
Qwen3-ASR Technical Report
Paper • 2601.21337 • Published • 38
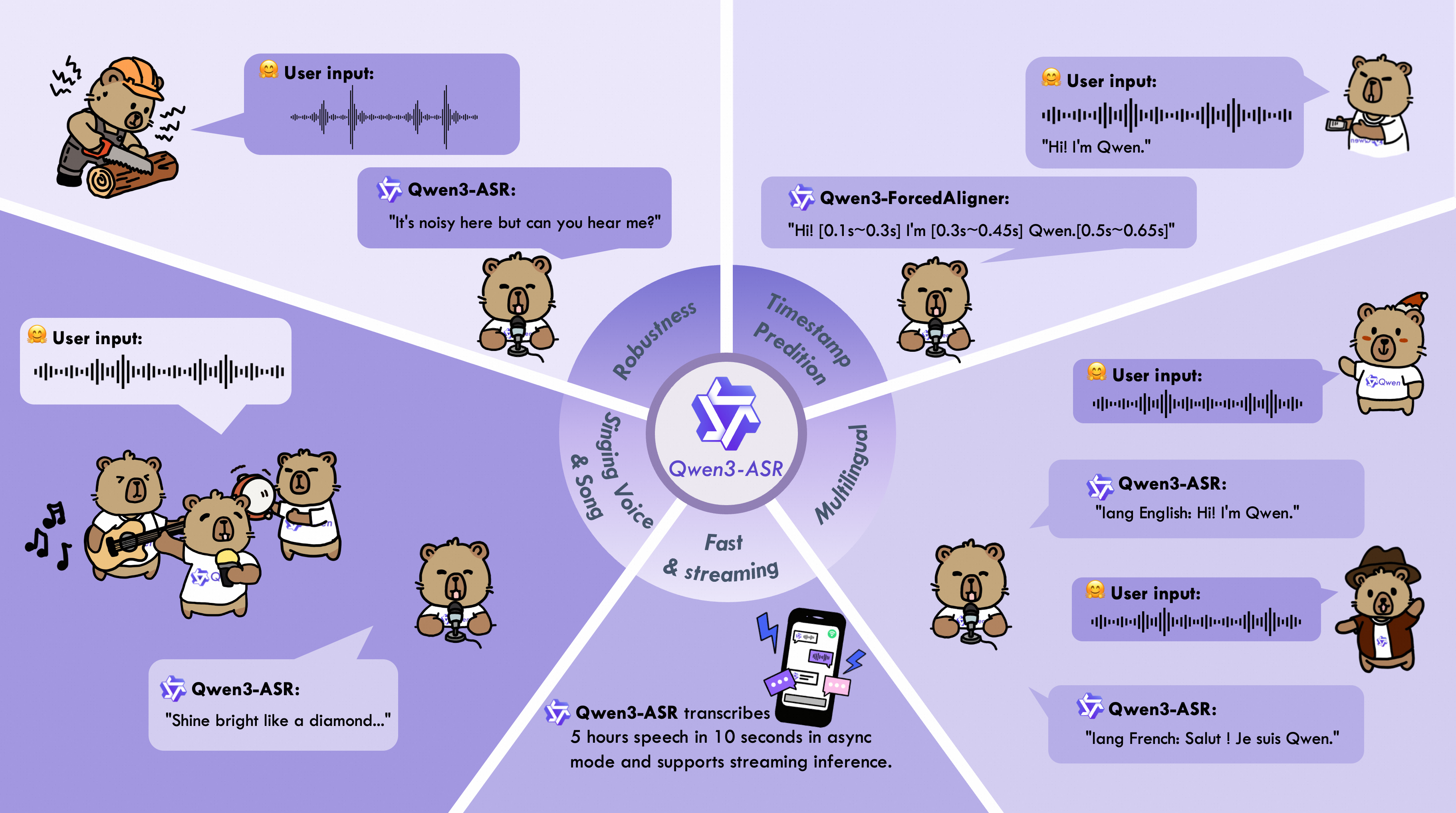
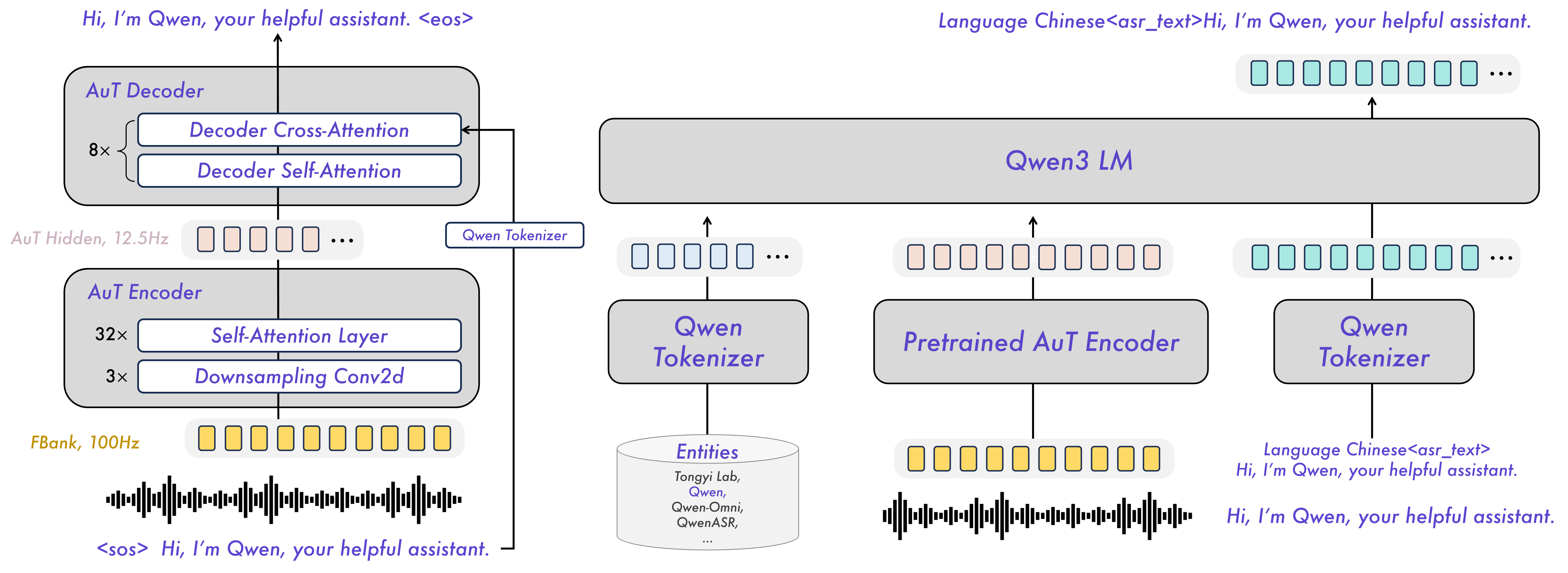
The Qwen3-ASR family includes Qwen3-ASR-1.7B and Qwen3-ASR-0.6B, which support language identification and ASR for 52 languages and dialects. Both leverage large-scale speech training data and the strong audio understanding capability of their foundation model, Qwen3-Omni. The 1.7B version achieves state-of-the-art performance among open-source ASR models and is competitive with the strongest proprietary commercial APIs.
Key features:
| Model | Supported Languages | Supported Dialects | Inference Mode | Audio Types |
|---|---|---|---|---|
| Qwen/Qwen3-ASR-1.7B-hf & Qwen/Qwen3-ASR-0.6B-hf | Chinese (zh), English (en), Cantonese (yue), Arabic (ar), German (de), French (fr), Spanish (es), Portuguese (pt), Indonesian (id), Italian (it), Korean (ko), Russian (ru), Thai (th), Vietnamese (vi), Japanese (ja), Turkish (tr), Hindi (hi), Malay (ms), Dutch (nl), Swedish (sv), Danish (da), Finnish (fi), Polish (pl), Czech (cs), Filipino (fil), Persian (fa), Greek (el), Hungarian (hu), Macedonian (mk), Romanian (ro) | Anhui, Dongbei, Fujian, Gansu, Guizhou, Hebei, Henan, Hubei, Hunan, Jiangxi, Ningxia, Shandong, Shaanxi, Shanxi, Sichuan, Tianjin, Yunnan, Zhejiang, Cantonese (HK), Cantonese (Guangdong), Wu, Minnan | Offline / Streaming | Speech, Singing Voice, Songs with BGM |
| Qwen/Qwen3-ForcedAligner-0.6B-hf | Chinese, English, Cantonese, French, German, Italian, Japanese, Korean, Portuguese, Russian, Spanish | — | NAR | Speech |
Qwen3-ASR is supported natively in 🤗 Transformers. Until it is part of an official Transformers release, install from source:
pip install git+https://github.com/huggingface/transformers
apply_transcription_request handles chat-template formatting for you and is the recommended entry point.
from transformers import AutoProcessor, AutoModelForMultimodalLM
model_id = "Qwen/Qwen3-ASR-1.7B-hf"
processor = AutoProcessor.from_pretrained(model_id)
model = AutoModelForMultimodalLM.from_pretrained(model_id, device_map="auto")
print(f"Model loaded on {model.device} with dtype {model.dtype}")
inputs = processor.apply_transcription_request(
audio="https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen3-ASR-Repo/asr_en.wav",
).to(model.device, model.dtype)
output_ids = model.generate(**inputs, max_new_tokens=256)
generated_ids = output_ids[:, inputs["input_ids"].shape[1]:]
# Raw output includes language tag and <asr_text> marker
raw = processor.decode(generated_ids)[0]
print(f"Raw: {raw}")
# Parsed output: dict with "language" and "transcription"
parsed = processor.decode(generated_ids, return_format="parsed")[0]
print(f"Parsed: {parsed}")
# Extract only the transcription text
transcription = processor.decode(generated_ids, return_format="transcription_only")[0]
print(f"Transcription: {transcription}")
"""
Raw: language English<asr_text>Mr. Quilter is the apostle of the middle classes, and we are glad to welcome his gospel.
Parsed: {'language': 'English', 'transcription': 'Mr. Quilter is the apostle of the middle classes, and we are glad to welcome his gospel.'}
Transcription: Mr. Quilter is the apostle of the middle classes, and we are glad to welcome his gospel.
"""
Pass a language hint to skip auto-detection.
from transformers import AutoProcessor, AutoModelForMultimodalLM
model_id = "Qwen/Qwen3-ASR-1.7B-hf"
processor = AutoProcessor.from_pretrained(model_id)
model = AutoModelForMultimodalLM.from_pretrained(model_id, device_map="auto")
# Without language hint (auto-detect)
inputs = processor.apply_transcription_request(
audio="https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen3-ASR-Repo/asr_zh.wav",
).to(model.device, model.dtype)
output_ids = model.generate(**inputs, max_new_tokens=256)
generated_ids = output_ids[:, inputs["input_ids"].shape[1]:]
print(f"Auto-detect: {processor.decode(generated_ids, return_format='transcription_only')[0]}")
# With language hint (language code or full name both accepted)
inputs = processor.apply_transcription_request(
audio="https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen3-ASR-Repo/asr_zh.wav",
language="Chinese", # or "zh"
).to(model.device, model.dtype)
output_ids = model.generate(**inputs, max_new_tokens=256)
generated_ids = output_ids[:, inputs["input_ids"].shape[1]:]
print(f"With hint: {processor.decode(generated_ids, return_format='transcription_only')[0]}")
Pass a list of audio paths and optional languages to transcribe multiple files in one call.
from transformers import AutoProcessor, AutoModelForMultimodalLM
model_id = "Qwen/Qwen3-ASR-1.7B-hf"
processor = AutoProcessor.from_pretrained(model_id)
model = AutoModelForMultimodalLM.from_pretrained(model_id, device_map="auto")
audio = [
"https://huggingface.co/datasets/bezzam/audio_samples/resolve/main/librispeech_mr_quilter.wav",
"https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen3-ASR-Repo/asr_zh.wav",
]
inputs = processor.apply_transcription_request(
audio, language=[None, "zh"],
).to(model.device, model.dtype)
output_ids = model.generate(**inputs, max_new_tokens=256)
generated_ids = output_ids[:, inputs["input_ids"].shape[1]:]
transcriptions = processor.decode(generated_ids, return_format="transcription_only")
for i, text in enumerate(transcriptions):
print(f"Audio {i + 1}: {text}")
apply_transcription_request is a convenience wrapper around apply_chat_template. Use the chat template directly for more control, such as providing a language hint via a system message.
from transformers import AutoProcessor, Qwen3ASRForConditionalGeneration
model_id = "Qwen/Qwen3-ASR-1.7B-hf"
processor = AutoProcessor.from_pretrained(model_id)
model = Qwen3ASRForConditionalGeneration.from_pretrained(model_id, device_map="auto")
chat_template = [
[
{"role": "system", "content": [{"type": "text", "text": "English"}]},
{
"role": "user",
"content": [
{
"type": "audio",
"path": "https://huggingface.co/datasets/bezzam/audio_samples/resolve/main/librispeech_mr_quilter.wav",
},
],
},
],
[
{
"role": "user",
"content": [
{
"type": "audio",
"path": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen3-ASR-Repo/asr_zh.wav",
},
],
},
],
]
inputs = processor.apply_chat_template(
chat_template, tokenize=True, return_dict=True,
).to(model.device, model.dtype)
output_ids = model.generate(**inputs, max_new_tokens=256)
generated_ids = output_ids[:, inputs["input_ids"].shape[1]:]
transcriptions = processor.decode(generated_ids, return_format="transcription_only")
for text in transcriptions:
print(text)
from transformers import AutoProcessor, Qwen3ASRForConditionalGeneration
model_id = "Qwen/Qwen3-ASR-1.7B-hf"
processor = AutoProcessor.from_pretrained(model_id)
model = Qwen3ASRForConditionalGeneration.from_pretrained(model_id, device_map="auto")
model.train()
chat_template = [
[
{
"role": "user",
"content": [
{
"type": "text",
"text": "Mr. Quilter is the apostle of the middle classes, and we are glad to welcome his gospel.",
},
{
"type": "audio",
"path": "https://huggingface.co/datasets/bezzam/audio_samples/resolve/main/librispeech_mr_quilter.wav",
},
],
}
],
]
inputs = processor.apply_chat_template(
chat_template, tokenize=True, return_dict=True, output_labels=True,
).to(model.device, model.dtype)
loss = model(**inputs).loss
print("Loss:", loss.item())
loss.backward()
Use Qwen3ASRForTokenClassification to obtain word-level timestamps from a transcript. Transcribe first with the ASR model, then align with the forced aligner.
Supported languages: Chinese, English, Cantonese, French, German, Italian, Japanese, Korean, Portuguese, Russian, Spanish.
Japanese requires
nagisaand Korean requiressoynlp:pip install nagisa soynlp
import torch
from transformers import AutoProcessor, AutoModelForMultimodalLM, AutoModelForTokenClassification
asr_model_id = "Qwen/Qwen3-ASR-0.6B-hf"
aligner_model_id = "Qwen/Qwen3-ForcedAligner-0.6B-hf"
asr_processor = AutoProcessor.from_pretrained(asr_model_id)
asr_model = AutoModelForMultimodalLM.from_pretrained(asr_model_id, device_map="auto")
aligner_processor = AutoProcessor.from_pretrained(aligner_model_id)
aligner_model = AutoModelForTokenClassification.from_pretrained(
aligner_model_id, dtype=torch.bfloat16, device_map="auto"
)
audio_url = "https://huggingface.co/datasets/bezzam/audio_samples/resolve/main/librispeech_mr_quilter.wav"
# Step 1: Transcribe
inputs = asr_processor.apply_transcription_request(audio=audio_url)
inputs = inputs.to(asr_model.device, asr_model.dtype)
output_ids = asr_model.generate(**inputs, max_new_tokens=256)
generated_ids = output_ids[:, inputs["input_ids"].shape[1]:]
parsed = asr_processor.decode(generated_ids, return_format="parsed")[0]
transcript = parsed["transcription"]
language = parsed["language"] or "English"
# Step 2: Prepare alignment inputs
aligner_inputs, word_lists = aligner_processor.prepare_forced_aligner_inputs(
audio=audio_url, transcript=transcript, language=language,
)
aligner_inputs = aligner_inputs.to(aligner_model.device, aligner_model.dtype)
# Step 3: Run forced aligner
with torch.inference_mode():
outputs = aligner_model(**aligner_inputs)
# Step 4: Decode timestamps
timestamps = aligner_processor.decode_forced_alignment(
logits=outputs.logits,
input_ids=aligner_inputs["input_ids"],
word_lists=word_lists,
timestamp_token_id=aligner_model.config.timestamp_token_id,
)[0]
for item in timestamps:
print(f"{item['text']:<20} {item['start_time']:>8.3f}s → {item['end_time']:>8.3f}s")
"""
Word Start (s) End (s)
------------------------------------------
Mr 0.560 0.800
Quilter 0.800 1.280
is 1.280 1.440
the 1.440 1.520
apostle 1.520 2.080
...
"""
from transformers import pipeline
model_id = "Qwen/Qwen3-ASR-1.7B-hf"
pipe = pipeline("any-to-any", model=model_id, device_map="auto")
chat_template = [
{
"role": "user",
"content": [
{
"type": "audio",
"path": "https://huggingface.co/datasets/bezzam/audio_samples/resolve/main/librispeech_mr_quilter.wav",
},
],
}
]
outputs = pipe(text=chat_template, return_full_text=False)
raw_text = outputs[0]["generated_text"]
# Use processor helper to extract transcription
transcription = pipe.processor.extract_transcription(raw_text)
print(f"Transcription: {transcription}")
Both the ASR and forced aligner models support torch.compile. The forced aligner is a particularly good fit because it runs a single forward pass with no autoregressive decoding, making it ideal for bulk timestamping workflows.
On an A100 we observed ~2.5× speed-up for the forced aligner and ~2.4× for ASR generate at batch size 4.
import torch
from transformers import AutoProcessor, AutoModelForMultimodalLM
model_id = "Qwen/Qwen3-ASR-1.7B-hf"
processor = AutoProcessor.from_pretrained(model_id)
model = AutoModelForMultimodalLM.from_pretrained(model_id, dtype=torch.bfloat16).to("cuda").eval()
audio_url = "https://huggingface.co/datasets/bezzam/audio_samples/resolve/main/librispeech_mr_quilter.wav"
inputs = processor.apply_transcription_request(
audio=[audio_url] * 4,
).to("cuda", torch.bfloat16)
model.forward = torch.compile(model.forward)
# Warmup
with torch.inference_mode():
for _ in range(3):
_ = model.generate(**inputs, max_new_tokens=256, do_sample=False)
# Inference
with torch.inference_mode():
output_ids = model.generate(**inputs, max_new_tokens=256, do_sample=False)
generated_ids = output_ids[:, inputs["input_ids"].shape[1]:]
print(processor.decode(generated_ids, return_format="transcription_only")[0])
WER on the HuggingFace Open ASR Leaderboard:
| Model | Mean WER | AMI | Earnings22 | GigaSpeech | LS Clean | LS Other | SPGISpeech | VoxPopuli |
|---|---|---|---|---|---|---|---|---|
| Qwen3-ASR-1.7B-hf | 5.59 | 9.26 | 9.88 | 7.25 | 1.24 | 2.92 | 2.58 | 5.99 |
| Qwen3-ASR-0.6B-hf | 6.31 | 10.57 | 10.72 | 7.65 | 1.69 | 3.97 | 2.74 | 6.80 |
@article{Qwen3-ASR,
title={Qwen3-ASR Technical Report},
author={Xian Shi, Xiong Wang, Zhifang Guo, Yongqi Wang, Pei Zhang, Xinyu Zhang, Zishan Guo,
Hongkun Hao, Yu Xi, Baosong Yang, Jin Xu, Jingren Zhou, Junyang Lin},
journal={arXiv preprint arXiv:2601.21337},
year={2026}
}