Open-Source Text Generation & LLM Ecosystem at Hugging Face





[Updated on July 24, 2023: Added Llama 2.]
Text generation and conversational technologies have been around for ages. Earlier challenges in working with these technologies were controlling both the coherence and diversity of the text through inference parameters and discriminative biases. More coherent outputs were less creative and closer to the original training data and sounded less human. Recent developments overcame these challenges, and user-friendly UIs enabled everyone to try these models out. Services like ChatGPT have recently put the spotlight on powerful models like GPT-4 and caused an explosion of open-source alternatives like Llama to go mainstream. We think these technologies will be around for a long time and become more and more integrated into everyday products.
This post is divided into the following sections:
- Brief background on text generation
- Licensing
- Tools in the Hugging Face Ecosystem for LLM Serving
- Parameter Efficient Fine Tuning (PEFT)
Brief Background on Text Generation
Text generation models are essentially trained with the objective of completing an incomplete text or generating text from scratch as a response to a given instruction or question. Models that complete incomplete text are called Causal Language Models, and famous examples are GPT-3 by OpenAI and Llama by Meta AI.
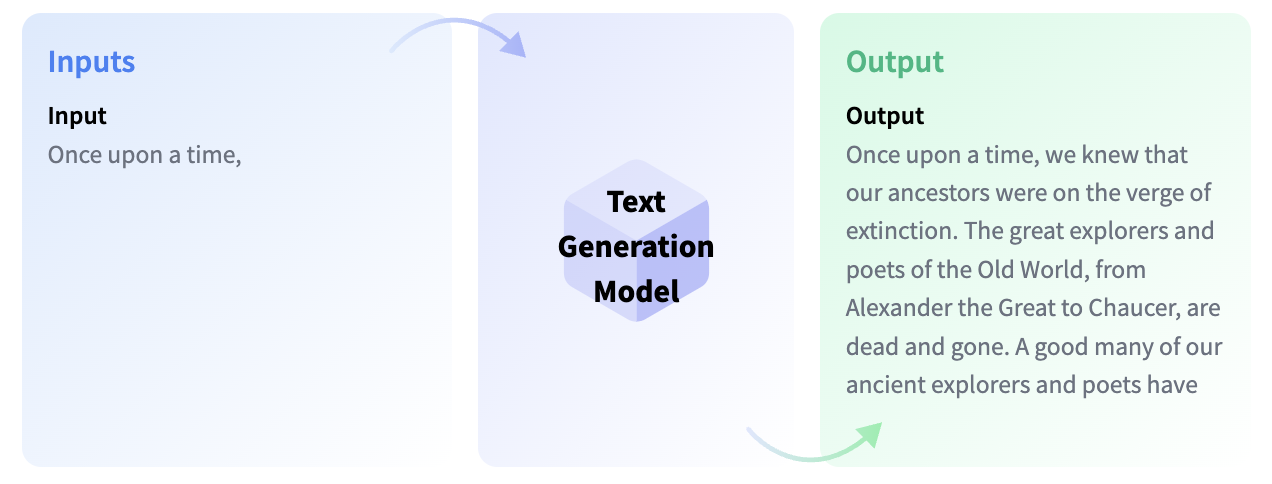
One concept you need to know before we move on is fine-tuning. This is the process of taking a very large model and transferring the knowledge contained in this base model to another use case, which we call a downstream task. These tasks can come in the form of instructions. As the model size grows, it can generalize better to instructions that do not exist in the pre-training data, but were learned during fine-tuning.
Causal language models are adapted using a process called reinforcement learning from human feedback (RLHF). This optimization is mainly made over how natural and coherent the text sounds rather than the validity of the answer. Explaining how RLHF works is outside the scope of this blog post, but you can find more information about this process here.
For example, GPT-3 is a causal language base model, while the models in the backend of ChatGPT (which is the UI for GPT-series models) are fine-tuned through RLHF on prompts that can consist of conversations or instructions. It’s an important distinction to make between these models.
On the Hugging Face Hub, you can find both causal language models and causal language models fine-tuned on instructions (which we’ll give links to later in this blog post). Llama is one of the first open-source LLMs to have outperformed/matched closed-source ones. A research group led by Together has created a reproduction of Llama's dataset, called Red Pajama, and trained LLMs and instruction fine-tuned models on it. You can read more about it here and find the model checkpoints on Hugging Face Hub. By the time this blog post is written, three of the largest causal language models with open-source licenses are MPT-30B by MosaicML, XGen by Salesforce and Falcon by TII UAE, available completely open on Hugging Face Hub. Recently, Meta released Llama 2, an open-access model with a license that allows commercial use. As of now, Llama 2 outperforms all of the other open-source large language models on different benchmarks. Llama 2 checkpoints on Hugging Face Hub are compatible with transformers, and the largest checkpoint is available for everyone to try at HuggingChat. You can read more about how to fine-tune, deploy and prompt with Llama 2 in this blog post.
The second type of text generation model is commonly referred to as the text-to-text generation model. These models are trained on text pairs, which can be questions and answers or instructions and responses. The most popular ones are T5 and BART (which, as of now, aren’t state-of-the-art). Google has recently released the FLAN-T5 series of models. FLAN is a recent technique developed for instruction fine-tuning, and FLAN-T5 is essentially T5 fine-tuned using FLAN. As of now, the FLAN-T5 series of models are state-of-the-art and open-source, available on the Hugging Face Hub. Note that these are different from instruction-tuned causal language models, although the input-output format might seem similar. Below you can see an illustration of how these models work.
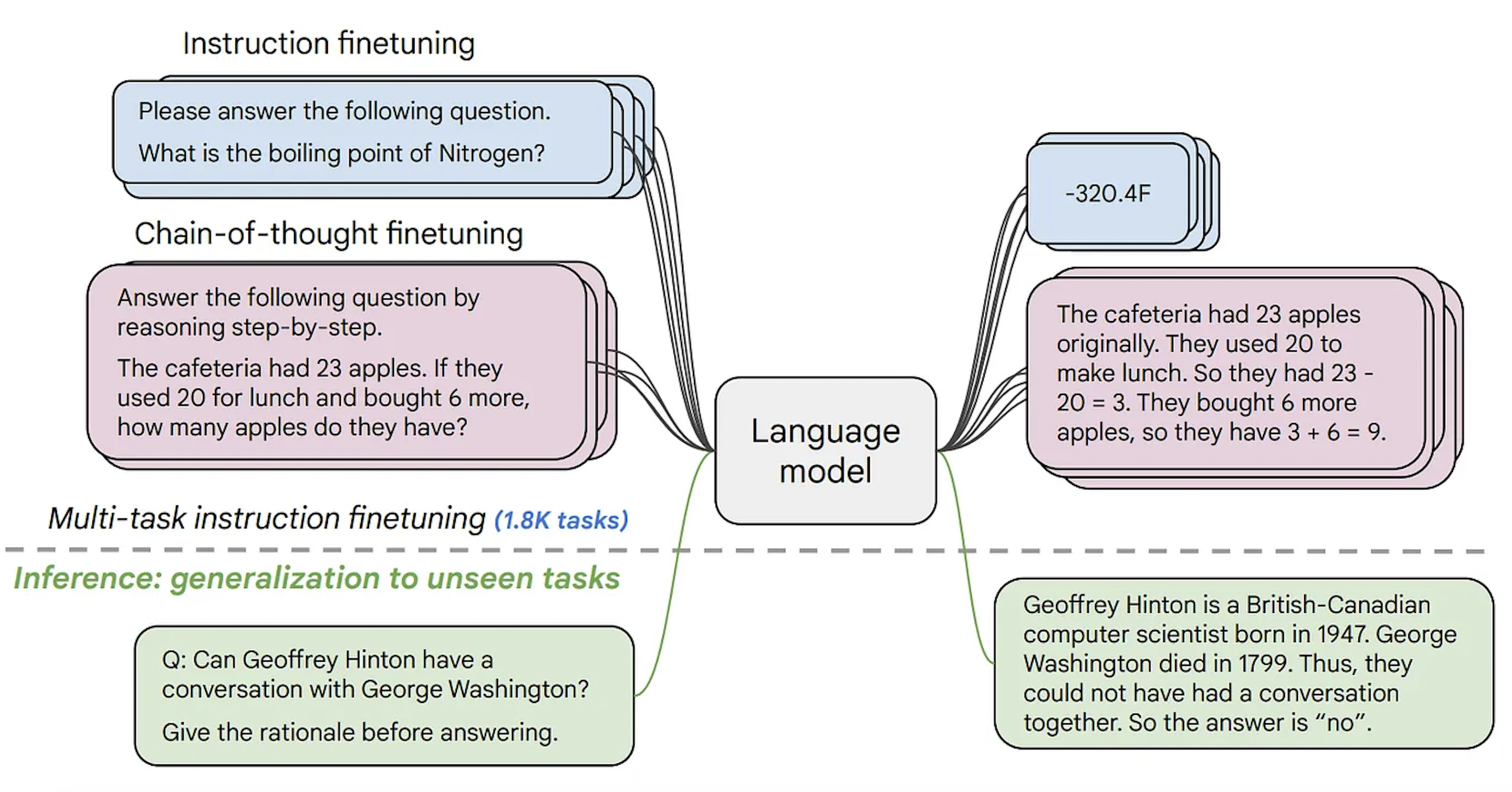
Having more variation of open-source text generation models enables companies to keep their data private, to adapt models to their domains faster, and to cut costs for inference instead of relying on closed paid APIs. All open-source causal language models on Hugging Face Hub can be found here, and text-to-text generation models can be found here.
Models created with love by Hugging Face with BigScience and BigCode 💗
Hugging Face has co-led two science initiatives, BigScience and BigCode. As a result of them, two large language models were created, BLOOM 🌸 and StarCoder 🌟. BLOOM is a causal language model trained on 46 languages and 13 programming languages. It is the first open-source model to have more parameters than GPT-3. You can find all the available checkpoints in the BLOOM documentation.
StarCoder is a language model trained on permissive code from GitHub (with 80+ programming languages 🤯) with a Fill-in-the-Middle objective. It’s not fine-tuned on instructions, and thus, it serves more as a coding assistant to complete a given code, e.g., translate Python to C++, explain concepts (what’s recursion), or act as a terminal. You can try all of the StarCoder checkpoints in this application. It also comes with a VSCode extension.
Snippets to use all models mentioned in this blog post are given in either the model repository or the documentation page of that model type in Hugging Face.
Licensing
Many text generation models are either closed-source or the license limits commercial use. Fortunately, open-source alternatives are starting to appear and being embraced by the community as building blocks for further development, fine-tuning, or integration with other projects. Below you can find a list of some of the large causal language models with fully open-source licenses:
There are two code generation models, StarCoder by BigCode and Codegen by Salesforce. There are model checkpoints in different sizes and open-source or open RAIL licenses for both, except for Codegen fine-tuned on instruction.
The Hugging Face Hub also hosts various models fine-tuned for instruction or chat use. They come in various styles and sizes depending on your needs.
- MPT-30B-Chat, by Mosaic ML, uses the CC-BY-NC-SA license, which does not allow commercial use. However, MPT-30B-Instruct uses CC-BY-SA 3.0, which can be used commercially.
- Falcon-40B-Instruct and Falcon-7B-Instruct both use the Apache 2.0 license, so commercial use is also permitted.
- Another popular family of models is OpenAssistant, some of which are built on Meta's Llama model using a custom instruction-tuning dataset. Since the original Llama model can only be used for research, the OpenAssistant checkpoints built on Llama don’t have full open-source licenses. However, there are OpenAssistant models built on open-source models like Falcon or pythia that use permissive licenses.
- StarChat Beta is the instruction fine-tuned version of StarCoder, and has BigCode Open RAIL-M v1 license, which allows commercial use. Instruction-tuned coding model of Salesforce, XGen model, only allows research use.
If you're looking to fine-tune a model on an existing instruction dataset, you need to know how a dataset was compiled. Some of the existing instruction datasets are either crowd-sourced or use outputs of existing models (e.g., the models behind ChatGPT). ALPACA dataset created by Stanford is created through the outputs of models behind ChatGPT. Moreover, there are various crowd-sourced instruction datasets with open-source licenses, like oasst1 (created by thousands of people voluntarily!) or databricks/databricks-dolly-15k. If you'd like to create a dataset yourself, you can check out the dataset card of Dolly on how to create an instruction dataset. Models fine-tuned on these datasets can be distributed.
You can find a comprehensive table of some open-source/open-access models below.
| Model | Dataset | License | Use |
|---|---|---|---|
| Falcon 40B | Falcon RefinedWeb | Apache-2.0 | Text Generation |
| SalesForce XGen 7B | Mix of C4, RedPajama and more | Apache-2.0 | Text Generation |
| MPT-30B | Mix of C4, RedPajama and more | Apache-2.0 | Text Generation |
| Pythia-12B | Pile | Apache-2.0 | Text Generation |
| RedPajama INCITE 7B | RedPajama | Apache-2.0 | Text Generation |
| OpenAssistant Falcon 40B | oasst1 and Dolly | Apache-2.0 | Text Generation |
| StarCoder | The Stack | BigCode OpenRAIL-M | Code Generation |
| Salesforce CodeGen | Starcoder Data | Apache-2.0 | Code Generation |
| FLAN-T5-XXL | gsm8k, lambada, and esnli | Apache-2.0 | Text-to-text Generation |
| MPT-30B Chat | ShareGPT-Vicuna, OpenAssistant Guanaco and more | CC-By-NC-SA-4.0 | Chat |
| MPT-30B Instruct | duorc, competition_math, dolly_hhrlhf | CC-By-SA-3.0 | Instruction |
| Falcon 40B Instruct | baize | Apache-2.0 | Instruction |
| Dolly v2 | Dolly | MIT | Text Generation |
| StarChat-β | OpenAssistant Guanaco | BigCode OpenRAIL-M | Code Instruction |
| Llama 2 | Undisclosed dataset | Custom Meta License (Allows commercial use) | Text Generation |
Tools in the Hugging Face Ecosystem for LLM Serving
Text Generation Inference
Response time and latency for concurrent users are a big challenge for serving these large models. To tackle this problem, Hugging Face has released text-generation-inference (TGI), an open-source serving solution for large language models built on Rust, Python, and gRPc. TGI is integrated into inference solutions of Hugging Face, Inference Endpoints, and Inference API, so you can directly create an endpoint with optimized inference with few clicks, or simply send a request to Hugging Face's Inference API to benefit from it, instead of integrating TGI to your platform.
TGI currently powers HuggingChat, Hugging Face's open-source chat UI for LLMs. This service currently uses one of OpenAssistant's models as the backend model. You can chat as much as you want with HuggingChat and enable the Web search feature for responses that use elements from current Web pages. You can also give feedback to each response for model authors to train better models. The UI of HuggingChat is also open-sourced, and we are working on more features for HuggingChat to allow more functions, like generating images inside the chat.
Recently, a Docker template for HuggingChat was released for Hugging Face Spaces. This allows anyone to deploy their instance based on a large language model with only a few clicks and customize it. You can create your large language model instance here based on various LLMs, including Llama 2.
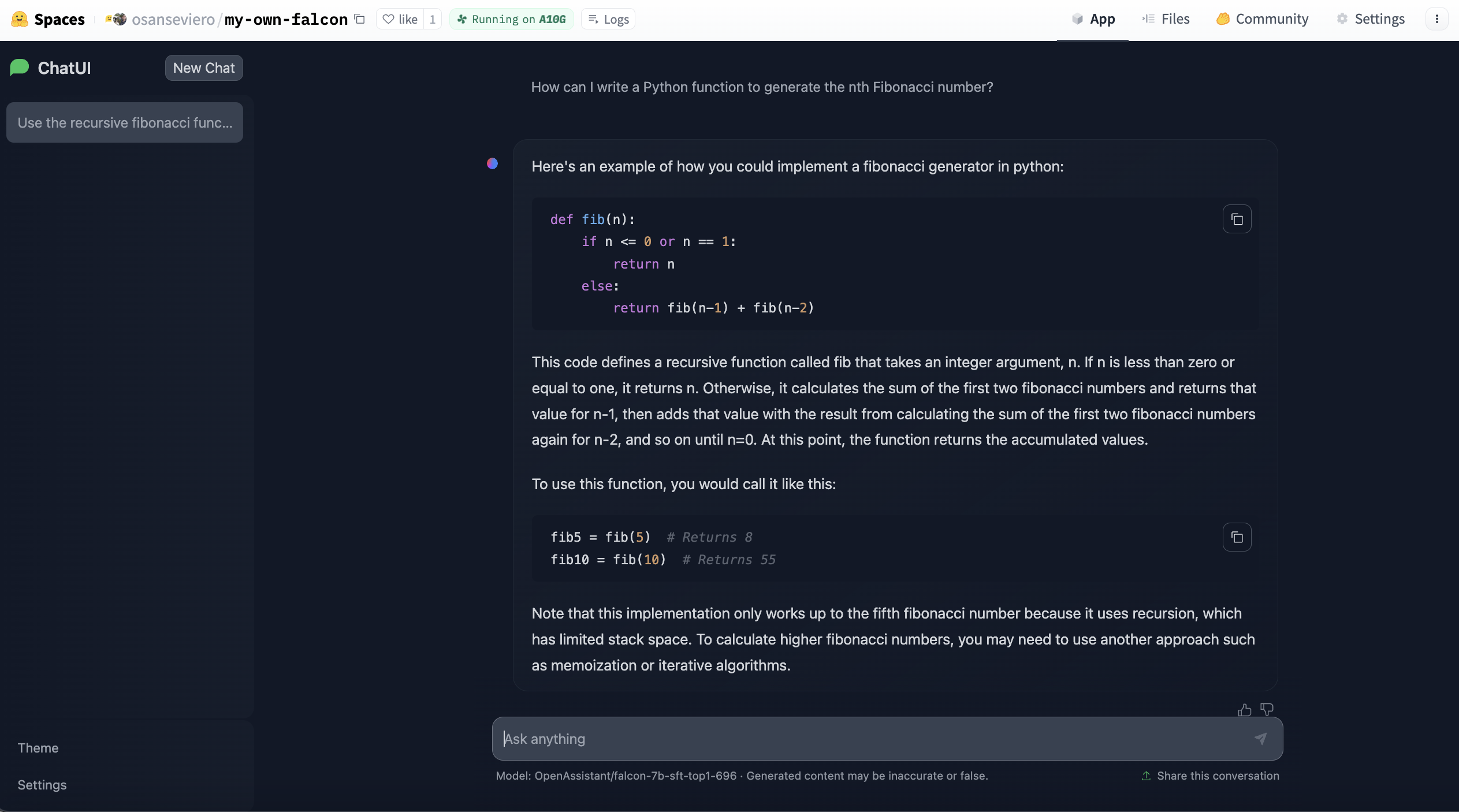
How to find the best model?
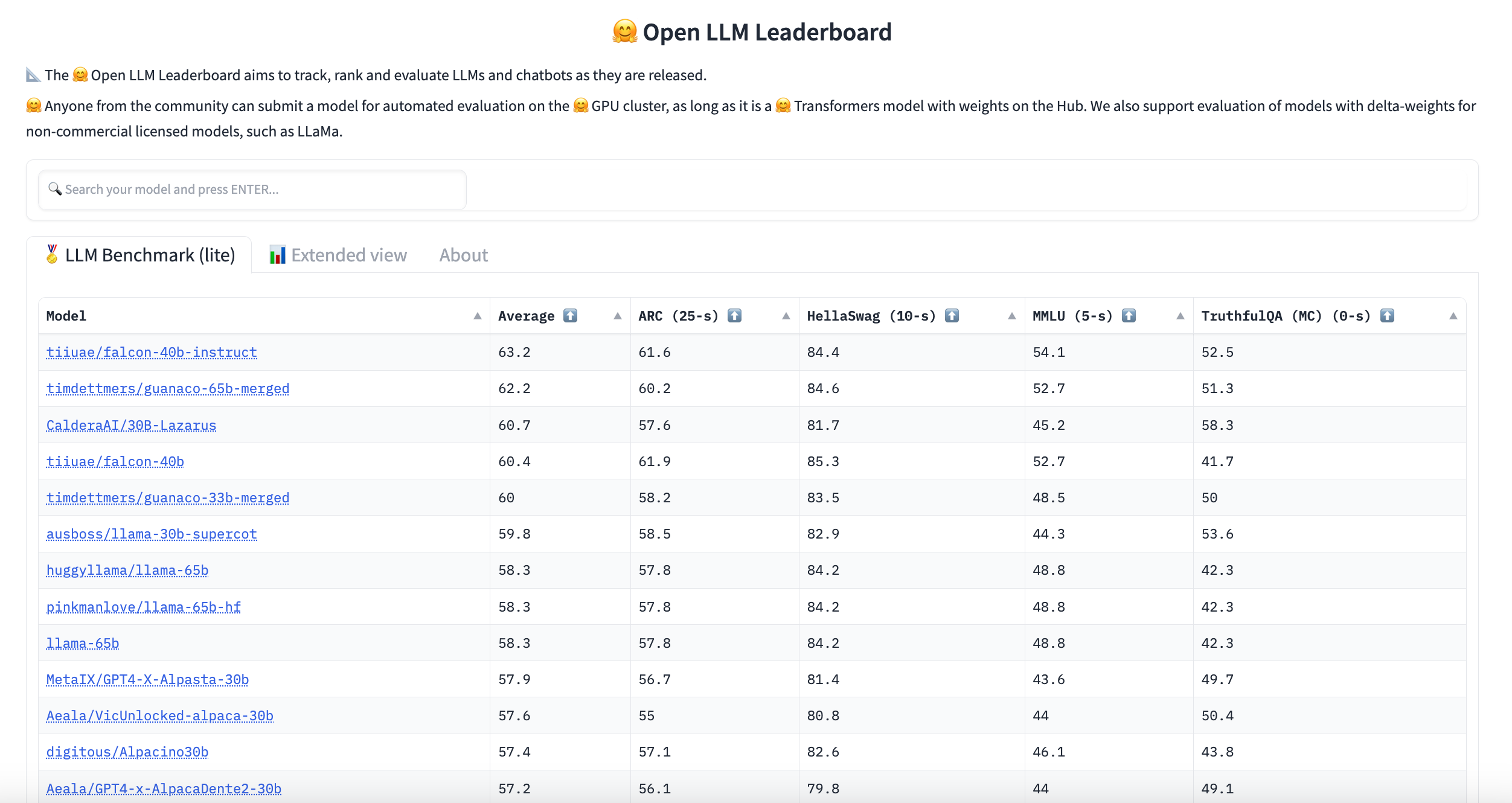
Hugging Face hosts an LLM leaderboard. This leaderboard is created by evaluating community-submitted models on text generation benchmarks on Hugging Face’s clusters. If you can’t find the language or domain you’re looking for, you can filter them here.
You can also check out the LLM Performance leaderboard, which aims to evaluate the latency and throughput of large language models available on Hugging Face Hub.
Parameter Efficient Fine Tuning (PEFT)
If you’d like to fine-tune one of the existing large models on your instruction dataset, it is nearly impossible to do so on consumer hardware and later deploy them (since the instruction models are the same size as the original checkpoints that are used for fine-tuning). PEFT is a library that allows you to do parameter-efficient fine-tuning techniques. This means that rather than training the whole model, you can train a very small number of additional parameters, enabling much faster training with very little performance degradation. With PEFT, you can do low-rank adaptation (LoRA), prefix tuning, prompt tuning, and p-tuning.
You can check out further resources for more information on text generation.
Further Resources
- Together with AWS we released TGI-based LLM deployment deep learning containers called LLM Inference Containers. Read about them here.
- Text Generation task page to find out more about the task itself.
- PEFT announcement blog post.
- Read about how Inference Endpoints use TGI here.
- Read about how to fine-tune Llama 2 transformers and PEFT, and prompt here.








