
VolFill: Single-View Amodal 3D Scene Reconstruction with Volumetric Flow Matching
Paper • 2605.31466 • Published
![]()
![]()
![]()
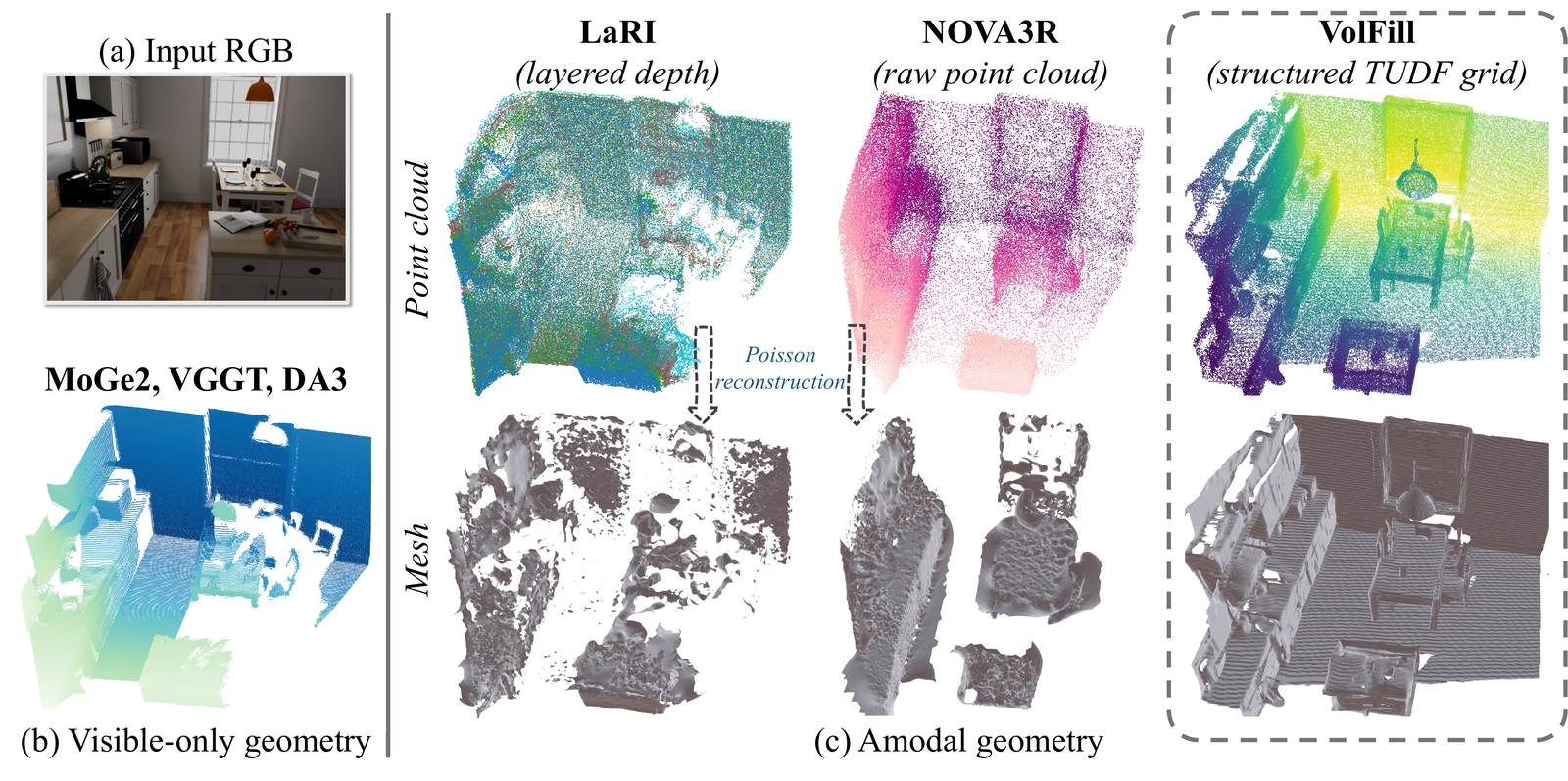
Pretrained checkpoints for VolFill, which recovers the complete 3D scene geometry — including occluded surfaces — from a single RGB image, represented as a 256³ Truncated Unsigned Distance Function (TUDF) grid.
Authors: Tuan Duc Ngo¹, Chuang Gan¹, Evangelos Kalogerakis¹˒² | ¹University of Massachusetts Amherst ²Technical University of Crete
VolFill is a two-stage latent generative model. A hybrid 3D VAE (sparse encoder → dense bottleneck → hybrid dense-to-sparse decoder) compresses the 256³ TUDF to a compact 16³×16ch latent, and a latent Diffusion Transformer trained with flow matching generates that latent — conditioned on (a) frozen MoGe-v2 image features as a global geometric prior and (b) a visible-geometry latent that anchors the occluded regions. At inference the model encodes the visible region, samples the DiT for 50 Euler steps with CFG = 3.0, and decodes to a TUDF that is thresholded into a point cloud or mesh.
| File | Description |
|---|---|
volfill_dit.pth |
Latent flow-matching DiT (visible-latent conditioned, 16× variant) |
volfill_vae.pth |
Hybrid 3D VAE (sparse encoder + hybrid decoder) |
inference.yaml |
Model architecture + sampler config |
latent_stats_16x.npy |
Latent normalization statistics (mean / std) |
The MoGe geometry prior (Ruicheng/moge-2-vitl, Ruicheng/moge-2-vitl-normal)
is downloaded automatically on first run.
Install the inference code from the GitHub repo (CUDA 13.0 / RTX 40-series), then everything in this model repo downloads automatically:
# CLI — all weights/config/stats auto-download from this repo
python -m volfill.amodal.inference_latent_visible \
--hf_repo TuanNgo/VolFill --input_path image.jpg --output ./results/
from PIL import Image
from volfill.amodal.inference_latent_visible import LatentTUDFVisibleInference
infer = LatentTUDFVisibleInference.from_pretrained("TuanNgo/VolFill")
result = infer(Image.open("image.jpg").convert("RGB"))
# result["tudf"]: (1, 1, 256, 256, 256) predicted TUDF in [-1, 1]
See the GitHub README for installation, point-cloud visualization, and local / Google-Drive checkpoint options.
@article{ngo2026volfill,
title = {VolFill: Single-View Amodal 3D Scene Reconstruction with Volumetric Flow Matching},
author = {Ngo, Tuan Duc and Gan, Chuang and Kalogerakis, Evangelos},
journal = {arXiv preprint arXiv:2605.31466},
year = {2026}
}
Released under the MIT License. Built on LaRI, reuses sparse-conv modules from TRELLIS, and uses MoGe-v2 as the visible geometry prior.