
Quantized 4-bit models
Collection
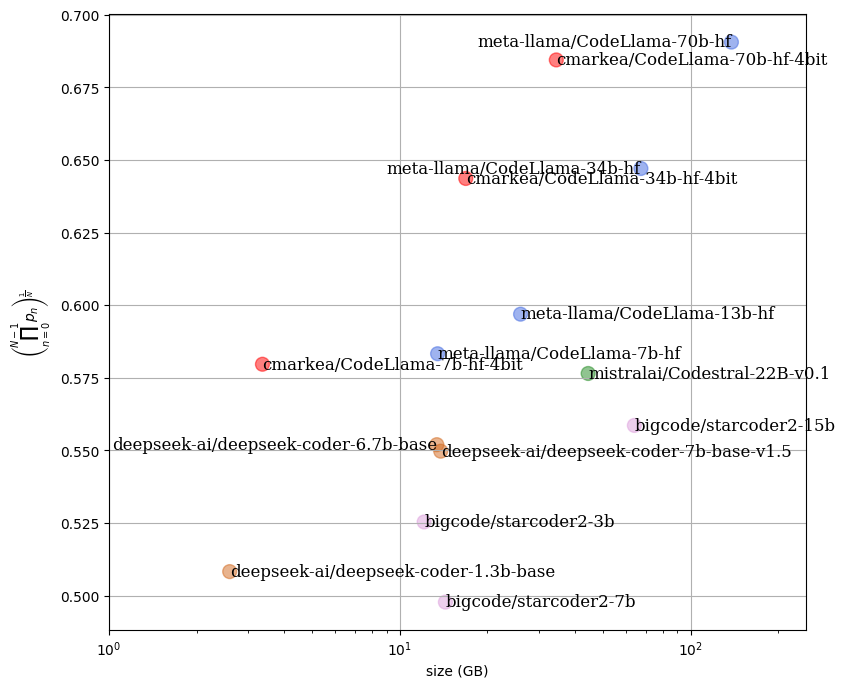
Large model quantized with post-quantization performance very close to the original models, allowing it to run on reasonable infrastructure.
•
10 items
•
Updated
•
1