Graphcore and Hugging Face Launch New Lineup of IPU-Ready Transformers



Graphcore and Hugging Face have significantly expanded the range of Machine Learning modalities and tasks available in Hugging Face Optimum, an open-source library for Transformers performance optimization. Developers now have convenient access to a wide range of off-the-shelf Hugging Face Transformer models, optimised to deliver the best possible performance on Graphcore’s IPU.
Including the BERT transformer model made available shortly after Optimum Graphcore launched, developers can now access 10 models covering Natural Language Processing (NLP), Speech and Computer Vision, which come with IPU configuration files and ready-to-use pre-trained and fine-tuned model weights.
New Optimum models
Computer vision
ViT (Vision Transformer) is a breakthrough in image recognition that uses the transformer mechanism as its main component. When images are input to ViT, they're divided into small patches similar to how words are processed in language systems. Each patch is encoded by the Transformer (Embedding) and then can be processed individually.
NLP
GPT-2 (Generative Pre-trained Transformer 2) is a text generation transformer model pretrained on a very large corpus of English data in a self-supervised fashion. This means it was pretrained on the raw texts only, with no humans labelling them in any way (which is why it can use lots of publicly available data) with an automatic process to generate inputs and labels from those texts. More precisely, it is trained to generate texts from a prompt by guessing the next word in sentences.
RoBERTa (Robustly optimized BERT approach) is a transformer model that (like GPT-2) is pretrained on a large corpus of English data in a self-supervised fashion. More precisely, RoBERTa it was pretrained with the masked language modeling (MLM) objective. Taking a sentence, the model randomly masks 15% of the words in the input then runs the entire masked sentence through the model and has to predict the masked words. Roberta can be used for masked language modeling, but is mostly intended to be fine-tuned on a downstream task.
DeBERTa (Decoding-enhanced BERT with disentangled attention) is a pretrained neural language model for NLP tasks. DeBERTa adapts the 2018 BERT and 2019 RoBERTa models using two novel techniques—a disentangled attention mechanism and an enhanced mask decoder—significantly improving the efficiency of model pretraining and performance of downstream tasks.
BART is a transformer encoder-encoder (seq2seq) model with a bidirectional (BERT-like) encoder and an autoregressive (GPT-like) decoder. BART is pre-trained by (1) corrupting text with an arbitrary noising function, and (2) learning a model to reconstruct the original text. BART is particularly effective when fine-tuned for text generation (e.g. summarization, translation) but also works well for comprehension tasks (e.g. text classification, question answering).
LXMERT (Learning Cross-Modality Encoder Representations from Transformers) is a multimodal transformer model for learning vision and language representations. It has three encoders: object relationship encoder, a language encoder, and a cross-modality encoder. It is pretrained via a combination of masked language modeling, visual-language text alignment, ROI-feature regression, masked visual-attribute modeling, masked visual-object modeling, and visual-question answering objectives. It has achieved state-of-the-art results on the VQA and GQA visual-question-answering datasets.
T5 (Text-to-Text Transfer Transformer) is a revolutionary new model that can take any text and convert it into a machine learning format for translation, question answering or classification. It introduces a unified framework that converts all text-based language problems into a text-to-text format for transfer learning. By doing so, it has simplified a way to use the same model, objective function, hyperparameters, and decoding procedure across a diverse set of NLP tasks.
Speech
HuBERT (Hidden-Unit BERT) is a self-supervised speech recognition model pretrained on audio, learning a combined acoustic and language model over continuous inputs. The HuBERT model either matches or improves upon the state-of-the-art wav2vec 2.0 performance on the Librispeech (960h) and Libri-light (60,000h) benchmarks with 10min, 1h, 10h, 100h, and 960h fine-tuning subsets.
Wav2Vec2 is a pretrained self-supervised model for automatic speech recognition. Using a novel contrastive pretraining objective, Wav2Vec2 learns powerful speech representations from large amounts of unlabelled speech data, followed by fine-tuning on a small amount of transcribed speech data, outperforming the best semi-supervised methods while being conceptually simpler.
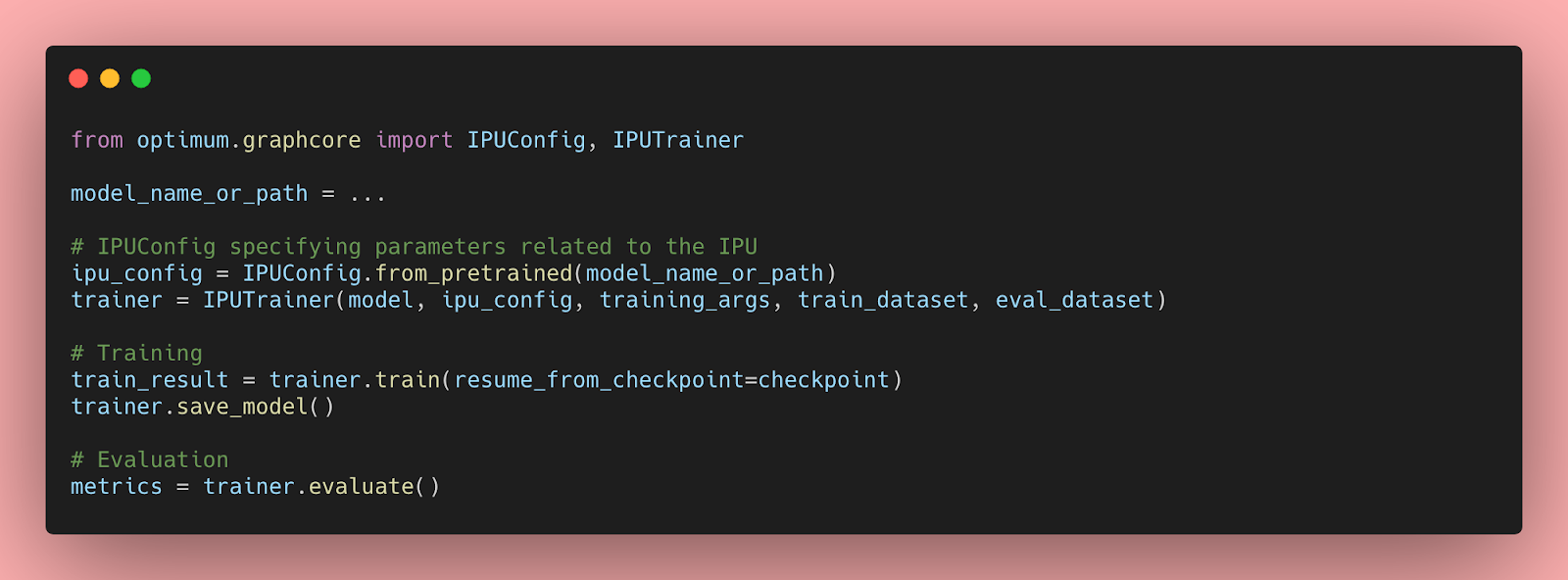
Hugging Face Optimum Graphcore: building on a solid partnership
Graphcore joined the Hugging Face Hardware Partner Program in 2021 as a founding member, with both companies sharing the common goal of lowering the barriers for innovators seeking to harness the power of machine intelligence.
Since then, Graphcore and Hugging Face have worked together extensively to make training of transformer models on IPUs fast and easy, with the first Optimum Graphcore model (BERT) being made available last year.
Transformers have proven to be extremely efficient for a wide range of functions, including feature extraction, text generation, sentiment analysis, translation and many more. Models like BERT are widely used by Graphcore customers in a huge array of applications including cybersecurity, voice call automation, drug discovery, and translation.
Optimizing their performance in the real world requires considerable time, effort and skills that are beyond the reach of many companies and organizations. In providing an open-source library of transformer models, Hugging Face has directly addressed these issues. Integrating IPUs with HuggingFace also allows developers to leverage not just the models, but also datasets available in the HuggingFace Hub.
Developers can now use Graphcore systems to train 10 different types of state-of-the-art transformer models and access thousands of datasets with minimal coding complexity. With this partnership, we are providing users with the tools and ecosystem to easily download and fine-tune state-of-the-art pretrained models to various domains and downstream tasks.
Bringing Graphcore’s latest hardware and software to the table
While members of Hugging Face’s ever-expanding user base have already been able to benefit from the speed, performance, and power- and cost-efficiency of IPU technology, a combination of recent hardware and software releases from Graphcore will unlock even more potential.
On the hardware front, the Bow IPU — announced in March and now shipping to customers — is the first processor in the world to use Wafer-on-Wafer (WoW) 3D stacking technology, taking the well-documented benefits of the IPU to the next level. Featuring ground-breaking advances in compute architecture and silicon implementation, communication and memory, each Bow IPU delivers up to 350 teraFLOPS of AI compute—an impressive 40% increase in performance—and up to 16% more power efficiency compared to the previous generation IPU. Importantly, Hugging Face Optimum users can switch seamlessly from previous generation IPUs to Bow processors, as no code changes are required.
Software also plays a vital role in unlocking the IPU’s capabilities, so naturally Optimum offers a plug-and-play experience with Graphcore’s easy-to-use Poplar SDK — which itself has received a major 2.5 update. Poplar makes it easy to train state-of-the-art models on state-of-the-art hardware, thanks to its full integration with standard machine learning frameworks, including PyTorch, PyTorch Lightning, and TensorFlow—as well as orchestration and deployment tools such as Docker and Kubernetes. Making Poplar compatible with these widely used, third-party systems allows developers to easily port their models from their other compute platforms and start taking advantage of the IPU’s advanced AI capabilities.
Get started with Hugging Face’s Optimum Graphcore models
If you’re interested in combining the benefits of IPU technology with the strengths of transformer models, you can download the latest range of Optimum Graphcore models from the Graphcore organization on the Hub, or access the code from the Optimum GitHub repo. Our Getting Started blog post will guide you through each step to start experimenting with IPUs.
Additionally, Graphcore has built an extensive page of developer resources, where you can find the IPU Model Garden—a repository of deployment-ready ML applications including computer vision, NLP, graph networks and more—alongside an array of documentation, tutorials, how-to-videos, webinars, and more. You can also access Graphcore’s GitHub repo for more code references and tutorials.
To learn more about using Hugging Face on Graphcore, head over to our partner page!