Announcing Evaluation on the Hub









This project has been archived. If you want to evaluate LLMs on the Hub, check out this collection of leaderboards.
TL;DR: Today we introduce Evaluation on the Hub, a new tool powered by AutoTrain that lets you evaluate any model on any dataset on the Hub without writing a single line of code!
Progress in AI has been nothing short of amazing, to the point where some people are now seriously debating whether AI models may be better than humans at certain tasks. However, that progress has not at all been even: to a machine learner from several decades ago, modern hardware and algorithms might look incredible, as might the sheer quantity of data and compute at our disposal, but the way we evaluate these models has stayed roughly the same.
However, it is no exaggeration to say that modern AI is in an evaluation crisis. Proper evaluation these days involves measuring many models, often on many datasets and with multiple metrics. But doing so is unnecessarily cumbersome. This is especially the case if we care about reproducibility, since self-reported results may have suffered from inadvertent bugs, subtle differences in implementation, or worse.
We believe that better evaluation can happen, if we - the community - establish a better set of best practices and try to remove the hurdles. Over the past few months, we've been hard at work on Evaluation on the Hub: evaluate any model on any dataset using any metric, at the click of a button. To get started, we evaluated hundreds models on several key datasets, and using the nifty new Pull Request feature on the Hub, opened up loads of PRs on model cards to display their verified performance. Evaluation results are encoded directly in the model card metadata, following a format for all models on the Hub. Check out the model card for DistilBERT to see how it looks!
On the Hub
Evaluation on the Hub opens the door to so many interesting use cases. From the data scientist or executive who needs to decide which model to deploy, to the academic trying to reproduce a paper’s results on a new dataset, to the ethicist who wants to better understand risks of deployment. If we have to single out three primary initial use case scenarios, they are these:
Finding the best model for your task
Suppose you know exactly what your task is and you want to find the right model for the job. You can check out the leaderboard for a dataset representative of your task, which aggregates all the results. That’s great! And what if that fancy new model you’re interested in isn’t on the leaderboard yet for that dataset? Simply run an evaluation for it, without leaving the Hub.
Evaluating models on your brand new dataset
Now what if you have a brand spanking new dataset that you want to run baselines on? You can upload it to the Hub and evaluate as many models on it as you like. No code required. What’s more, you can be sure that the way you are evaluating these models on your dataset is exactly the same as how they’ve been evaluated on other datasets.
Evaluating your model on many other related datasets
Or suppose you have a brand new question answering model, trained on SQuAD? There are hundreds of different question answering datasets to evaluate on :scream: You can pick the ones you are interested in and evaluate your model, directly from the Hub.
Ecosystem
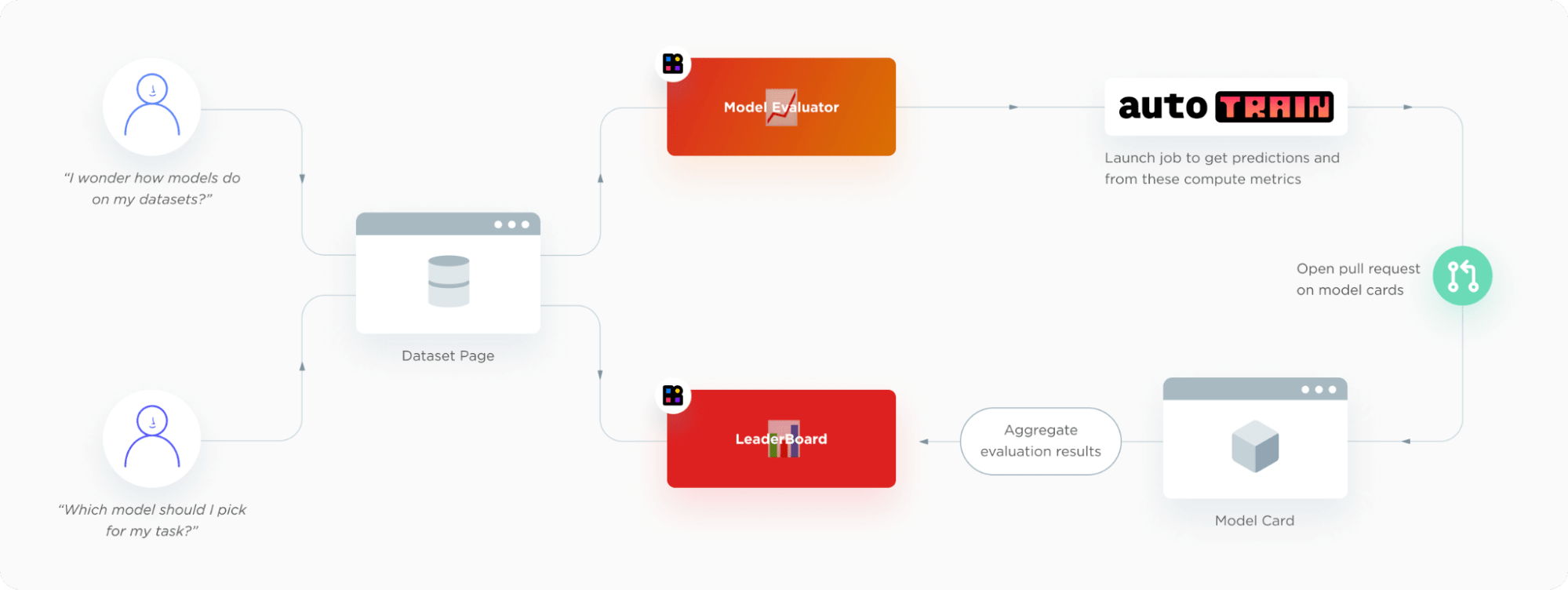
Evaluation on the Hub is meant to make your life easier. But of course, there’s a lot happening in the background. What we really like about Evaluation on the Hub: it fits so neatly into the existing Hugging Face ecosystem, we almost had to do it. Users start on dataset pages, from where they can launch evaluations or see leaderboards. The model evaluation submission interface and the leaderboards are regular Hugging Face Spaces. The evaluation backend is powered by AutoTrain, which opens up a PR on the Hub for the given model’s model card.
DogFood - Distinguishing Dogs, Muffins and Fried Chicken
So what does it look like in practice? Let’s run through an example. Suppose you are in the business of telling apart dogs, muffins and fried chicken (a.k.a. dogfooding!).

As the above image shows, to solve this problem, you’ll need:
- A dataset of dog, muffin, and fried chicken images
- Image classifiers that have been trained on these images
Fortunately, your data science team has uploaded a dataset to the Hugging Face Hub and trained a few different models on it. So now you just need to pick the best one - let’s use Evaluation on the Hub to see how well they perform on the test set!
Configuring an evaluation job
To get started, head over to the model-evaluator Space and select the dataset you want to evaluate models on. For our dataset of dog and food images, you’ll see something like the image below:

Now, many datasets on the Hub contain metadata that specifies how an evaluation should be configured (check out acronym_identification for an example). This allows you to evaluate models with a single click, but in our case we’ll show you how to configure the evaluation manually.
Clicking on the Advanced configuration button will show you the various settings to choose from:
- The task, dataset, and split configuration
- The mapping of the dataset columns to a standard format
- The choice of metrics
As shown in the image below, configuring the task, dataset, and split to evaluate on is straightforward:

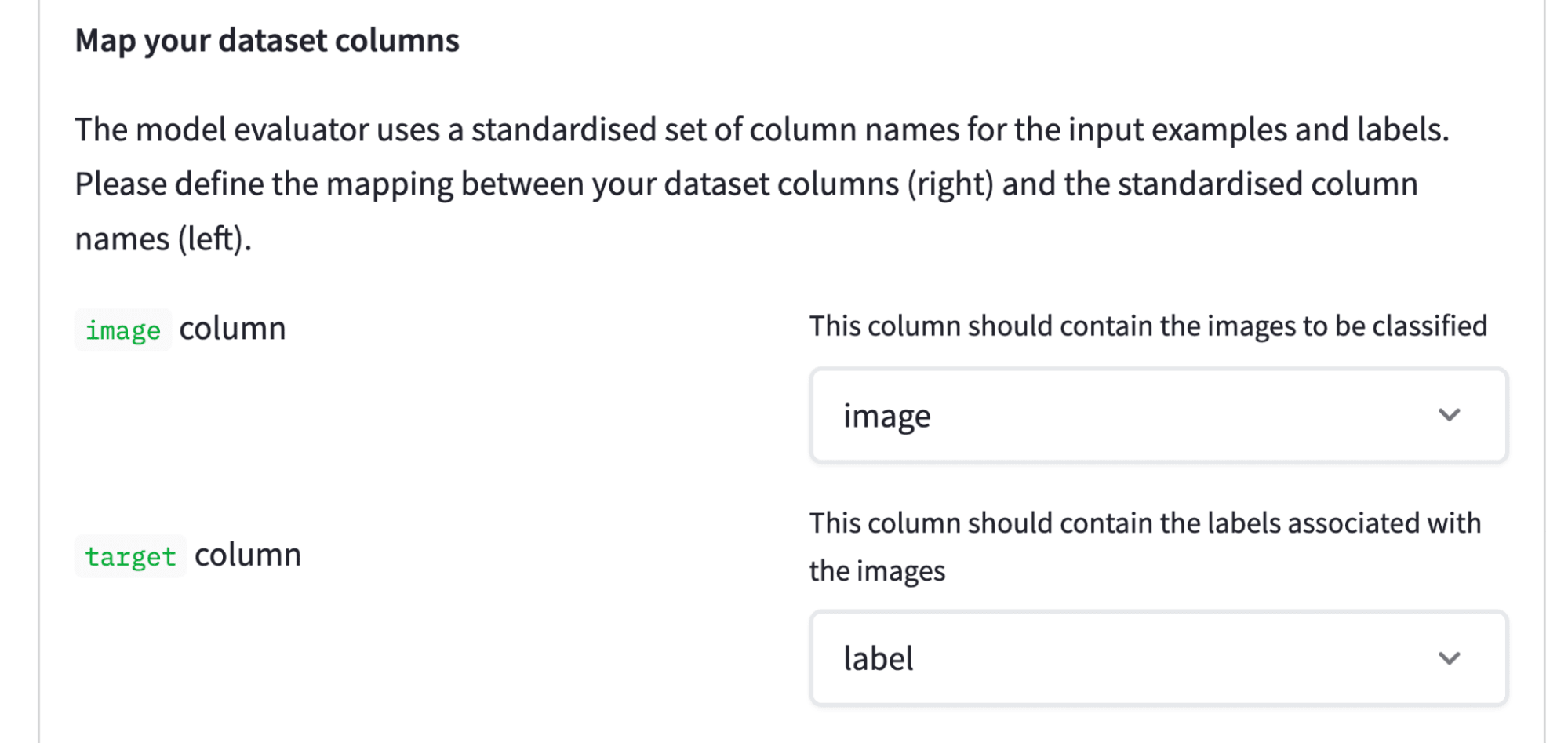
The next step is to define which dataset columns contain the images, and which ones contain the labels:
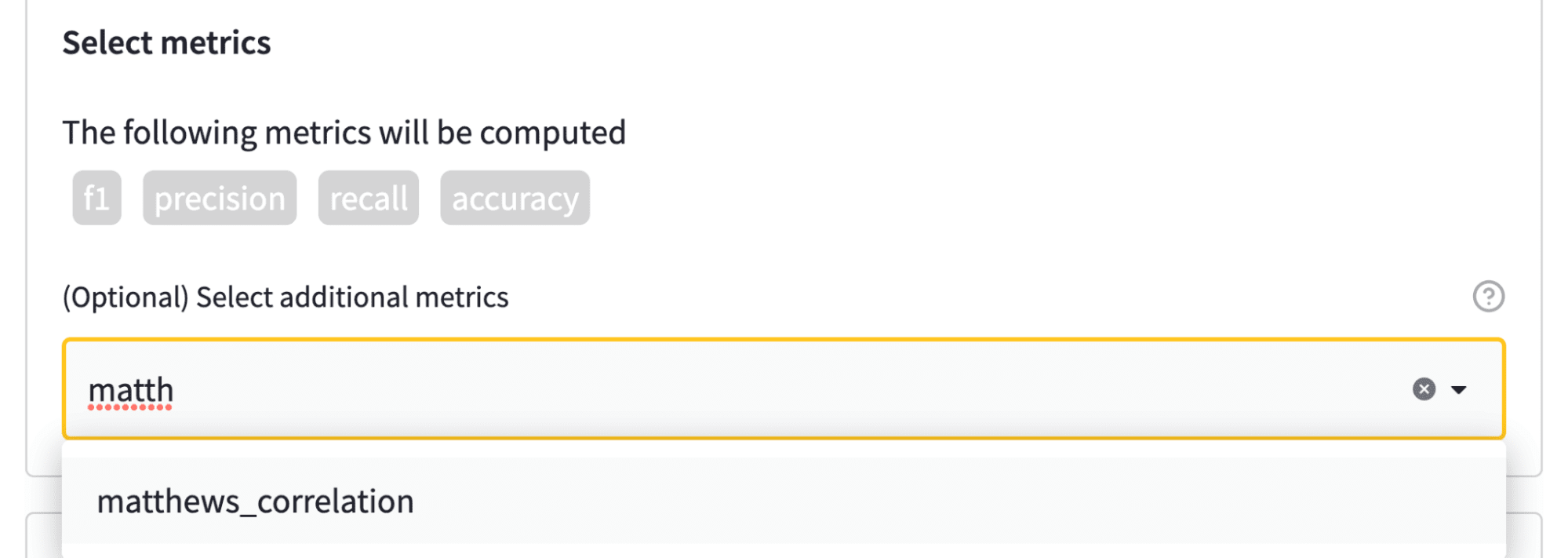
Now that the task and dataset are configured, the final (optional) step is to select the metrics to evaluate with. Each task is associated with a set of default metrics. For example, the image below shows that F1 score, accuracy etc will be computed automatically. To spice things up, we’ll also calculate the Matthew’s correlation coefficient, which provides a balanced measure of classifier performance:
And that’s all it takes to configure an evaluation job! Now we just need to pick some models to evaluate - let’s take a look.
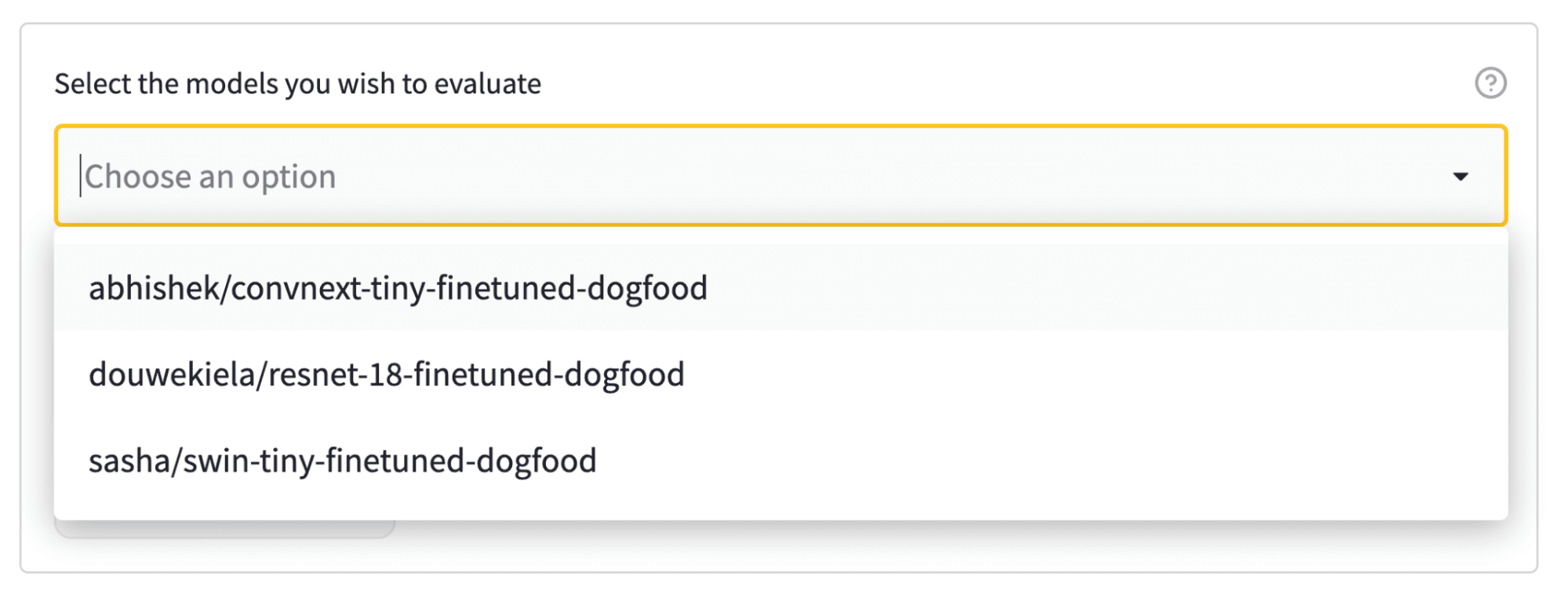
Selecting models to evaluate
Evaluation on the Hub links datasets and models via tags in the model card metadata. In our example, we have three models to choose from, so let’s select them all!
Once the models are selected, simply enter your Hugging Face Hub username (to be notified when the evaluation is complete) and hit the big Evaluate models button:
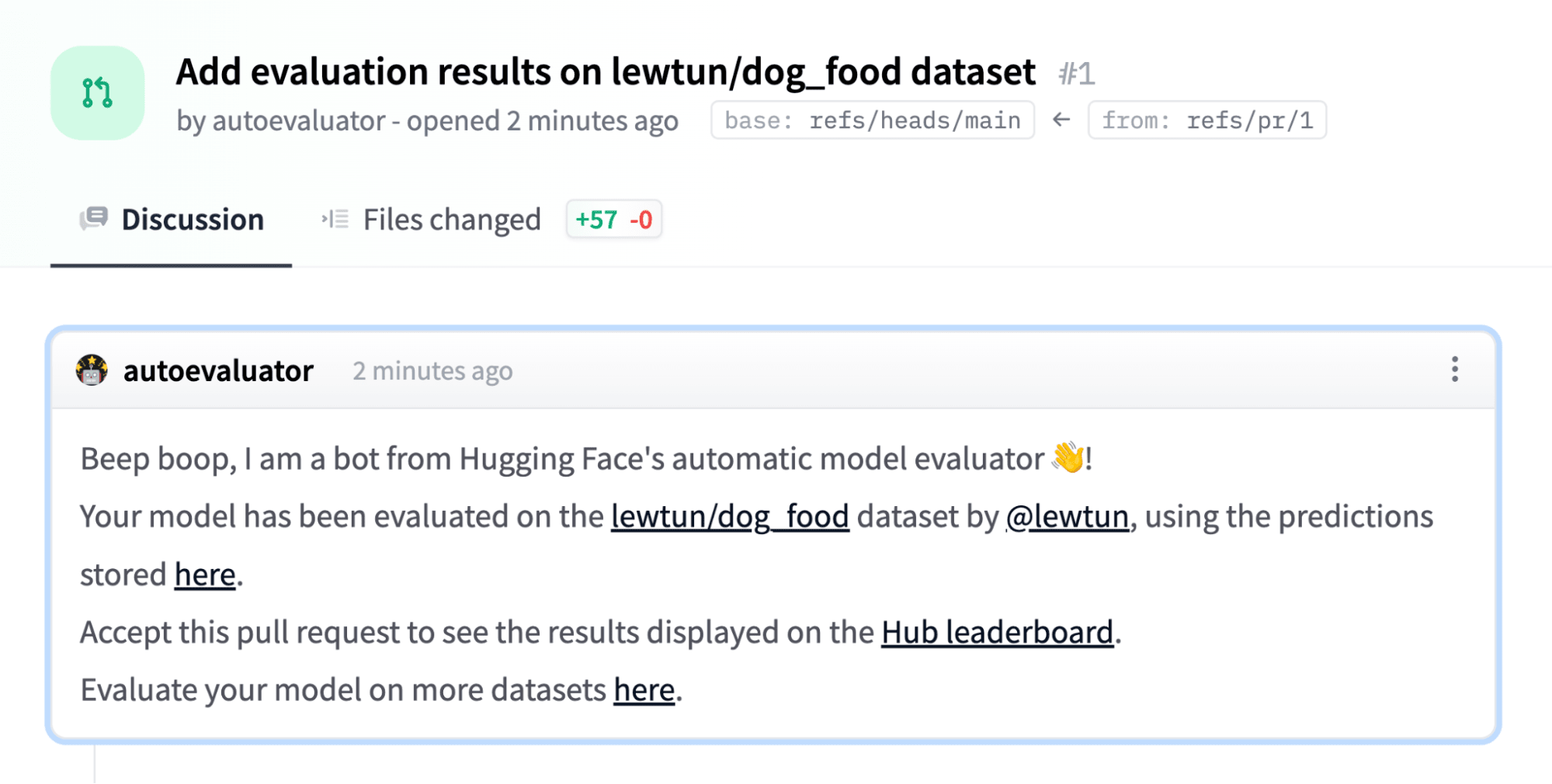
Once a job is submitted, the models will be automatically evaluated and a Hub pull request will be opened with the evaluation results:
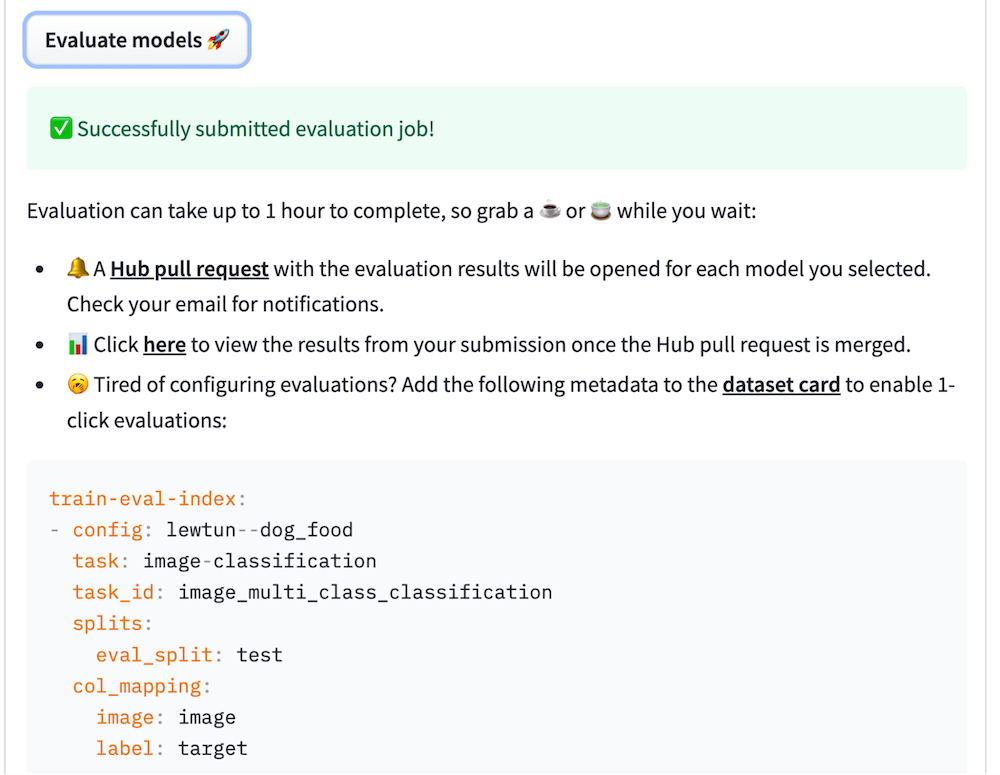
You can also copy-paste the evaluation metadata into the dataset card so that you and the community can skip the manual configuration next time!
Check out the leaderboard
To facilitate the comparison of models, Evaluation on the Hub also provides leaderboards that allow you to examine which models perform best on which split and metric:
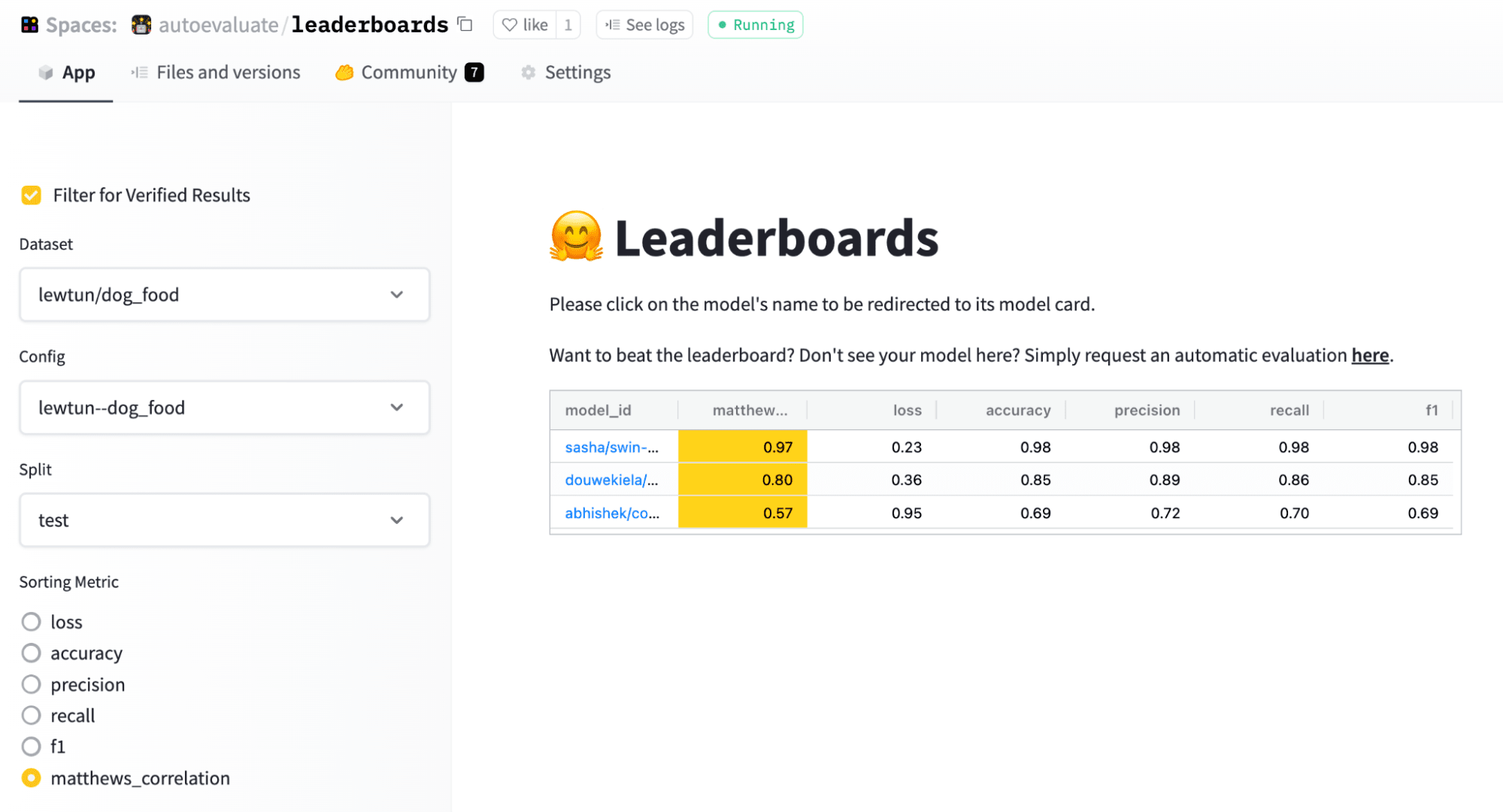
Looks like the Swin Transformer came out on top!
Try it yourself!
If you’d like to evaluate your own choice of models, give Evaluation on the Hub a spin by checking out these popular datasets:
- Emotion for text classification
- MasakhaNER for named entity recognition
- SAMSum for text summarization
The Bigger Picture
Since the dawn of machine learning, we've evaluated models by computing some form of accuracy on a held-out test set that is assumed to be independent and identically distributed. Under the pressures of modern AI, that paradigm is now starting to show serious cracks.
Benchmarks are saturating, meaning that machines outperform humans on certain test sets, almost faster than we can come up with new ones. Yet, AI systems are known to be brittle and suffer from, or even worse amplify, severe malicious biases. Reproducibility is lacking. Openness is an afterthought. While people fixate on leaderboards, practical considerations for deploying models, such as efficiency and fairness, are often glossed over. The hugely important role data plays in model development is still not taken seriously enough. What is more, the practices of pretraining and prompt-based in-context learning have blurred what it means to be “in distribution” in the first place. Machine learning is slowly catching up to these things, and we hope to help the field move forward with our work.
Next Steps
A few weeks ago, we launched the Hugging Face Evaluate library, aimed at lowering barriers to the best practices of machine learning evaluation. We have also been hosting benchmarks, like RAFT and GEM. Evaluation on the Hub is a logical next step in our efforts to enable a future where models are evaluated in a more holistic fashion, along many axes of evaluation, in a trustable and guaranteeably reproducible manner. Stay tuned for more launches soon, including more tasks, and a new and improved data measurements tool!
We’re excited to see where the community will take this! If you'd like to help out, evaluate as many models on as many datasets as you like. And as always, please give us lots of feedback, either on the Community tabs or the forums!






