Kakao Brain’s Open Source ViT, ALIGN, and the New COYO Text-Image Dataset









Kakao Brain and Hugging Face are excited to release a new open-source image-text dataset COYO of 700 million pairs and two new visual language models trained on it, ViT and ALIGN. This is the first time ever the ALIGN model is made public for free and open-source use and the first release of ViT and ALIGN models that come with the train dataset.
Kakao Brain’s ViT and ALIGN models follow the same architecture and hyperparameters as provided in the original respective Google models but are trained on the open source COYO dataset. Google’s ViT and ALIGN models, while trained on huge datasets (ViT trained on 300 million images and ALIGN trained on 1.8 billion image-text pairs respectively), cannot be replicated because the datasets are not public. This contribution is particularly valuable to researchers who want to reproduce visual language modeling with access to the data as well. More detailed information on the Kakao ViT and ALIGN models can be found here.
This blog will introduce the new COYO dataset, Kakao Brain's ViT and ALIGN models, and how to use them! Here are the main takeaways:
- First open-source ALIGN model ever!
- First open ViT and ALIGN models that have been trained on an open-source dataset COYO
- Kakao Brain's ViT and ALIGN models perform on par with the Google versions
- ViT and ALIGN demos are available on HF! You can play with the ViT and ALIGN demos online with image samples of your own choice!
Performance Comparison
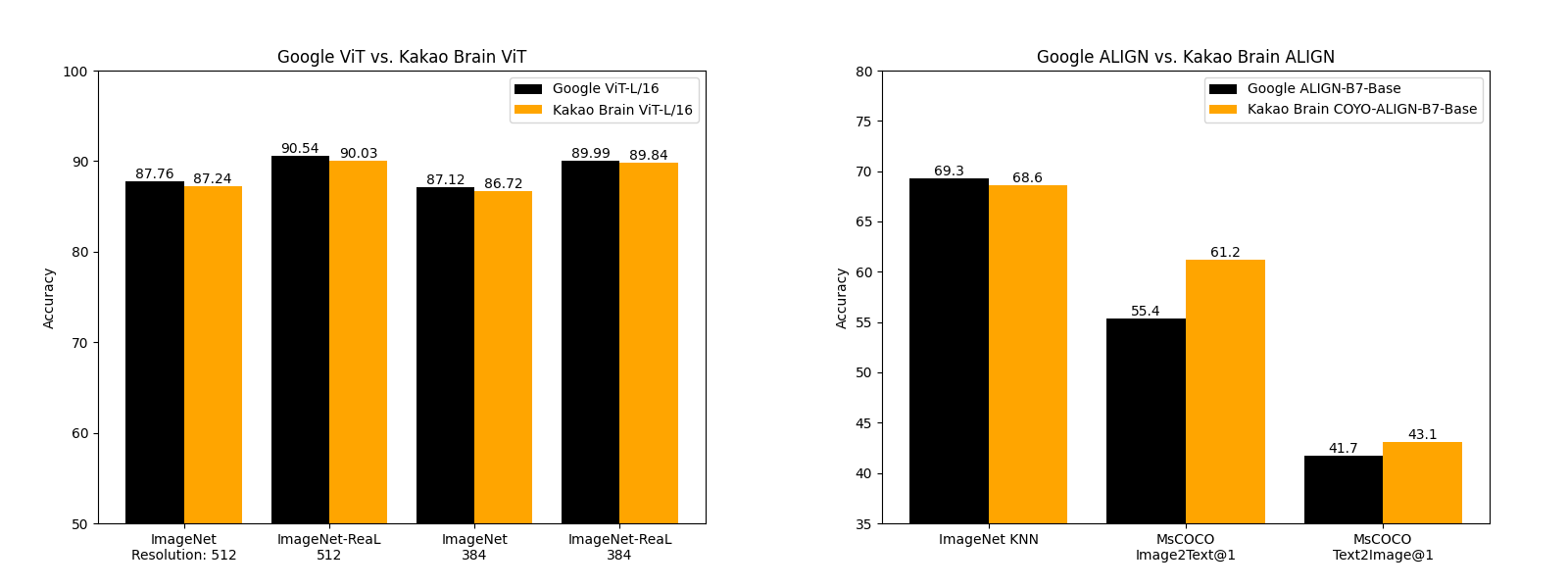
Kakao Brain's released ViT and ALIGN models perform on par and sometimes better than what Google has reported about their implementation. Kakao Brain's ALIGN-B7-Base model, while trained on much fewer pairs (700 million pairs vs 1.8 billion), performs on par with Google's ALIGN-B7-Base on the Image KNN classification task and better on MS-COCO retrieval image-to-text, text-to-image tasks. Kakao Brain's ViT-L/16 performs similarly to Google's ViT-L/16 when evaluated on ImageNet and ImageNet-ReaL at model resolutions 384 and 512. This means the community can use Kakao Brain's ViT and ALIGN models to replicate Google's ViT and ALIGN releases especially when users require access to the training data. We are excited to see open-source and transparent releases of these models that perform on par with the state of the art!
COYO DATASET

What's special about these model releases is that the models are trained on the free and accessible COYO dataset. COYO is an image-text dataset of 700 million pairs similar to Google's ALIGN 1.8B image-text dataset which is a collection of "noisy" alt-text and image pairs from webpages, but open-source. COYO-700M and ALIGN 1.8B are "noisy" because minimal filtering was applied. COYO is similar to the other open-source image-text dataset, LAION but with the following differences. While LAION 2B is a much larger dataset of 2 billion English pairs, compared to COYO’s 700 million pairs, COYO pairs come with more metadata that give users more flexibility and finer-grained control over usage. The following table shows the differences: COYO comes equipped with aesthetic scores for all pairs, more robust watermark scores, and face count data.
| COYO | LAION 2B | ALIGN 1.8B |
|---|---|---|
| Image-text similarity score calculated with CLIP ViT-B/32 and ViT-L/14 models, they are provided as metadata but nothing is filtered out so as to avoid possible elimination bias | Image-text similarity score provided with CLIP (ViT-B/32) - only examples above threshold 0.28 | Minimal, Frequency based filtering |
| NSFW filtering on images and text | NSFW filtering on images | Google Cloud API |
| Face recognition (face count) data provided as meta-data | No face recognition data | NA |
| 700 million pairs all English | 2 billion English | 1.8 billion |
| From CC 2020 Oct - 2021 Aug | From CC 2014-2020 | NA |
| Aesthetic Score | Aesthetic Score Partial | NA |
| More robust Watermark score | Watermark Score | NA |
| Hugging Face Hub | Hugging Face Hub | Not made public |
| English | English | English? |
How ViT and ALIGN work
So what do these models do? Let's briefly discuss how the ViT and ALIGN models work.
ViT -- Vision Transformer -- is a vision model proposed by Google in 2020 that resembles the text Transformer architecture. It is a new approach to vision, distinct from convolutional neural nets (CNNs) that have dominated vision tasks since 2012's AlexNet. It is upto four times more computationally efficient than similarly performing CNNs and domain agnostic. ViT takes as input an image which is broken up into a sequence of image patches - just as the text Transformer takes as input a sequence of text - and given position embeddings to each patch to learn the image structure. ViT performance is notable in particular for having an excellent performance-compute trade-off. While some of Google's ViT models are open-source, the JFT-300 million image-label pair dataset they were trained on has not been released publicly. While Kakao Brain's trained on COYO-Labeled-300M, which has been released publicly, and released ViT model performs similarly on various tasks, its code, model, and training data(COYO-Labeled-300M) are made entirely public for reproducibility and open science.
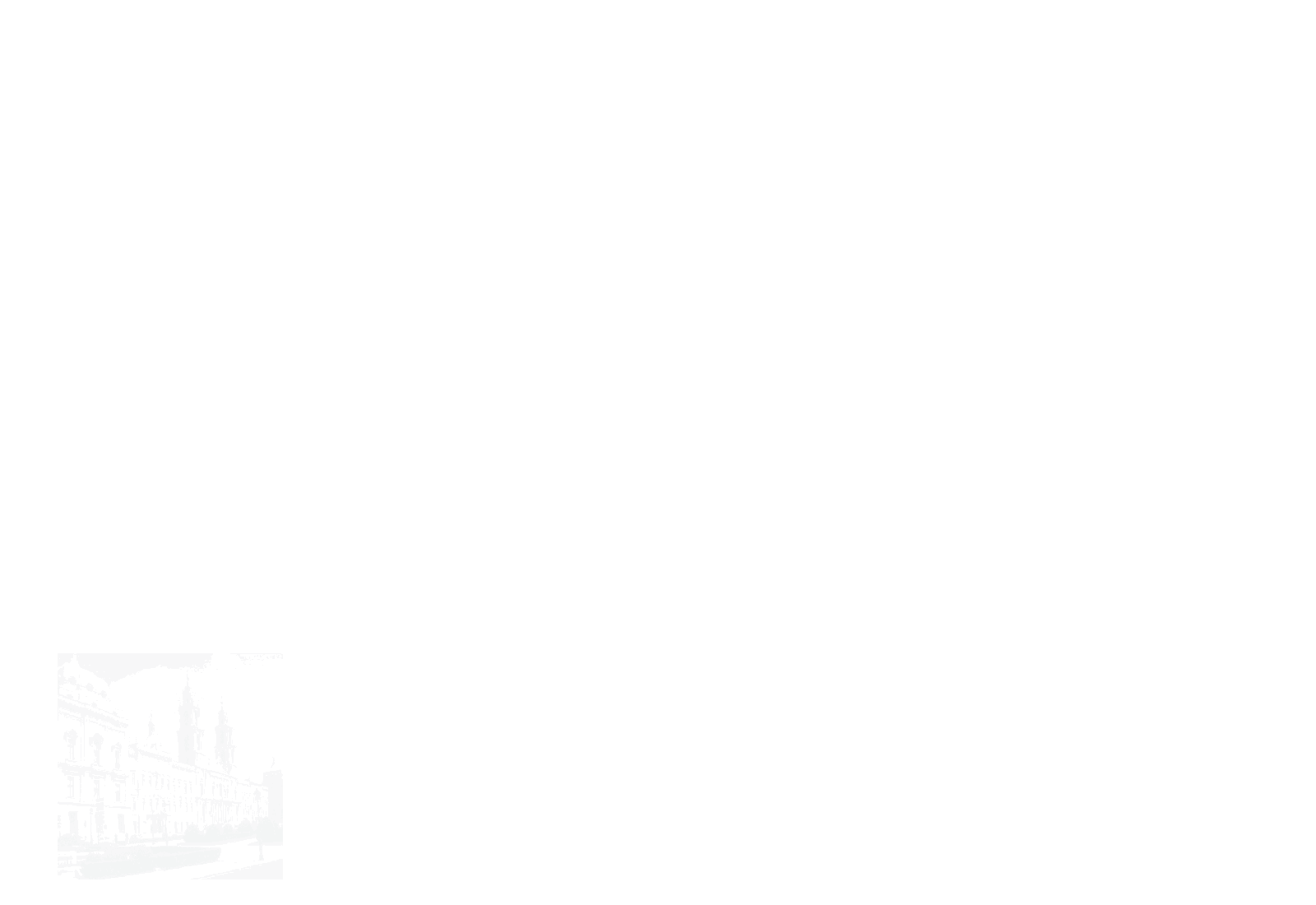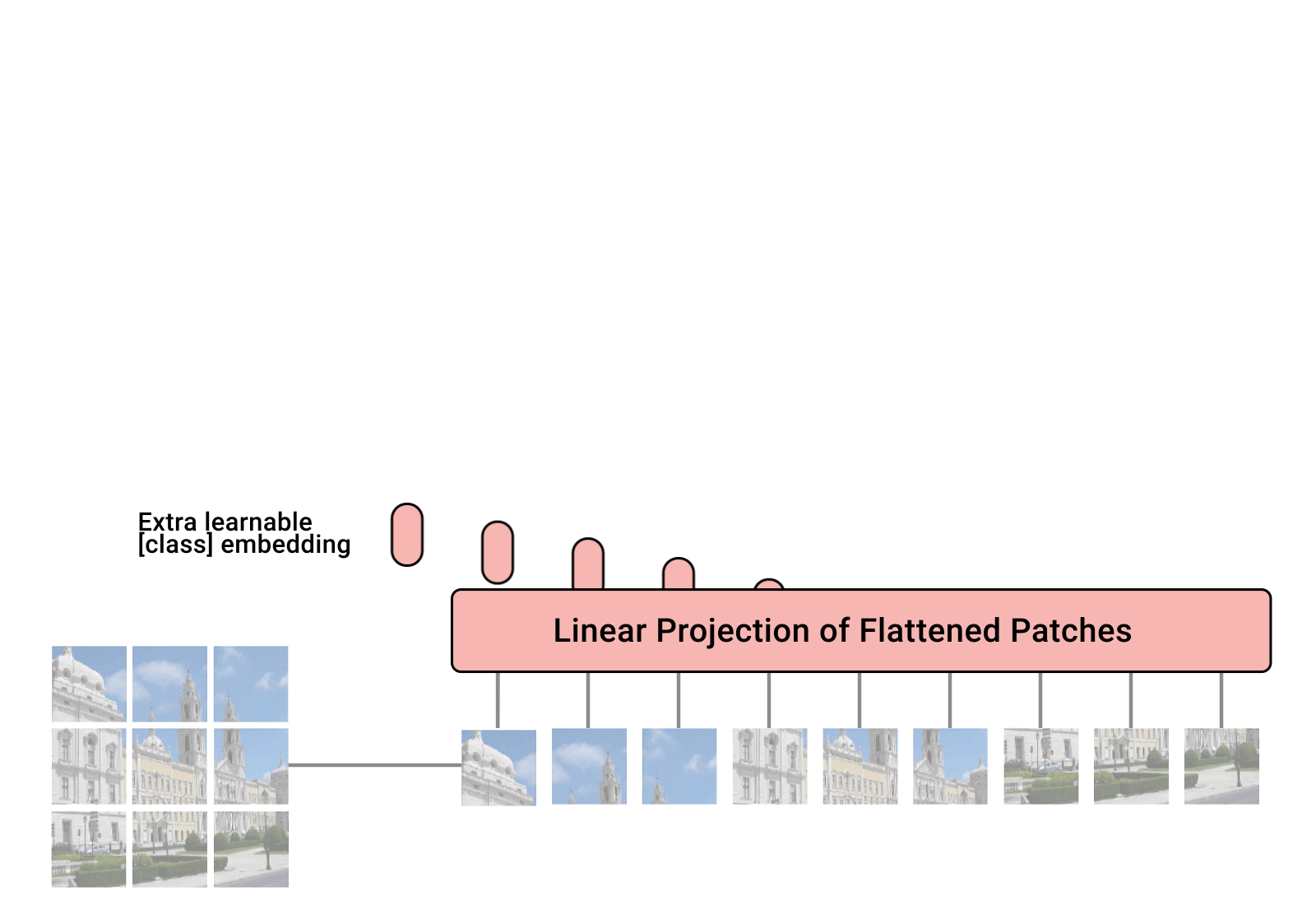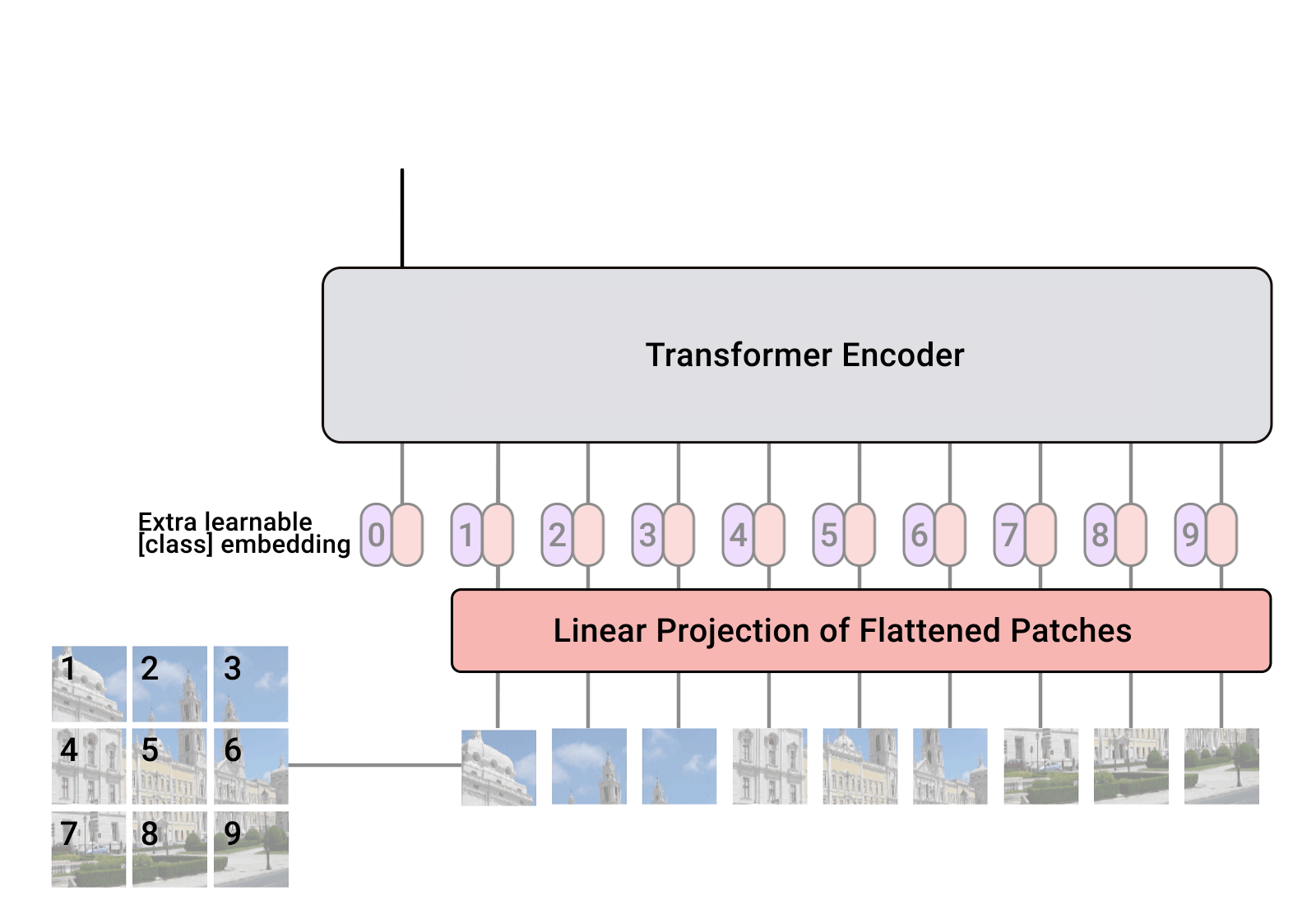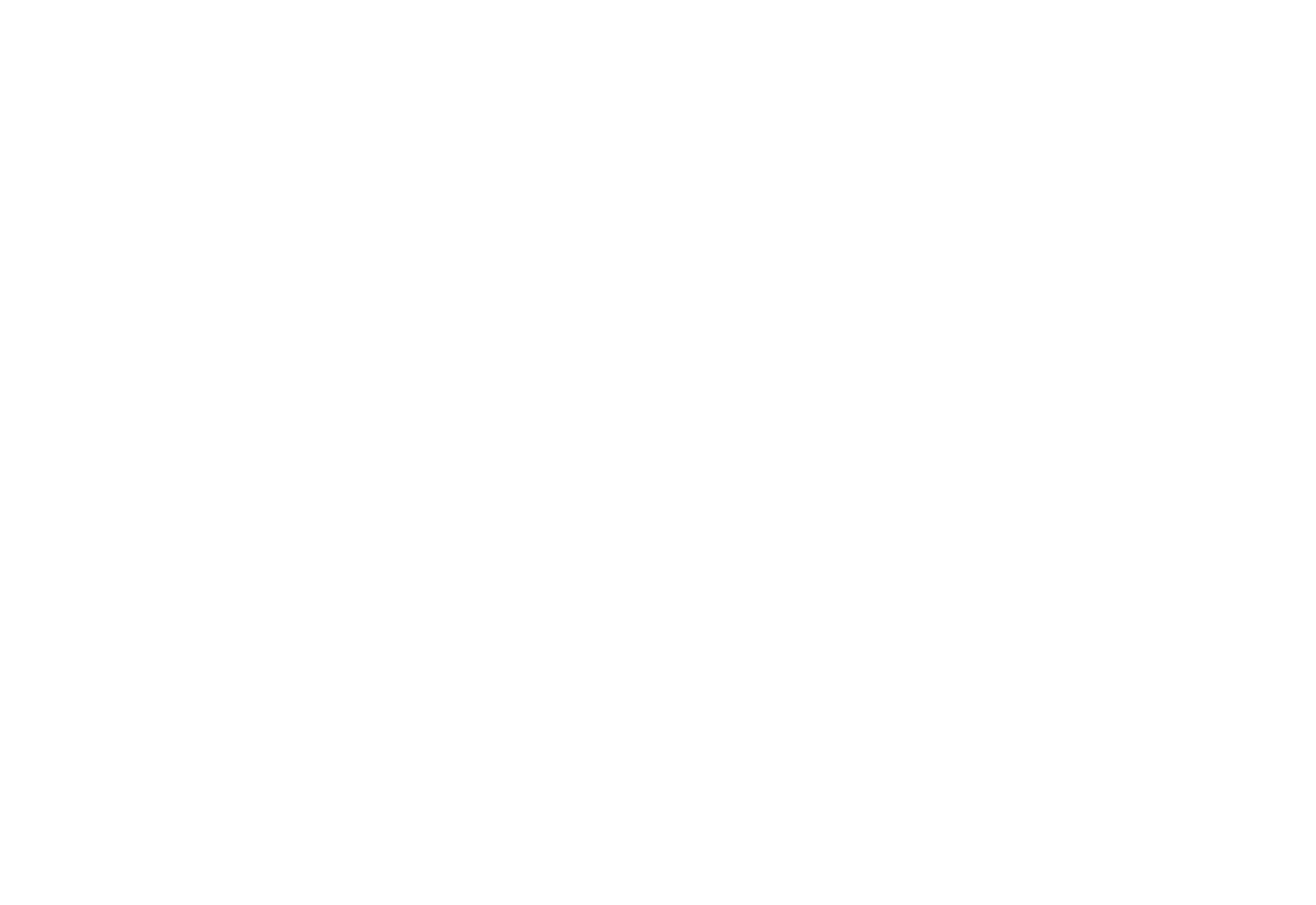
Google then introduced ALIGN -- a Large-scale Image and Noisy Text Embedding model in 2021 -- a visual-language model trained on "noisy" text-image data for various vision and cross-modal tasks such as text-image retrieval. ALIGN has a simple dual-encoder architecture trained on image and text pairs, learned via a contrastive loss function. ALIGN's "noisy" training corpus is notable for balancing scale and robustness. Previously, visual language representational learning had been trained on large-scale datasets with manual labels, which require extensive preprocessing. ALIGN's corpus uses the image alt-text data, text that appears when the image fails to load, as the caption to the image -- resulting in an inevitably noisy, but much larger (1.8 billion pair) dataset that allows ALIGN to perform at SoTA levels on various tasks. Kakao Brain's ALIGN is the first open-source version of this model, trained on the COYO dataset and performs better than Google's reported results.

How to use the COYO dataset
We can conveniently download the COYO dataset with a single line of code using the 🤗 Datasets library. To preview the COYO dataset and learn more about the data curation process and the meta attributes included, head over to the dataset page on the hub or the original Git repository. To get started, let's install the 🤗 Datasets library: pip install datasets and download it.
>>> from datasets import load_dataset
>>> dataset = load_dataset('kakaobrain/coyo-700m')
>>> dataset
While it is significantly smaller than the LAION dataset, the COYO dataset is still massive with 747M image-text pairs and it might be unfeasible to download the whole dataset to your local. In order to download only a subset of the dataset, we can simply pass in the streaming=True argument to the load_dataset() method to create an iterable dataset and download data instances as we go.
>>> from datasets import load_dataset
>>> dataset = load_dataset('kakaobrain/coyo-700m', streaming=True)
>>> print(next(iter(dataset['train'])))
{'id': 2680060225205, 'url': 'https://cdn.shopify.com/s/files/1/0286/3900/2698/products/TVN_Huile-olive-infuse-et-s-227x300_e9a90ffd-b6d2-4118-95a1-29a5c7a05a49_800x.jpg?v=1616684087', 'text': 'Olive oil infused with Tuscany herbs', 'width': 227, 'height': 300, 'image_phash': '9f91e133b1924e4e', 'text_length': 36, 'word_count': 6, 'num_tokens_bert': 6, 'num_tokens_gpt': 9, 'num_faces': 0, 'clip_similarity_vitb32': 0.19921875, 'clip_similarity_vitl14': 0.147216796875, 'nsfw_score_opennsfw2': 0.0058441162109375, 'nsfw_score_gantman': 0.018961310386657715, 'watermark_score': 0.11015450954437256, 'aesthetic_score_laion_v2': 4.871710777282715}
How to use ViT and ALIGN from the Hub
Let’s go ahead and experiment with the new ViT and ALIGN models. As ALIGN is newly added to 🤗 Transformers, we will install the latest version of the library: pip install -q git+https://github.com/huggingface/transformers.git and get started with ViT for image classification by importing the modules and libraries we will use. Note that the newly added ALIGN model will be a part of the PyPI package in the next release of the library.
import requests
from PIL import Image
import torch
from transformers import ViTImageProcessor, ViTForImageClassification
Next, we will download a random image of two cats and remote controls on a couch from the COCO dataset and preprocess the image to transform it to the input format expected by the model. To do this, we can conveniently use the corresponding preprocessor class (ViTProcessor). To initialize the model and the preprocessor, we will use one of the Kakao Brain ViT repos on the hub. Note that initializing the preprocessor from a repository ensures that the preprocessed image is in the expected format required by that specific pretrained model.
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(requests.get(url, stream=True).raw)
processor = ViTImageProcessor.from_pretrained('kakaobrain/vit-large-patch16-384')
model = ViTForImageClassification.from_pretrained('kakaobrain/vit-large-patch16-384')
The rest is simple, we will forward preprocess the image and use it as input to the model to retrieve the class logits. The Kakao Brain ViT image classification models are trained on ImageNet labels and output logits of shape (batch_size, 1000).
# preprocess image or list of images
inputs = processor(images=image, return_tensors="pt")
# inference
with torch.no_grad():
outputs = model(**inputs)
# apply SoftMax to logits to compute the probability of each class
preds = torch.nn.functional.softmax(outputs.logits, dim=-1)
# print the top 5 class predictions and their probabilities
top_class_preds = torch.argsort(preds, descending=True)[0, :5]
for c in top_class_preds:
print(f"{model.config.id2label[c.item()]} with probability {round(preds[0, c.item()].item(), 4)}")
And we are done! To make things even easier and shorter, we can also use the convenient image classification pipeline and pass the Kakao Brain ViT repo name as our target model to initialize the pipeline. We can then pass in a URL or a local path to an image or a Pillow image and optionally use the top_k argument to return the top k predictions. Let's go ahead and get the top 5 predictions for our image of cats and remotes.
>>> from transformers import pipeline
>>> classifier = pipeline(task='image-classification', model='kakaobrain/vit-large-patch16-384')
>>> classifier('http://images.cocodataset.org/val2017/000000039769.jpg', top_k=5)
[{'score': 0.8223727941513062, 'label': 'remote control, remote'}, {'score': 0.06580372154712677, 'label': 'tabby, tabby cat'}, {'score': 0.0655883178114891, 'label': 'tiger cat'}, {'score': 0.0388941615819931, 'label': 'Egyptian cat'}, {'score': 0.0011215205304324627, 'label': 'lynx, catamount'}]
If you want to experiment more with the Kakao Brain ViT model, head over to its Space on the 🤗 Hub.
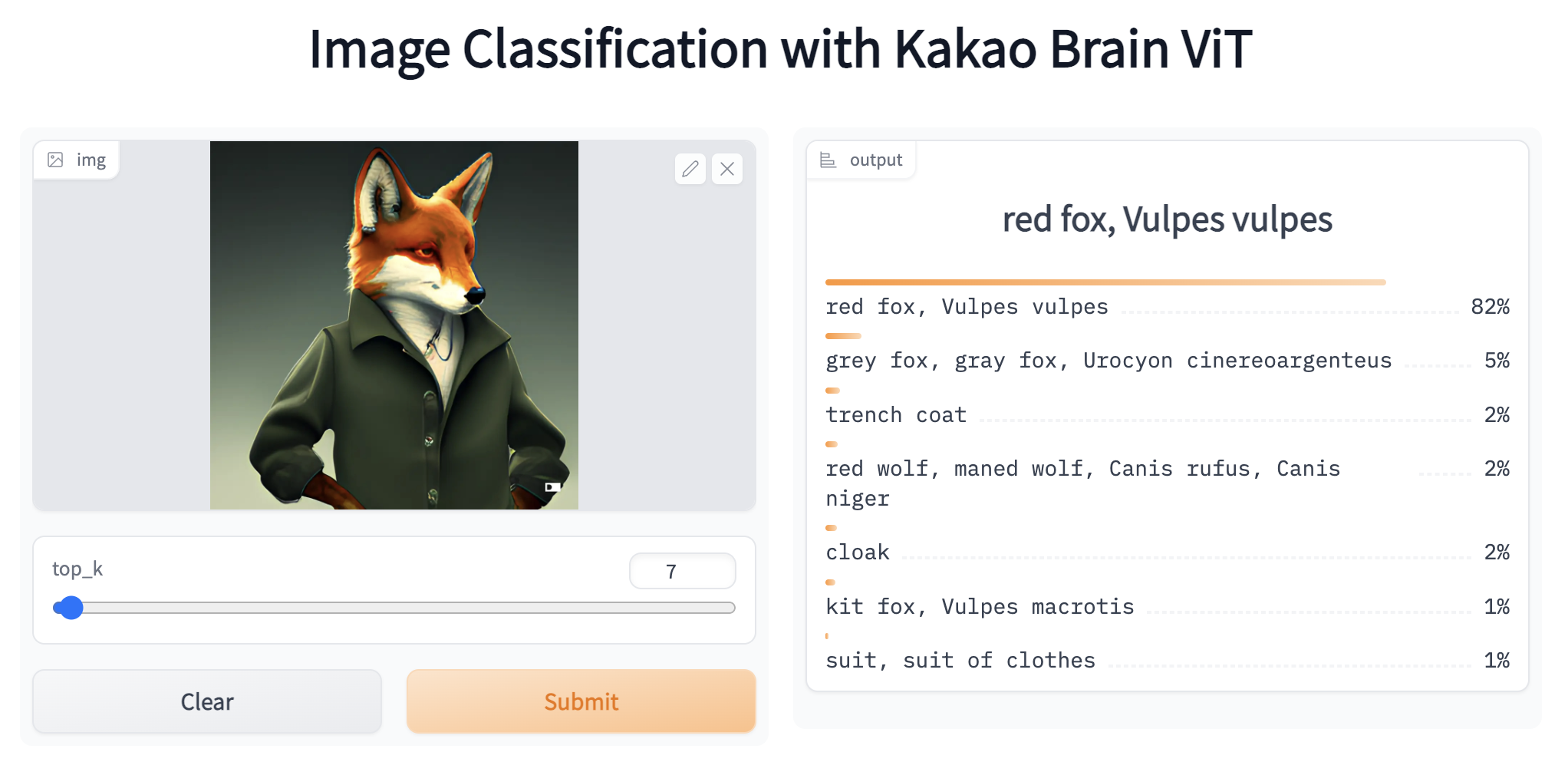
Let's move on to experimenting with ALIGN, which can be used to retrieve multi-modal embeddings of texts or images or to perform zero-shot image classification. ALIGN's transformers implementation and usage is similar to CLIP. To get started, we will first download the pretrained model and its processor, which can preprocess both the images and texts such that they are in the expected format to be fed into the vision and text encoders of ALIGN. Once again, let's import the modules we will use and initialize the preprocessor and the model.
import requests
from PIL import Image
import torch
from transformers import AlignProcessor, AlignModel
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(requests.get(url, stream=True).raw)
processor = AlignProcessor.from_pretrained('kakaobrain/align-base')
model = AlignModel.from_pretrained('kakaobrain/align-base')
We will start with zero-shot image classification first. To do this, we will supply candidate labels (free-form text) and use AlignModel to find out which description better describes the image. We will first preprocess both the image and text inputs and feed the preprocessed input to the AlignModel.
candidate_labels = ['an image of a cat', 'an image of a dog']
inputs = processor(images=image, text=candidate_labels, return_tensors='pt')
with torch.no_grad():
outputs = model(**inputs)
# this is the image-text similarity score
logits_per_image = outputs.logits_per_image
# we can take the softmax to get the label probabilities
probs = logits_per_image.softmax(dim=1)
print(probs)
Done, easy as that. To experiment more with the Kakao Brain ALIGN model for zero-shot image classification, simply head over to its demo on the 🤗 Hub. Note that, the output of AlignModel includes text_embeds and image_embeds (see the documentation of ALIGN). If we don't need to compute the per-image and per-text logits for zero-shot classification, we can retrieve the vision and text embeddings using the convenient get_image_features() and get_text_features() methods of the AlignModel class.
text_embeds = model.get_text_features(
input_ids=inputs['input_ids'],
attention_mask=inputs['attention_mask'],
token_type_ids=inputs['token_type_ids'],
)
image_embeds = model.get_image_features(
pixel_values=inputs['pixel_values'],
)
Alternatively, we can use the stand-along vision and text encoders of ALIGN to retrieve multi-modal embeddings. These embeddings can then be used to train models for various downstream tasks such as object detection, image segmentation and image captioning. Let's see how we can retrieve these embeddings using AlignTextModel and AlignVisionModel. Note that we can use the convenient AlignProcessor class to preprocess texts and images separately.
from transformers import AlignTextModel
processor = AlignProcessor.from_pretrained('kakaobrain/align-base')
model = AlignTextModel.from_pretrained('kakaobrain/align-base')
# get embeddings of two text queries
inputs = processor(['an image of a cat', 'an image of a dog'], return_tensors='pt')
with torch.no_grad():
outputs = model(**inputs)
# get the last hidden state and the final pooled output
last_hidden_state = outputs.last_hidden_state
pooled_output = outputs.pooler_output
We can also opt to return all hidden states and attention values by setting the output_hidden_states and output_attentions arguments to True during inference.
with torch.no_grad():
outputs = model(**inputs, output_hidden_states=True, output_attentions=True)
# print what information is returned
for key, value in outputs.items():
print(key)
Let's do the same with AlignVisionModel and retrieve the multi-modal embedding of an image.
from transformers import AlignVisionModel
processor = AlignProcessor.from_pretrained('kakaobrain/align-base')
model = AlignVisionModel.from_pretrained('kakaobrain/align-base')
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(requests.get(url, stream=True).raw)
inputs = processor(images=image, return_tensors='pt')
with torch.no_grad():
outputs = model(**inputs)
# print the last hidden state and the final pooled output
last_hidden_state = outputs.last_hidden_state
pooled_output = outputs.pooler_output
Similar to ViT, we can use the zero-shot image classification pipeline to make our work even easier. Let's see how we can use this pipeline to perform image classification in the wild using free-form text candidate labels.
>>> from transformers import pipeline
>>> classifier = pipeline(task='zero-shot-image-classification', model='kakaobrain/align-base')
>>> classifier(
... 'https://huggingface.co/datasets/Narsil/image_dummy/raw/main/parrots.png',
... candidate_labels=['animals', 'humans', 'landscape'],
... )
[{'score': 0.9263709783554077, 'label': 'animals'}, {'score': 0.07163811475038528, 'label': 'humans'}, {'score': 0.0019908479880541563, 'label': 'landscape'}]
>>> classifier(
... 'https://huggingface.co/datasets/Narsil/image_dummy/raw/main/parrots.png',
... candidate_labels=['black and white', 'photorealist', 'painting'],
... )
[{'score': 0.9735308885574341, 'label': 'black and white'}, {'score': 0.025493400171399117, 'label': 'photorealist'}, {'score': 0.0009757201769389212, 'label': 'painting'}]
Conclusion
There have been incredible advances in multi-modal models in recent years, with models such as CLIP and ALIGN unlocking various downstream tasks such as image captioning, zero-shot image classification, and open vocabulary object detection. In this blog, we talked about the latest open source ViT and ALIGN models contributed to the Hub by Kakao Brain, as well as the new COYO text-image dataset. We also showed how you can use these models to perform various tasks with a few lines of code both on their own or as a part of 🤗 Transformers pipelines.
That was it! We are continuing to integrate the most impactful computer vision and multi-modal models and would love to hear back from you. To stay up to date with the latest news in computer vision and multi-modal research, you can follow us on Twitter: @adirik, @a_e_roberts, @NielsRogge, @RisingSayak, and @huggingface.