
Darija LID Benchmark
A curated Arabic dialect identification dataset focused on Moroccan Darija, built from multiple public sources, cleaned, taxonomised.
Goal
Binary text classification:
| Label | Meaning |
|---|---|
darija |
Moroccan Arabic (Arabic script or Arabizi) |
other |
Other dialects, MSA, English, etc. |
Dataset Schema
| Column | Type | Description |
|---|---|---|
src |
string | Source dataset identifier(s), joined by | |
text |
string | Original raw text |
text_clean |
string | Text after noise removal and normalisation |
label |
string | darija or other |
dialect_family |
string | Broad geographic family (e.g. Maghrebi, Levantine) |
country |
string | Country-level grouping |
dialect |
string | Fine-grained dialect label from the source |
has_latin_script |
bool | Whether text_clean contains at least one Latin character |
EDA
1. Dataset Size
| Count | |
|---|---|
| Raw samples | 471,402 |
| After removing duplicates & noisy text (pure emojies, pure punct, math operations, Telugu text, etc.) | 471,030 |
2. Label Distribution
| Label | % |
|---|---|
other |
52.01% |
darija |
47.98% |
The dataset is near-balanced. The slight majority of other samples comes primarily from Levantine and Universal (MSA/English) sources.
3. Text Length (word count after cleaning)
| Statistic | Value |
|---|---|
| Mean | ~9 words |
| Std | ~10 words |
| Median | 7 words |
| 25th percentile | 5 words |
| 50th percentile | 7 words |
| 75th percentile | 11 words |
| Min | 1 word |
| Max | 670 words |
Single-word samples represent ~0.8% of the dataset. Should they be retained or removed?
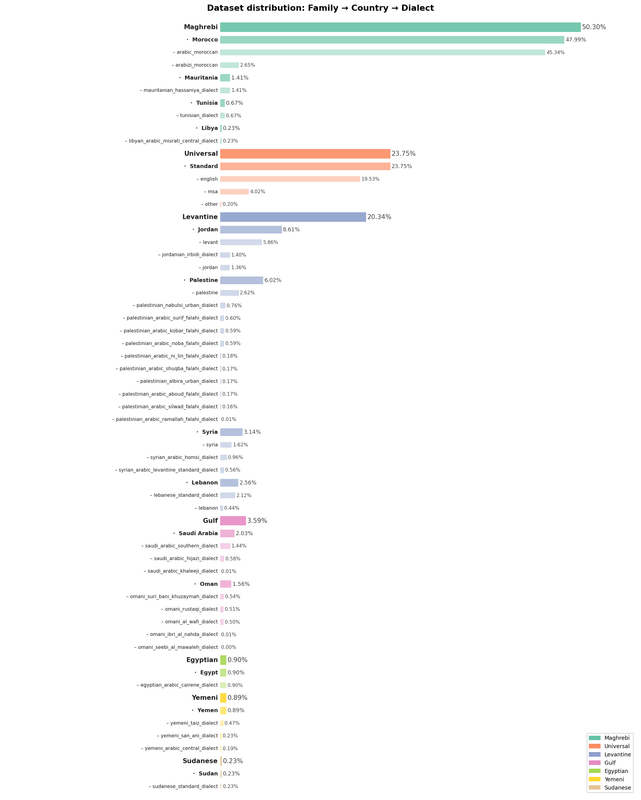
4. Dialect Taxonomy
Dialects are grouped into a three-level hierarchy: Family → Country → Dialect.
5. Script Distribution
| has_latin_script | Interpretation |
|---|---|
False |
Pure Arabic script |
True |
Contains at least one Latin character (Arabizi, code-switch, English) |
6. Geographic Coverage Gaps
Notable absences in the current dataset:
- Algeria — no Algerian Darija samples
- French — no French
7. Source Datasets
| Source | Role |
|---|---|
atlasia/Darija-LID |
Primary Moroccan Darija source |
atlasia/levantine_dialects |
Levantine other class |
atlasia/Darija_LID_Anootation_10k |
Annotated Moroccan samples |
atlasia/DODa-audio-dataset |
Transcribed Darija speech |
UBC-NLP/alexandria |
Multi-dialect Arabic |
- Downloads last month
- 103