
ccmusic-database/song_structure
Audio Classification
•
Updated
•
12
This repository is publicly accessible, but you have to accept the conditions to access its files and content.
The song_structure dataset contains links to web audios used for data collection purposes. song_structure does not own or claim rights to the content linked within this dataset; all rights and copyright remain with the respective content creators and channel owners. Users are responsible for ensuring compliance with the terms and conditions of the platforms hosting these audios.
Log in or Sign Up to review the conditions and access this dataset content.
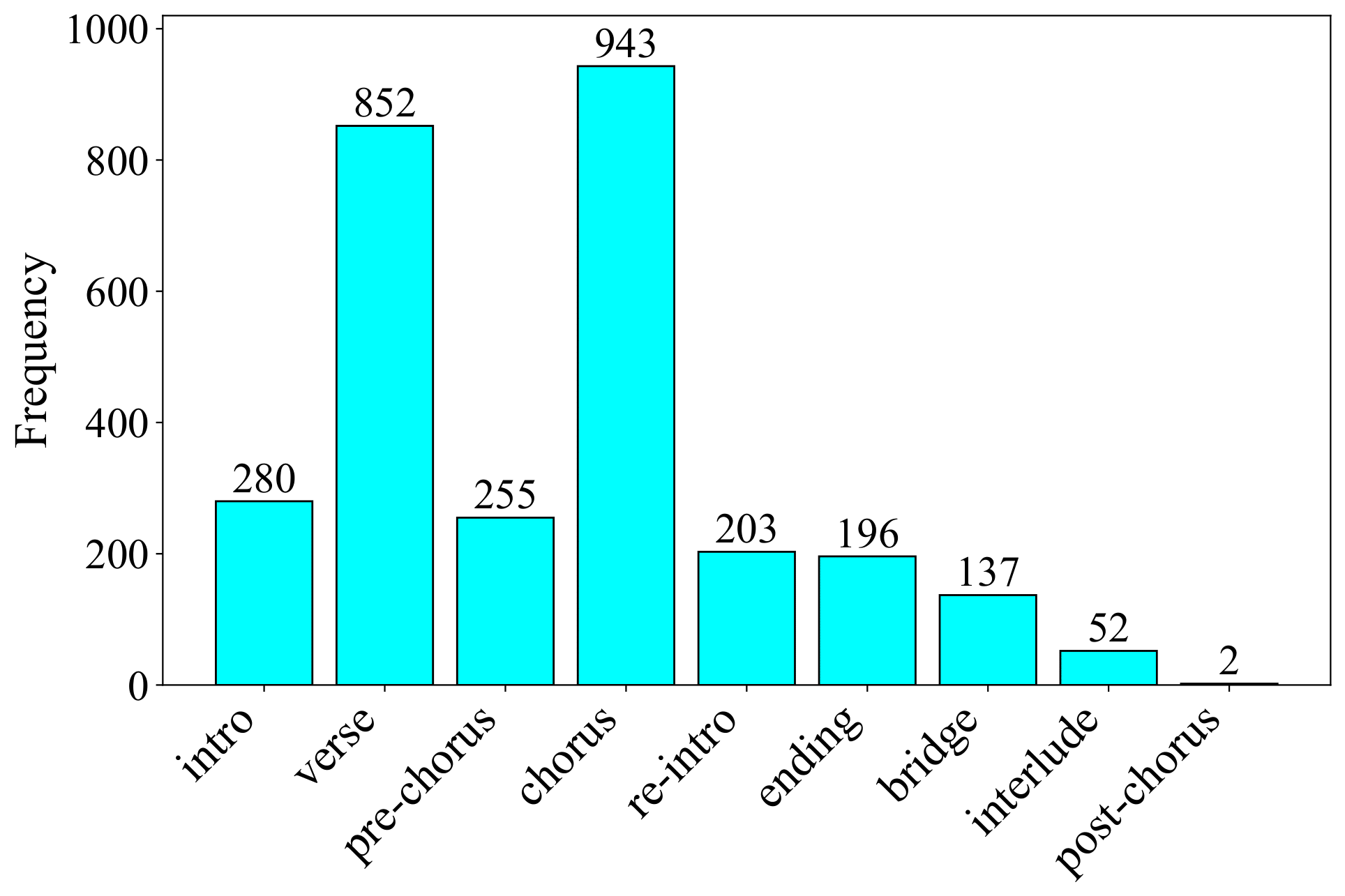
The raw dataset comprises 300 pop songs in .mp3 format, sourced from the NetEase music, accompanied by a structure annotation file for each song in .txt format. The annotator for music structure is a professional musician and teacher from the China Conservatory of Music. For the statistics of the dataset, there are 208 Chinese songs, 87 English songs, three Korean songs and two Japanese songs. The song structures are labeled as follows: intro, re-intro, verse, chorus, pre-chorus, post-chorus, bridge, interlude and ending. Below figure shows the frequency of each segment label that appears in the set. The labels chorus and verse are the two most prevalent segment labels in the dataset and they are the most common segment in Western popular music. Among them, the number of “Postchorus” tags is the least, with only two present.
| audio | mel | label |
|---|---|---|
| .mp3, 22050Hz | .jpg, 22050Hz | {onset_time:uint32,offset_time:uint32,structure:string} |
.zip(.mp3), .txt
intro, chorus, verse, pre-chorus, post-chorus, bridge, ending
train
Unlike the above three datasets for classification, this one has not undergone pre-processing such as spectrogram transform. Thus we provide the original content only. The integrated version of the dataset is organized based on audio files, with each item structured into three columns: The first column contains the audio of the song in .mp3 format, sampled at 22,050 Hz. The second column consists of lists indicating the time points that mark the boundaries of different song sections, while the third column contains lists corresponding to the labels of the song structures listed in the second column. Strictly speaking, the first column represents the data, while the subsequent two columns represent the label.
time-series-forecasting
Chinese, English
from datasets import load_dataset
dataset = load_dataset(
"ccmusic-database/song_structure",
name="default",
split="train",
token="Your_Access_Token",
)
for item in dataset:
print(item)
GIT_LFS_SKIP_SMUDGE=1 git clone git@hf.co:datasets/ccmusic-database/song_structure
cd song_structure
https://www.modelscope.cn/datasets/ccmusic-database/song_structure
Lack of a dataset for song structure
Zhaorui Liu, Monan Zhou
Students from CCMUSIC
Students from CCMUSIC collected 300 pop songs, as well as a structure annotation file for each song
Students from CCMUSIC
Due to copyright issues with the original music, only features of audio by frame are provided in the dataset
Promoting the development of the AI music industry
Only for mp3
Most are Chinese songs
Zijin Li
https://huggingface.co/ccmusic-database/song_structure
@dataset{zhaorui_liu_2021_5676893,
author = {Zhaorui Liu and Zijin Li},
title = {Music Data Sharing Platform for Computational Musicology Research (CCMUSIC DATASET)},
month = nov,
year = 2021,
publisher = {Zenodo},
version = {1.1},
doi = {10.5281/zenodo.5676893},
url = {https://doi.org/10.5281/zenodo.5676893}
}
Provide a dataset for song structure