
Qwen3-ASR Technical Report
Paper • 2601.21337 • Published • 38
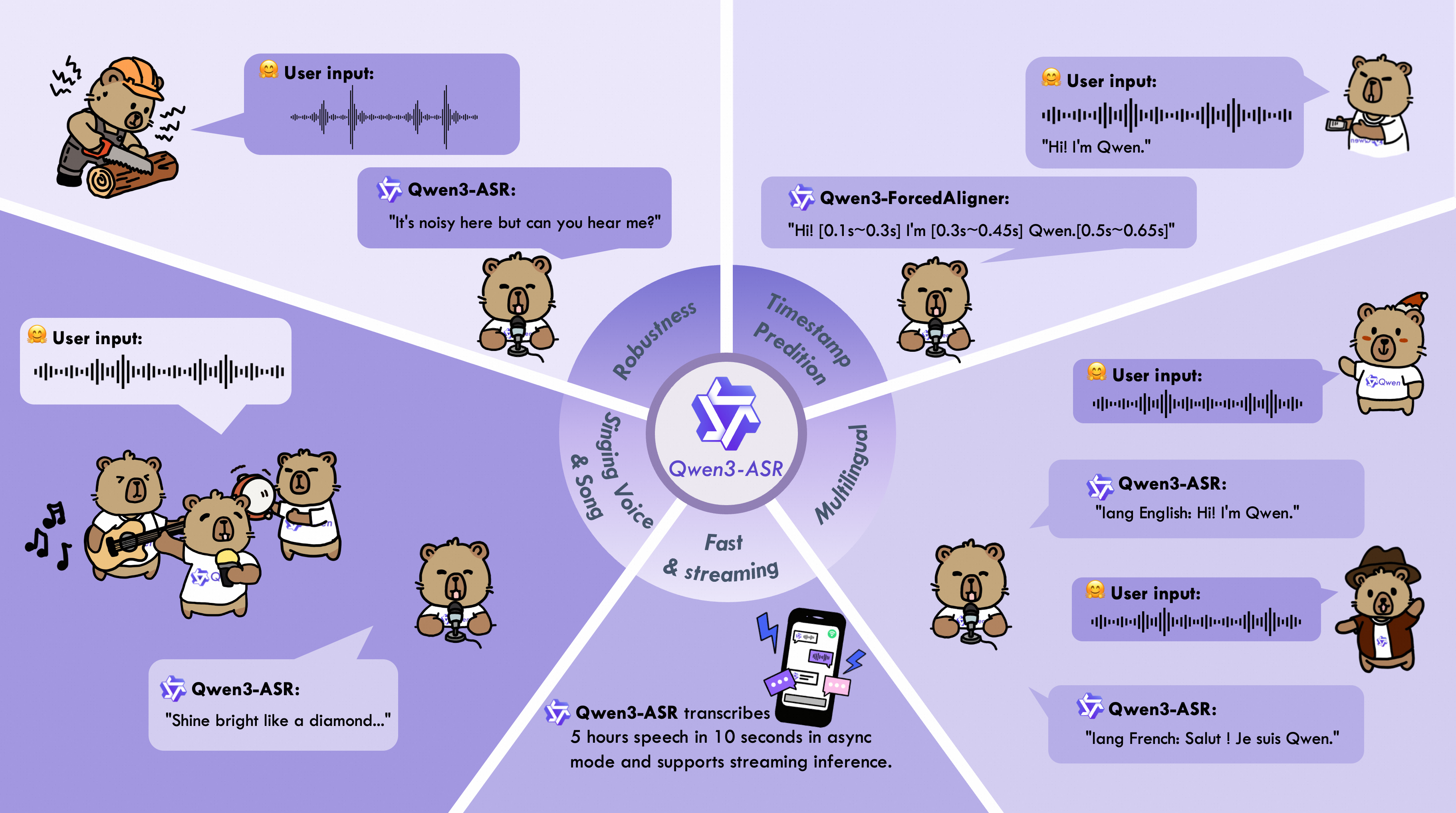
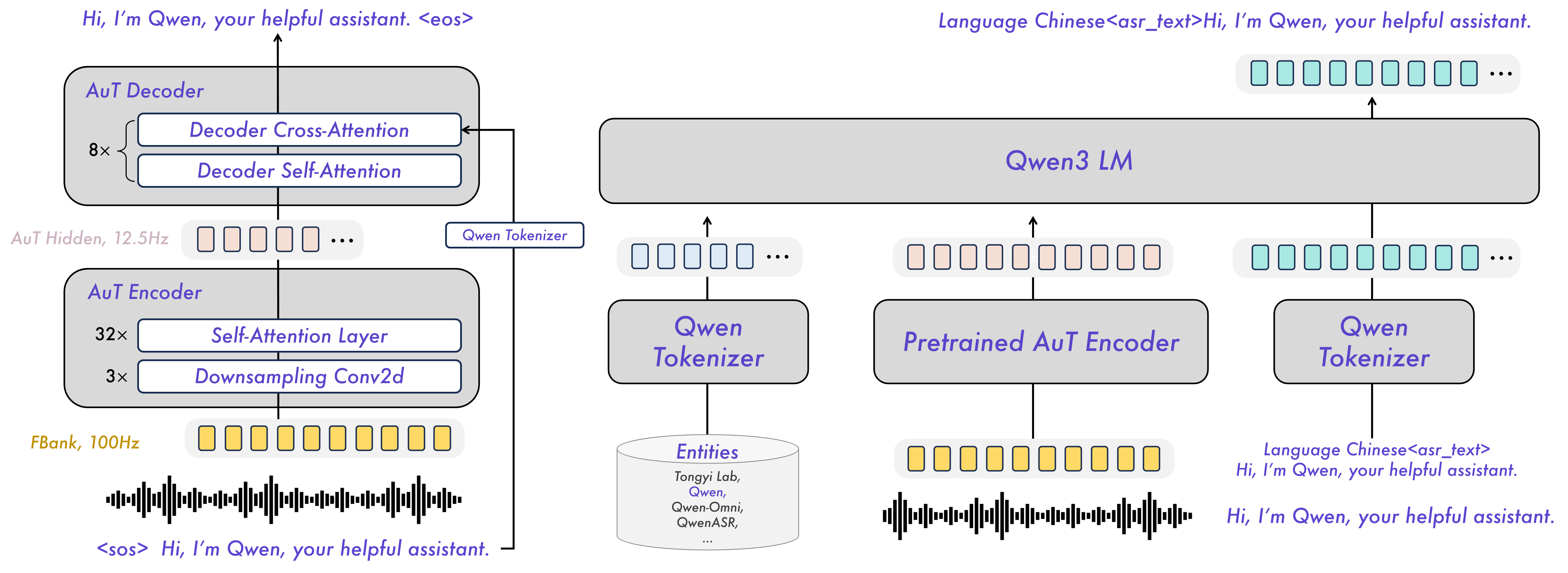
The Qwen3-ASR family includes Qwen3-ASR-1.7B and Qwen3-ASR-0.6B, which support language identification and ASR for 52 languages and dialects. Both leverage large-scale speech training data and the strong audio understanding capability of their foundation model, Qwen3-Omni. The 1.7B version achieves state-of-the-art performance among open-source ASR models and is competitive with the strongest proprietary commercial APIs.
Key features:
| Model | Supported Languages | Supported Dialects | Inference Mode | Audio Types |
|---|---|---|---|---|
| Qwen/Qwen3-ASR-1.7B-hf & Qwen/Qwen3-ASR-0.6B-hf | Chinese (zh), English (en), Cantonese (yue), Arabic (ar), German (de), French (fr), Spanish (es), Portuguese (pt), Indonesian (id), Italian (it), Korean (ko), Russian (ru), Thai (th), Vietnamese (vi), Japanese (ja), Turkish (tr), Hindi (hi), Malay (ms), Dutch (nl), Swedish (sv), Danish (da), Finnish (fi), Polish (pl), Czech (cs), Filipino (fil), Persian (fa), Greek (el), Hungarian (hu), Macedonian (mk), Romanian (ro) | Anhui, Dongbei, Fujian, Gansu, Guizhou, Hebei, Henan, Hubei, Hunan, Jiangxi, Ningxia, Shandong, Shaanxi, Shanxi, Sichuan, Tianjin, Yunnan, Zhejiang, Cantonese (HK), Cantonese (Guangdong), Wu, Minnan | Offline / Streaming | Speech, Singing Voice, Songs with BGM |
| Qwen/Qwen3-ForcedAligner-0.6B-hf | Chinese, English, Cantonese, French, German, Italian, Japanese, Korean, Portuguese, Russian, Spanish | — | NAR | Speech |
Until Qwen3-ForcedAligner is part of an official Transformers release, install from source:
pip install git+https://github.com/huggingface/transformers
Transcribe with the ASR model, then pass the transcript and audio to the forced aligner.
import torch
from transformers import AutoProcessor, AutoModelForMultimodalLM, AutoModelForTokenClassification
asr_model_id = "Qwen/Qwen3-ASR-0.6B-hf"
aligner_model_id = "Qwen/Qwen3-ForcedAligner-0.6B-hf"
asr_processor = AutoProcessor.from_pretrained(asr_model_id)
asr_model = AutoModelForMultimodalLM.from_pretrained(asr_model_id, device_map="auto")
aligner_processor = AutoProcessor.from_pretrained(aligner_model_id)
aligner_model = AutoModelForTokenClassification.from_pretrained(
aligner_model_id, dtype=torch.bfloat16, device_map="auto"
)
audio_url = "https://huggingface.co/datasets/bezzam/audio_samples/resolve/main/librispeech_mr_quilter.wav"
# Step 1: Transcribe
inputs = asr_processor.apply_transcription_request(audio=audio_url)
inputs = inputs.to(asr_model.device, asr_model.dtype)
output_ids = asr_model.generate(**inputs, max_new_tokens=256)
generated_ids = output_ids[:, inputs["input_ids"].shape[1]:]
parsed = asr_processor.decode(generated_ids, return_format="parsed")[0]
transcript = parsed["transcription"]
language = parsed["language"] or "English"
# Step 2: Prepare alignment inputs
aligner_inputs, word_lists = aligner_processor.prepare_forced_aligner_inputs(
audio=audio_url, transcript=transcript, language=language,
)
aligner_inputs = aligner_inputs.to(aligner_model.device, aligner_model.dtype)
# Step 3: Run forced aligner
with torch.inference_mode():
outputs = aligner_model(**aligner_inputs)
# Step 4: Decode timestamps
timestamps = aligner_processor.decode_forced_alignment(
logits=outputs.logits,
input_ids=aligner_inputs["input_ids"],
word_lists=word_lists,
timestamp_token_id=aligner_model.config.timestamp_token_id,
)[0]
for item in timestamps:
print(f"{item['text']:<20} {item['start_time']:>8.3f}s → {item['end_time']:>8.3f}s")
"""
Word Start (s) End (s)
------------------------------------------
Mr 0.560 0.800
Quilter 0.800 1.280
is 1.280 1.440
the 1.440 1.520
apostle 1.520 2.080
...
"""
The forced aligner accepts transcripts from any ASR system. Below is a batch inference example using NVIDIA Parakeet CTC for transcription.
import torch
from datasets import Audio, load_dataset
from transformers import AutoModelForCTC, AutoProcessor, AutoModelForTokenClassification
parakeet_processor = AutoProcessor.from_pretrained("nvidia/parakeet-ctc-1.1b")
parakeet_model = AutoModelForCTC.from_pretrained(
"nvidia/parakeet-ctc-1.1b", dtype="auto", device_map="cuda",
)
aligner_model_id = "Qwen/Qwen3-ForcedAligner-0.6B-hf"
aligner_processor = AutoProcessor.from_pretrained(aligner_model_id)
aligner_model = AutoModelForTokenClassification.from_pretrained(
aligner_model_id, dtype=torch.bfloat16, device_map="cuda",
)
ds = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")
ds = ds.cast_column("audio", Audio(sampling_rate=parakeet_processor.feature_extractor.sampling_rate))
audio_arrays = [ds[i]["audio"]["array"] for i in range(3)]
sr = ds[0]["audio"]["sampling_rate"]
# Batch transcribe with Parakeet
inputs = parakeet_processor(audio_arrays, sampling_rate=sr, return_tensors="pt", padding=True).to(
parakeet_model.device, dtype=parakeet_model.dtype
)
with torch.inference_mode():
outputs = parakeet_model.generate(**inputs)
transcripts = parakeet_processor.decode(outputs)
# Batch align with Qwen3 Forced Aligner
aligner_inputs, word_lists = aligner_processor.prepare_forced_aligner_inputs(
audio=audio_arrays, transcript=transcripts, language="English",
)
aligner_inputs = aligner_inputs.to(aligner_model.device, aligner_model.dtype)
with torch.inference_mode():
aligner_outputs = aligner_model(**aligner_inputs)
batch_timestamps = aligner_processor.decode_forced_alignment(
logits=aligner_outputs.logits,
input_ids=aligner_inputs["input_ids"],
word_lists=word_lists,
timestamp_token_id=aligner_model.config.timestamp_token_id,
)
for i, (transcript, timestamps) in enumerate(zip(transcripts, batch_timestamps)):
print(f"\n[Sample {i}] {transcript}")
for item in timestamps[:5]:
print(f" {item['text']:<20} {item['start_time']:>8.3f}s → {item['end_time']:>8.3f}s")
if len(timestamps) > 5:
print(f" ... ({len(timestamps) - 5} more words)")
The forced aligner is an especially good fit for torch.compile because it runs a single forward pass with no autoregressive decoding. This makes it ideal for bulk audio timestamping: transcribe with any ASR model, then batch-align with the compiled forced aligner for maximum throughput.
On an A100, we observed a speed-up of ~2.5× for a batch size of 4 (benchmark script).
import torch
from transformers import AutoProcessor, AutoModelForTokenClassification
model_id = "Qwen/Qwen3-ForcedAligner-0.6B-hf"
num_warmup = 5
batch_size = 4
processor = AutoProcessor.from_pretrained(model_id)
model = AutoModelForTokenClassification.from_pretrained(model_id, dtype=torch.bfloat16).to("cuda")
audio_url = "https://huggingface.co/datasets/bezzam/audio_samples/resolve/main/librispeech_mr_quilter.wav"
transcript = "Mr. Quilter is the apostle of the middle classes."
aligner_inputs, word_lists = processor.prepare_forced_aligner_inputs(
audio=[audio_url] * batch_size,
transcript=[transcript] * batch_size,
language=["English"] * batch_size,
)
aligner_inputs = aligner_inputs.to("cuda", torch.bfloat16)
model.forward = torch.compile(model.forward)
# Warmup
with torch.no_grad():
for _ in range(num_warmup):
_ = model(**aligner_inputs)
# Inference
with torch.no_grad():
outputs = model(**aligner_inputs)
@article{Qwen3-ASR,
title={Qwen3-ASR Technical Report},
author={Xian Shi, Xiong Wang, Zhifang Guo, Yongqi Wang, Pei Zhang, Xinyu Zhang, Zishan Guo,
Hongkun Hao, Yu Xi, Baosong Yang, Jin Xu, Jingren Zhou, Junyang Lin},
journal={arXiv preprint arXiv:2601.21337},
year={2026}
}