Getting Started with Transformers on Habana Gaudi

A couple of weeks ago, we've had the pleasure to announce that Habana Labs and Hugging Face would partner to accelerate Transformer model training.
Habana Gaudi accelerators deliver up to 40% better price performance for training machine learning models compared to the latest GPU-based Amazon EC2 instances. We are super excited to bring this price performance advantages to Transformers 🚀
In this hands-on post, I'll show you how to quickly set up a Habana Gaudi instance on Amazon Web Services, and then fine-tune a BERT model for text classification. As usual, all code is provided so that you may reuse it in your projects.
Let's get started!
Setting up an Habana Gaudi instance on AWS
The simplest way to work with Habana Gaudi accelerators is to launch an Amazon EC2 DL1 instance. These instances are equipped with 8 Habana Gaudi processors that can easily be put to work thanks to the Habana Deep Learning Amazon Machine Image (AMI). This AMI comes preinstalled with the Habana SynapseAI® SDK, and the tools required to run Gaudi accelerated Docker containers. If you'd like to use other AMIs or containers, instructions are available in the Habana documentation.
Starting from the EC2 console in the us-east-1 region, I first click on Launch an instance and define a name for the instance ("habana-demo-julsimon").
Then, I search the Amazon Marketplace for Habana AMIs.
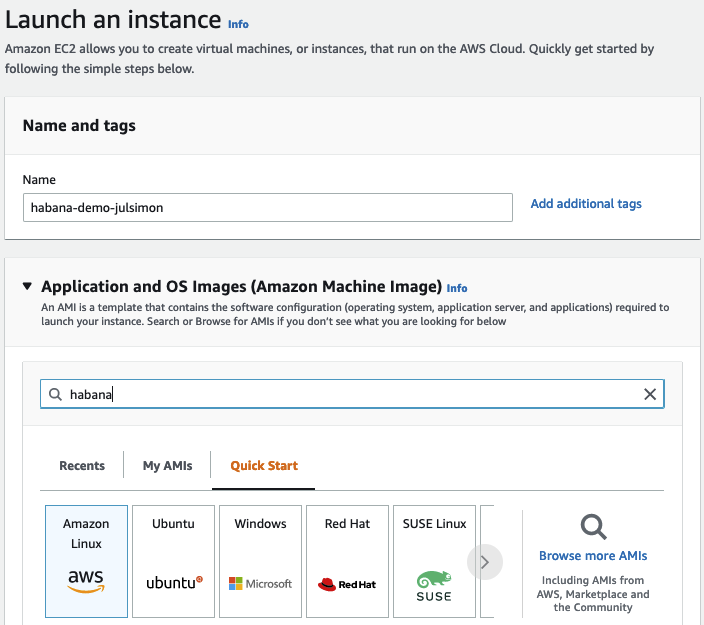
I pick the Habana Deep Learning Base AMI (Ubuntu 20.04).
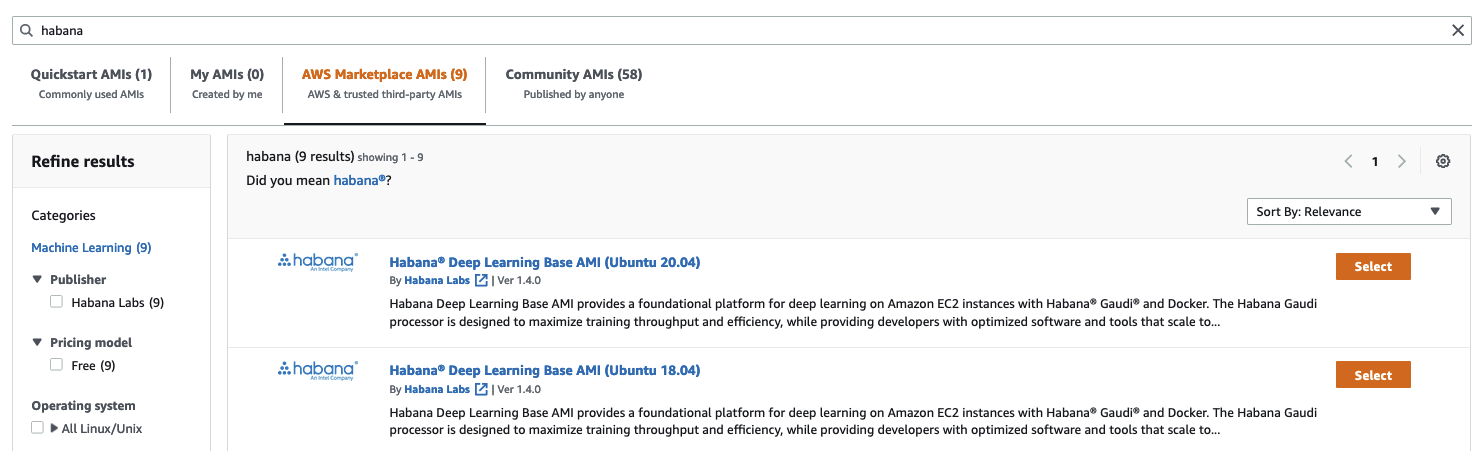
Next, I pick the dl1.24xlarge instance size (the only size available).
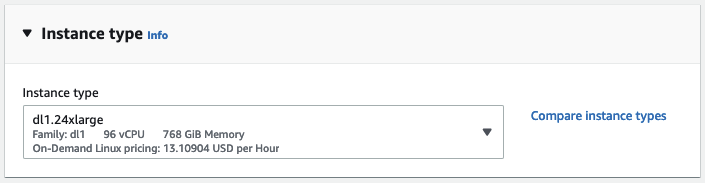
Then, I select the keypair that I'll use to connect to the instance with ssh. If you don't have a keypair, you can create one in place.
As a next step, I make sure that the instance allows incoming ssh traffic. I do not restrict the source address for simplicity, but you should definitely do it in your account.

By default, this AMI will start an instance with 8GB of Amazon EBS storage, which won't be enough here. I bump storage to 50GB.
Next, I assign an Amazon IAM role to the instance. In real life, this role should have the minimum set of permissions required to run your training job, such as the ability to read data from one of your Amazon S3 buckets. This role is not needed here as the dataset will be downloaded from the Hugging Face hub. If you're not familiar with IAM, I highly recommend reading the Getting Started documentation.
Then, I ask EC2 to provision my instance as a Spot Instance, a great way to reduce the $13.11 per hour cost.
Finally, I launch the instance. A couple of minutes later, the instance is ready and I can connect to it with ssh. Windows users can do the same with PuTTY by following the documentation.
ssh -i ~/.ssh/julsimon-keypair.pem ubuntu@ec2-18-207-189-109.compute-1.amazonaws.com
On this instance, the last setup step is to pull the Habana container for PyTorch, which is the framework I'll use to fine-tune my model. You can find information on other prebuilt containers and on how to build your own in the Habana documentation.
docker pull \
vault.habana.ai/gaudi-docker/1.5.0/ubuntu20.04/habanalabs/pytorch-installer-1.11.0:1.5.0-610
Once the image has been pulled to the instance, I run it in interactive mode.
docker run -it \
--runtime=habana \
-e HABANA_VISIBLE_DEVICES=all \
-e OMPI_MCA_btl_vader_single_copy_mechanism=none \
--cap-add=sys_nice \
--net=host \
--ipc=host vault.habana.ai/gaudi-docker/1.5.0/ubuntu20.04/habanalabs/pytorch-installer-1.11.0:1.5.0-610
I'm now ready to fine-tune my model.
Fine-tuning a text classification model on Habana Gaudi
I first clone the Optimum Habana repository inside the container I've just started.
git clone https://github.com/huggingface/optimum-habana.git
Then, I install the Optimum Habana package from source.
cd optimum-habana
pip install .
Then, I move to the subdirectory containing the text classification example and install the required Python packages.
cd examples/text-classification
pip install -r requirements.txt
I can now launch the training job, which downloads the bert-large-uncased-whole-word-masking model from the Hugging Face hub, and fine-tunes it on the MRPC task of the GLUE benchmark.
Please note that I'm fetching the Habana Gaudi configuration for BERT from the Hugging Face hub, and you could also use your own. In addition, other popular models are supported, and you can find their configuration file in the Habana organization.
python run_glue.py \
--model_name_or_path bert-large-uncased-whole-word-masking \
--gaudi_config_name Habana/bert-large-uncased-whole-word-masking \
--task_name mrpc \
--do_train \
--do_eval \
--per_device_train_batch_size 32 \
--learning_rate 3e-5 \
--num_train_epochs 3 \
--max_seq_length 128 \
--use_habana \
--use_lazy_mode \
--output_dir ./output/mrpc/
After 2 minutes and 12 seconds, the job is complete and has achieved an excellent F1 score of 0.9181, which could certainly improve with more epochs.
***** train metrics *****
epoch = 3.0
train_loss = 0.371
train_runtime = 0:02:12.85
train_samples = 3668
train_samples_per_second = 82.824
train_steps_per_second = 2.597
***** eval metrics *****
epoch = 3.0
eval_accuracy = 0.8505
eval_combined_score = 0.8736
eval_f1 = 0.8968
eval_loss = 0.385
eval_runtime = 0:00:06.45
eval_samples = 408
eval_samples_per_second = 63.206
eval_steps_per_second = 7.901
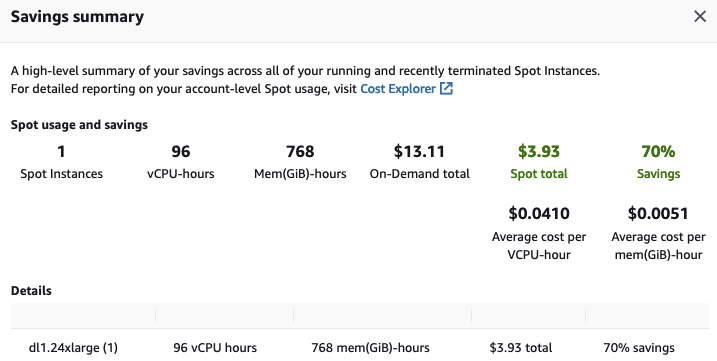
Last but not least, I terminate the EC2 instance to avoid unnecessary charges. Looking at the Savings Summary in the EC2 console, I see that I saved 70% thanks to Spot Instances, paying only $3.93 per hour instead of $13.11.
As you can see, the combination of Transformers, Habana Gaudi, and AWS instances is powerful, simple, and cost-effective. Give it a try and let us know what you think. We definitely welcome your questions and feedback on the Hugging Face Forum.
Please reach out to Habana to learn more about training Hugging Face models on Gaudi processors.

