
Apollo2-9B-exl2
Original model: Apollo2-9B
Made by: FreedomIntelligence
Quants
4bpw h6 (main)
4.5bpw h6
5bpw h6
6bpw h6
8bpw h8
Quantization notes
Made with Exllamav2 0.2.3 with the default dataset. This model needs software with Exllamav2 library such as Text-Generation-WebUI, TabbyAPI, etc.
This model has to fit your GPU to be usable and it's mainly meant for RTX cards on Windows/Linux or AMD on Linux.
For computers with incompatible hardware it's better to use GGUF versions of the model, you can find them here.
Original model card
Democratizing Medical LLMs For Much More Languages
Covering 12 Major Languages including English, Chinese, French, Hindi, Spanish, Arabic, Russian, Japanese, Korean, German, Italian, Portuguese and 38 Minor Languages So far.
📃 Paper • 🌐 Demo • 🤗 ApolloMoEDataset • 🤗 ApolloMoEBench • 🤗 Models •🌐 Apollo • 🌐 ApolloMoE

🌈 Update
- [2024.10.15] ApolloMoE repo is published!🎉
Languages Coverage
12 Major Languages and 38 Minor Languages
Click to view the Languages Coverage
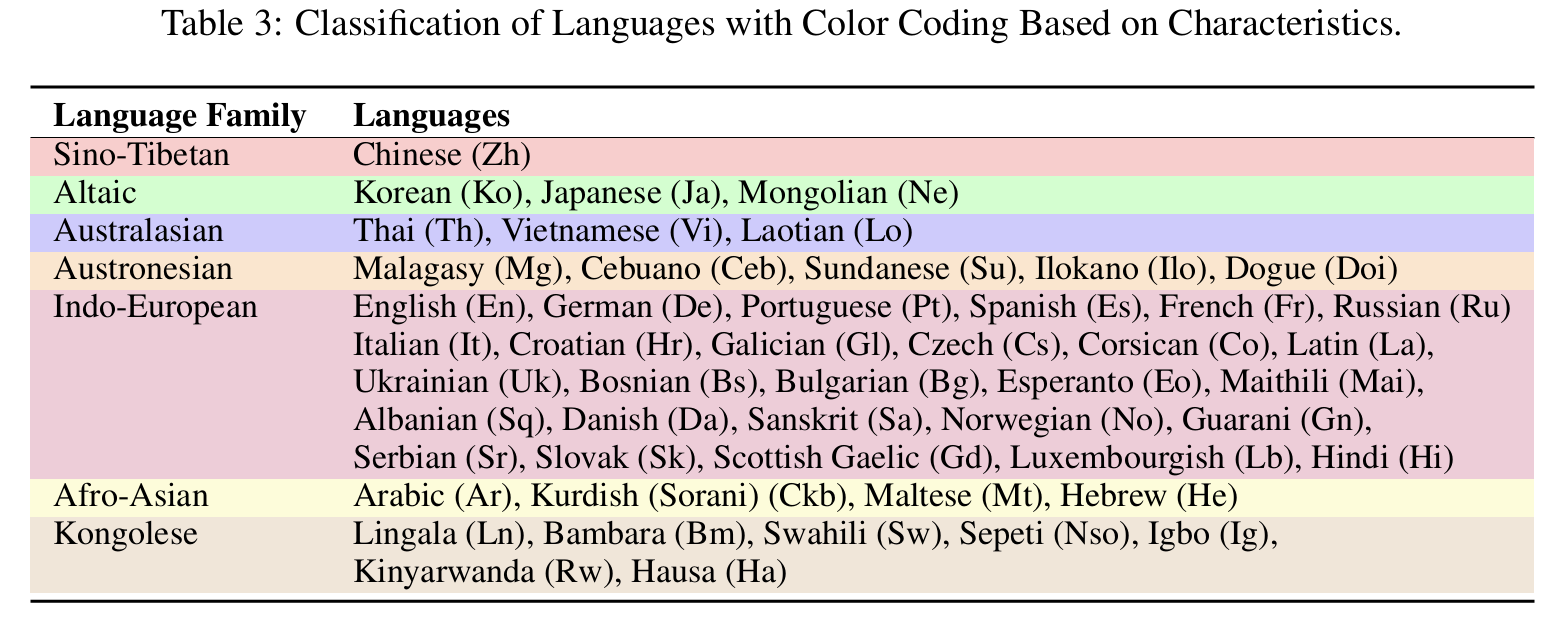
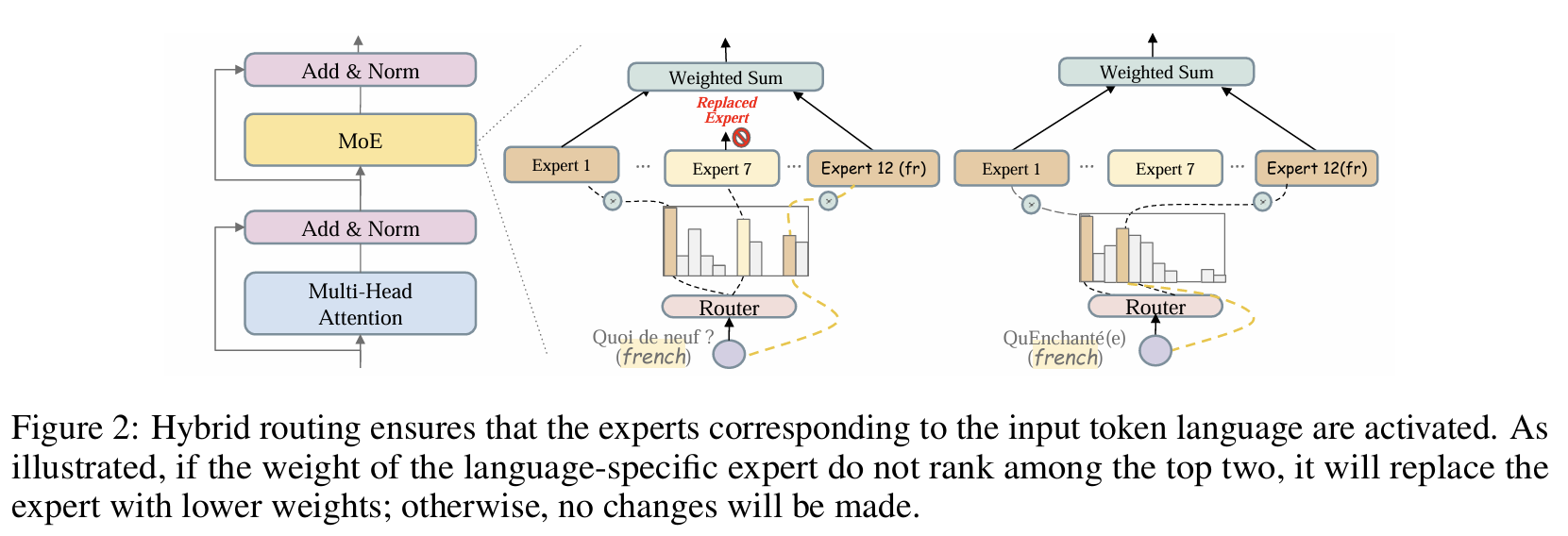
Architecture
Click to view the MoE routing image
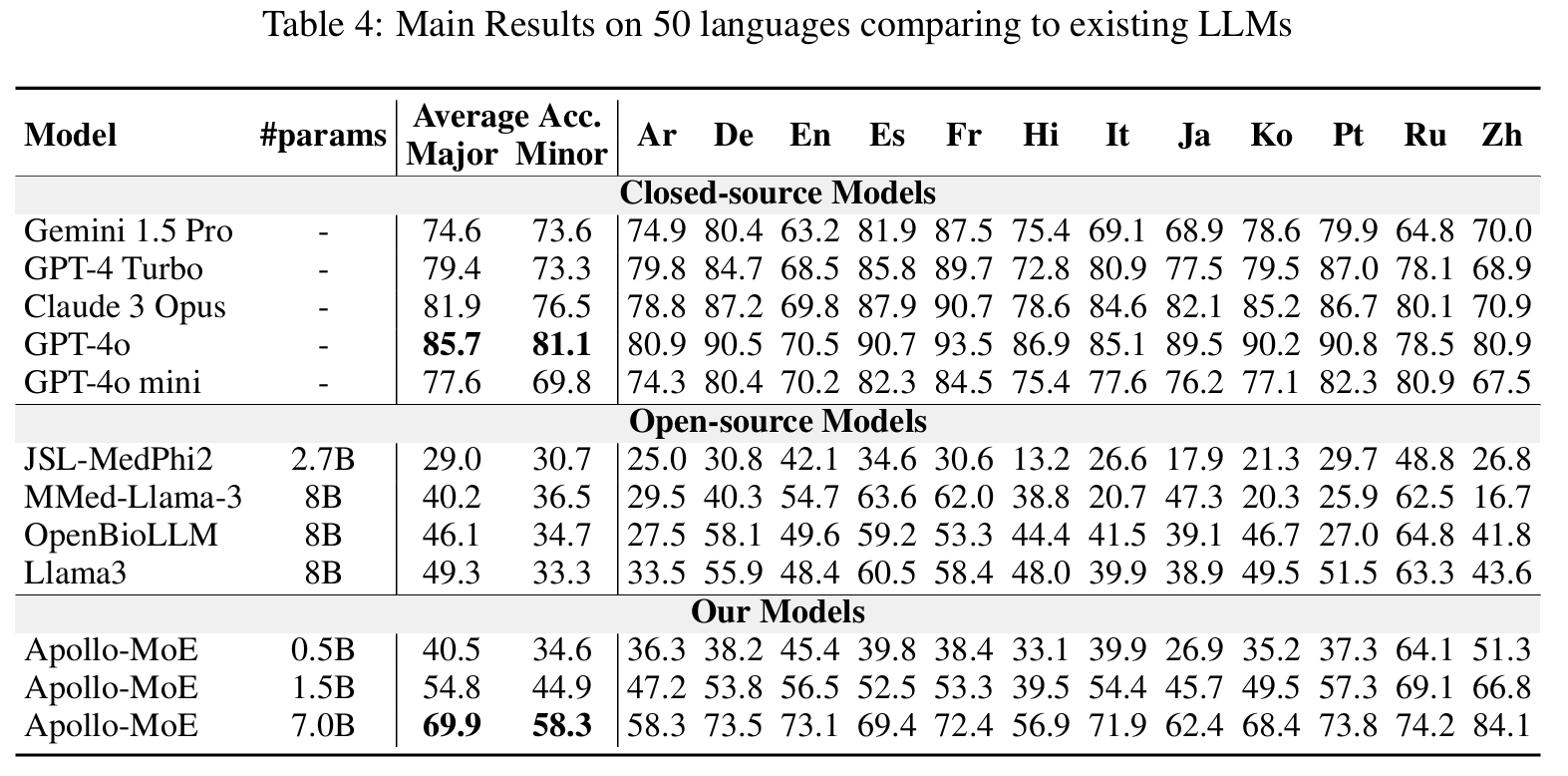
Results
Dense
🤗 Apollo2-0.5B • 🤗 Apollo2-1.5B • 🤗 Apollo2-2B
🤗 Apollo2-3.8B • 🤗 Apollo2-7B • 🤗 Apollo2-9B
Click to view the Dense Models Results
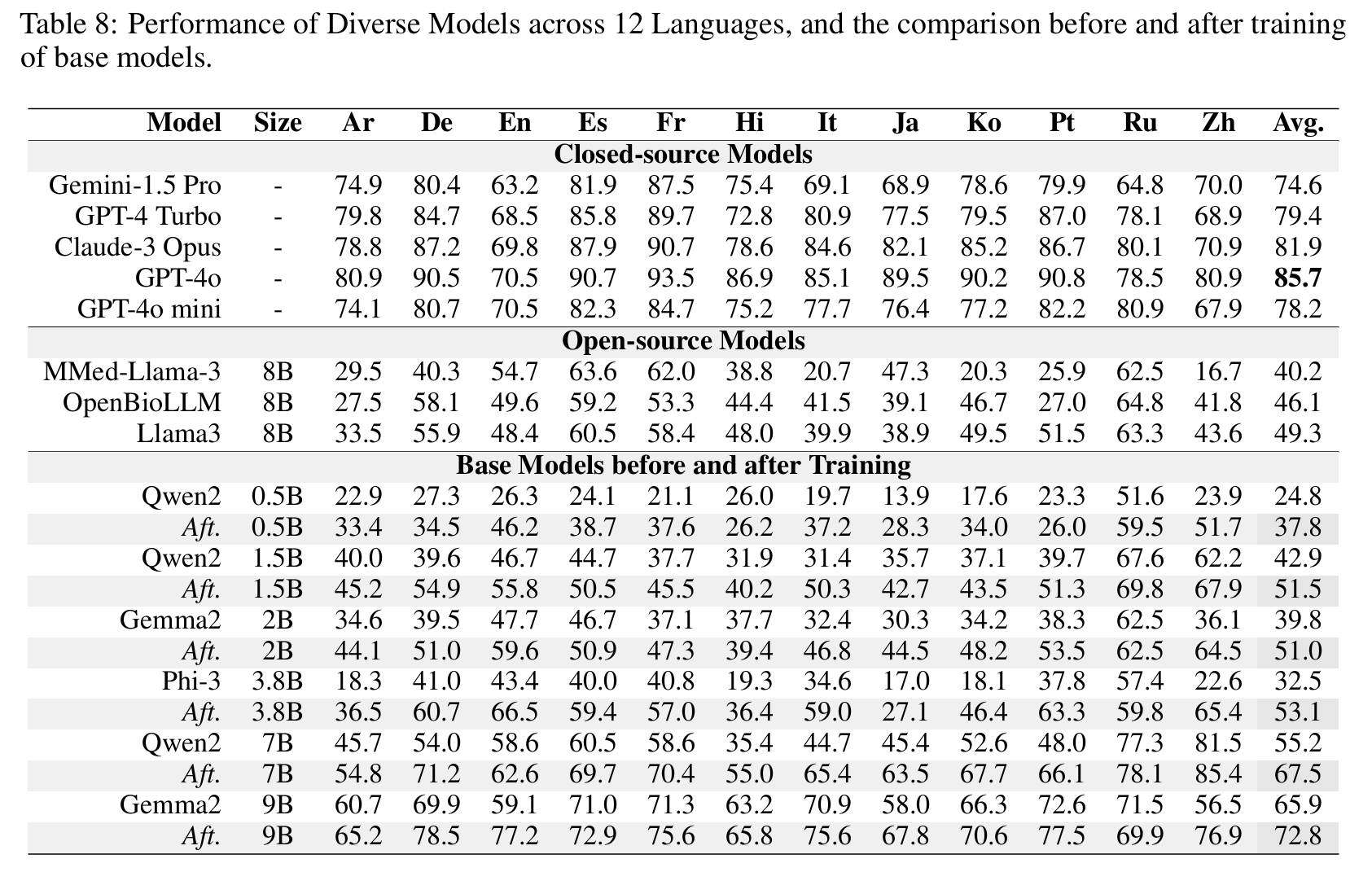
Post-MoE
🤗 Apollo-MoE-0.5B • 🤗 Apollo-MoE-1.5B • 🤗 Apollo-MoE-7B
Click to view the Post-MoE Models Results
Usage Format
Apollo2
- 0.5B, 1.5B, 7B: User:{query}\nAssistant:{response}<|endoftext|>
- 2B, 9B: User:{query}\nAssistant:{response}<eos>
- 3.8B: <|user|>\n{query}<|end|><|assisitant|>\n{response}<|end|>
Apollo-MoE
- 0.5B, 1.5B, 7B: User:{query}\nAssistant:{response}<|endoftext|>
Dataset & Evaluation
Dataset 🤗 ApolloMoEDataset
Evaluation 🤗 ApolloMoEBench
Click to expand
EN:
- MedQA-USMLE
- MedMCQA
- PubMedQA: Because the results fluctuated too much, they were not used in the paper.
- MMLU-Medical
- Clinical knowledge, Medical genetics, Anatomy, Professional medicine, College biology, College medicine
ZH:
- MedQA-MCMLE
- CMB-single: Not used in the paper
- Randomly sample 2,000 multiple-choice questions with single answer.
- CMMLU-Medical
- Anatomy, Clinical_knowledge, College_medicine, Genetics, Nutrition, Traditional_chinese_medicine, Virology
- CExam: Not used in the paper
- Randomly sample 2,000 multiple-choice questions
ES: Head_qa
FR:
- Frenchmedmcqa
- [MMLU_FR]
- Clinical knowledge, Medical genetics, Anatomy, Professional medicine, College biology, College medicine
HI: MMLU_HI
- Clinical knowledge, Medical genetics, Anatomy, Professional medicine, College biology, College medicine
AR: MMLU_AR
- Clinical knowledge, Medical genetics, Anatomy, Professional medicine, College biology, College medicine
JA: IgakuQA
KO: KorMedMCQA
IT:
- MedExpQA
- [MMLU_IT]
- Clinical knowledge, Medical genetics, Anatomy, Professional medicine, College biology, College medicine
DE: BioInstructQA: German part
PT: BioInstructQA: Portuguese part
RU: RuMedBench
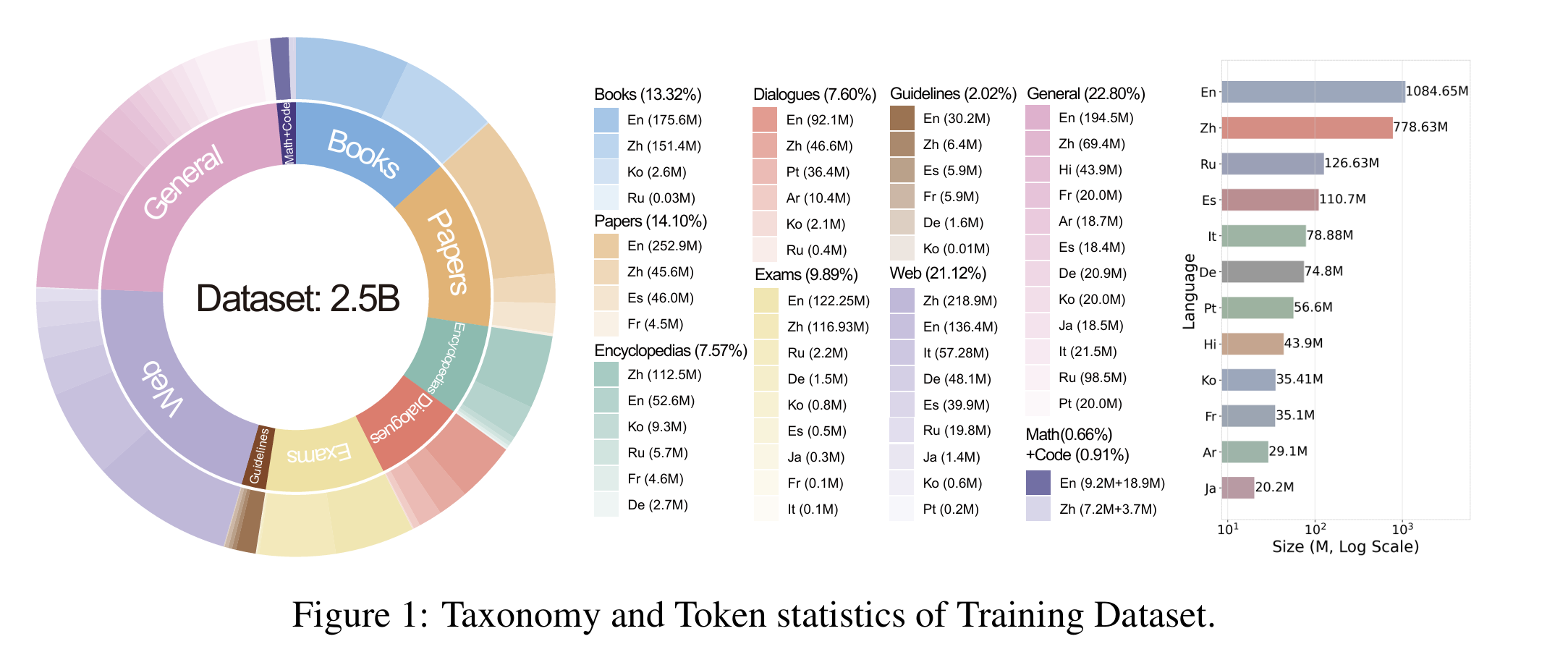
Results reproduction
Click to expand
We take Apollo2-7B or Apollo-MoE-0.5B as example
Download Dataset for project:
bash 0.download_data.shPrepare test and dev data for specific model:
- Create test data for with special token
bash 1.data_process_test&dev.shPrepare train data for specific model (Create tokenized data in advance):
- You can adjust data Training order and Training Epoch in this step
bash 2.data_process_train.shTrain the model
- If you want to train in Multi Nodes please refer to ./src/sft/training_config/zero_multi.yaml
bash 3.single_node_train.shEvaluate your model: Generate score for benchmark
bash 4.eval.sh
Citation
Please use the following citation if you intend to use our dataset for training or evaluation:
@misc{zheng2024efficientlydemocratizingmedicalllms,
title={Efficiently Democratizing Medical LLMs for 50 Languages via a Mixture of Language Family Experts},
author={Guorui Zheng and Xidong Wang and Juhao Liang and Nuo Chen and Yuping Zheng and Benyou Wang},
year={2024},
eprint={2410.10626},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2410.10626},
}
- Downloads last month
- 3