Introducing Würstchen: Fast Diffusion for Image Generation












What is Würstchen?
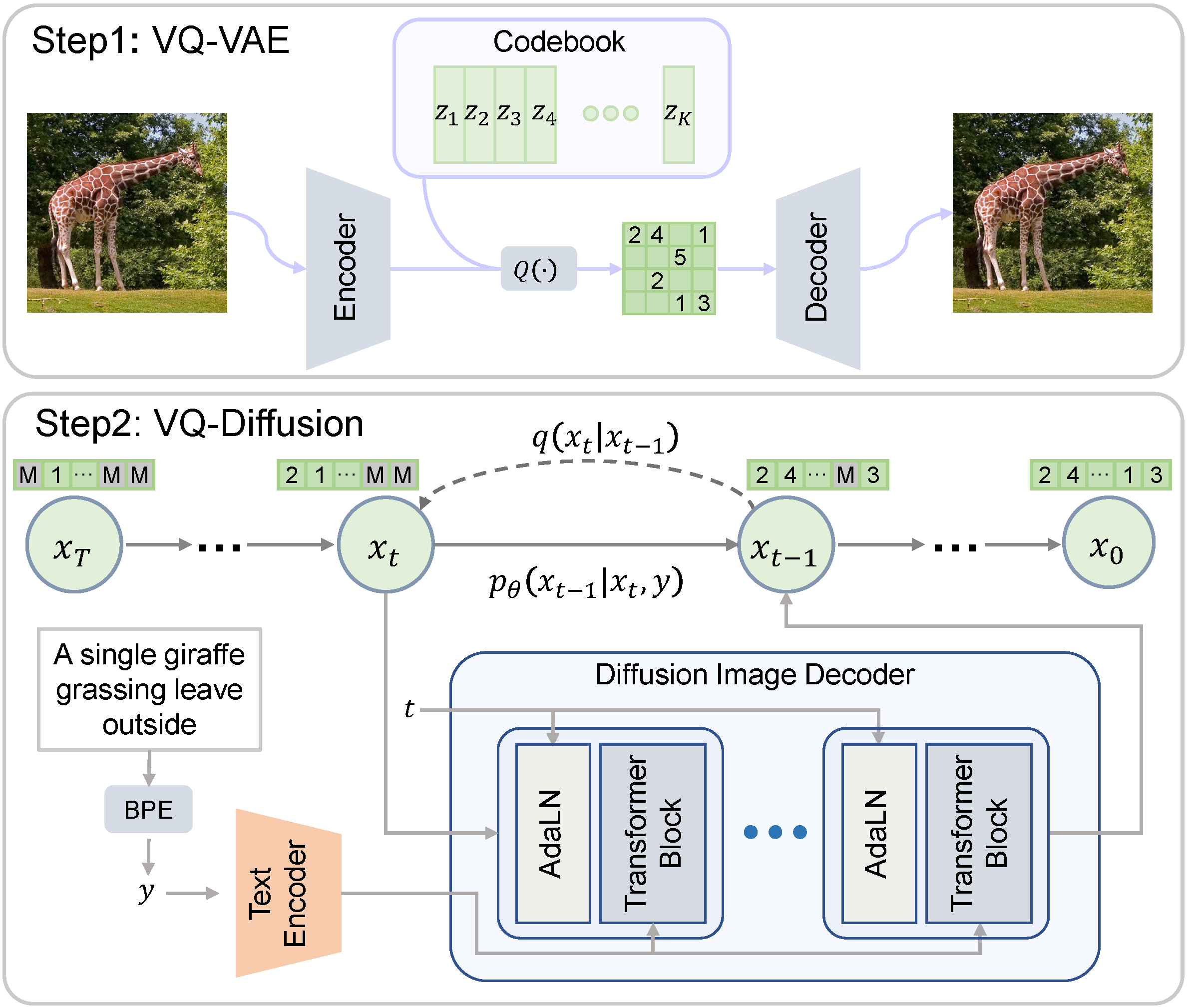
Würstchen is a diffusion model, whose text-conditional component works in a highly compressed latent space of images. Why is this important? Compressing data can reduce computational costs for both training and inference by orders of magnitude. Training on 1024×1024 images is way more expensive than training on 32×32. Usually, other works make use of a relatively small compression, in the range of 4x - 8x spatial compression. Würstchen takes this to an extreme. Through its novel design, it achieves a 42x spatial compression! This had never been seen before, because common methods fail to faithfully reconstruct detailed images after 16x spatial compression. Würstchen employs a two-stage compression, what we call Stage A and Stage B. Stage A is a VQGAN, and Stage B is a Diffusion Autoencoder (more details can be found in the paper). Together Stage A and B are called the Decoder, because they decode the compressed images back into pixel space. A third model, Stage C, is learned in that highly compressed latent space. This training requires fractions of the compute used for current top-performing models, while also allowing cheaper and faster inference. We refer to Stage C as the Prior.

Why another text-to-image model?
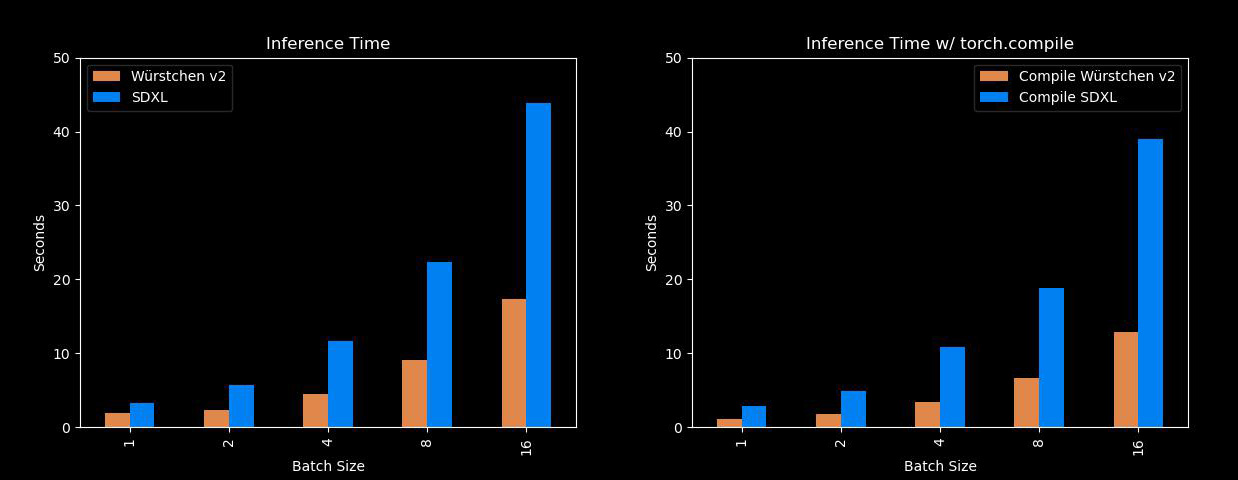
Well, this one is pretty fast and efficient. Würstchen’s biggest benefits come from the fact that it can generate images much faster than models like Stable Diffusion XL, while using a lot less memory! So for all of us who don’t have A100s lying around, this will come in handy. Here is a comparison with SDXL over different batch sizes:
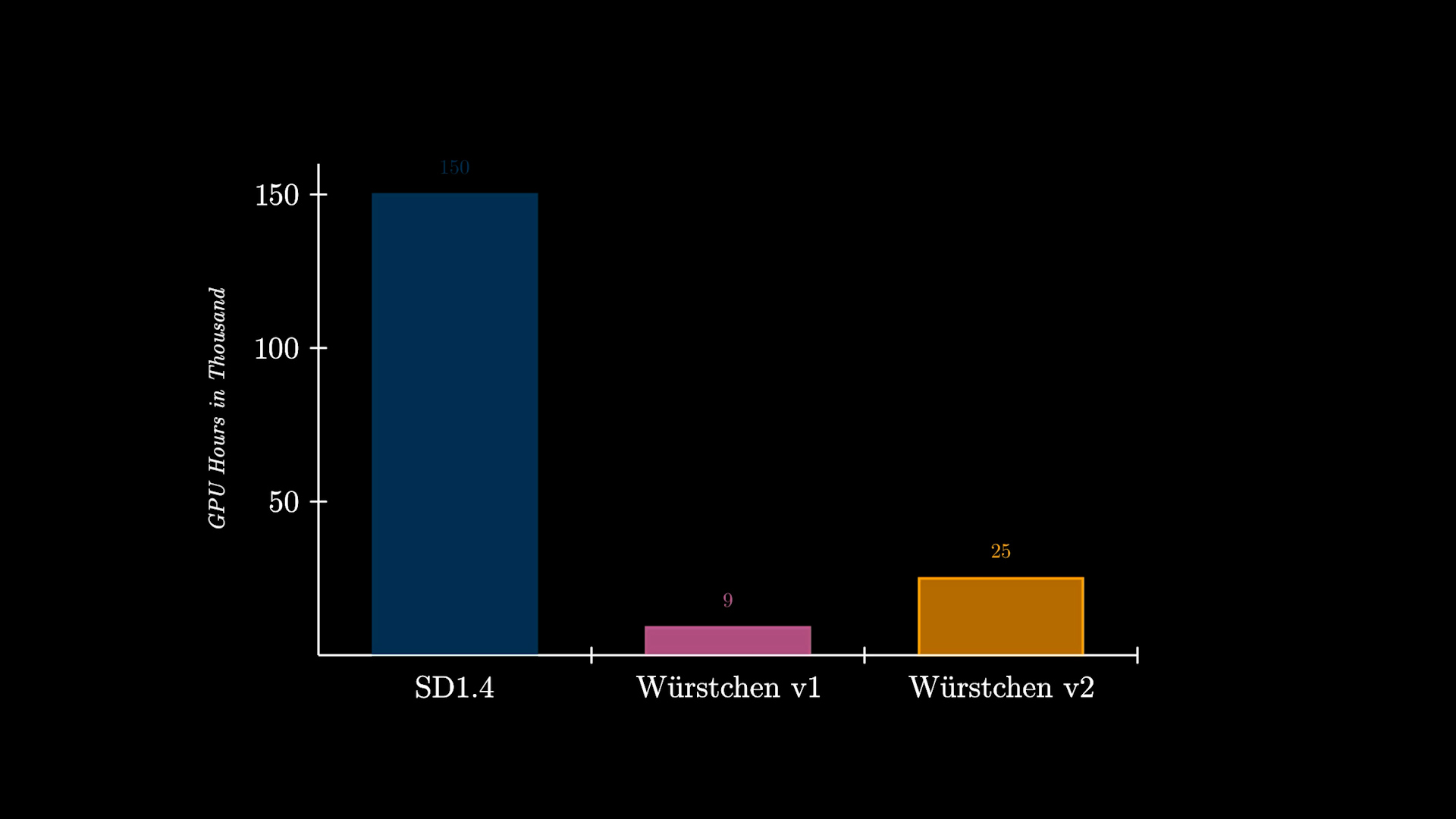
In addition to that, another greatly significant benefit of Würstchen comes with the reduced training costs. Würstchen v1, which works at 512x512, required only 9,000 GPU hours of training. Comparing this to the 150,000 GPU hours spent on Stable Diffusion 1.4 suggests that this 16x reduction in cost not only benefits researchers when conducting new experiments, but it also opens the door for more organizations to train such models. Würstchen v2 used 24,602 GPU hours. With resolutions going up to 1536, this is still 6x cheaper than SD1.4, which was only trained at 512x512.
You can also find a detailed explanation video here:
How to use Würstchen?
You can either try it using the Demo here:
Otherwise, the model is available through the Diffusers Library, so you can use the interface you are already familiar with. For example, this is how to run inference using the AutoPipeline:
import torch
from diffusers import AutoPipelineForText2Image
from diffusers.pipelines.wuerstchen import DEFAULT_STAGE_C_TIMESTEPS
pipeline = AutoPipelineForText2Image.from_pretrained("warp-ai/wuerstchen", torch_dtype=torch.float16).to("cuda")
caption = "Anthropomorphic cat dressed as a firefighter"
images = pipeline(
caption,
height=1024,
width=1536,
prior_timesteps=DEFAULT_STAGE_C_TIMESTEPS,
prior_guidance_scale=4.0,
num_images_per_prompt=4,
).images

What image sizes does Würstchen work on?
Würstchen was trained on image resolutions between 1024x1024 & 1536x1536. We sometimes also observe good outputs at resolutions like 1024x2048. Feel free to try it out.
We also observed that the Prior (Stage C) adapts extremely fast to new resolutions. So finetuning it at 2048x2048 should be computationally cheap.

Models on the Hub
All checkpoints can also be seen on the Huggingface Hub. Multiple checkpoints, as well as future demos and model weights can be found there. Right now there are 3 checkpoints for the Prior available and 1 checkpoint for the Decoder. Take a look at the documentation where the checkpoints are explained and what the different Prior models are and can be used for.
Diffusers integration
Because Würstchen is fully integrated in diffusers, it automatically comes with various goodies and optimizations out of the box. These include:
- Automatic use of PyTorch 2
SDPAaccelerated attention, as described below. - Support for the xFormers flash attention implementation, if you need to use PyTorch 1.x instead of 2.
- Model offload, to move unused components to CPU while they are not in use. This saves memory with negligible performance impact.
- Sequential CPU offload, for situations where memory is really precious. Memory use will be minimized, at the cost of slower inference.
- Prompt weighting with the Compel library.
- Support for the
mpsdevice on Apple Silicon macs. - Use of generators for reproducibility.
- Sensible defaults for inference to produce high-quality results in most situations. Of course you can tweak all parameters as you wish!
Optimisation Technique 1: Flash Attention
Starting from version 2.0, PyTorch has integrated a highly optimised and resource-friendly version of the attention mechanism called torch.nn.functional.scaled_dot_product_attention or SDPA. Depending on the nature of the input, this function taps into multiple underlying optimisations. Its performance and memory efficiency outshine the traditional attention model. Remarkably, the SDPA function mirrors the characteristics of the flash attention technique, as highlighted in the research paper Fast and Memory-Efficient Exact Attention with IO-Awareness penned by Dao and team.
If you're using Diffusers with PyTorch 2.0 or a later version, and the SDPA function is accessible, these enhancements are automatically applied. Get started by setting up torch 2.0 or a newer version using the official guidelines!
images = pipeline(caption, height=1024, width=1536, prior_timesteps=DEFAULT_STAGE_C_TIMESTEPS, prior_guidance_scale=4.0, num_images_per_prompt=4).images
For an in-depth look at how diffusers leverages SDPA, check out the documentation.
If you're on a version of Pytorch earlier than 2.0, you can still achieve memory-efficient attention using the xFormers library:
pipeline.enable_xformers_memory_efficient_attention()
Optimisation Technique 2: Torch Compile
If you're on the hunt for an extra performance boost, you can make use of torch.compile. It is best to apply it to both the prior's
and decoder's main model for the biggest increase in performance.
pipeline.prior_prior = torch.compile(pipeline.prior_prior , mode="reduce-overhead", fullgraph=True)
pipeline.decoder = torch.compile(pipeline.decoder, mode="reduce-overhead", fullgraph=True)
Bear in mind that the initial inference step will take a long time (up to 2 minutes) while the models are being compiled. After that you can just normally run inference:
images = pipeline(caption, height=1024, width=1536, prior_timesteps=DEFAULT_STAGE_C_TIMESTEPS, prior_guidance_scale=4.0, num_images_per_prompt=4).images
And the good news is that this compilation is a one-time execution. Post that, you're set to experience faster inferences consistently for the same image resolutions. The initial time investment in compilation is quickly offset by the subsequent speed benefits. For a deeper dive into torch.compile and its nuances, check out the official documentation.
How was the model trained?
The ability to train this model was only possible through compute resources provided by Stability AI. We wanna say a special thank you to Stability for giving us the possibility to pursue this kind of research, with the chance to make it accessible to so many more people!
Resources
- Further information about this model can be found in the official diffusers documentation.
- All the checkpoints can be found on the hub
- You can try out the demo here.
- Join our Discord if you want to discuss future projects or even contribute with your own ideas!
- Training code and more can be found in the official GitHub repository