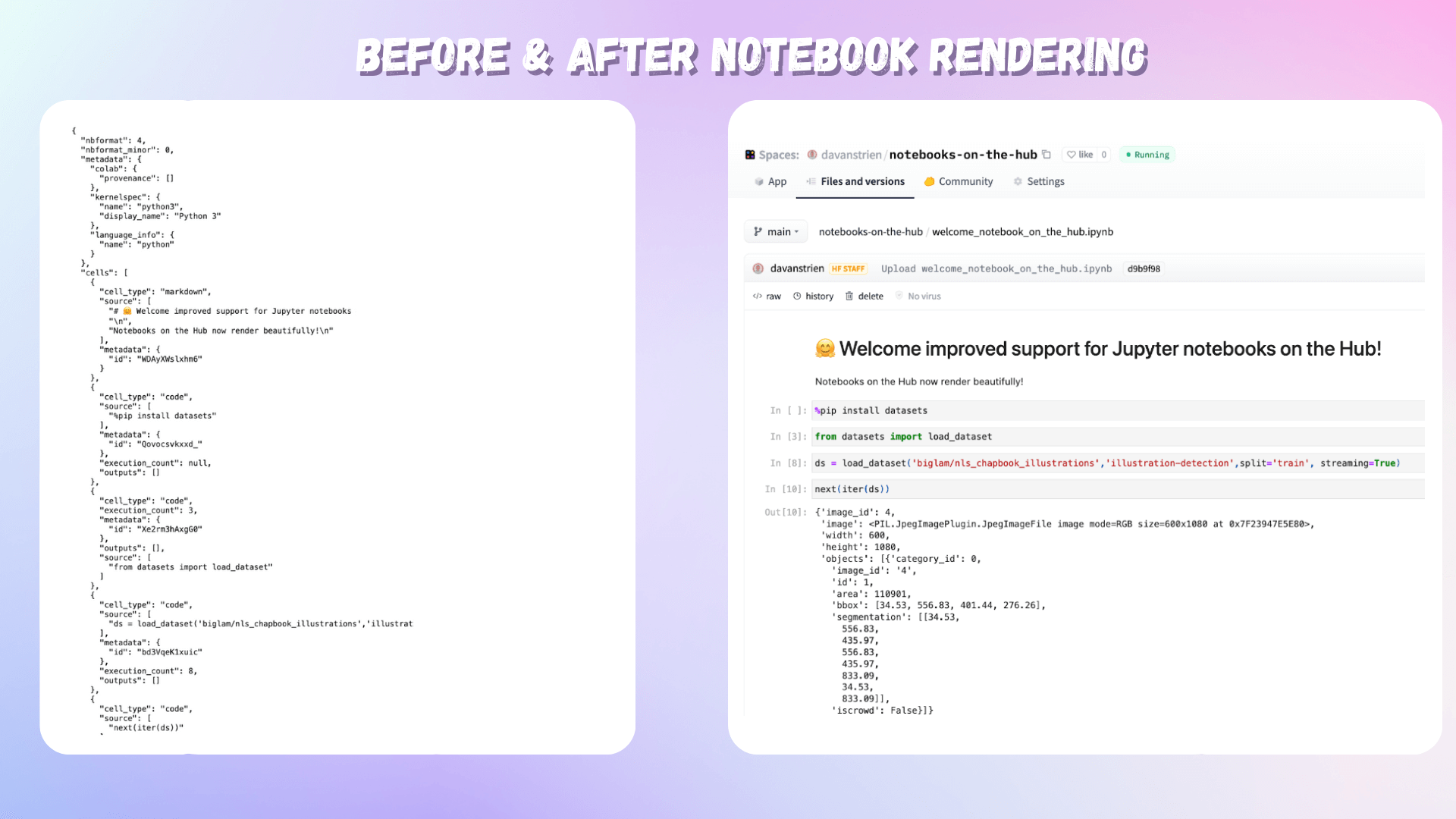
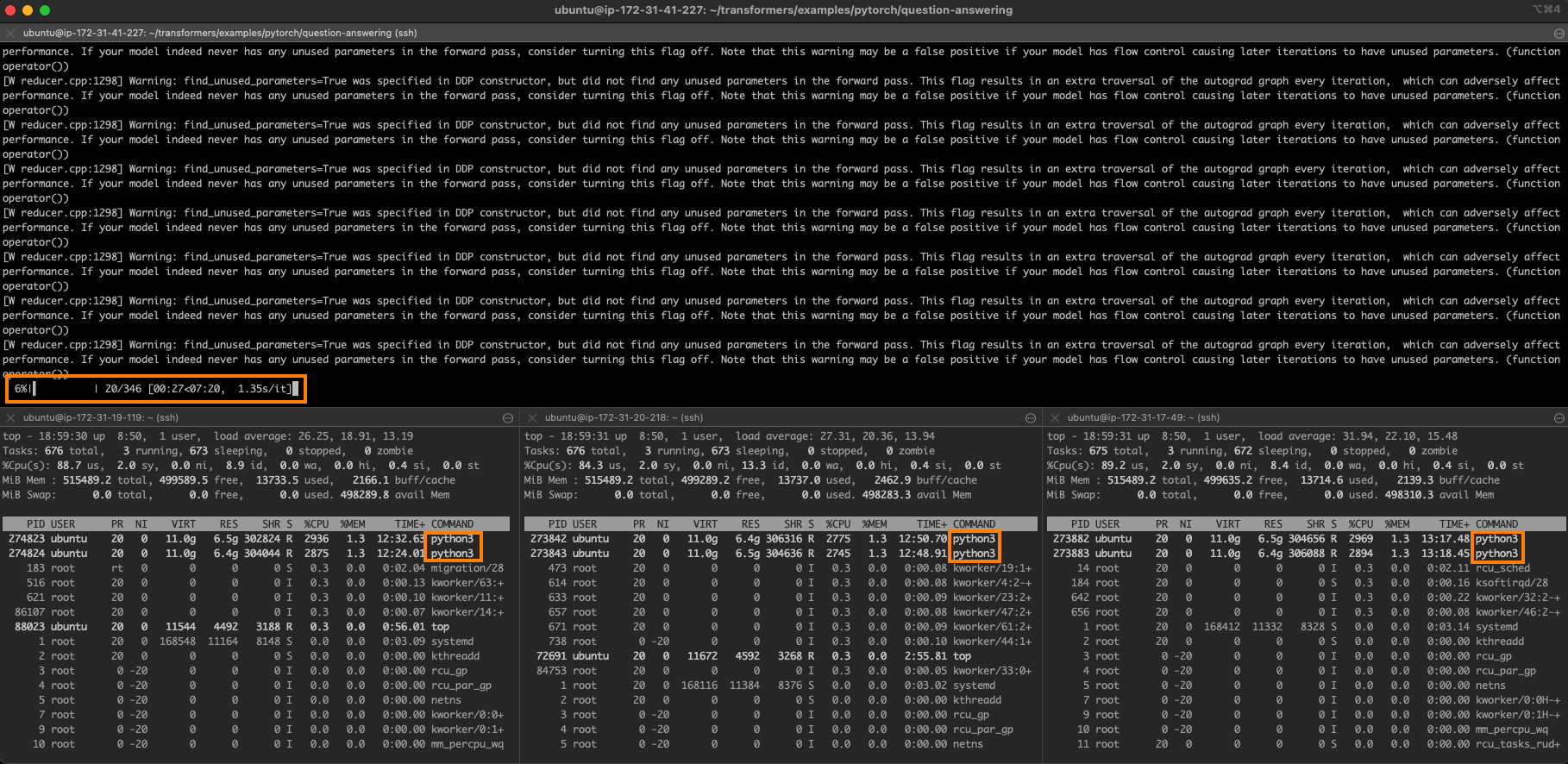
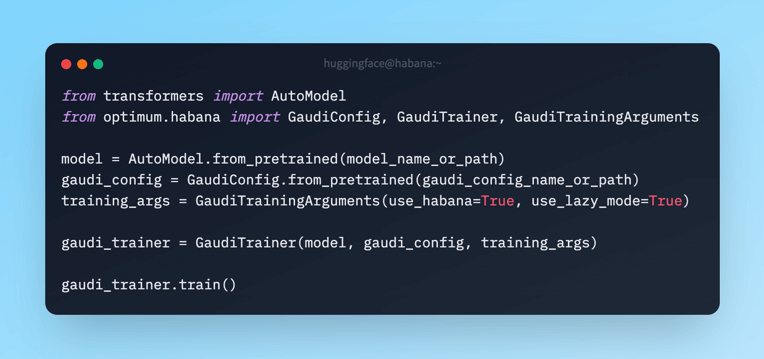
Can we create pedagogically valuable multi-turn synthetic datasets from Cosmopedia? By davanstrien • about 2 hours ago • 2
Evalverse: Revolutionizing Large Language Model Evaluation with a Unified, User-Friendly Framework By Yescia • about 3 hours ago
A Guide to Designing New Functional Proteins and Improving Protein Function, Stability, and Diversity with Generative AI By AmelieSchreiber • 6 days ago • 11
Token Merging for fast LLM inference : Background and first trials with Mistral By samchain • 7 days ago • 1
Estimating Memory Consumption of LLMs for Inference and Fine-Tuning for Cohere Command-R+ By Andyrasika • 11 days ago • 4
Post-OCR-Correction: 1 billion words dataset of automated OCR correction by LLM By Pclanglais • 11 days ago • 9
Can we create pedagogically valuable multi-turn synthetic datasets from Cosmopedia? By davanstrien • about 2 hours ago • 2
Evalverse: Revolutionizing Large Language Model Evaluation with a Unified, User-Friendly Framework By Yescia • about 3 hours ago
A Guide to Designing New Functional Proteins and Improving Protein Function, Stability, and Diversity with Generative AI By AmelieSchreiber • 6 days ago • 11
Token Merging for fast LLM inference : Background and first trials with Mistral By samchain • 7 days ago • 1
Estimating Memory Consumption of LLMs for Inference and Fine-Tuning for Cohere Command-R+ By Andyrasika • 11 days ago • 4
Post-OCR-Correction: 1 billion words dataset of automated OCR correction by LLM By Pclanglais • 11 days ago • 9