
[0.37353, 0.090907, 0.253736, 0.100189]
]
}
]
}
The top-level key, pages, is a list of every page in the document. The above example shows only one page.
words is a list of words without spaces, with their individual associated bounding box in the next entry.
bbox contains the bounding box coordinates in left, top, width, height format, with coordinates relative to the page size.
line_pos, for words, is a list of tuples indicating the index of the line the word belongs to, then the starting position in that line, character-wise.
lines are lines (parts of sequences, strings separated by spaces) grouped together using the heuristic detailed above.
bbox contains the bounding box coordinates in left, top, width, height format, with coordinates relative to the page size.
For each page,
images_bbox gives the bounding boxes of the images embedded in the page.
images_bbox_no_text_overlap gives a reduced list of bounding boxes that have no overlap with text found in the pdf. Text might be present as a drawing or another representation, however.
``
score is a placeholder of value 1.0 for the entire dataset.
Such a formatting follows the multimodal dataset from the Industry Document Library, https://huggingface.co/datasets/pixparse/idl-wds.
Estimating the number of tokens is done using a LlamaTokenizer from tokenizers. There is a clear power law distribution with respect to data length.
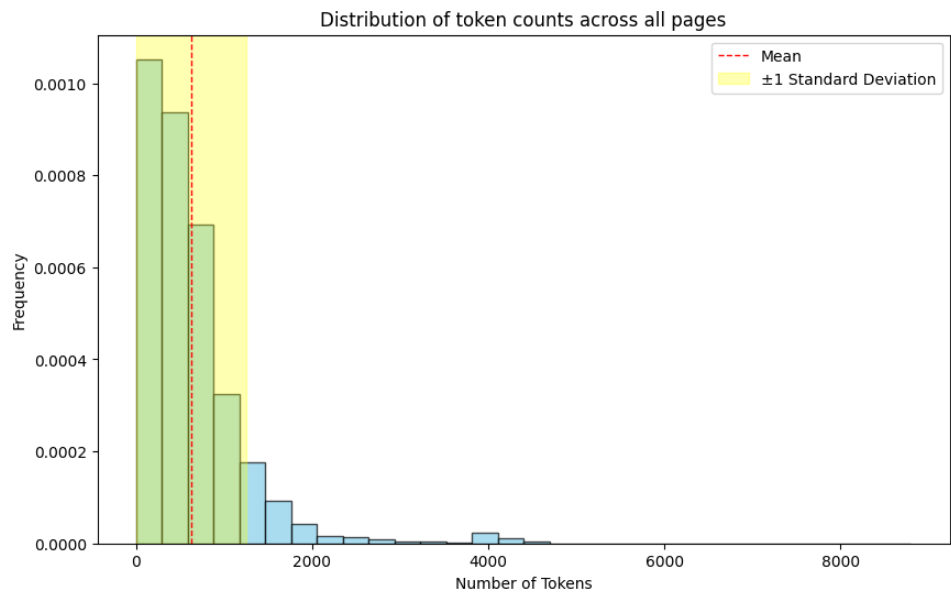
A histogram of token count distribution per page, taken from a subset of the dataset. There is a visible power law.
pdfa-eng-wds-{0000..1799}.tarPablo Montalvo, Ross Wightman
This dataset is intended as an OCR-heavy pretraining basis for vision-language models. As a corpus, it does not represent the intent and purpose from CC-MAIN-2021-31-PDF-UNTRUNCATED. The original is made to represent extant pdf data in its diversity and complexity. In particular, common issues related to misuse of pdfs such as mojibake (garbled text due to decoding erros) are yet to be addressed systematically, and this dataset present simplifications that can hide such issues found in the wild. In order to address these biases, we recommend to examine carefully both the simplified annotation and the original pdf data, beyond a simple rendering.
Further, the annotation is limited to what can be extracted and is readily available - text drawn in images and only present as a bitmap rendition might be missed entirely by said annotation.
Finally, the restriction to English language is made to alleviate difficulties related to multilingual processing so that the community can be familiarized with this optimized multimodal format. A later release will be done on the full PDFA, with splits per languages, layout types, and so on.
Data has been filtered from the original corpus. As a consequence, users should note Common Crawl's license and terms of use and the Digital Corpora project's Terms of Use.

