
[Trimming] Whisper
Collection
Collection of trimmed OpenAI's Whisper audio models. The models are sorted alphabetically. • 920 items • Updated
This model is a 11.27% smaller version of openai/whisper-small optimized for Dutch language via vocabulary size reduction using the trimming method.
This trimmed model should perform similarly to the original model with only 16,384 tokens and a much smaller memory footprint. However, it may not perform well for other languages as tokens not commonly used in the selected languages were removed from the vocabulary.
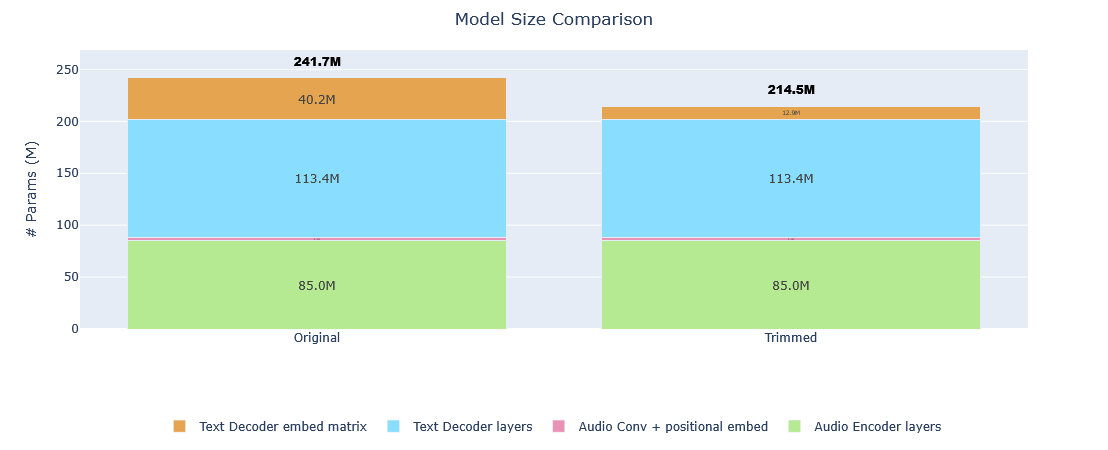
| Metric | Original | Trimmed | Reduction |
|---|---|---|---|
| Vocabulary size | 51,865 tokens | 16,384 tokens | 68.41% |
| Model size | 241,734,912 params | 214,485,504 params | 11.27% |
from transformers import AutoModelForSpeechSeq2Seq, AutoProcessor, pipeline
import librosa
# Pipeline function
processor = AutoProcessor.from_pretrained("alphaedge-ai/whisper-small-nld-16384")
pipe = pipeline(
"automatic-speech-recognition",
model="alphaedge-ai/whisper-small-nld-16384",
tokenizer=processor.tokenizer,
feature_extractor=processor.feature_extractor,
generate_kwargs={"language": "dutch", "task": "transcribe"},
)
# Loading and resampling at 16 kHz (required by Whisper)
audio_array, sampling_rate = librosa.load(audio_path, sr=16000)
# Result
result = pipe(audio_array)
print("Transcription :", result["text"])
@misc{radford2022whisper,
doi = {10.48550/ARXIV.2212.04356},
url = {https://arxiv.org/abs/2212.04356},
author = {Radford, Alec and Kim, Jong Wook and Xu, Tao and Brockman, Greg and McLeavey, Christine and Sutskever, Ilya},
title = {Robust Speech Recognition via Large-Scale Weak Supervision},
publisher = {arXiv},
year = {2022},
copyright = {arXiv.org perpetual, non-exclusive license}
}
@misc{hf_blogpost_trimming,
title={Introduction to Trimming},
author={Loïck BOURDOIS and Tom AARSEN and Bram VANROY and Christopher AKIKI and Woojun JUNG and Manuel ROMERO and Prithiv SAKTHI},
year={2026},
url={https://huggingface.co/blog/lbourdois/introduction-to-trimming},
}
Base model
openai/whisper-small